Identification of a novel non-coding RNA, MIAT, that confers risk of myocardial infarction (original) (raw)
Abstract
Through a large-scale case-control association study using 52,608 haplotype-based single nucleotide polymorphism (SNP) markers, we identified a susceptible locus for myocardial infarction (MI) on chromosome 22q12.1. Following linkage disequilibrium (LD) mapping, haplotype analyses revealed that six SNPs in this locus, all of which were in complete LD, showed markedly significant association with MI (χ 2=25.27, _P_=0.0000005; comparison of allele frequency, 3,435 affected individuals versus 3,774 controls, in the case of intron 1 5,338 C>T; rs2331291). Within this locus, we isolated a complete cDNA of a novel gene, designated myocardial infarction associated transcript (MIAT). MIAT has five exons, and in vitro translation assay showed that MIAT did not encode any translational product, indicating that this is likely to be a functional RNA. In vitro functional analyses revealed that the minor variant of one SNP in exon 5 increased transcriptional level of the novel gene. Moreover, unidentified nuclear protein(s) bound more intensely to risk allele than non-risk allele. These results indicate that the altered expression of MIAT by the SNP may play some role in the pathogenesis of MI.
Similar content being viewed by others
Introduction
Coronary artery diseases (CAD) including myocardial infarction (MI) have been the major cause of mortality and morbidity among late-onset diseases in many industrialized countries with a Western lifestyle (Breslow 1997; Braunwald 1997). MI often occurs without any preceding clinical signs, and is followed by severe complications, especially ventricular fibrillation and cardiac rupture which result in sudden death. Although recent advances in the treatment and diagnosis of MI have improved the quality of life for MI patients, its morbidity is still high.
Epidemiological studies revealed a variety of coronary risk factors, including type 2 diabetes mellitus, hypercholesterolemia, hypertension, and obesity. There are also studies reporting a genetic factor of this disorder; one reported first-degree relatives of patients who have had an acute MI prior to age 55 years have 2–7 times higher risk of MI (Lusis et al. 2004). A twin study indicated an eight-fold increase in risk of death from MI when a first twin dies of MI before age 55 years (Marenberg et al. 1994). In this context, common genetic variants are considered to contribute to genetic risks of common diseases (Lander 1996; Risch and Merikangas 1996; Collins et al. 1997).
To date, various genetic variants that confer susceptibility to MI have been indicated to be present on several chromosomal loci through linkage analyses or case-control association studies using single nucleotide polymorphism (SNP) (Topol et al. 2001; Yamada et al. 2002; Ozaki et al. 2002, 2004, 2006; Stenina et al. 2003; Helgadottir et al. 2004). Case-control association study by means of genome-wide SNP analysis is one of the most powerful approaches to identify genetic variants susceptibility to common diseases.
We report here identification of SNPs in myocardial infarction associated transcript (MIAT) that were associated with MI through our comprehensive SNP association study. We also demonstrated the possible transcriptional effect of this variation on the expression level of MIAT.
Materials and methods
DNA samples
This study included 3,464 Japanese individuals with myocardial infarction who were referred to Osaka Acute Coronary Insufficiency Study Group, which involved the cardiovascular units of 25 hospitals in Osaka. The diagnosis of definite myocardial infarction has been previously described (Ohnishi et al. 2000; Ozaki et al. 2002). The control individuals consisted of 3,819 members of the general population who were recruited through several medical institutes in Japan. DNAs were prepared from these samples according to standard protocols. All individuals were Japanese, gave written informed consent to participate in the study, or their parents gave them when they were under 20 years old, according to the process approved by the relevant Ethical Committee at SNP Research Center, The Institute of Physical and Chemical Research (RIKEN) Yokohama.
SNP discovery and genotyping
Protocols for PCR primers, PCR experiments, DNA extraction, DNA sequencing and genotyping of SNPs have been previously described (Iida et al. 2001). For SNP discovery, genomic DNAs from 24 Japanese individuals were used, and direct sequencing was performed using capillary sequencer (ABI3700; Applied Biosystems, Foster City, Calif., USA).
Statistical analysis
We assessed association and Hardy–Weinberg equilibrium by χ 2-test (Yamada et al. 2001; Ozaki et al. 2002). Haplotype block and haplotype frequencies were estimated using SNPAlyze software (DYNACOM, Chiba, Japan) and Haploview v3.2 (Barrett et al. 2005).
Northern blot analysis
Human multiple-tissue Northern (MTN) blots (Clontech, Palo Alto, Calif., USA) were pre-hybridized and hybridized with α-[32_P_]-dCTP labeled cDNA fragment prepared by PCR using primer pair shown in Table 1, as a probe. Washed membranes were autoradiographed for 7 days at −80°C.
Table 1 Primer sequences used in this study
Isolation of full-length cDNA
A human fetal brain cDNA library was constructed with combination of gene specific linker primers, random hexamer linker primer and oligo(dT) linker primer using ZAP cDNA synthesis kit (Stratagene, La Jolla, Calif., USA) according to the manufacturer’s protocol. The library was screened with the same probe as Northern experiment. Positive clones were selected and their insert cDNAs were excised in vivo in pBluescriptIISK(-) (Stratagene) according to the manufacturer’s protocol. To obtain the missing 5′- or 3′-portion, we performed a rapid amplification of cDNA ends (RACE) using BD SMART RACE cDNA Amplification Kit (Clontech) according to the manufacturer’s instructions. Primers for full-length cDNA isolation were shown in Table 1.
In vitro translation assay
Four kinds of plasmids corresponding to variant 1–4, which were obtained through screening of ZAP human fetal brain cDNA library for isolation of MIAT full-length cDNA, were transcribed and translated using TNT T7 Quick Coupled Transcription/Translation Systems (Promega, Madison, USA) and Transcend Biotin-Lysyl-tRNA (Promega) according to the manufacturer’s protocols. For negative control experiments, the antisense plasmids were constructed by inserting each PCR-amplified variant product in the opposite direction to pBluescript SK(+). Primers for constructing of the antisense plasmids were shown in Table 1. After SDS-PAGE and electro-blotting, the biotinylated products were visualized using the Transcend Nonradioactive Translation Detection Systems (Promega).
Luciferase assay
To investigate functions of six SNPs, we cloned genomic fragments into pGL3-promoter vector (Promega) in the 5′–3′ orientation. For intron 1 5,338 C>T and exon 5 11,093 G>A SNPs, each PCR-amplified product was used to be cloned into each of the vectors; for two SNPs in exon 3, one single PCR-amplified product containing both of the SNP loci was used; for exon 5 11,741 G>A and exon 5 12,311 C>T SNPs, double stranded oligonucleotides was cloned into pGL3-promoter vector. Primers and oligonucleotides for cloning of luciferase construct were shown in Table 1. We grew HEK293 cells (RIKEN Cell Bank, Wako, Japan) in Dulbecco’s modified Eagle’s medium supplemented with 10% fetal bovine serum. We then performed luciferase assay according to the manufacturer’s protocol. After 24 h of the transfection, we lysed the cells in passive lysis buffer (Promega) and then measured luciferase activity using the Dual-Luciferase Reporter Assay System (Promega).
Electrophoretic mobility-shift assay (EMSA)
We prepared nuclear extract from HEK293 cells as previously described (Andrews and Faller 1991) and then incubated it with 33-bp oligonucleotides labeled with digoxigenin-11-ddUTP using the Dig Gel Shift Kit, second generation (Roche, Mannheim, Germany). The oligonucleotides used in EMSA experiments were shown in Table 1. The reaction was done with 1/10 volume of Poly [d(I-C)]. For competition studies, we pre-incubated nuclear extract with unlabeled oligonucleotides (200-fold excess) before adding digoxigenin-labeled oligonucleotide. We separated the protein-DNA complexes on a non-denaturing 6% polyacrylamide gel in 0.5× Tris–Borate-EDTA buffer. We transferred the gel to nitrocellulose membrane and detected the signal with a chemiluminescent detection system (Roche) according to the manufacturer’s instructions.
In vitro RNA stability assay
First, we genotyped five SNP loci using DNAs extracted from 20 different human B cell lines (HEV cell lines; RIKEN cell bank). For further RNA stability assay, we used one cell line that was heterozygous for all of these SNPs. Two DNA fragments, corresponding to nt 956–1,827 and nt 1,975–3,400 of MIAT variant 4 (GenBank accession number; AB_263417) were amplified by PCR and used as a template. These fragments were cloned into a pBlueScript II SK(+) in the 5′–3′ orientation. We purified the vectors and performed transcription reaction using MEGAscript high yield transcription kit (T3 kit) (Ambion) according to the manufacturer’s instruction. Using 3 μl of the transcription products and 3 μl of HEK293 cell extracts (diluted 20-folds with distilled water), we performed RNA stability assay as described previously (Suzuki et al. 2003).
Results
Large-scale SNP association study
We performed a large scale case-control association study using 188 MI patients and 752 general Japanese population by our high-throughput multiplex PCR-Invader assay method (Ohnishi et al. 2001) for 52,608 gene-based SNPs selected from the JSNP database on the basis of the haplotype block structure reported previously (Haga et al. 2002; Tsunoda et al. 2004). Detailed screening strategy and results will be described elsewhere (Ebana et al., in preparation). From this first-stage screening, we identified one SNP (rs2301523) in FLJ25967 (GenBank accession number, AK098833) on chromosome 22q12.1 to reveal a significant association with MI (_P_=0.0006). Further investigation of this SNP using a total of 3,464 MI patients and 3,819 general population confirmed the association with MI with a χ 2 value of 22.71 (_P_=0.0000019; comparison of allele frequency) and odds ratio of 1.36 (95% confidence interval (CI); 1.20–1.55, Table 2).
Table 2 Association analyses between MI and six SNPs in MIAT
Identification of the full-length gene
Since cDNA sequences of 1,713 bases for FLJ25967 (GenBank Accession code; AK098833) did not contain a long open reading frame (ORF), we first examined expression of FLJ25967 in 4 fetal and 16 adult human tissues by Northern blot analyses. As shown in Fig. 1, the transcript of approximately 10 kb in length was detected in spleen, peripheral blood leukocyte, lung, liver, thymus, colon and small intestine, although predominant signals were detected in fetal brain and brain. To obtain the full-length cDNA sequence for this gene, we screened the fetal brain cDNA library and subsequently carried out 5′- and 3′-RACE experiments. From the results of the full-length cDNA sequences, this gene was considered to have four splicing variants (GenBank Accession number: AB263414, AB263415, AB263416, and AB263417), each consisting of 10,142, 10,016, 10,068 and 9,942 nucleotides, respectively. However, we still found no long ORF in either of the four cDNA sequences; the longest ORF we identified was 447-base long encoding 149 amino acids (Fig. 2b). Although we compared this ORF with protein sequecnes in the public databases using the BLAST program (Altschul et al. 1990), we found no protein showing a significant similarity. To investigate whether the transcript was really translated into protein, we carried out in vitro translation assay for each of the four variants, but no translated product was detected (Fig. 3), suggesting this gene encodes a functional RNA. We designated this gene MIAT, myocardial infarction associated transcript.
Fig. 1
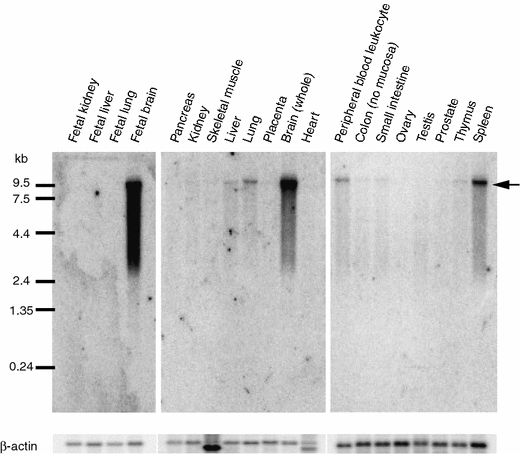
Expression of MIAT in human tissues. Arrows indicate the transcript of approximately 10 kb in size. β-actin cDNA was used as the quantity control
Fig. 2

Genomic organization and splicing variants of MIAT. a Genomic structure of MIAT. Base-pair numbering at the top was based on an entry from GenBank DNA database (NT011520.10). b Four splicing variants of MIAT and their possible open reading frames. The longest ORF was shown in gray. Inverted triangle and vertical line indicate ATG initiation codon and stop codon, respectively
Fig. 3
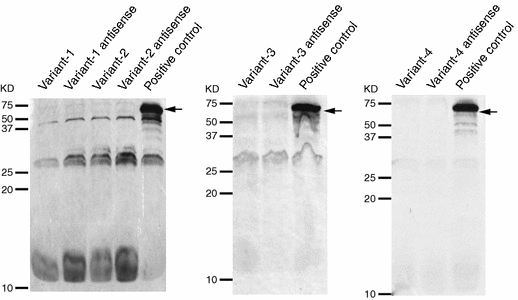
In vitro translation assay The arrows indicate the bands for positive controls
A comparison of genomic DNA sequences in GenBank database with each of the cDNA sequences determined a genomic structure of the MIAT gene. This gene consists of five exons (Fig. 2a) and all the splice junctions were considered to conform to the basic GT/AG rule (Mount 1982; Shapiro and Senapathy 1987).
Linkage disequilibrium and haplotype analysis
To search for the possibility that another SNP(s) in this locus confers risk of MI, we investigated SNPs in this region thoroughly, except for the regions corresponding to repetitive sequences. By direct sequencing of genomic DNA from 24 individuals in Japanese population, we identified a total of 60 SNPs, including 14 novel ones which were not registered in the dbSNP database (http://www.ncbi.nlm.nih.gov/SNP/index.html; build 126, Table 3). Subsequently, we selected 35 SNPs on the basis of the following two conditions; (1) SNPs should show minor allele frequencies (MAF) >5%, and (2) only one SNP can be selected from a group of SNPs that are in perfect LD among them. Then, we genotyped 96 individuals with MI and investigated a precise haplotype structure in this region using Haploview software (http://www.hapmap.org). As shown in Fig. 4, we identified one haplotype block including the marker SNP rs2301523, which was first identified to have an association with MI through our large-scale study. In addition, we found five SNPs (intron 1 5,338 C>T, exon 3 8,813 G>A, exon 5 11,093 G>A, exon 5 11,741 G>A, exon 5 12,311 C>T) in the block in strong linkage disequilibrium (LD) with the marker SNP. Therefore, we examined whether these five SNPs were also tightly associated with susceptibility to MI by genotyping approximately 3,400 individuals with MI and 3,700 control subjects. As shown in Table 2, all of them showed significant associations with MI. In particular, one SNP (intron 1 5,338 C>T; rs2331291) presented the most significant association with MI (_χ_²=25.27, _P_=0.0000005; comparison of allele frequency).
Table 3 SNPs in MIAT
Fig. 4
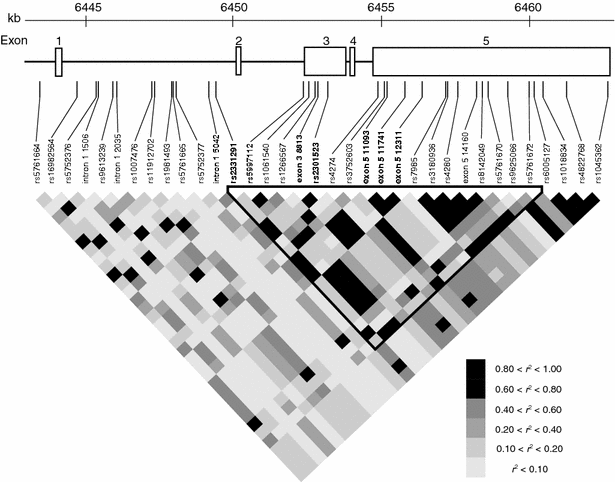
Linkage disequilibrium structure at the MIAT locus SNPs identified by this study are shown. SNPs in bold indicate significant association with MI (see also Table 2). Those which were not deposited in dbSNP database (build 126) were labeled with their location in the gene (e.g., intron 1 5,042). Pairwise r 2 values for all combination of SNP pairs are shown in gray scale
To clarify a possibility that one particular haplotype in the block confers risk of MI, we selected five tag SNPs (exon 3 8,555 T>C, exon 3 9,186 G>A, exon 5 10,804 G>A, exon 5 14,569 A>T, exon 5 15,219 C>A) that could cover 90% of haplotypes in this block. We compared frequency of haplotypes and genotypes of 652 individuals with MI and 620 control subjects using these tag SNPs. Since neither haplotypes nor four other tag SNPs showed statistical significance for the association with MI (Tables 4, 5), we considered that the first marker SNP rs2301523 and additional five SNPs showing the strong LD with it were candidate SNPs associated with MI.
Table 4 Association analyses of the tag SNPs in the haplotype block
Table 5 Haplotype analyses
We investigated relationship between patients’ genotype information and clinical profiles including diabetes, hypertension, smoking, hyperlipidemia, sex, and age by one-way ANOVA and χ 2 test. Since we could not find positive association for any of the coronary risk factors, age, or sex (data not shown), we concluded our findings are directly related to the pathogenesis of MI.
Luciferase and Gel-shift assay
Since MIAT was considered to be a non-coding functional RNA, we investigated the functions of these SNPs by examining their effect on transcriptional regulation by luciferase assay using HEK293 cell. As shown in Fig. 5d, the clone containing a G allele at position 11,741 in exon 5 had approximately 1.3-fold greater transcriptional activity than an A allele or the vector only. However, the remaining five SNPs did not show statistical difference in their transcriptional activity (_P_>0.05; Fig. 5a–c, e). Subsequently, to examine whether a nuclear factor(s) might bind to genomic sequence around the exon 5 11,741 SNP, we searched for binding motifs for known transcription factors around this SNP sequence by TFSEARCH program (http://www.cbrc.jp/research/db/TFSEARCHJ.html) based on the TRANSFAC database (Heinemeyer et al. 1998). Although no motif for binding of the transcriptional factors was predicted, we attempted to examine binding of some nuclear factor(s) in nuclear extract from HEK293 cells to oligonucleotides corresponding to the 11,741 G and 11,741 A alleles, respectively. As shown in Fig. 5f, the A-allele oligonucleotide bound more tightly to some nuclear factor present in HEK293 cells than the G-allele oligonucleotide.
Fig. 5
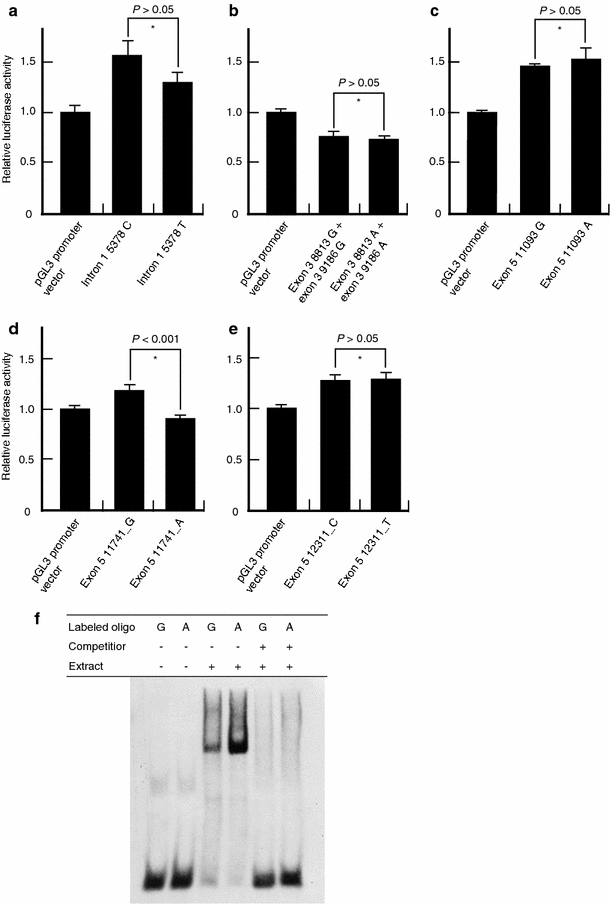
Transcriptional effect of the six SNPs in MIAT. a–e Luciferase assays in HEK293 cells. Only exon 5 11,741 G>A SNP affected transcriptional activity (d). *Student’s t test. We repeated each experiment three times and studied each sample in triplicate or duplicate. f Binding of an unknown nuclear factor(s) to exon 5 of MIAT. The experiments were repeated three times with similar results
Effect of SNP on RNA stability
In two previous studies, SNPs and haplotypes in exons have been implicated in having some roles in the stability of mRNA (Suzuki et al. 2003; Yang et al. 2003). To examine a possibility that the five exonic SNPs showing the significant association with MI (exon 3 8,813 G>A, exon 3 9,186 G>A, exon 5 11,093 G>A, exon 5 11,741 G>A and exon 5 112,311 C>T) might influence the stability of mRNA, we carried out RNA stability assay using HEK293 cells (Suzuki et al. 2003). Although the mRNA corresponding to the minor haplotype tended to be degraded more rapidly as compared with that corresponding to the major one, the difference was not statistically significant (data not shown).
Discussion
Through a large scale case-control association study using gene-based genome-wide tag SNPs, we found that six SNPs in MIAT, a novel gene encoding a possible non-coding functional RNA, might confer the genetic risk of MI. Since the function of this gene was not known, it was not possible to identify this gene as associated with MI by means of candidate gene approach. An advantage of the genome-wide association without any hypothesis is to find genetic variations, even in genes encoding functional RNAs, associated with various diseases. Hence, we are confident that a comprehensive association study using genome-wide tag SNPs is a powerful tool to fully understand genetic backgrounds of common diseases.
Our findings indicated that MIAT is a non-coding functional RNA. Biological functions of several non-coding functional RNAs have been investigated intensively; for example, H19 was shown to be involved in imprinting (Pfeifer et al. 1996). Xist was the first example of the functional RNA and was proven to regulate inactivation of the X chromosome (Brown et al. 1991). Hoxa11s is an antisense RNA for Hoxa11 and regulates transcription of Hoxa11 (Hsieh-Li et al. 1995). Recently, Willingham et al. (2005) identified a functional long non-coding RNA (termed NRON), which acts as a repressor of the nuclear factor of activated T cell (NFAT), and showed that specific ncRNAs as NRON may play a role in regulating the complexity of intracellular trafficking. Carninci et al. (2005) found over 23,000 non-coding RNA species through comparison between full-length cDNA sequences and genome sequences, indicating the complexity of mammalian transcriptional landscape. Thus, a large number of non-coding functional RNAs seem to play important roles in a variety of biological functions. Another aspect of functional RNA is a micro RNA (miRNA), one of the sequence-specific post-transcriptional regulators of gene expression (Tang 2005). It is generated by Dicer, a multidomain enzyme of the RNase III family. Dicer cuts precursor miRNAs with hairpin structure into miRNAs. However, sequence comparison of sense strand with antisense one using BLASTN program (Altschul et al. 1990) did not reveal complementary segments within MIAT, suggesting no possible hairpin structure that might give rise to double stranded RNA by Dicer. This indicates that MIAT is unlikely to contain an miRNA precursor. Although it is very difficult to reveal the function of MIAT with the present knowledge, we think the increasing attention to non-coding RNA and subsequent progress will help to solve this problem.
In the present study, we identified SNPs in MIAT conferring susceptibility to MI through a large-scale case-control association study. Although function of MIAT remains unclear, we believe that knowledge of genetic factors contributing to the pathogenesis of MI as presented here, will lead to improved diagnosis, treatment and prevention.
References
- Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (1990) Basic local alignment search tool. J Mol Biol 215:403–410
Article CAS Google Scholar - Andrews NC, Faller DV (1991) A rapid micropreparation teqhnique fore extraction of DNA-binding proteins from limiting numbers of mammalian cells. Nucleic Acids Res 19:2499
Article CAS Google Scholar - Barrett JC, Fry B, Maller J, Daly MJ (2005) Haploview: analysis and visualization of LD and haplotype maps. Bioinformatics 21:263–265
Article CAS Google Scholar - Breslow JW (1997) Cardiovascular disease burden increases, NIH funding decreases. Nat Med 3:600–601
Article CAS Google Scholar - Braunwald E (1997) Shattuck lecture-cardiovascular medicine at the turn of the millennium: triumphs, concerns and opportunities. N Engl J Med 337:1360–1369
Article CAS Google Scholar - Brown CJ, Ballabio A, Rupert JL, Lafreniere RG, Grompe M, Tonlorenzi R, Willard HF (1991) A gene from the region of the human X inactivation centre is expressed exclusively from the inactive X chromosome. Nature 349:38–44
Article CAS Google Scholar - Carninci P, Kasukawa T, Katayama S, Gough J, Frith MC, Maeda N, Oyama R, Ravasi T, Lenhard B, Wells C, Kodzius R, Shimokawa K, Bajic VB, Brenner SE, Batalov S, Forrest AR, Zavolan M, Davis MJ, Wilming LG, Aidinis V, Allen JE, Ambesi-Impiombato A, Apweiler R, Aturaliya RN, Bailey TL, Bansal M, Baxter L, Beisel KW, Bersano T, Bono H, Chalk AM, Chiu KP, Choudhary V, Christoffels A, Clutterbuck DR, Crowe ML, Dalla E, Dalrymple BP, de Bono B, Della Gatta G, di Bernardo D, Down T, Engstrom P, Fagiolini M, Faulkner G, Fletcher CF, Fukushima T, Furuno M, Futaki S, Gariboldi M, Georgii-Hemming P, Gingeras TR, Gojobori T, Green RE, Gustincich S, Harbers M, Hayashi Y, Hensch TK, Hirokawa N, Hill D, Huminiecki L, Iacono M, Ikeo K, Iwama A, Ishikawa T, Jakt M, Kanapin A, Katoh M, Kawasawa Y, Kelso J, Kitamura H, Kitano H, Kollias G, Krishnan SP, Kruger A, Kummerfeld SK, Kurochkin IV, Lareau LF, Lazarevic D, Lipovich L, Liu J, Liuni S, McWilliam S, Madan Babu M, Madera M, Marchionni L, Matsuda H, Matsuzawa S, Miki H, Mignone F, Miyake S, Morris K, Mottagui-Tabar S, Mulder N, Nakano N, Nakauchi H, Ng P, Nilsson R, Nishiguchi S, Nishikawa S, Nori F, Ohara O, Okazaki Y, Orlando V, Pang KC, Pavan WJ, Pavesi G, Pesole G, Petrovsky N, Piazza S, Reed J, Reid JF, Ring BZ, Ringwald M, Rost B, Ruan Y, Salzberg SL, Sandelin A, Schneider C, Schonbach C, Sekiguchi K, Semple CA, Seno S, Sessa L, Sheng Y, Shibata Y, Shimada H, Shimada K, Silva D, Sinclair B, Sperling S, Stupka E, Sugiura K, Sultana R, Takenaka Y, Taki K, Tammoja K, Tan SL, Tang S, Taylor MS, Tegner J, Teichmann SA, Ueda HR, van Nimwegen E, Verardo R, Wei CL, Yagi K, Yamanishi H, Zabarovsky E, Zhu S, Zimmer A, Hide W, Bult C, Grimmond SM, Teasdale RD, Liu ET, Brusic V, Quackenbush J, Wahlestedt C, Mattick JS, Hume DA, Kai C, Sasaki D, Tomaru Y, Fukuda S, Kanamori-Katayama M, Suzuki M, Aoki J, Arakawa T, Iida J, Imamura K, Itoh M, Kato T, Kawaji H, Kawagashira N, Kawashima T, Kojima M, Kondo S, Konno H, Nakano K, Ninomiya N, Nishio T, Okada M, Plessy C, Shibata K, Shiraki T, Suzuki S, Tagami M, Waki K, Watahiki A, Okamura-Oho Y, Suzuki H, Kawai J, Hayashizaki Y, FANTOM Consortium RIKEN Genome Exploration Research Group, Genome Science Group (Genome Network Project Core Group) (2005) The transcriptional landscape of the mammalian genome. Science 309:1559–1563
Article CAS Google Scholar - Collins FS, Guyer MS, Charkravarti A (1997) Variations on a theme: cataloging human DNA sequence variation. Science 278:1580–1581
Article CAS Google Scholar - Haga H, Yamada R, Ohnishi Y, Nakamura Y, Tanaka T (2002) Gene-based SNP discovery as part of the Japanese Millennium Genome Project: identification of 190,562 genetic varidations in the human genome. J Hum Genet 47:605–610
Article CAS Google Scholar - Heinemeyer T, Wingender E, Reuter I, Hermjakob H, Kel AE, Kel OV, Ignatieva EV, Ananko EA, Podkolodnaya OA, Kolpakov FA, Podkolodny NL, Kolchanov NA (1998) Databases on transcriptional regulation: TRANSFAC, TRRD, and COMPEL. Nucleic Acids Res 26:364–370
Article Google Scholar - Helgadottir A, Manolescu A, Thorleifsson G, Gretarsdottir S, Jonsdottir H, Thorsteinsdottir U, Samani NJ, Gudmundsson G, Grant SF, Thorgeirsson G, Sveinbjornsdottir S, Valdimarsson EM, Matthiasson SE, Johannsson H, Gudmundsdottir O, Gurney ME, Sainz J, Thorhallsdottir M, Andresdottir M, Frigge ML, Topol EJ, Kong A, Gudnason V, Hakonarson H, Gulcher JR, Stefansson K (2004) The gene encoding 5-lipoxygenase activating protein confers risk of myocardial infarction and stroke. Nat Genet 36:233–239
Article CAS Google Scholar - Hsieh-Li HM, Witte DP, Weinstein M, Branford W, Li H, Small K, Potter SS (1995) Hoxa 11 structure, extensive antisense transcription, and function in male and female fertility. Development 121:1373–1385
CAS PubMed Google Scholar - Iida A, Saito S, Sekine A, Kitamoto T, Kitamura Y, Mishima C, Osawa S, Kondo K, Harigae S, Nakamura Y (2001) Catalog of 258 single-nucleotide polymorphisms (SNPs) in genes encoding three organic anion transporters, three organic anion-transporting polypeptides, and three NADH: ubiquinone oxidoreductase flavoproteins. J Hum Genet 46:668–683
Article CAS Google Scholar - Lander ES (1996) The new genomics: global views of biology. Science 274:536–539
Article CAS Google Scholar - Lusis AJ, Mar R, Pajukanta P (2004) Genetics of atherosclerosis. Annu Rev Genomics Hum Genet 5:189–218
Article CAS Google Scholar - Marenberg ME, Rish N, Berkman LF, Floderus B, de Faire U (1994) Genetic susceptibility to death from coronary heart disease in a study of twins. N Engl J Med 330:1041–1046
Article CAS Google Scholar - Mount SM (1982) A catalogue of splice junction sequences. Nucleic Acids Res 10:459–472
Article CAS Google Scholar - Ohnishi Y, Tanaka T, Yamada R, Suematsu K, Minami M, Fujii K, Hoki N, Kodama K, Nagata S, Hayashi T, Kinoshita N, Sato H, Sato H, Kuzuya T, Takeda H, Hori M, Nakamura Y (2000) Identification of the 187 single nucleotide polymorphisms (SNPs) among 41 candidate genes for ischemic heart disease in the Japanese population. Hum Genet 106:288–292
Article CAS Google Scholar - Ohnishi Y, Tanaka T, Ozaki K, Yamada R, Suzuki H, Nakamura Y (2001) A high-throughput SNP typing system for genome-wide association studies. J Hum Genet 46:471–477
Article CAS Google Scholar - Ozaki K, Ohnishi Y, Iida A, Sekine A, Yamada R, Tsunoda T, Sato H, Sato H, Hori M, Nakamura Y, Tanaka T (2002) Functional SNPs in the lymphotoxin-a gene that are associated with susceptibility to myocardial infarction. Nat Genet 32:650–654
Article CAS Google Scholar - Ozaki K, Inoue K, Sato H, Iida A, Ohnishi Y, Sekine A, Odashiro K, Nobuyoshi M, Hori M, Nakamura Y, Tanaka T (2004) Functional variation in LGALS2 confers risk of myocardial infarction and regulates lymphotoxin-a secretion in vitro. Nature 429:72–75
Article CAS Google Scholar - Ozaki K, Sato H, Iida A, Mizuno H, Nakamura T, Miyamoto Y, Takahashi A, Tsunoda T, Ikegawa S, Kamatani N, Hori M, Nakamura Y, Tanaka T (2006) A functional SNP in PSMA6 confers risk of myocardial infarction in the Japanese population. Nat Genet (Epub ahead of print)
- Pfeifer K, Leighton PA, Tilghman SM (1996) The structural H19 gene is required for transgene imprinting. Proc Natl Acad Sci USA 93:13876–13883
Article CAS Google Scholar - Risch N, Merikangas K (1996) The future of genetic studies of complex human diseases. Science 273:1516–1517
Article CAS Google Scholar - Shapiro MB, Senapathy P (1987) RNA splice junctions of different classes of eukaryotes: Sequence statistics and functional implications in gene expression. Nucleic Acids Res 15:7155–7174
Article CAS Google Scholar - Stenina OI, Desai SY, Krukovets I, Kight K, Janigro D, Topol EJ, Plow EF (2003) Thrombospondin-4 and its variants: expression and differential effects on endothelial cells. Circulation 108:1514–1519
Article CAS Google Scholar - Suzuki A, Yamada R, Chang X, Tokuhiro S, Sawada T, Suzuki M, Nagasaki M, Nakayama-Hamada M, Kawaida R, Ono M, Ohtsuki M, Furukawa H, Yoshino S, Yukioka M, Tohma S, Matsubara T, Wakitani S, Teshima R, Nishioka Y, Sekine A, Iida A, Takahashi A, Tsunoda T, Nakamura Y, Yamamoto K (2003) Functional haplotypes of PADI4, encording citrullinating enzyme peptidylarginine deiminase 4, are associated with rheumatoid arthritis. Nat Genet 34:395–402
Article CAS Google Scholar - Tang G (2005) siRNA and miRNA: an insight into RISCs. Trends Biochem Sci 30:106–114
Article CAS Google Scholar - Topol EJ, McCarthy J, Gabriel S, Moliterno DJ, Rogers WJ, Newby LK, Freedman M, Metivier J, Cannata R, O’Donnell CJ, Kottke-Marchant K, Murugesan G, Plow EF, Stenina O, Daley GQ (2001) Single nucleotide polymorphisms in multiple novel thrombospondin genes may be associated with familial premature myocardial infarction. Circulation 104:2641–2644
Article CAS Google Scholar - Tsunoda T, Lathrop GM, Sekine A, Yamada R, Takahashi A, Ohnishi Y, Tanaka T, Nakamura Y (2004) Variation of the gene-based SNPs and linkage disequilibrium patterns in the human genome. Hum Mol Genet 13:1623–1632
Article CAS Google Scholar - Willingham AT, Orth AP, Batalov S, Peters EC, Wen BG, Aza-Blanc P, Hogenesch JB, Schultz PG (2005) A strategy for probing the functional of noncording RNAs finds a repressor of NFAT. Science 309:1570–1573
Article CAS Google Scholar - Yamada R, Tanaka T, Unoki M, Nagai T, Sawada T, Ohnishi Y, Tsunoda T, Yukioka M, Maeda A, Suzuki K, Tateishi H, Ochi T, Nakamura Y, Yamamoto K (2001) Association between a single-nucleotide polymorphism in the promoter of the human interleukin-3 gene and rheumatoid arthritis in Japanese patients, and maximum-likelihood estimation of combinatorial effect that two genetic loci have on susceptibility to the disease. Am J Hum Genet 68:674–685
Article CAS Google Scholar - Yamada Y, Izawa H, Ichihara S, Takatsu F, Ishihara H, Hirayama H (2002) Prediction of the risk of myocardial infarction from polymorphisms in candidate genes. N Engl J Med 347:1916–1923
Article CAS Google Scholar - Yang T, McNally BA, Ferrone S, Liu Y, Xheng P (2003) A single nucleotide deletion leads to rapid degradation of TAP-1 mRNA in a melanoma cell line. J Biol Chem 278:15291–15296
Article CAS Google Scholar
Acknowledgments
We thank Maki Takahashi, Mayumi Yoshii, Saori Abiko, Wataru Yamanobe, Rumiko Ohishi, Makiko Watabe, Kaori Tabei and Saori Manabe for their assistance. We also thank all the other members of SNP Research Center, RIKEN and OACIS for their contribution to the completion of our study. We are also grateful to members of The Rotary Club of Osaka-Midosuji District 2660 Rotary International in Japan for supporting our study. This work was supported in part by a grant from the Takeda science foundation, the Uehara science foundation and the Japanese Millennium Project.
Author information
Authors and Affiliations
- Laboratory for Cardiovascular Diseases, SNP Research Center, The Institute of Physical and Chemical Research (RIKEN), 4-6-1 Shirokanedai, Minato-ku, Tokyo, 108-8639, Japan
Nobuaki Ishii, Kouichi Ozaki & Toshihiro Tanaka - Division of Cardiology, Department of Medicine, Nihon University School of Medicine, Tokyo, Japan
Nobuaki Ishii & Satoshi Saito - Department of Cardiovascular Medicine, Osaka University Graduate School of Medicine, Suita, Japan
Hiroshi Sato, Hiroya Mizuno & Masatsugu Hori - Laboratory for Genotyping, SNP Research Center, The Institute of Physical and Chemical Research (RIKEN), Tokyo, Japan
Susumu Saito & Yusuke Nakamura - Laboratory for Statistical Analysis, SNP Research Center, The Institute of Physical and Chemical Research (RIKEN), Tokyo, Japan
Atsushi Takahashi & Naoyuki Kamatani - Laboratory for Bone and Joint Disease, SNP Research Center, The Institute of Physical and Chemical Research (RIKEN), Tokyo, Japan
Yoshinari Miyamoto & Shiro Ikegawa
Authors
- Nobuaki Ishii
You can also search for this author inPubMed Google Scholar - Kouichi Ozaki
You can also search for this author inPubMed Google Scholar - Hiroshi Sato
You can also search for this author inPubMed Google Scholar - Hiroya Mizuno
You can also search for this author inPubMed Google Scholar - Susumu Saito
You can also search for this author inPubMed Google Scholar - Atsushi Takahashi
You can also search for this author inPubMed Google Scholar - Yoshinari Miyamoto
You can also search for this author inPubMed Google Scholar - Shiro Ikegawa
You can also search for this author inPubMed Google Scholar - Naoyuki Kamatani
You can also search for this author inPubMed Google Scholar - Masatsugu Hori
You can also search for this author inPubMed Google Scholar - Satoshi Saito
You can also search for this author inPubMed Google Scholar - Yusuke Nakamura
You can also search for this author inPubMed Google Scholar - Toshihiro Tanaka
You can also search for this author inPubMed Google Scholar
Corresponding author
Correspondence toToshihiro Tanaka.
Rights and permissions
About this article
Cite this article
Ishii, N., Ozaki, K., Sato, H. et al. Identification of a novel non-coding RNA, MIAT, that confers risk of myocardial infarction.J Hum Genet 51, 1087–1099 (2006). https://doi.org/10.1007/s10038-006-0070-9
- Received: 14 August 2006
- Accepted: 31 August 2006
- Published: 01 December 2006
- Issue Date: December 2006
- DOI: https://doi.org/10.1007/s10038-006-0070-9