Jialu Li (original) (raw)
| Jialu Li Hi, thanks for stopping by. I'm an Applied Scientist at Adobe, working on text-to-image and text-to-video foundation model training. I received my Ph.D. from The University of North Carolina at Chapel Hill, advised by Prof. Mohit Bansal. Before joining UNC-CH, I got my Master degree from Cornell University, where I was advised by Prof. Claire Cardie. I did my Bachelor degree at Shanghai JiaoTong University. Email / CV / Google Scholar / Twitter / Github |  |
|---|
Research
I have a broad interest in Multimodal research, with a focus on text-to-image generation, Vision-and-Language Navigation, and multi-modal LLM.
News
- We have a paper accepted to ICML 2026.
- We have a paper accepted to AAAI 2026.
- I will join Adobe as an Applied Scientist starting from Summer 2025.
- We have two papers accepted to ICLR 2025.
- We have a paper accepted to NeurIPS 2024.
- I will intern at Google as Student Researcher for Summer 2024.
- We have a paper accepted to AAAI 2024.
- We have a paper accepted to NeurIPS 2023.
- We have a paper accepted to ICCV 2023 and selected as Oral presentation.
- I will intern at Apple as Machine Learning Research Intern for Summer 2023.
- We have a paper accepted to CVPR 2023.
- We have a paper accepted to Findings of NAACL 2022.
- We have a paper accepted to CVPR 2022.
- I will intern at Amazon as Applied Scientist for Summer 2022.
- We have a paper accepted to EMNLP 2021.
- We have a paper accepted to NAACL 2021.
- We have a paper accepted to EMNLP 2020.
- I will join UNC-CH as a new Ph.D. student in Fall 2020.
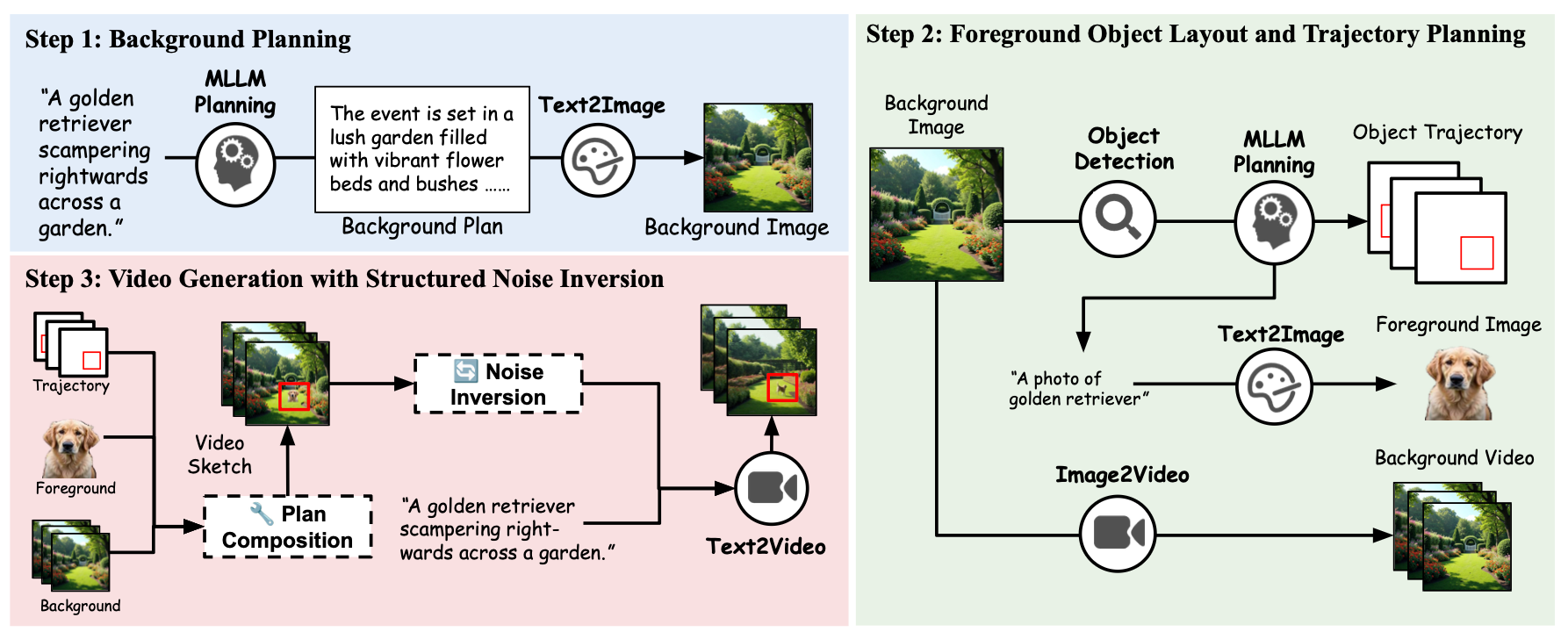 |
Training-free guidance in text-to-video generation via multimodal planning and structured noise initialization Jialu Li*, Shoubin Yu*, Han Lin*, Jaemin Cho, Jaehong Yoon, Mohit Bansal. Preprint paper /code /bib /website |
|---|---|
| Unbounded: A Generative Infinite Game of Character Life Simulation Jialu Li, Yuanzhen Li, Neal Wadhwa, Yael Pritch, David E. Jacobs, Michael Rubinstein, Mohit Bansal, Nataniel Ruiz. ICLR, 2025 paper /bib /website | |
| DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation Zun Wang, Jialu Li, Han Lin, Jaehong Yoon, Mohit Bansal. AAAI, 2026 paper /code /bib /website | |
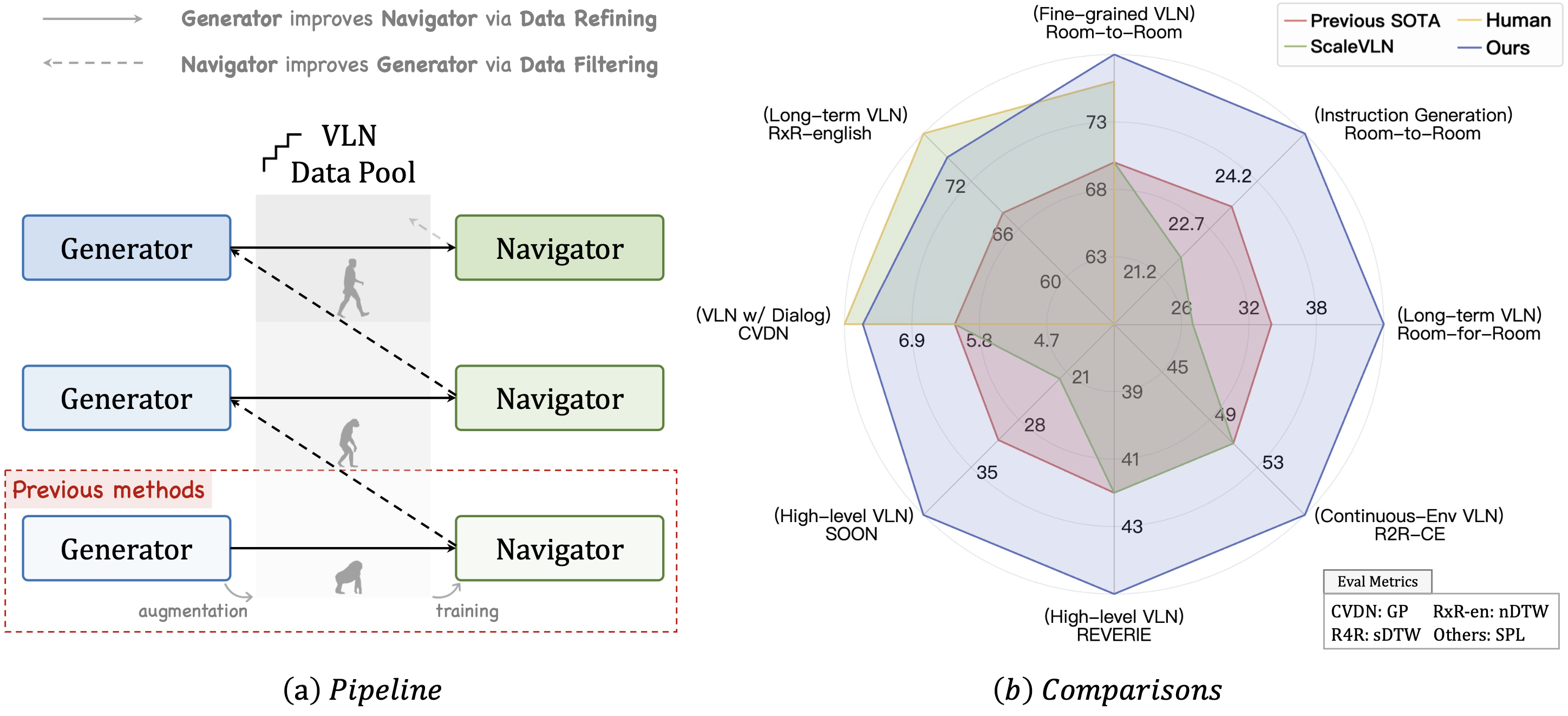 |
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel Zun Wang, Jialu Li, Yicong Hong, Songze Li, Kunchang Li, Shoubin Yu, Yi Wang, Yu Qiao,Yali Wang, Mohit Bansal, Limin Wang. ICLR, 2025 paper /code /bib |
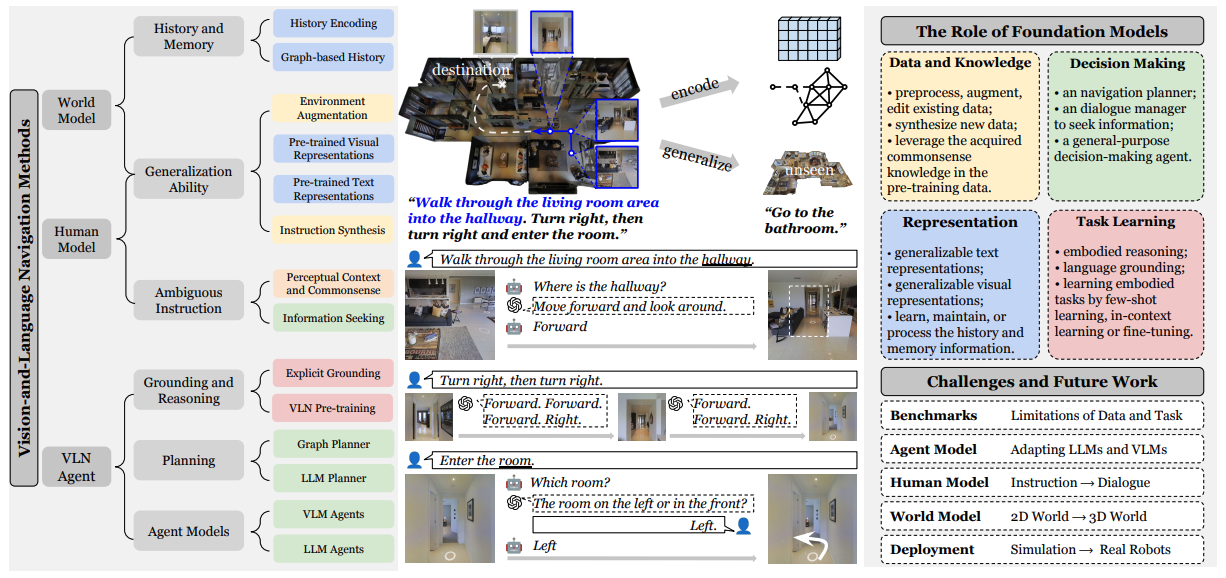 |
Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models Yue Zhang*, Ziqiao Ma*, Jialu Li*, Yanyuan Qiao*, Zun Wang*, Joyce Chai, Qi Wu, Mohit Bansal, Parisa Kordjamshidi TMLR paper |
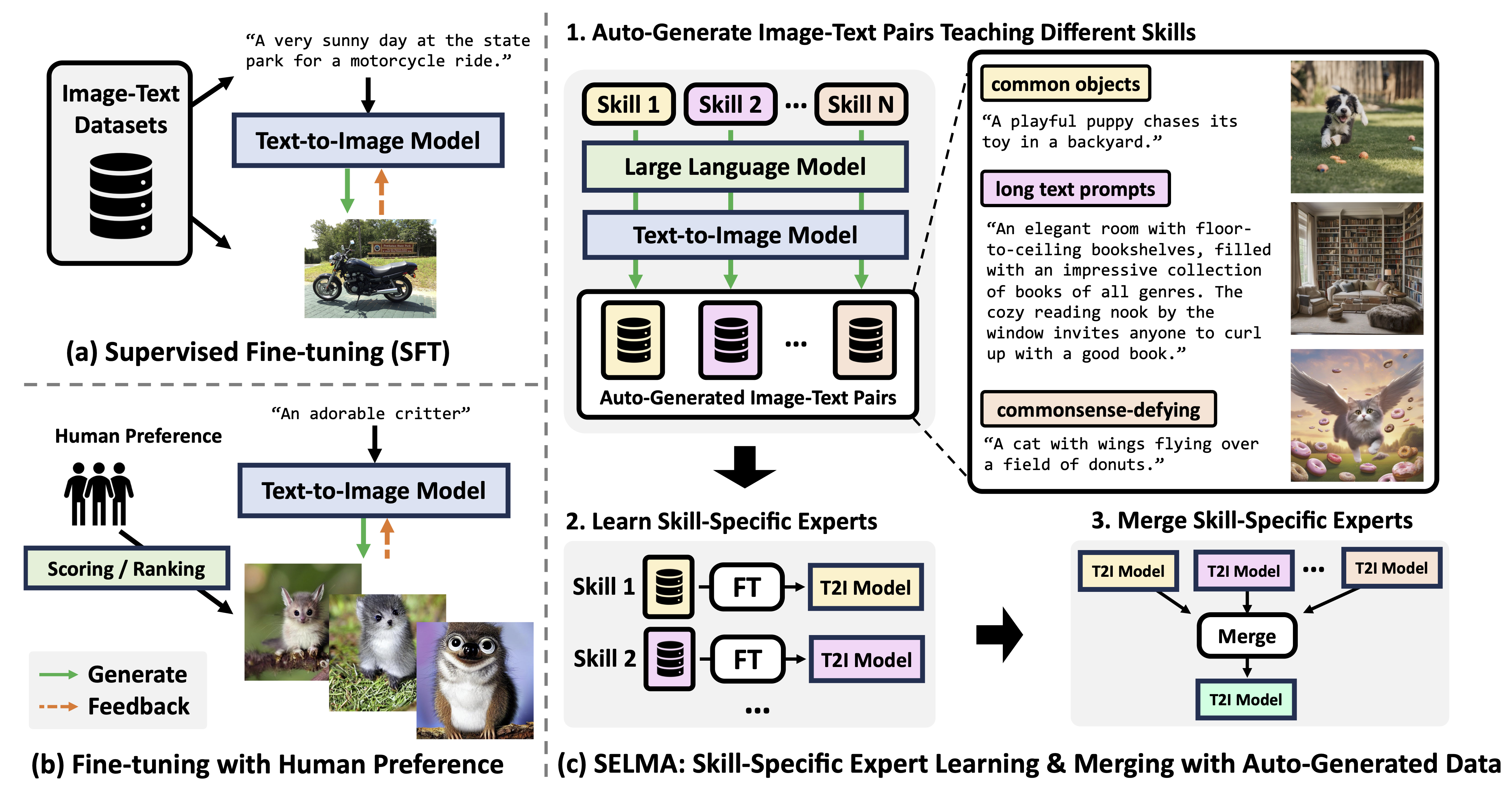 |
SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data Jialu Li*, Jaemin Cho*, Yi-Lin Sung, Jaehong Yoon, Mohit Bansal. NeurIPS, 2024 paper /code /bib /website |
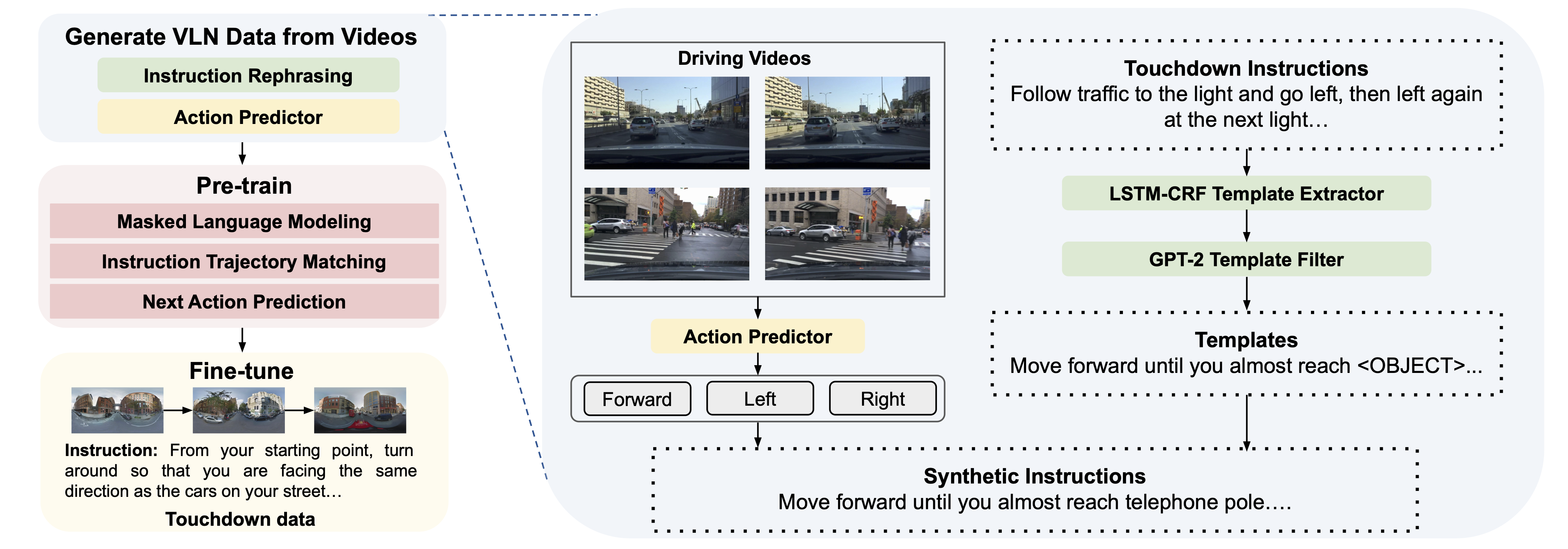 |
VLN-VIDEO: Utilizing Driving Videos for Outdoor Vision-and-Language Navigation Jialu Li, Aishwarya Padmakumar, Gaurav Sukhatme, Mohit Bansal. AAAI, 2024 paper |
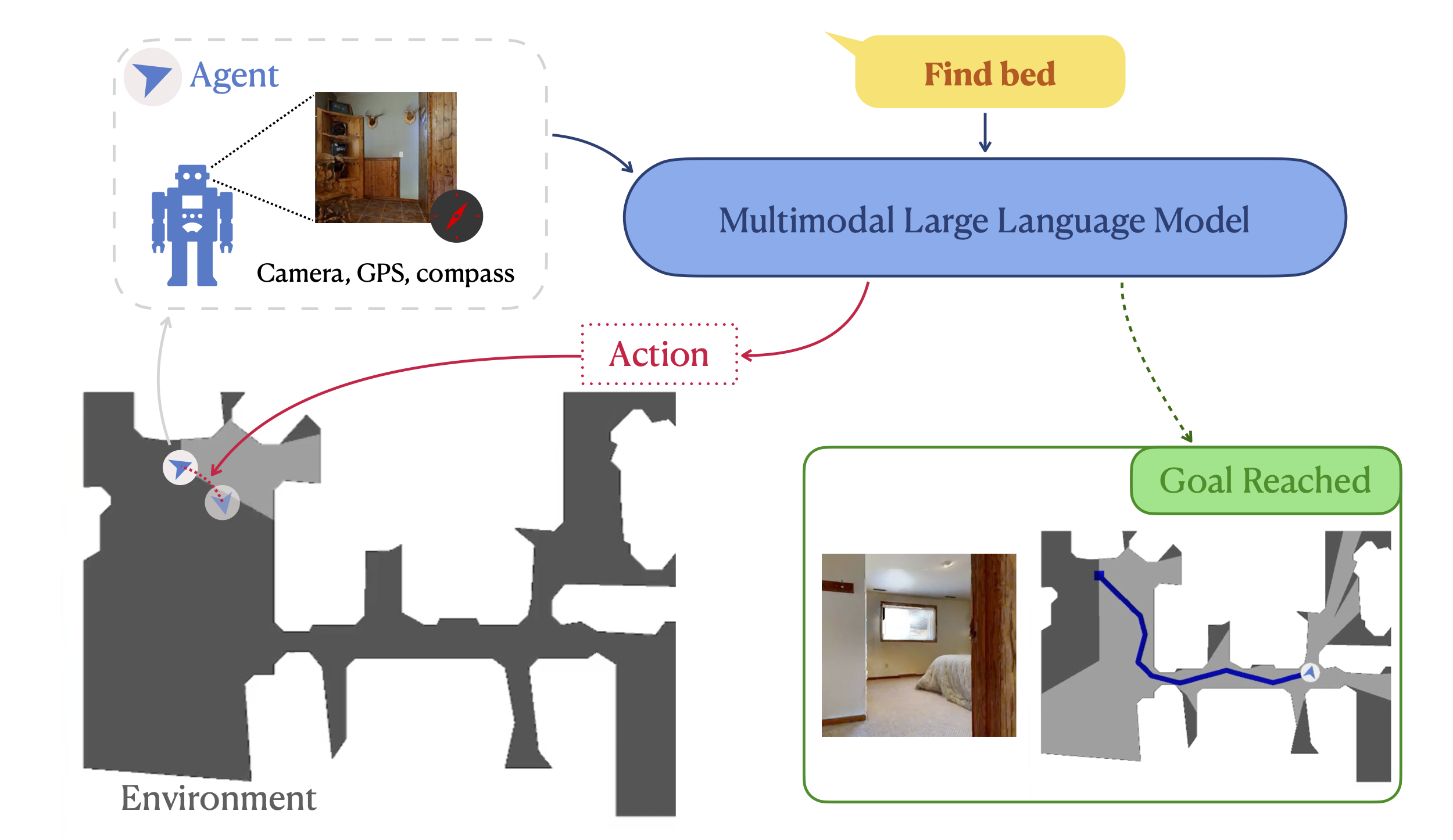 |
Multimodal large language model for visual navigation Yao-Hung Hubert Tsai, Vansh Dhar, Hugues Thomas, Jialu Li, Bowen Zhang, Jian Zhang Preprint paper |
| PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation Jialu Li, Mohit Bansal. NeurIPS, 2023 paper /code /bib /website | |
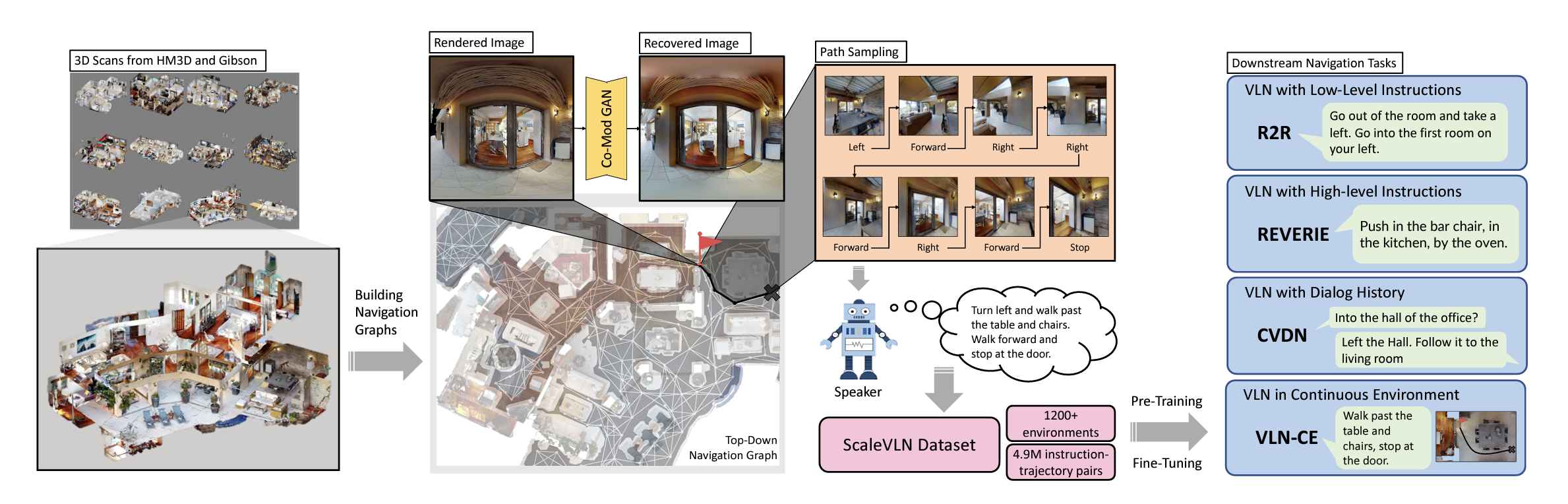 |
Scaling Data Generation in Vision-and-Language Navigation Zun Wang*, Jialu Li*, Yicong Hong*, Yi Wang, Qi Wu, Mohit Bansal,Stephen Gould, Hao Tan, Yu Qiao. ICCV, 2023, Oral Presentation paper /code /bib |
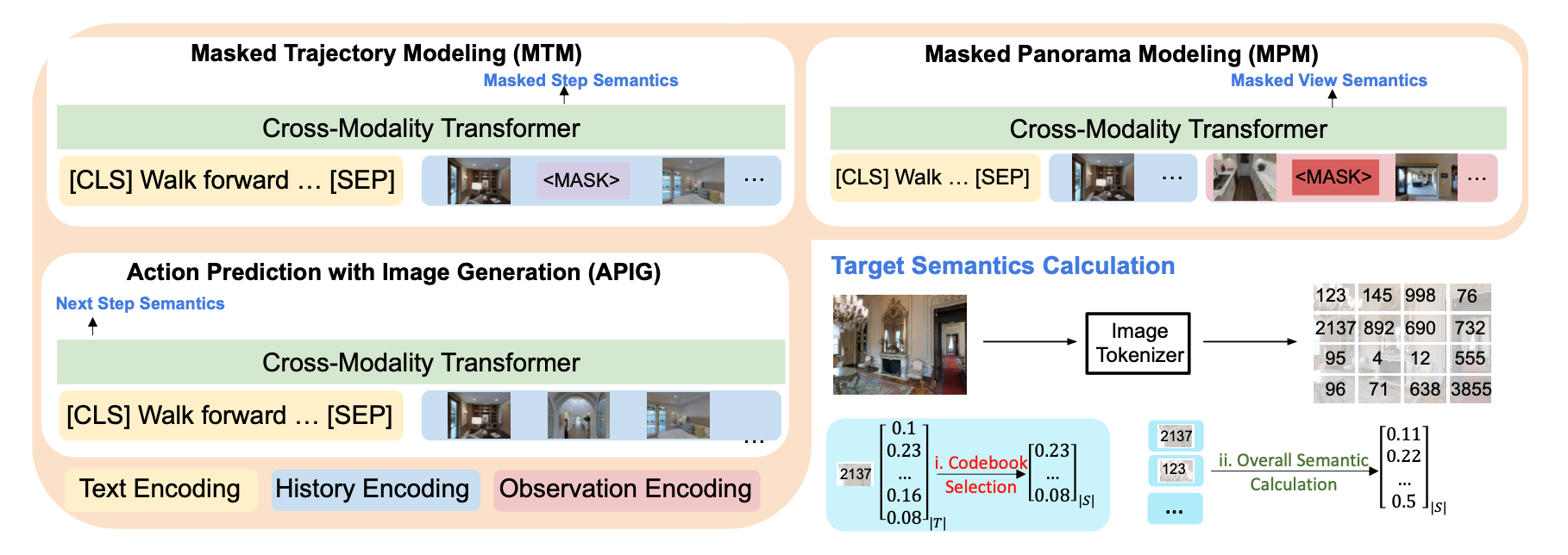 |
Improving Vision-and-Language Navigation by Generating Future-View Image Semantics Jialu Li, Mohit Bansal. CVPR, 2023 paper /code /bib /website |
| CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment Agnostic Representations Jialu Li, Hao Tan, Mohit Bansal. Findings of NAACL, 2022 paper /code /bib | |
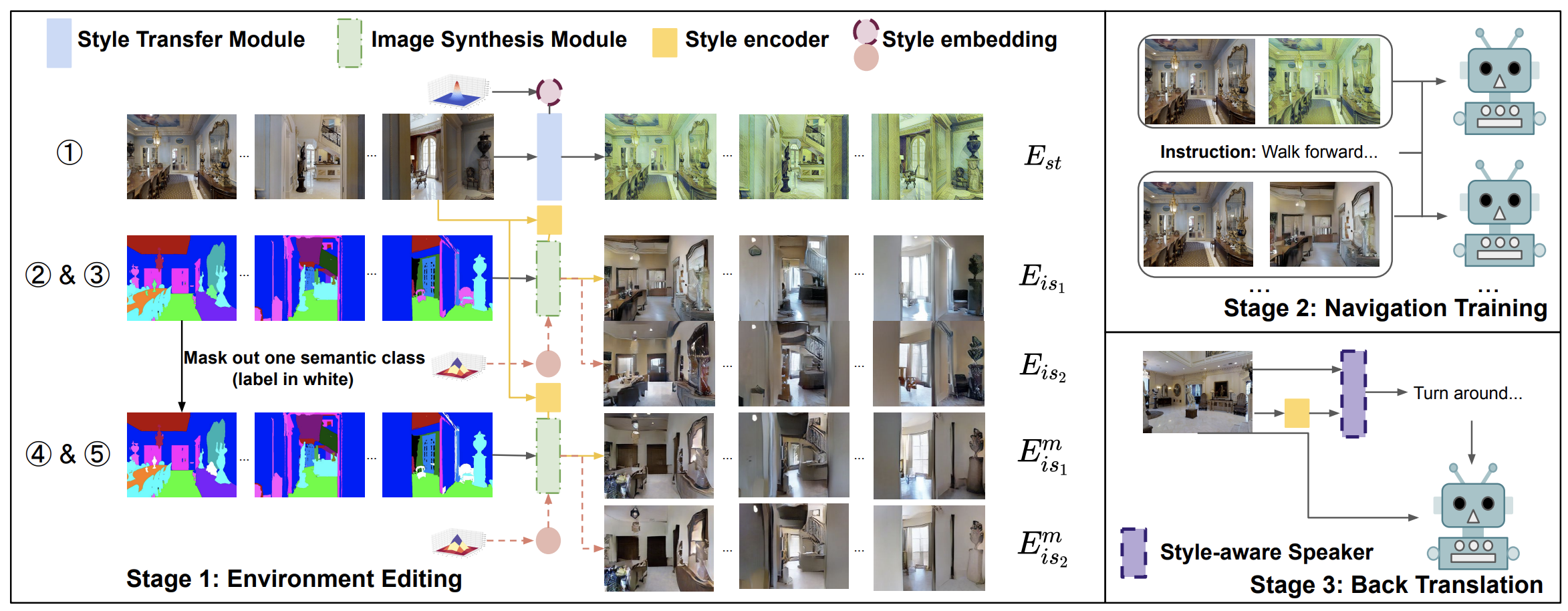 |
EnvEdit: Environment Editing for Vision-and-Language Navigation Jialu Li, Hao Tan, Mohit Bansal. CVPR, 2022 paper /code /bib |
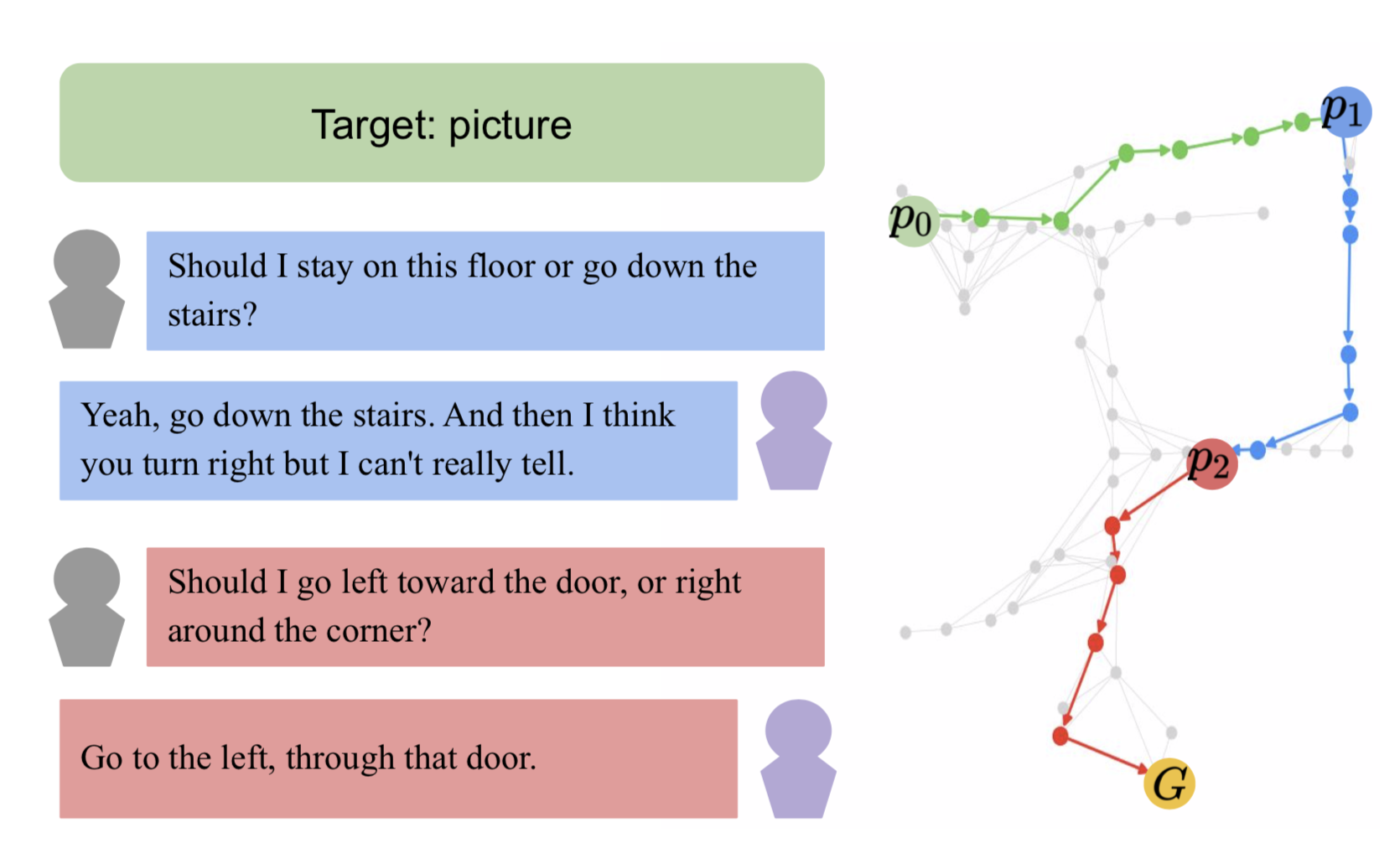 |
NDH-Full: Learning and Evaluating Navigational Agents on Full-Length Dialogue Hyounghun Kim, Jialu Li, Mohit Bansal. EMNLP, 2021 paper /code /bib |
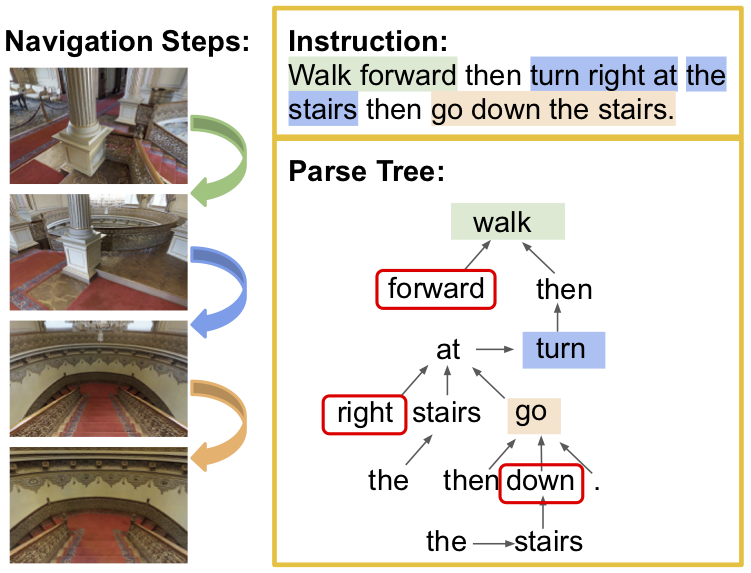 |
Improving Cross-Modal Alignment in Vision Language Navigation via Syntactic Information Jialu Li, Hao Tan, Mohit Bansal. NAACL, 2021 (short papers) paper /code /bib |
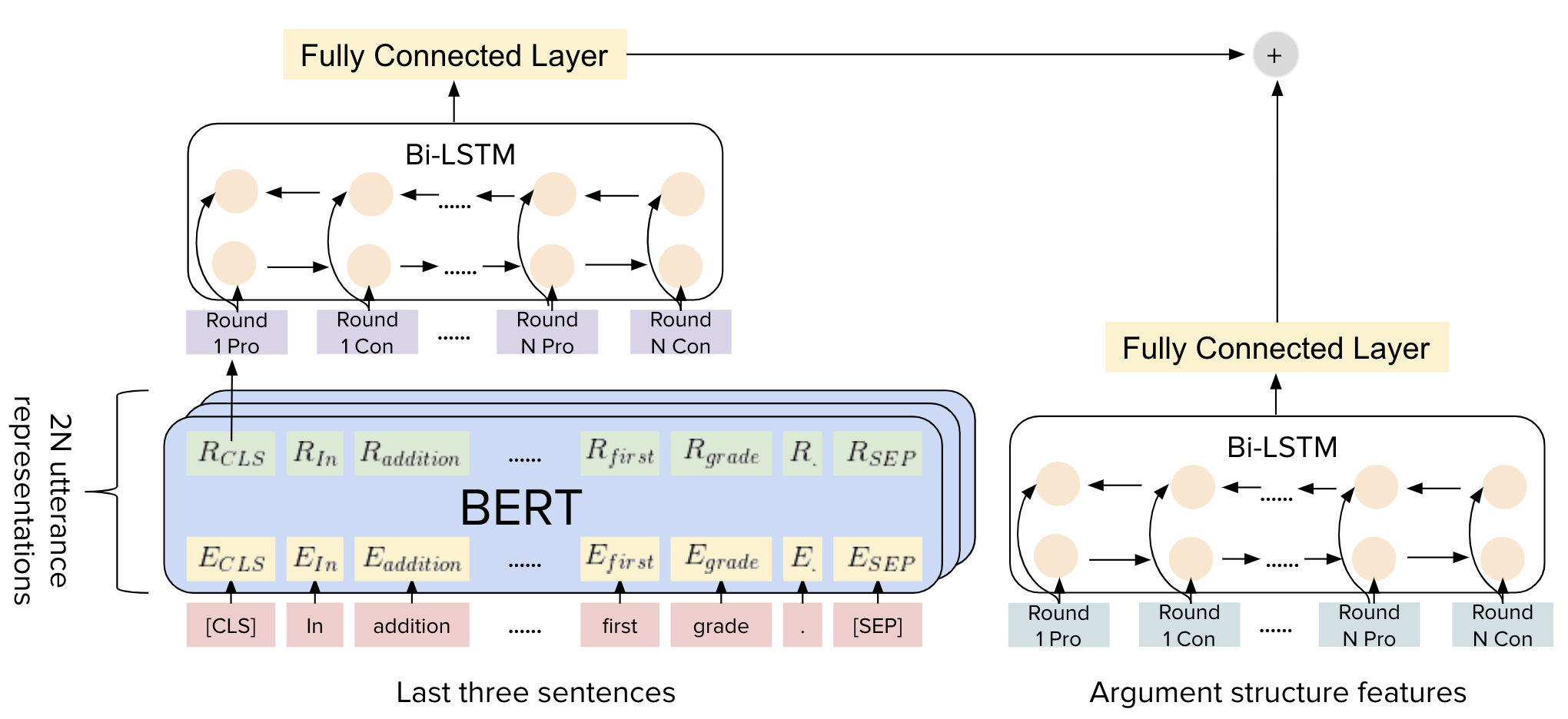 |
Exploring the Role of Argument Structure in Online Debate Persuasion Jialu Li, Esin Durmus, Claire Cardie. EMNLP, 2020 (short papers) paper /code /bib |
Teaching
- Introduction to Natural Language Processing, Cornell University. Fall 2019.
Professional Service
- Reviewer for ARR, ACL, EMNLP, NAACL, EACL.
- Reviewer for ACM MM, AAAI, CVPR, ICCV, ECCV, ICLR, NeurIPS, WACV, AISTATS.