SOCIAL MEDIA TITLE TAG (original) (raw)
Scaling Up Dynamic Human-Scene Interaction Modeling
1Institute for AI, Peking University 2National Key Lab of General AI, BIGAI 3School of Computer Science, CFCS, Peking University
4Beijing Institute of Technology * Indicates Equal Contribution ✉️ Indicates Corresponding Author CVPR 2024 (highlight)
Synthesized Motions of Our Method
Real-time Game Control
Synthesized Motions with objects dynamically involved
Synthesized Motions with objects dynamically involved
Diverse synthesized locomotion and interaction with object scenes
Natural collision avoidance
Natural collision avoidance
\
Motion synthesis starting from any pose
Demos of TRUMANS dataset
*Drag mouse to rotate & scroll wheel to zoom in/out
A Motion clip from TRUMANS dataset in a bedroom.
A Motion clip from TRUMANS dataset in a living room.
A Motion clip from TRUMANS dataset in a kitchen.
Features of TRUMANS Dataset
Replaceable objects
Replaceable background
Extensive annotations
Diverse HOI motions
Abstract
Confronting the challenges of data scarcity and advanced motion synthesis in human-scene interaction (HSI) modeling, we introduce the TRUMANS dataset alongside a novel HSI motion synthesis method. TRUMANS stands as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. It intricately captures whole-body human motions and part-level object dynamics, focusing on the realism of contact. This dataset is further scaled up by transforming physical environments into exact virtual models and applying extensive augmentations to appearance and motion for both humans and objects while maintaining interaction fidelity. Utilizing TRUMANS we devise a diffusion-based autoregressive model that efficiently generates HSI sequences of any length, taking into account both scene context and intended actions. In experiments, our approach shows remarkable zero-shot generalizability on a range of 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), producing motions that closely mimic original motion-captured sequences, as confirmed by quantitative experiments and human studies.
Motion Synthesis Method
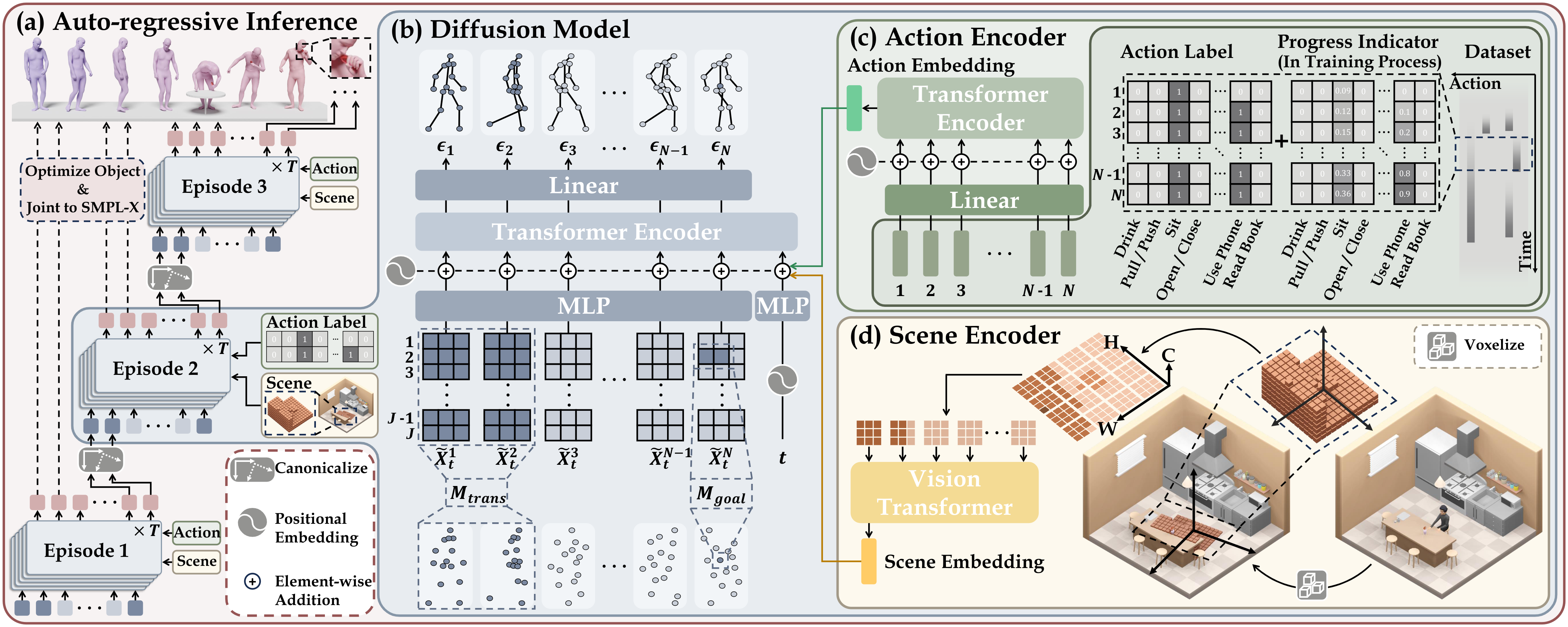
The overall architecture of our model. (a) Our model leverages an auto-regressive diffusion sampling strategy, whereby the long-sequence motion is sampled episode by episode. (b) The diffusion model incorporates DDPM with a transformer architecture, the frames of human joint being the input tokens. (c)(d) The action and scene conditions are encoded and forward to the first token.
BibTeX
@inproceedings{jiang2024scaling,
title={Scaling up dynamic human-scene interaction modeling},
author={Jiang, Nan and Zhang, Zhiyuan and Li, Hongjie and Ma, Xiaoxuan and Wang, Zan and Chen, Yixin and Liu, Tengyu and Zhu, Yixin and Huang, Siyuan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1737--1747},
year={2024}
}