I'm currently interested developing novel reinforcement learning algorithms that scale better to difficult problems, particularly involving large language models and interaction with humans.
Natural Language Actor-Critic: Scalable Off-Policy Learning in Language Space Joey Hong ,Kang Liu ,Zhan Ling ,Jiecao Chen ,Sergey Levine under submission , 2025 arXiv code website
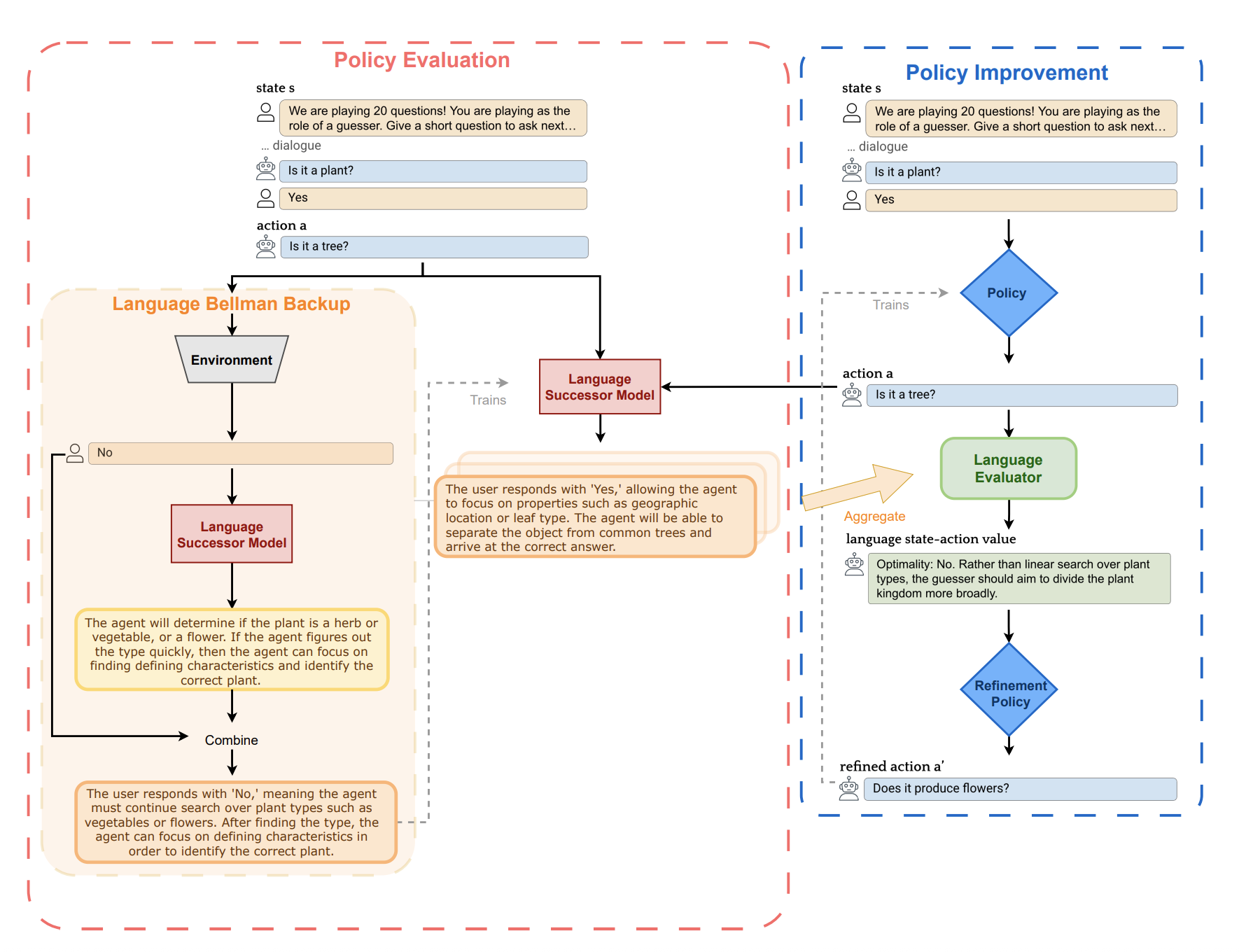
Planning without Search: Refining Frontier LLMs with Offline Goal-Conditioned RL Joey Hong ,Anca Dragan ,Sergey Levine NeurIPS , 2025 arXiv website
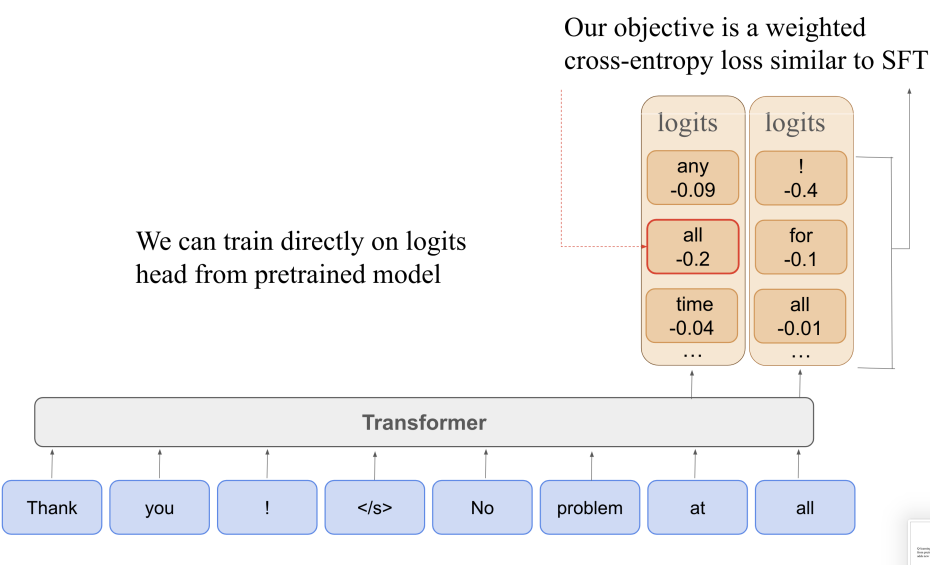
Q-SFT: Q-Learning for Language Models via Supervised Fine-Tuning Joey Hong ,Anca Dragan ,Sergey Levine ICLR , 2025 arXiv
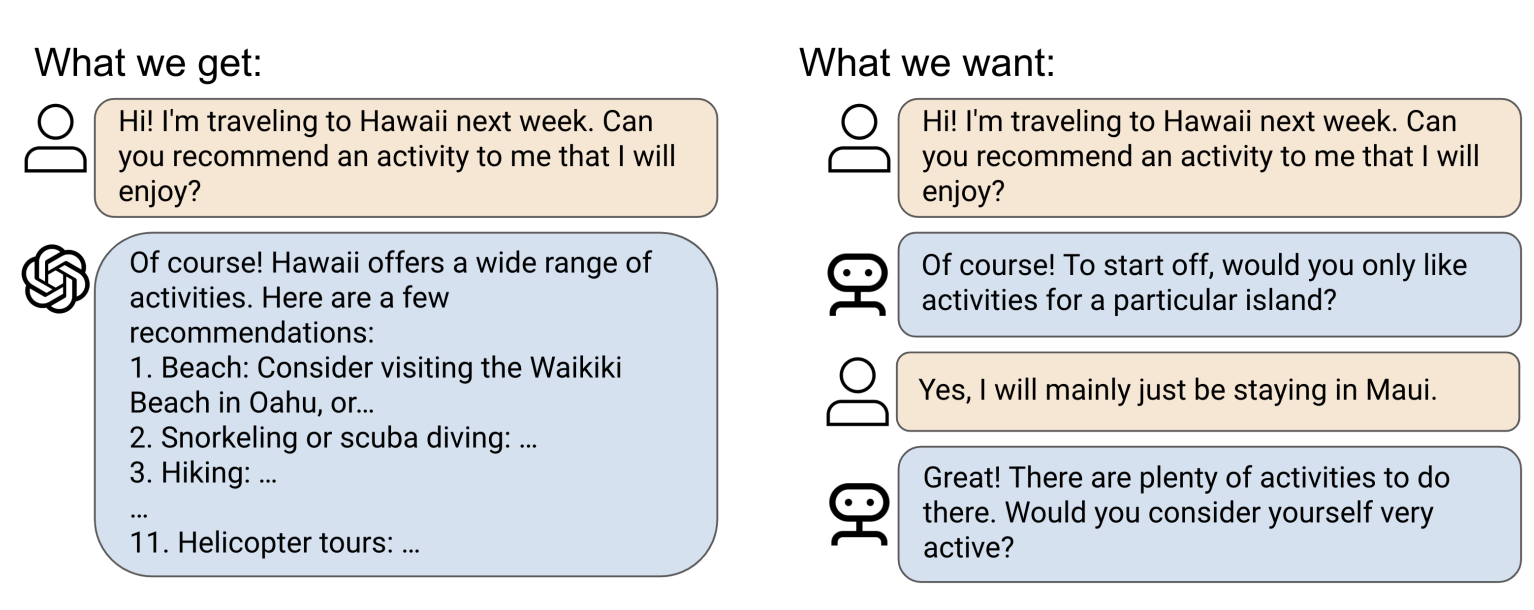
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations Joey Hong ,Sergey Levine ,Anca Dragan NeurIPS Foundation Models for Decision Making Workshop , 2024 arXiv ,slides
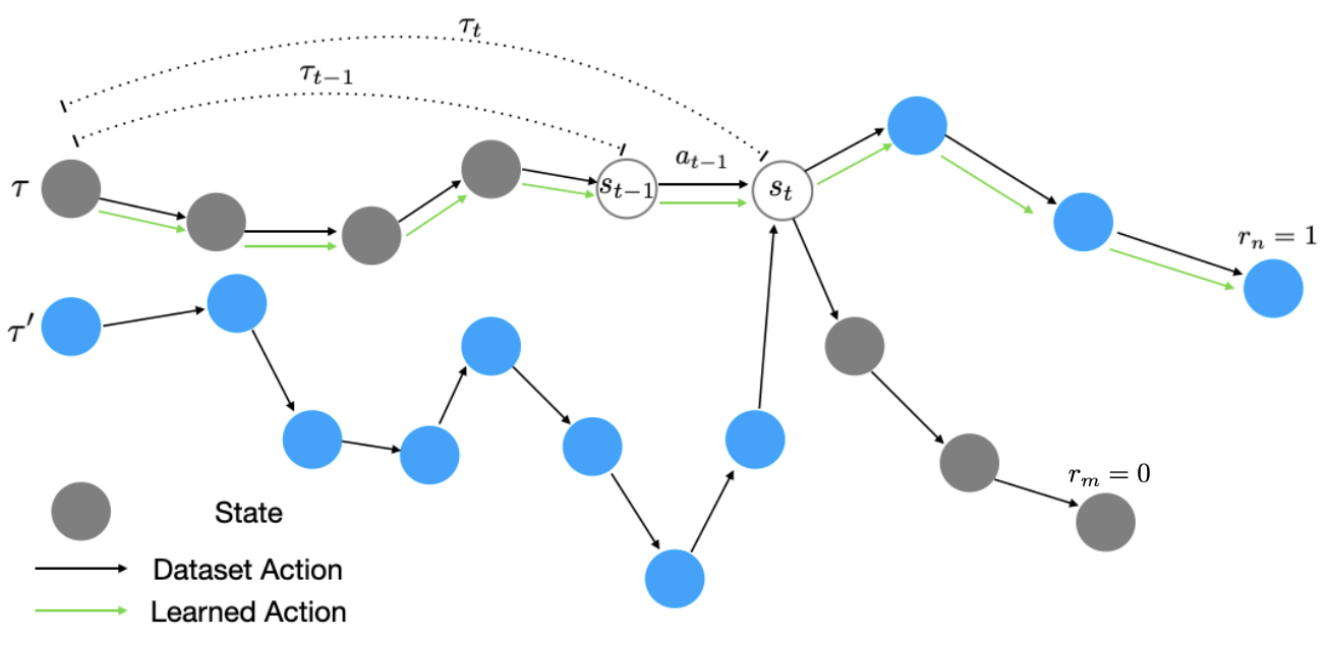
Offline RL with Observation Histories: Analyzing and Improving Sample Complexity Joey Hong ,Anca Dragan ,Sergey Levine ICLR , 2024 arXiv
Learning to Influence Human Behavior with Offline Reinforcement Learning Joey Hong ,Sergey Levine ,Anca Dragan NeurIPS , 2023 arXiv , website
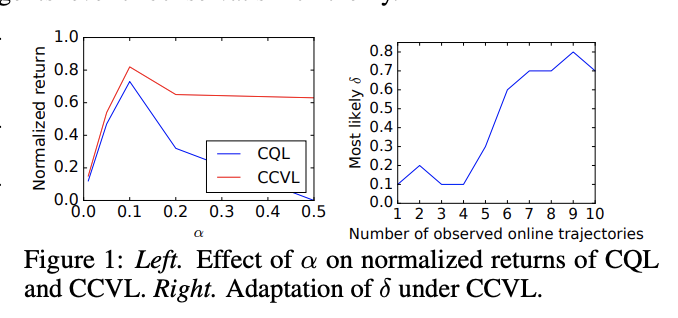
Confidence-Conditioned Value Functions for Offline Reinforcement Learning Joey Hong ,Aviral Kumar ,Sergey Levine ICLR , 2022 (oral) arXiv
On the Sensitivity of Reward Inference to Misspecified Human Models Joey Hong ,Kush Bhatia ,Anca Dragan ICLR , 2022 (oral) arXiv
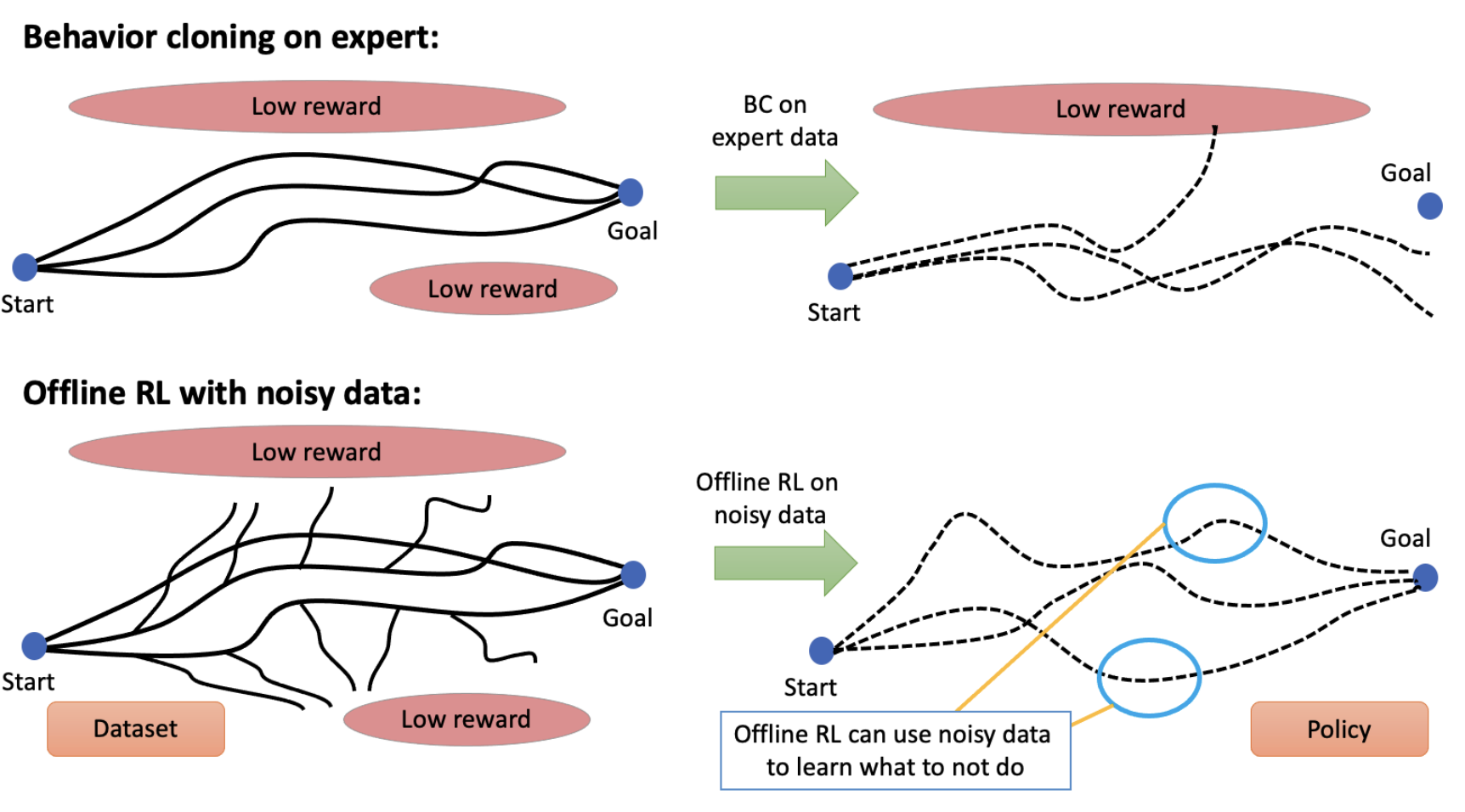
When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning? Aviral Kumar* ,Joey Hong* ,Anikait Singh ,Sergey Levine ICLR , 2021 arXiv ,blog