Dejia Xu (original) (raw)

I’m Dejia Xu and I’m now a research scientist at Luma AI. I got my Ph.D. from VITA Group, The University of Texas at Austin, advised by Prof. Atlas Wang.
My research helps build robust computational photography systems that display the physical world pleasingly and creative tools that let creators create or manipulate digital content as they wish. Now I mainly work on the area of Computational Photography, Creative Vision and Generative AI with a focus on video/3D.
I am open to coffee chats. Please feel free to reach out if you are interested in connecting!
news
selected publications

Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention
2024
We present Cavia, the first framework that enables users to generate multiple videos of the same scene with precise control over camera motion, while simultaneously preserving object motion.
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Dejia Xu, Weili Nie, Chao Liu, and 4 more authors
2024
We present a novel camera-controllable image-to-video generation framework, CamCo, that generates 3D-consistent videos. We introduce camera information via Plücker coordinates and propose epipolar constraint attention. We further fine-tune CamCo on real-world videos with camera poses estimated through structure-from-motion algorithms to better synthesize object motion.
Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
Hanwen Liang*, Yuyang Yin*, Dejia Xu, and 5 more authors
In Annual Conference on Neural Information Processing Systems, 2024
We present a novel 4D content generation framework, Diffusion4D, that, for the first time, adapts video diffusion models for explicit synthesis of spatial-temporal consistent novel views of 4D assets. The 4D-aware video diffusion model can seamlessly integrate with the off-the-shelf modern 4D construction pipelines to efficiently create 4D content within several minutes.
Comp4D: LLM-Guided Compositional 4D Scene Generation
Dejia Xu*, Hanwen Liang*, Neel P Bhatt, and 4 more authors
2024
We introduce Comp4D, compositional 4D scene synthesis from text input. Compared with previous object-centric 4D generation pipelines, our Compositional 4D Generation (Comp4D) framework integrates GPT-4 to decompose the scene and design proper trajectories, resulting in larger-scale movements and more realistic object interactions.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Shijie Zhou*, Zhiwen Fan*, Dejia Xu*, and 5 more authors
In European Conference on Computer Vision, 2024
We design a novel cascaded generation pipeline that produces 3D Gaussian-based objects without per-instance optimization. Our Amortized Generative 3D Gaussians (AGG) framework involves a coarse generator that predicts a hybrid representation for 3D Gaussians at a low resolution and a super-resolution module that delivers dense 3D Gaussians in the fine stage.
AGG: Amortized Generative 3D Gaussians for Single Image to 3D
Dejia Xu, Ye Yuan, Morteza Mardani, and 4 more authors
In Transactions on Machine Learning Research, 2024
We design a novel cascaded generation pipeline that produces 3D Gaussian-based objects without per-instance optimization. Our Amortized Generative 3D Gaussians (AGG) framework involves a coarse generator that predicts a hybrid representation for 3D Gaussians at a low resolution and a super-resolution module that delivers dense 3D Gaussians in the fine stage.
Taming Mode Collapse in Score Distillation for Text-to-3D Generation
Peihao Wang, Dejia Xu, Zhiwen Fan, and 8 more authors
In IEEE / CVF Computer Vision and Pattern Recognition Conference, 2024
We derive an entropy-maximizing score distillation rule that fosters view diversity and address the multi-face problem for text-to-3D generation.
PAIR-Diffusion: Object-Level Image Editing with Structure-and-Appearance Paired Diffusion Models
Vidit Goel, Elia Peruzzo, Yifan Jiang, and 5 more authors
In IEEE / CVF Computer Vision and Pattern Recognition Conference, 2024
4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency
Dejia Xu*, Yuyang Yin*, Zhangyang Wang, and 2 more authors
2023
We introduce grounded 4D content generation. We identify static 3D assets and monocular video sequences as key components in constructing the 4D content. Our pipeline facilitates conditional 4D generation, enabling users to specify geometry (3D assets) and motion (monocular videos), thus offering superior control over content creation.
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Zhiwen Fan, Kevin Wang, Kairun Wen, and 3 more authors
In Annual Conference on Neural Information Processing Systems, 2024
We transform 3D Gaussians into a more efficient and compact format.
Multi-Concept T2I-Zero: Tweaking Only The Text Embeddings and Nothing Else
Hazarapet Tunanyan, Dejia Xu, Shant Navasardyan, and 2 more authors
2023
CLE Diffusion: Controllable Light Enhancement Diffusion Model
Yuyang Yin, Dejia Xu, Chuangchuang Tan, and 3 more authors
In ACM Multimedia, 2023
Reference-based Painterly Inpainting via Diffusion: Crossing the Wild Reference Domain Gap
Dejia Xu, Xingqian Xu, Wenyan Cong, and 2 more authors
In IEEE / CVF Computer Vision and Pattern Recognition Conference AI4CC Workshop, 2024
NeuralLift-360: Lifting An In-the-wild 2D Photo to A 3D Object with 360 Views
Dejia Xu, Yifan Jiang, Peihao Wang, and 3 more authors
In IEEE / CVF Computer Vision and Pattern Recognition Conference, 2023
AligNeRF: High-Fidelity Neural Radiance Fields via Alignment-Aware Training
Yifan Jiang, Peter Hedman, Ben Mildenhall, and 4 more authors
In IEEE / CVF Computer Vision and Pattern Recognition Conference, 2023
NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes
Zhiwen Fan, Peihao Wang, Yifan Jiang, and 3 more authors
In International Conference on Learning Representations, 2023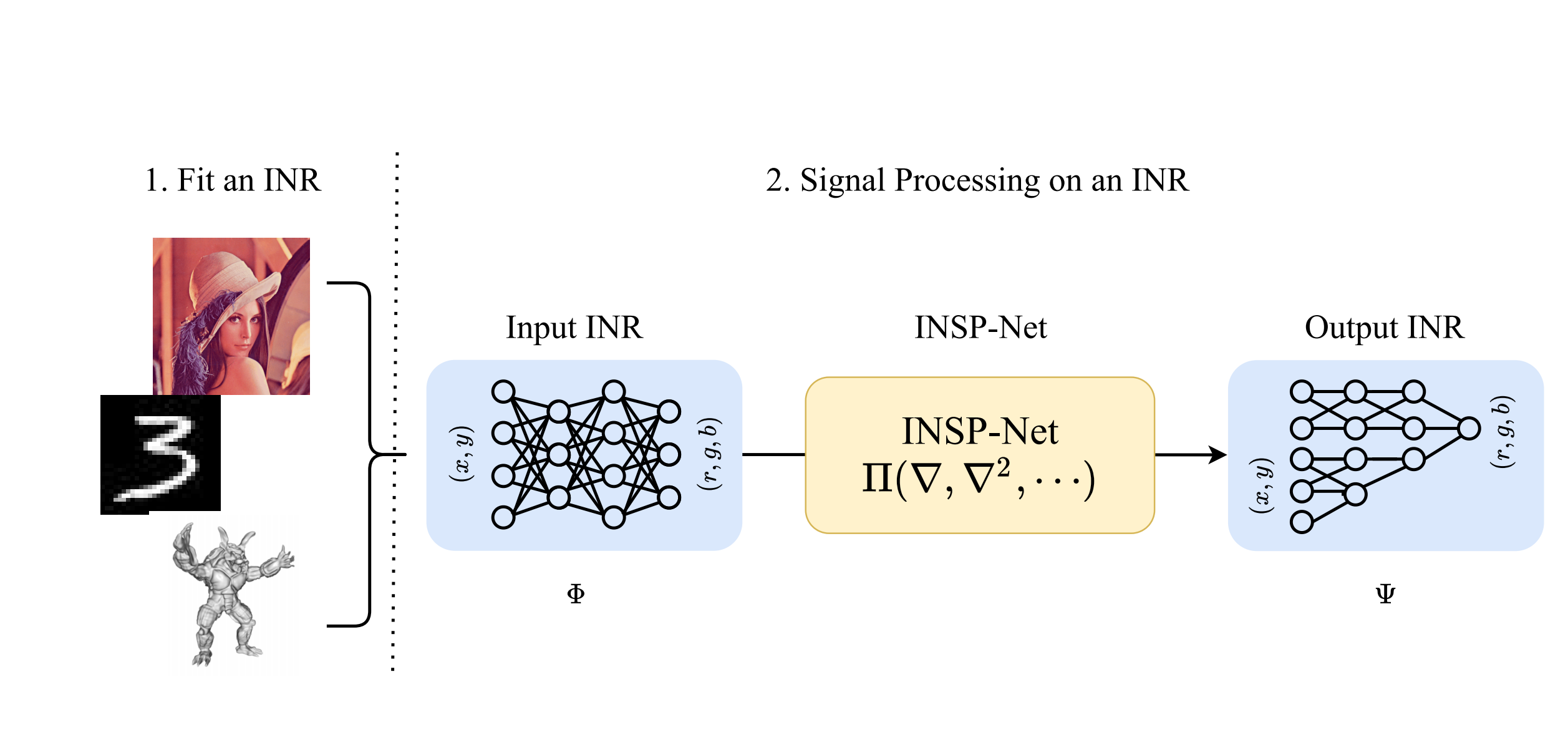
Signal Processing for Implicit Neural Representations
Dejia Xu*, Peihao Wang*, Yifan Jiang, and 2 more authors
In Annual Conference on Neural Information Processing Systems, 2022
SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image
Dejia Xu*, Yifan Jiang*, Peihao Wang, and 3 more authors
In European Conference on Computer Vision, 2022
Unified Implicit Neural Stylization
Zhiwen Fan, Yifan Jiang, Peihao Wang, and 3 more authors
In European Conference on Computer Vision, 2022
ReCoRo: Region-Controllable Robust Light Enhancement by User-Specified Imprecise Masks
Dejia Xu*, Hayk Poghosyan*, Shant Navasardyan, and 3 more authors
In ACM Multimedia, 2022
Cloud2Sketch: Augmenting Clouds with Imaginary Sketches
Zhaoyi Wan, Dejia Xu, Zhangyang Wang, and 2 more authors
In ACM Multimedia, 2022