Yiqing Liang (original) (raw)
News
- [ May-2025 ]: The first End-to-End 3D Learning (E2E3D) workshop is accepted to ICCV 2025! See you in Hawaii.
- [ May-2025 ]: MonoDyGauBench got accepted to TMLR 2025!
- [ Apr-2025 ]: ZeroMSF is selected as CVPR 2025 Award Candidate (0.48%)!
- [ Apr-2025 ]: I am giving an invited talk at Harvard Visual Computing Group!
- [ Mar-2025 ]: ZeroMSF is accepted to CVPR 2025 as an Oral Presentation!
- [ Feb-2025 ]: I am giving a lightning talk at NYC Computer Vision Day 2025!
- [ Nov-2024 ]: I am presenting my internship work with Nvidia Research at NECV 2024!
- [ Jun-2024 ]: I started the summer internship at LPR Team @ NVIDIA Research.
- [ Dec-2023 ]: My research is recognized in Hugging Face Daily Papers by AK!
- [ Dec-2023 ]: I am presenting my internship work with Meta Reality Labs at NECV 2023!
- [ Jul-2023 ]: SAFF got accepted to ICCV 2023!
- [ Jun-2023 ]: I started the summer internship at DSR team of Meta Reality Labs.
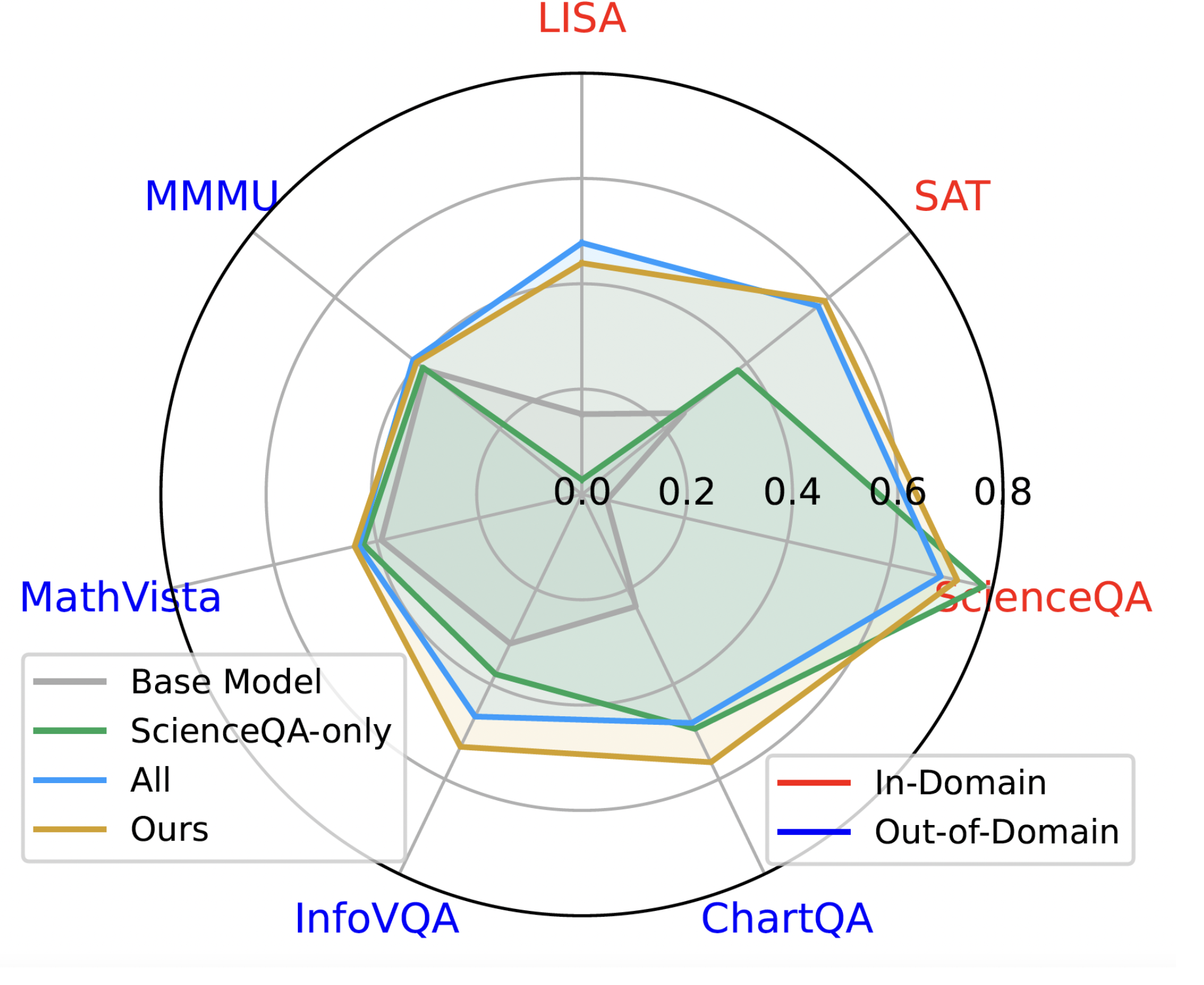 |
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning Yiqing Liang, Jielin Qiu,Wenhao Ding,Zuxin Liu,James Tompkin,Mengdi Xu,Mengzhou Xia,Zhengzhong Tu,Laixi Shi,Jiacheng Zhu Under Review, 2025 paper / data / code / bibtex We introduce MoDoMoDo, a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. |
|---|---|
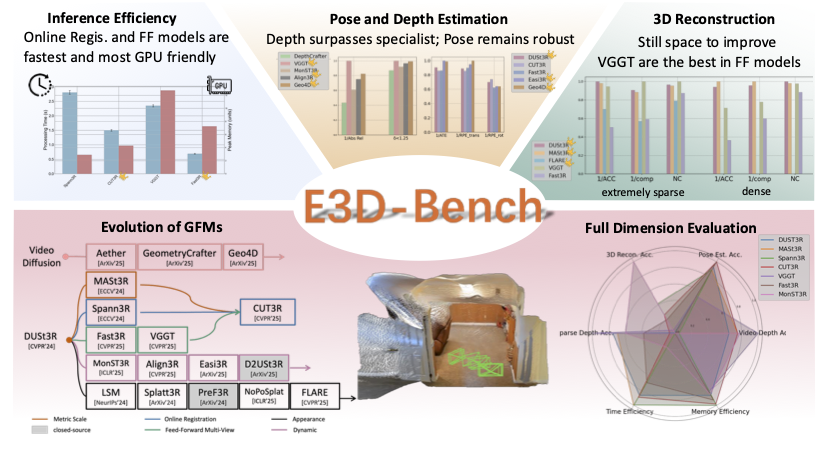 |
E3D-Bench: A Benchmark for End-to-End 3D Geometric Foundation Models Wenyan Cong,Yiqing Liang, Yancheng Zhang, Ziyi Yang, Yan Wang, Boris Ivanovic, Marco Pavone, Chen Chen, Zhangyang Wang, Zhiwen Fan Under Review, 2025 paper / code / bibtex We present the first comprehensive benchmark for 3D end‑to‑end 3D geometric foundation models, covering five core tasks: sparse-view depth estimation, video depth estimation, 3D reconstruction, multi-view pose estimation, novel view synthesis, and spanning both standard and challenging out-of-distribution datasets. |
  |
Zero-Shot Monocular Scene Flow Estimation in the Wild Yiqing Liang, Abhishek Badki*, Hang Su*, James Tompkin, Orazio Gallo CVPR, 2025 Oral, Award Candidate (0.48%) paper / video / code / bibtex We present ZeroMSF, the first generalizable 3D foundation model that understands monocular scene flow for diverse real-world scenarios, utilizing our curated data receipe of 1M synthetic training samples. |
  |
Monocular Dynamic Gaussian Splatting is Fast and Brittle and Scene Complexity Rules Yiqing Liang, Mikhail Okunev, Mikaela Angelina Uy, Runfeng Li, Leonidas J. Guibas, James Tompkin, Adam Harley TMLR, 2025 paper / data / code / bibtex We present a benchmark of dynamic Gaussian Splatting methods for monocular view synthesis, combining existing datasets and a new synthetic dataset to provide standardized comparisons and identify key factors affecting efficiency and quality. |
  |
GauFRe: Gaussian Deformation Fields for Real-time Dynamic Novel View Synthesis Yiqing Liang, Numair Khan, Zhengqin Li, Thu Nguyen-Phuoc, Douglas Lanman, James Tompkin, Lei Xiao CVPR, 2024, CV4MR WACV, 2025 [paper](gaufre/static/pdfs/WACV%5F2025%5F%5F%5FGauFRe %281%29.pdf) / code / bibtex We propose GauFRe: a dynamic scene reconstruction method using deformable 3D Gaussians for monocular video that is efficient to train, renders in real-time and separates static and dynamic regions. |
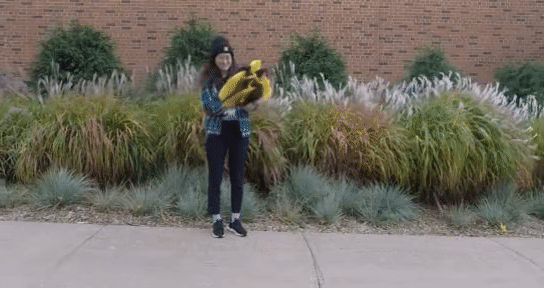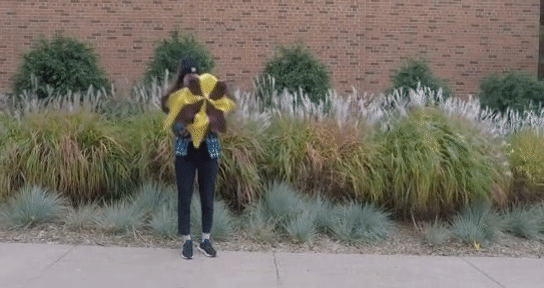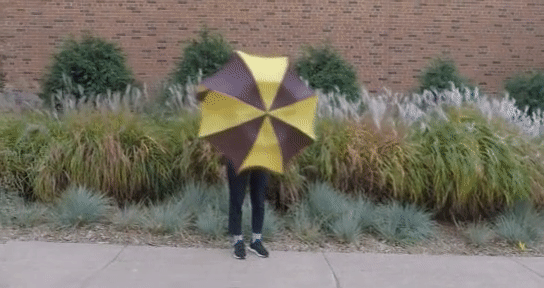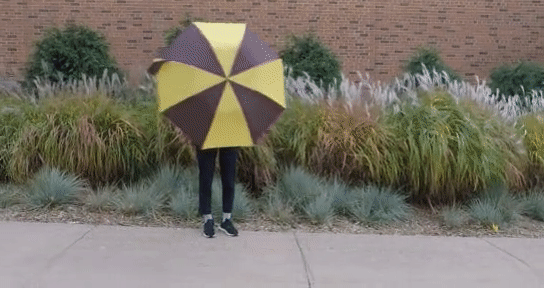  |
Semantic Attention Flow Fields for Monocular Dynamic Scene Decomposition Yiqing Liang, Eliot Laidlaw, Alexander Meyerowitz,Srinath Sridhar,James Tompkin ICCV, 2023 paper / code / bibtex We present SAFF: a dynamic neural volume reconstruction of a casual monocular video that consists of time-varying color, density, scene flow, semantics, and attention information. |
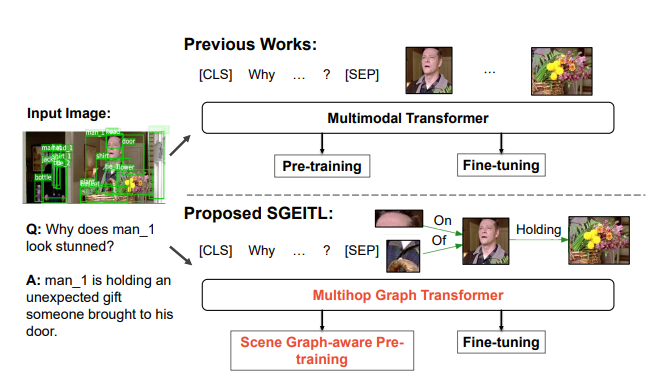 |
SGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning Zhecan Wang*, Haoxuan You*, Liunian Harold Li,Alireza Zareian, Suji Park, Yiqing Liang, Kai-Wei Chang, Shih-Fu Chang AAAI, 2022 paper / bibtex We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graph in commonsense reasoning |
  |
SSCNav: Confidence-Aware Semantic Scene Completion for Visual Semantic Navigation Yiqing Liang, Boyuan Chen, Shuran Song ICRA, 2021 paper / video / code / bibtex We explicitly model scene priors using a confidence-aware semantic scene completion module to complete the scene and guide the agent's navigation planning. |