Ming Zhang - Fudan University (original) (raw)
👋 Hi, I'm Ming Zhang (张明), also known as DinoBro (恐龙哥) or DinoDoctor (恐龙博士). I am a third-year direct Ph.D. student at the FudanNLP Lab, School of Computer Science, Fudan University, co-advised by Prof. Qi Zhang, A.P. Tao Gui, and Prof. Xuanjing Huang.
🔬 My research focuses on Large Language Model Evaluation and Dialogue Systems. Recently, I have been particularly interested in Context Learning and AI for Academia.
🏢 I previously interned at ByteDance (2024.09 – 2025.09) and am currently interning at the Tencent Qingyun Program (2025.12 – Present).
📝 I serve as a Reviewer for AAAI, ACL ARR, ICLR, NeurIPS, and ICML, and as an Area Chair for ACL ARR.
Beyond research, my personal interests include:
🔭 I have been a lifelong astronomy enthusiast and served as President of the Fudan Astronomy Society during my undergraduate years.
⚽ I am a devoted fan of football — my all-time idol is Lionel Andrés Messi.
🎮 I served as Captain of the Fudan University League of Legends Varsity Team (Jungle), peaked at Challenger (最强王者) in S3 and S12, and my favorite champion lately is Gangplank.
📧 mingzhang23 [at] m [dot] fudan [dot] edu [dot] cn / konglongge [at] outlook [dot] com
💬 Please feel free to add me on WeChat: zanyingluan
🔥 News
- 2026.07 ✈️ Heading to ACL 2026 in San Diego, USA — see you there!
- 2026.05 📄 LLMEval-Logic is now available on arXiv!
- 2026.05 🎉 SciAgentGym accepted by ICML 2026!
- 2026.04 🌐 The official LLMEval Project Website is now live!
- 2026.04 🎉 LLMEval-Fair, VRPO, and Beyond Scaling accepted by ACL 2026 Main! Speech Reward and Muse accepted by ACL 2026 Findings!
- 2026.02 🎉 Thinking with Video accepted by CVPR 2026!
- 2026.02 📄 CL-bench is now available on arXiv!
- 2026.01 📄 OpenNovelty and TaxoBench are now available on arXiv!
- 2026.01 🎉 Game-RL accepted by ICLR 2026!
- 2025.11 🎉 Reasoning or Memorization and Speech Tokenizer accepted by AAAI 2026!
- 2025.12 ✈️ Attended NeurIPS 2025 in San Diego, USA.
- 2025.11 ✈️ Attended EMNLP 2025 in Suzhou, China.
- 2025.09 🎉 EvaLearn accepted by NeurIPS 2025!
- 2025.08 🎉 LLMEval-Med accepted by EMNLP 2025!
- 2025.05 🎉 PFDial accepted by ACL 2025!
- 2025.01 🎉 Our LLM Agent Survey published in Science China Information Sciences!
- 2024.12 ✈️ Attended CIPS-LMG 2024 in Jiaxing, China.
- 2024.11 ✈️ Attended EMNLP 2024 in Miami, USA.
- 2024.09 🎉 TransferTOD and MathTrap accepted by EMNLP 2024!
- 2024.07 🎉 Mousi accepted by COLM 2024!
- 2023.12 🎉 LLMEval accepted by AAAI 2024!
✈️ Conferences & Travels
🇺🇸
ACL 2026 Upcoming
San Diego, USA · Jul 2026
🇺🇸
NeurIPS 2025 Attended
San Diego, USA · Dec 2025
🇨🇳
EMNLP 2025 Attended
Suzhou, China · Nov 2025
🇨🇳
CIPS-LMG 2024 Attended
Jiaxing, China · Nov–Dec 2024
Hosted by Fudan University
🇺🇸
EMNLP 2024 Attended
Miami, USA · Nov 2024
⭐ Selected Works
* denotes co-first author, † denotes corresponding author.
Context Learning
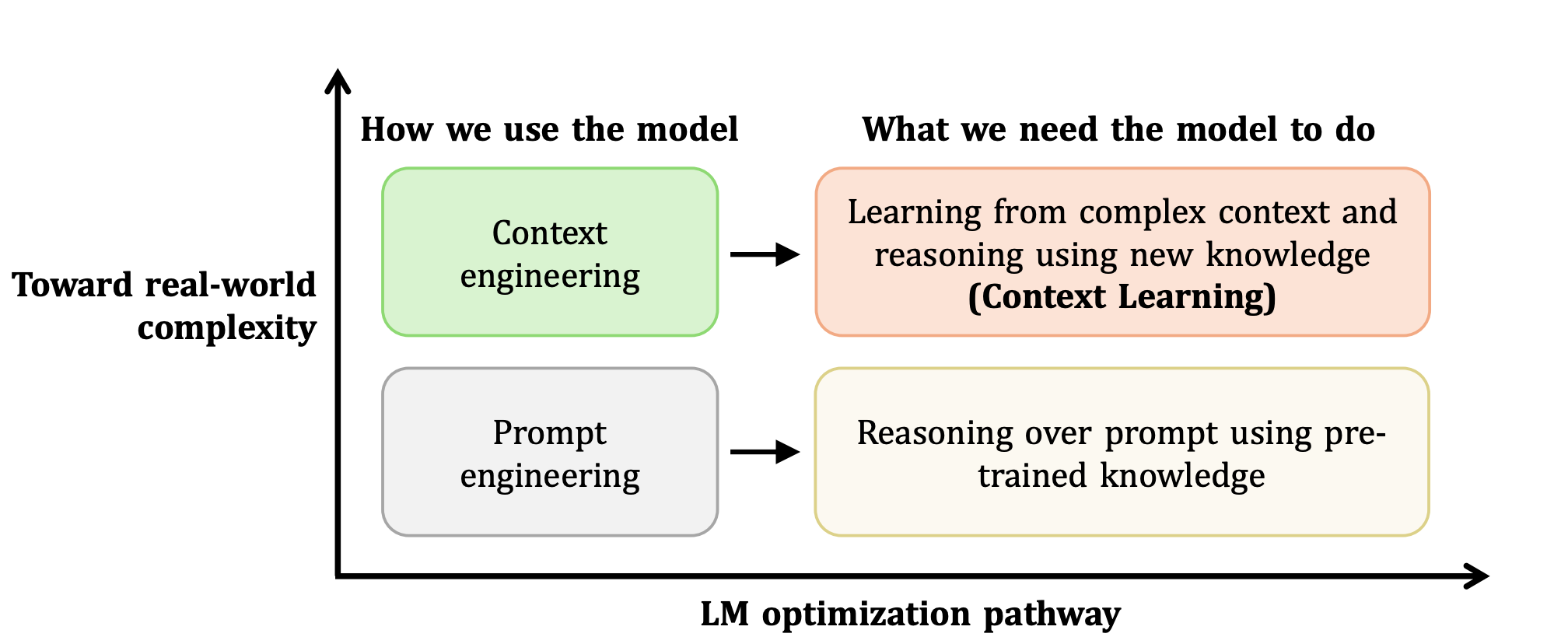
CL-bench: A Benchmark for Context Learning
Shihan Dou*, Ming Zhang*, Zhangyue Yin*, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, Huaibing Xie, Jianglu Hu, Shaolei Wang, Weichao Wang, Yanling Xiao, Yiting Liu, Zenan Xu, Zhen Guo, Pluto Zhou†, Tao Gui†, Zuxuan Wu, Xipeng Qiu, Qi Zhang, Xuanjing Huang, Yu-Gang Jiang, Di Wang, Shunyu Yao
A comprehensive benchmark for evaluating context learning capabilities of large language models, providing systematic assessment across diverse context-dependent tasks.
AI for Academia
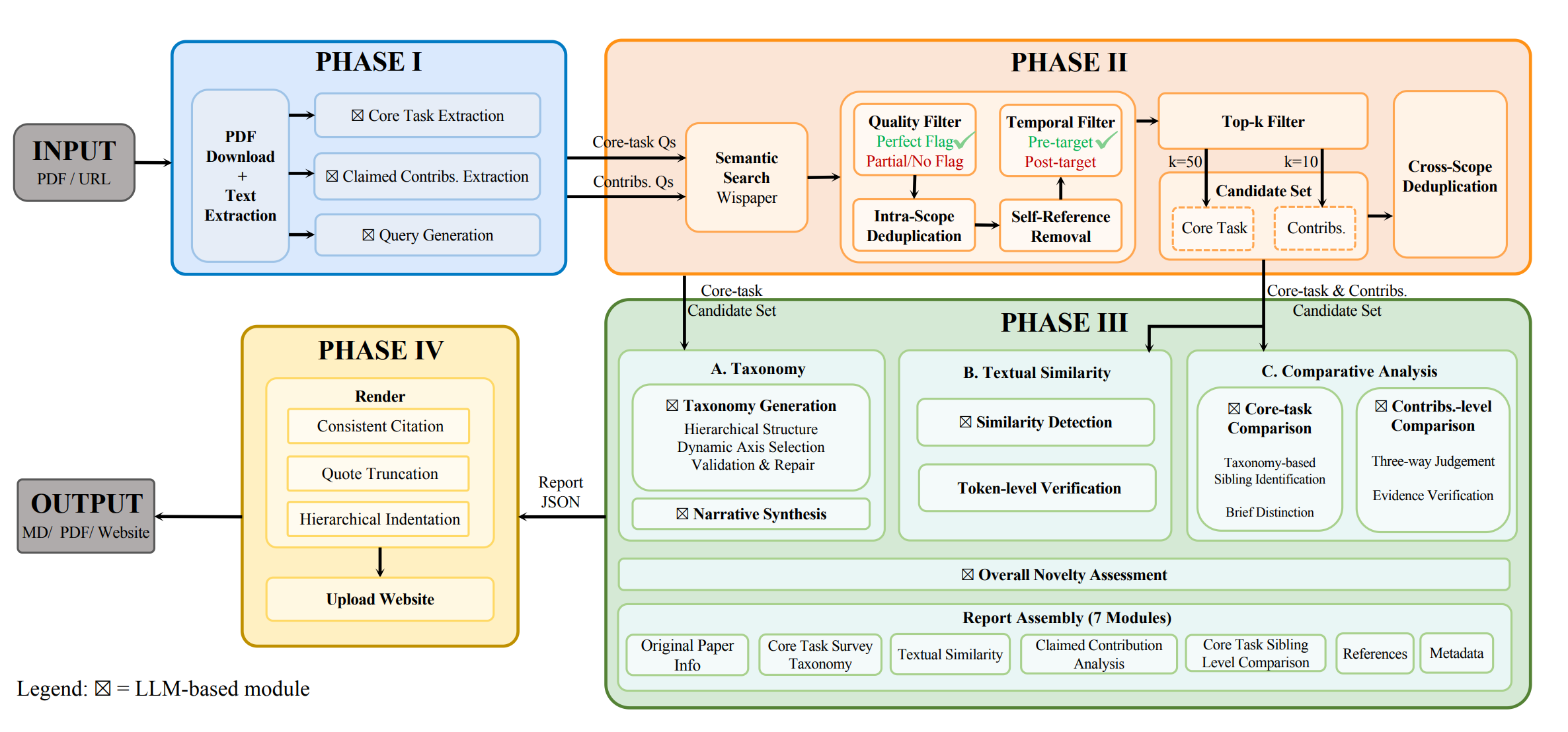
OpenNovelty: An LLM-Powered Agentic System for Verifiable Scholarly Novelty Assessment
Ming Zhang*†, Kexin Tan*, Yueyuan Huang*, Yujiong Shen, Chunchun Ma, Li Ju, Xinran Zhang, Yuhui Wang, Wenqing Jing, Jingyi Deng, Huayu Sha, Binze Hu, Jingqi Tong, Changhao Jiang, Yage Geng, Yuankai Ying, Yue Zhang, Zhangyue Yin, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang†, Xuanjing Huang
An LLM-powered agentic system that performs verifiable scholarly novelty assessment, automatically evaluating the originality of research ideas through systematic literature analysis.
LLM Evaluation
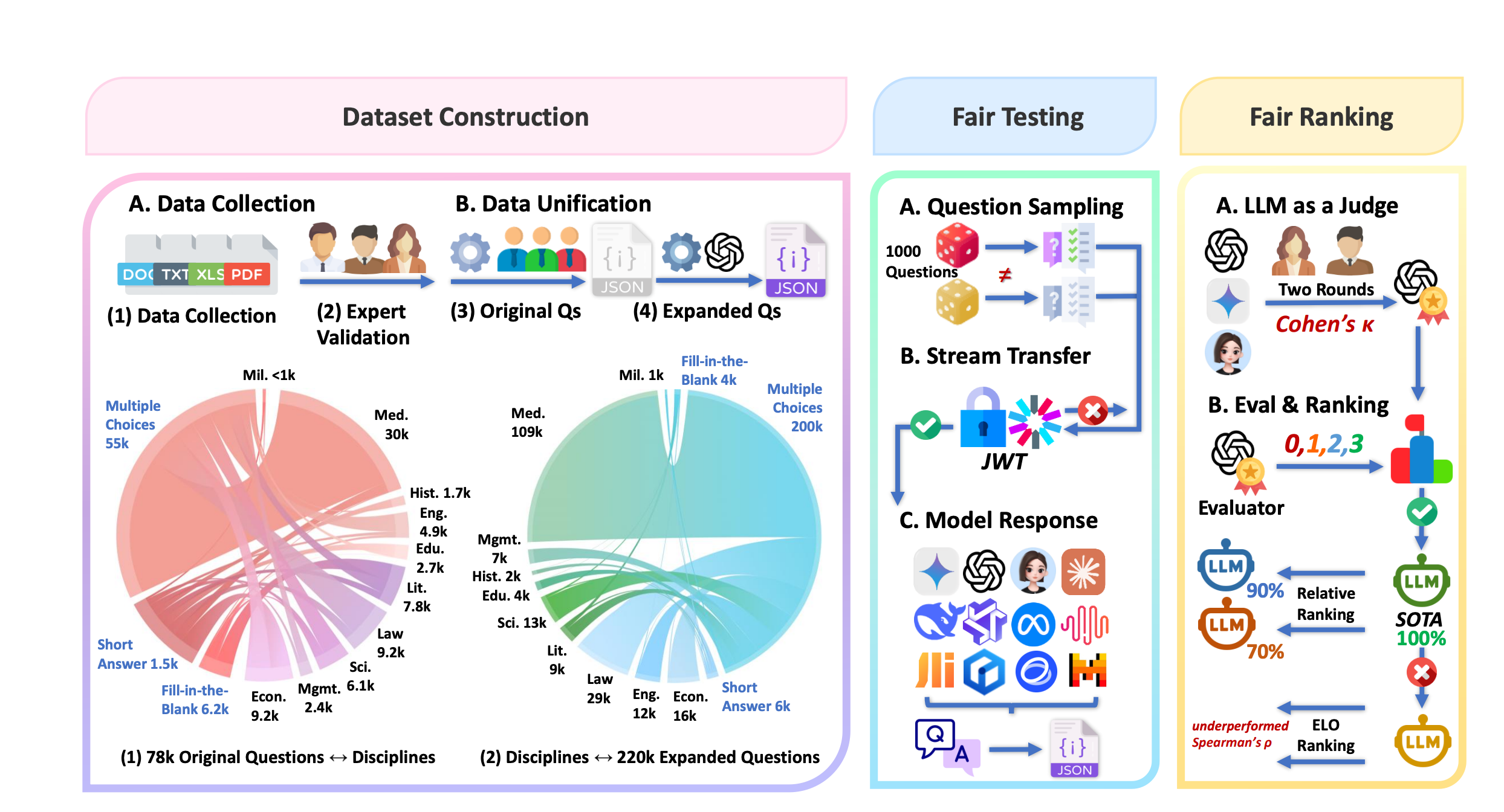
LLMEval-Fair: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models ACL 2026
Ming Zhang*†, Yujiong Shen*, Jingyi Deng*, Yuhui Wang*, Huayu Sha, Kexin Tan, Qiyuan Peng, Yue Zhang, Junzhe Wang, Shichun Liu, Yueyuan Huang, Jingqi Tong, Changhao Jiang, Yilong Wu, Zhihao Zhang, Mingqi Wu, Mingxu Chai, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang†, Xuanjing Huang
A large-scale longitudinal study on the robustness and fairness of LLM evaluation, addressing critical issues in benchmarking consistency and providing reliable evaluation methodologies.
LLM Evaluation
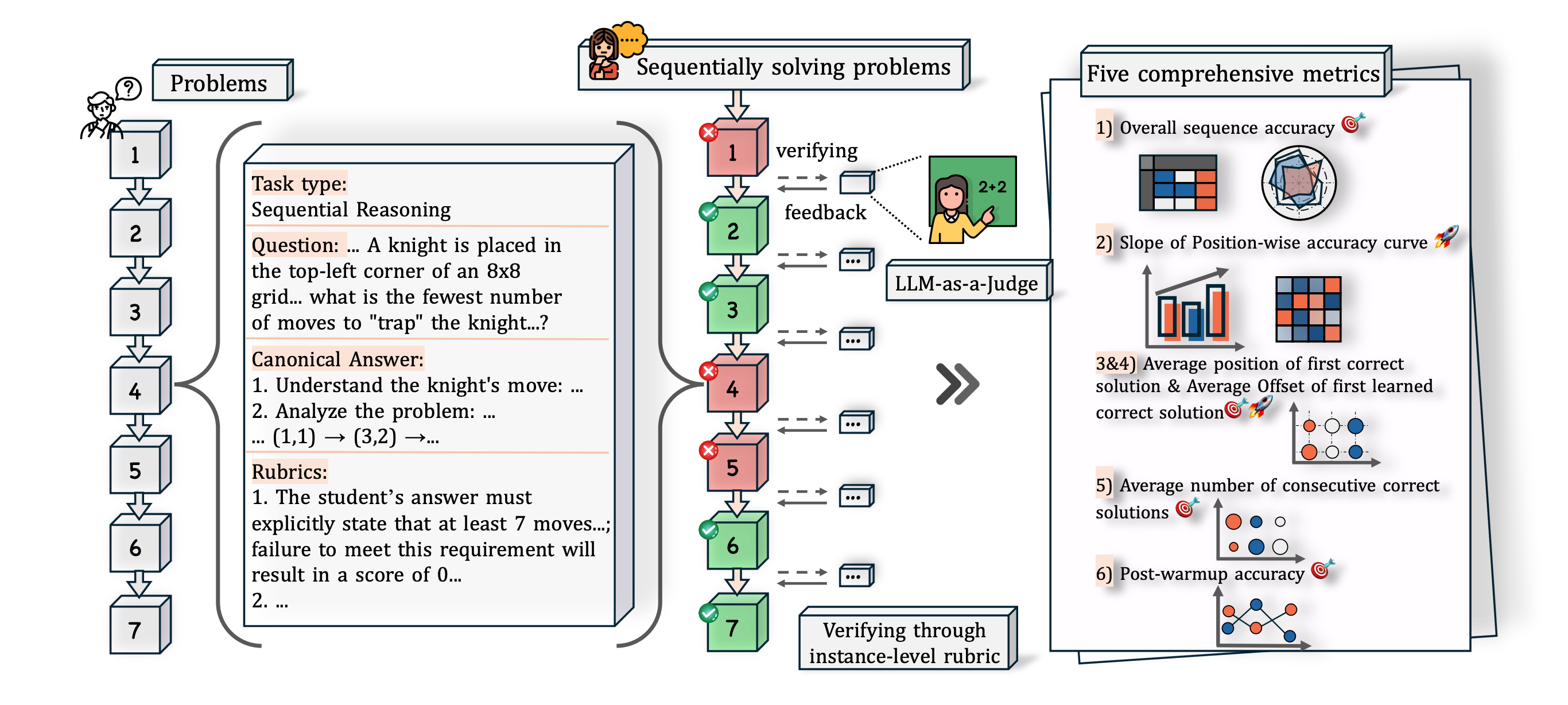
EvaLearn: Quantifying the Learning Capability and Efficiency of LLMs via Sequential Problem Solving NeurIPS 2025
Shihan Dou*, Ming Zhang*, Chenhao Huang, Jiayi Chen, Feng Chen, Shichun Liu, Yan Liu, Chenxiao Liu, Cheng Zhong, Zongzhang Zhang, Tao Gui†, Chao Xin, Chengzhi Wei, Lin Yan, Yonghui Wu, Qi Zhang†, Xuanjing Huang†
A novel framework for quantifying the learning capability and efficiency of large language models through sequential problem solving, providing new insights into how LLMs acquire and apply knowledge.
Agent Survey
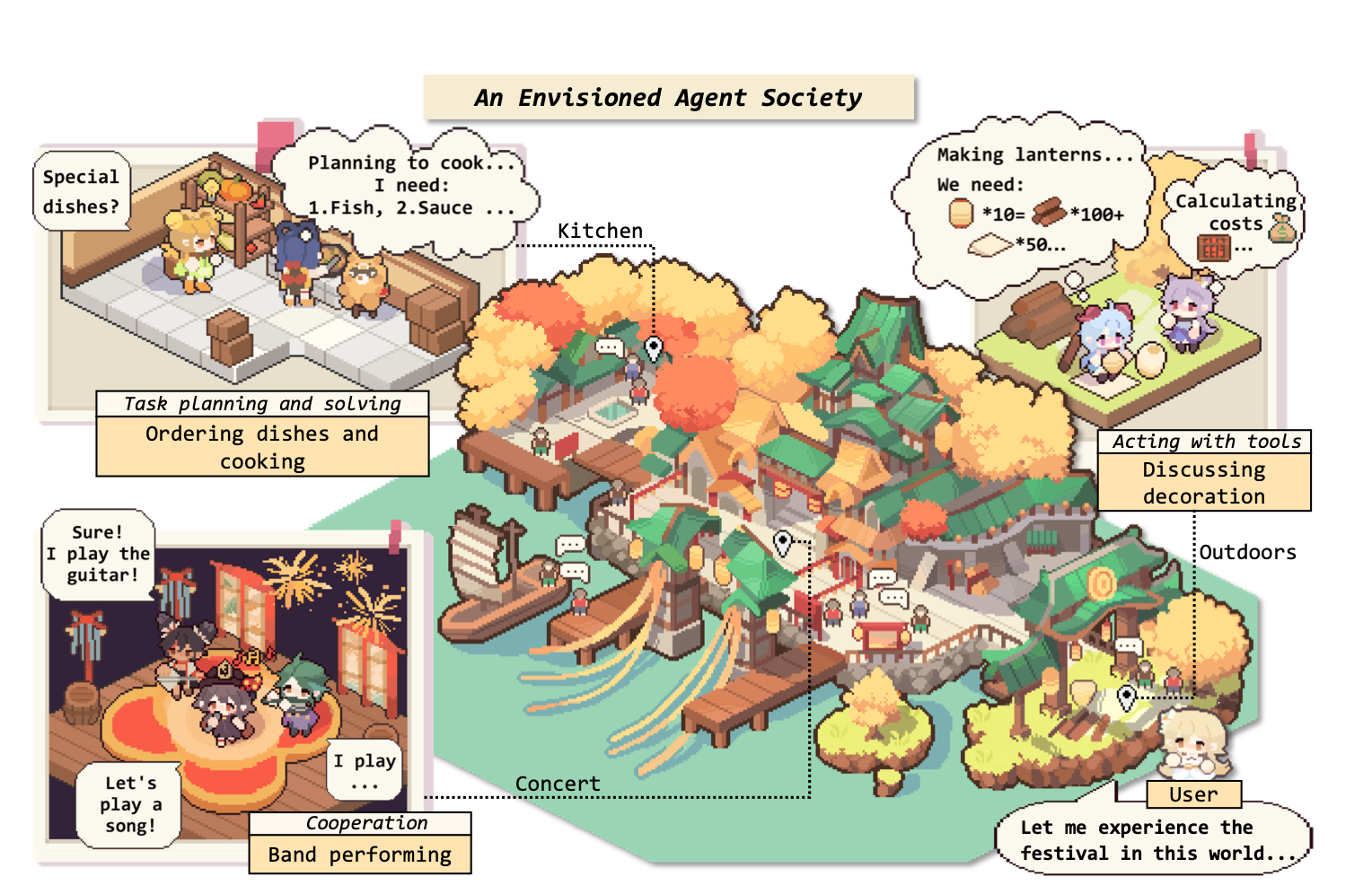
The Rise and Potential of Large Language Model Based Agents: A Survey SCIS
Zhiheng Xi*, Wenxiang Chen*, Xin Guo*, Wei He*, Yiwen Ding*, Boyang Hong*, Ming Zhang*, Junzhe Wang*, Senjie Jin*, Enyu Zhou*, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, Qi Zhang†, Tao Gui†
A comprehensive survey on LLM-based agents covering their construction, applications, and evaluation. This highly influential work provides a systematic overview of the emerging field of autonomous agents powered by large language models. Published in Science China Information Sciences.
📝 Publications
LLM Evaluation
LLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening arXiv 2026.05
Ming Zhang*, Qiyuan Peng*, Yinxi Wei, Yujiong Shen, Kexin Tan, Yuhui Wang, Zhenghao Xiang, Junjie Ye, Zhangyue Yin, Zhiheng Xi, Shihan Dou, Tao Gui, Maxm Pan†, Ruizhi Yang†, Qi Zhang†, Xuanjing Huang
From Scores to Preferences: Redefining MOS Benchmarking for Speech Quality Reward Modeling (MOS-RMBench) ACL 2026 Findings
Yifei Cao*, Changhao Jiang*, Jiabao Zhuang*, Jiajun Sun*, Ming Zhang, Zhiheng Xi, Hui Li, Shihan Dou, Yuran Wang, Yunke Zhang, Tao Ji, Tao Gui†, Qi Zhang, Xuanjing Huang
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm CVPR 2026
Jingqi Tong*, Yurong Mou*, Hangcheng Li*, Mingzhe Li*, Yongzhuo Yang*, Ming Zhang, Qiguang Chen, Tianyi Liang, Xiaomeng Hu, Yining Zheng, Xinchi Chen, Jun Zhao†, Xuanjing Huang, Xipeng Qiu†
Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning ICLR 2026
Jingqi Tong*, Jixin Tang*, Hangcheng Li*, Yurong Mou*, Ming Zhang, Jun Zhao†, Yanbo Wen, Fan Song, Jiahao Zhan, Yuyang Lu, Chaoran Tao, Zhiyuan Guo, Jizhou Yu, Tianhao Cheng, Changhao Jiang, Zhen Wang, Tao Liang, Zhihui Fei, Mingyang Wan, Guojun Ma, Weifeng Ge, Guanhua Chen, Tao Gui, Xipeng Qiu†, Qi Zhang†, Xuanjing Huang
Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination AAAI 2026
Mingqi Wu*, Zhihao Zhang*, Qiaole Dong*, Zhiheng Xi, Jun Zhao, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Huijie Lv, Ming Zhang, Yanwei Fu, Qin Liu, Songyang Zhang, Qi Zhang†
What Makes a Good Speech Tokenizer for LLM-Centric Speech Generation? A Systematic Study AAAI 2026
Xiaoran Fan*, Zhichao Sun*, Yangfan Gao*, Jingfei Xiong*, Hang Yan*, Yifei Cao, Jiajun Sun, Shuo Li, Zhihao Zhang, Zhiheng Xi, Yuhao Zhou, Senjie Jin, Changhao Jiang, Junjie Ye, Ming Zhang, Rui Zheng, Zhenhua Han, Yunke Zhang, Demei Yan, Shaokang Dong, Tao Ji†, Tao Gui†
CMDAR: A Chinese Multi-scene Dynamic Audio Reasoning Benchmark with Diverse Challenges arXiv 2025.09
Hui Li*, Changhao Jiang*, Hongyu Wang*, Ming Zhang, Jiajun Sun, Zhixiong Yang, Yifei Cao, Shihan Dou, Xiaoran Fan, Baoyu Fan, Tao Ji†, Tao Gui†, Qi Zhang†, Xuanjing Huang†
LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation EMNLP 2025 Findings
Ming Zhang*, Yujiong Shen*, Zelin Li*, Huayu Sha, Binze Hu, Yuhui Wang, Chenhao Huang, Shichun Liu, Jingqi Tong, Changhao Jiang, Mingxu Chai, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang†, Xuanjing Huang†
SpeechRole: A Large-Scale Dataset and Benchmark for Evaluating Speech Role-Playing Agents arXiv 2025.08
Changhao Jiang*†, Jiajun Sun*, Yifei Cao*, Jiabao Zhuang*, Hui Li, Xiaoran Fan, Ming Zhang, Junjie Ye, Shihan Dou, Zhiheng Xi, Jingqi Tong, Yilong Wu, Baoyu Fan, Tao Ji†, Tao Gui†, Qi Zhang, Xuanjing Huang
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning EMNLP 2024 Main
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities arXiv 2024.01
Chaochao Lu, Chen Qian, Guodong Zheng, Hongxing Fan, Hongzhi Gao, Jie Zhang, Jing Shao, Jingyi Deng, Jinlan Fu, Kexin Huang, Kunchang Li, Lijun Li, Limin Wang, Lu Sheng, Meiqi Chen, Ming Zhang, Qibing Ren, Sirui Chen, Tao Gui, Wanli Ouyang, Yali Wang, Yan Teng, Yaru Wang, Yi Wang, Yinan He, Yingchun Wang, Yixu Wang, Yongting Zhang, Yu Qiao, Yujiong Shen, Yurong Mou, Yuxi Chen, Zaibin Zhang, Zhelun Shi, Zhenfei Yin, Zhipin Wang
(Alphabetical order. Main contributor of text and code modalities.)
LLMEval: A Preliminary Study on How to Evaluate Large Language Models AAAI 2024
Yue Zhang*, Ming Zhang*, Haipeng Yuan, Shichun Liu, Yongyao Shi, Tao Gui, Qi Zhang†, Xuanjing Huang
AI for Academia
SciAgentGym: Benchmarking Multi-Step Scientific Tool-use in LLM Agents ICML 2026
Yujiong Shen*, Yajie Yang*, Zhiheng Xi*, Binze Hu, Huayu Sha, Jiazheng Zhang, Qiyuan Peng, Junlin Shang, Jixuan Huang, Yutao Fan, Jingqi Tong, Shihan Dou, Ming Zhang, Lei Bai, Zhenfei Yin†, Tao Gui†, Xingjun Ma, Qi Zhang, Xuanjing Huang†, Yu-Gang Jiang
Can Deep Research Agents Retrieve and Organize? Evaluating the Synthesis Gap with Expert Taxonomies arXiv 2026.01
Ming Zhang*†, Jiabao Zhuang*, Wenqing Jing*, Kexin Tan*, Ziyu Kong, Jingyi Deng, Yujiong Shen, Yuhang Zhao, Ning Luo, Renzhe Zheng, Jiahui Lin, Mingqi Wu, Long Ma, Shihan Dou, Tao Gui, Qi Zhang†, Xuanjing Huang
WisPaper: Your AI Scholar Search Engine arXiv 2025.12
Li Ju*, Jun Zhao*, Mingxu Chai, Ziyu Shen, Xiangyang Wang, Yage Geng, Chunchun Ma, Hao Peng, Guangbin Li, Tao Li, Chengyong Liao, Fu Wang, Xiaolong Wang, Junshen Chen, Rui Gong, Shijia Liang, Feiyan Li, Ming Zhang, Kexin Tan, Jujie Ye, Zhiheng Xi, Shihan Dou, Tao Gui, Yuankai Ying, Yang Shi, Yue Zhang, Qi Zhang†
Dialogue Systems
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts ACL 2025 Findings
Ming Zhang*, Yuhui Wang*, Yujiong Shen*, Tingyi Yang, Changhao Jiang, Yilong Wu, Shihan Dou, Qinhao Chen, Zhiheng Xi, Zhihao Zhang, Yi Dong, Zhen Wang, Zhihui Fei, Mingyang Wan, Tao Liang, Guojun Ma, Qi Zhang†, Tao Gui, Xuanjing Huang
TransferTOD: A Generalizable Chinese Multi-domain Task-oriented Dialogue System with Transfer Capabilities EMNLP 2024 Main
Ming Zhang*, Caishuang Huang*, Yilong Wu*, Shichun Liu, Huiyuan Zheng, Yurui Dong, Yujiong Shen, Shihan Dou, Jun Zhao, Junjie Ye, Qi Zhang†, Tao Gui, Xuanjing Huang
Others
Beyond Scaling: Measuring and Predicting the Upper Bound of Knowledge Retention in Language Model Pre-Training ACL 2026 Main
Changhao Jiang*†, Ming Zhang*, Yifei Cao*, Junjie Ye, Xiaoran Fan, Shihan Dou, Zhiheng Xi, Jiajun Sun, Yi Dong, Yujiong Shen, Jingqi Tong, Baoyu Fan, Tao Gui, Qi Zhang†, Xuanjing Huang
VRPO: Rethinking Value Modeling for Robust RL Training under Noisy Supervision ACL 2026 Main
Dingwei Zhu*, Shihan Dou*, Zhiheng Xi*, Senjie Jin, Guoqiang Zhang, Jiazheng Zhang, Junjie Ye, Mingxu Chai, Enyu Zhou, Ming Zhang, Caishuang Huang, Yunke Zhang, Yuran Wang, Tao Gui†
Muse: Towards Reproducible Long-Form Song Generation with Fine-Grained Style Control ACL 2026 Findings
Changhao Jiang*†, Jiahao Chen*, Zhenghao Xiang*, Zhixiong Yang*, Hanchen Wang*, Jiabao Zhuang*, Xinmeng Che, Jiajun Sun, Hui Li, Yifei Cao, Shihan Dou, Ming Zhang, Junjie Ye, Tao Ji†, Tao Gui†, Qi Zhang, Xuanjing Huang
What Is Wrong with Your Code Generated by Large Language Models? An Extensive Study SCIS 2025
Shihan Dou*, Haoxiang Jia*, Shenxi Wu, Huiyuan Zheng, Muling Wu, Yunbo Tao, Ming Zhang, Mingxu Chai, Jessica Fan, Zhiheng Xi, Rui Zheng, Yueming Wu, Ming Wen†, Tao Gui†, Qi Zhang, Xipeng Qiu, Xuanjing Huang†
Mousi: Poly-Visual-Expert Vision-Language Models COLM 2024
Xiaoran Fan*, Tao Ji*, Changhao Jiang*, Shuo Li*, Senjie Jin*, Sirui Song, Junke Wang, Boyang Hong, Lu Chen, Guodong Zheng, Ming Zhang, Caishuang Huang, Rui Zheng, Zhiheng Xi, Yuhao Zhou, Shihan Dou, Junjie Ye, Hang Yan, Tao Gui†, Qi Zhang†, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang