Nicolas Dufour personal website (original) (raw)
About me
I’m a third year Computer Vision PhD student at IMAGINE (ENPC) and VISTA (Ecole Polytechnique) labs. My research is focused on conditional generative models. I’m supervised by David Picard and Vicky Kalogeiton. Before my PhD, I graduated from the MVA master (Mathematiques, Vision et Apprentissage) at ENS Paris Saclay and I got my engineering degree from Telecom SudParis following the MSA specialization (Mathematics and Statistical Modeling). I’ve also done an internship at Meta, where i worked on Model Based Reinforcement Learning.
During my PhD, I have worked on GANs and diffusion models. I also have a high interest in the current development of the field of generative models around Large Language Models.
News
Jun, 2024
Attended CVPR 2024 to present our work CAD and OSV-5M.
Publications
2025

How far can we go with ImageNet for Text-to-Image generation?
Arxiv Preprint
Recent text-to-image (T2I) generation models have achieved remarkable results by training on billion-scale datasets, following a `bigger is better’ paradigm that prioritizes data quantity over quality. We challenge this established paradigm by demonstrating that strategic data augmentation of small, well-curated datasets can match or outperform models trained on massive web-scraped collections. Using only ImageNet enhanced with well-designed text and image augmentations, we achieve a +2 overall score over SD-XL on GenEval and +5 on DPGBench while using just 1/10th the parameters and 1/1000th the training images. Our results suggest that strategic data augmentation, rather than massive datasets, could offer a more sustainable path forward for T2I generation.
@article{dufour2024world80timestepsgenerative, title ={How far can we go with ImageNet for Text-to-Image generation?}, author ={Lucas Degeorge and Arijit Ghosh and Nicolas Dufour and David Picard and Vicky Kalogeiton}, year ={2025}, journal ={arXiv}, }
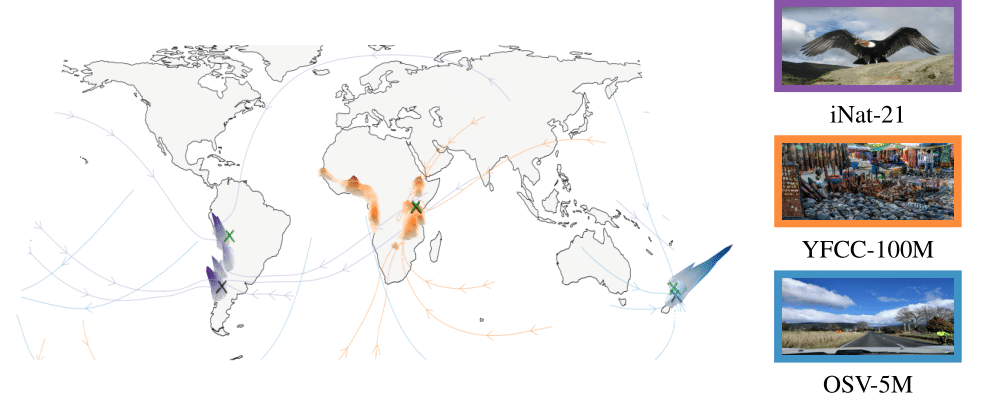
Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation
CVPR 2025
Global visual geolocation predicts where an image was captured on Earth. Since images vary in how precisely they can be localized, this task inherently involves a significant degree of ambiguity. However, existing approaches are deterministic and overlook this aspect. In this paper, we aim to close the gap between traditional geolocalization and modern generative methods. We propose the first generative geolocation approach based on diffusion and Riemannian flow matching, where the denoising process operates directly on the Earth’s surface. Our model achieves state-of-the-art performance on three visual geolocation benchmarks: OpenStreetView-5M, YFCC-100M, and iNat21. In addition, we introduce the task of probabilistic visual geolocation, where the model predicts a probability distribution over all possible locations instead of a single point. We introduce new metrics and baselines for this task, demonstrating the advantages of our diffusion-based approach.
@article{dufour2024world80timestepsgenerative, title ={Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation}, author ={Nicolas Dufour and David Picard and Vicky Kalogeiton and Loic Landrieu}, year ={2025}, journal ={CVPR}, }
2024
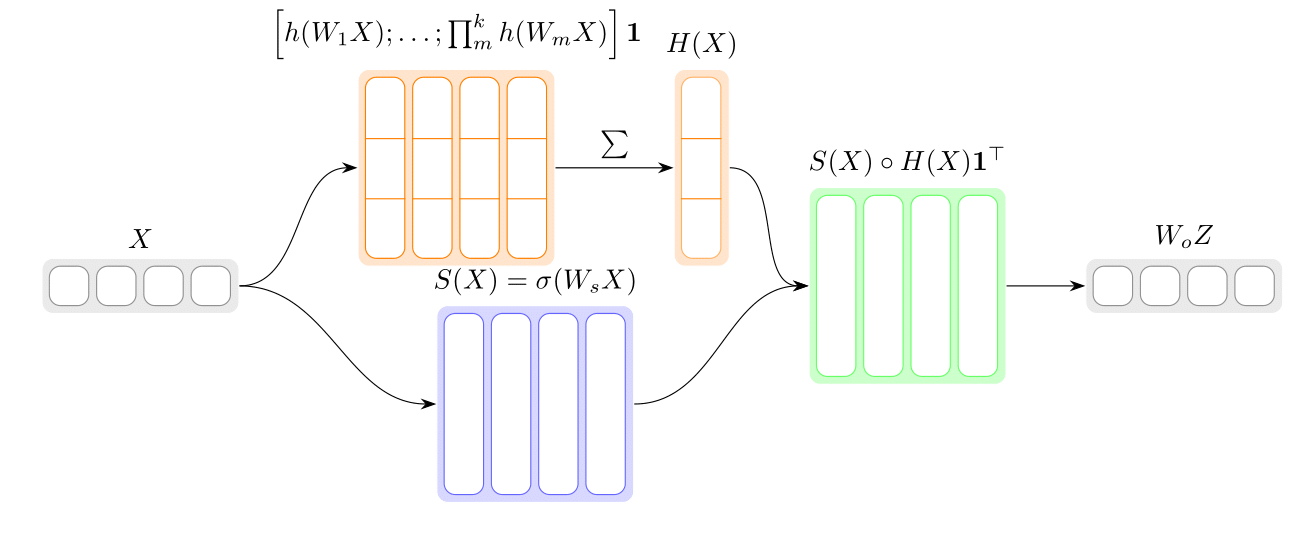
PoM: Efficient Image and Video Generation with the Polynomial Mixer
Arxiv Preprint
Diffusion models based on Multi-Head Attention (MHA) have become ubiquitous to generate high quality images and videos. However, encoding an image or a video as a sequence of patches results in costly attention patterns, as the requirements both in terms of memory and compute grow quadratically. To alleviate this problem, we propose a drop-in replacement for MHA called the Polynomial Mixer (PoM) that has the benefit of encoding the entire sequence into an explicit state. PoM has a linear complexity with respect to the number of tokens. This explicit state also allows us to generate frames in a sequential fashion, minimizing memory and compute requirement, while still being able to train in parallel. We show the Polynomial Mixer is a universal sequence-to-sequence approximator, just like regular MHA. We adapt several Diffusion Transformers (DiT) for generating images and videos with PoM replacing MHA, and we obtain high quality samples while using less computational resources
@article{picard2024pom, author = {David Picard and Nicolas Dufour}, title = {PoM: Efficient Image and Video Generation with the Polynomial Mixer}, journal = {arXiv}, year = {2024}, }

Analysis of Classifier-Free Guidance Weight Schedulers
TMLR
Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances, requiring merely a single line of code. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks.
@article{wang2024analysis, title={Analysis of Classifier-Free Guidance Weight Schedulers}, author={Xi Wang and Nicolas Dufour and Nefeli Andreou and Marie-Paule Cani and Victoria Fernandez Abrevaya and David Picard and Vicky Kalogeiton}, journal={TMLR}, year={2024} }
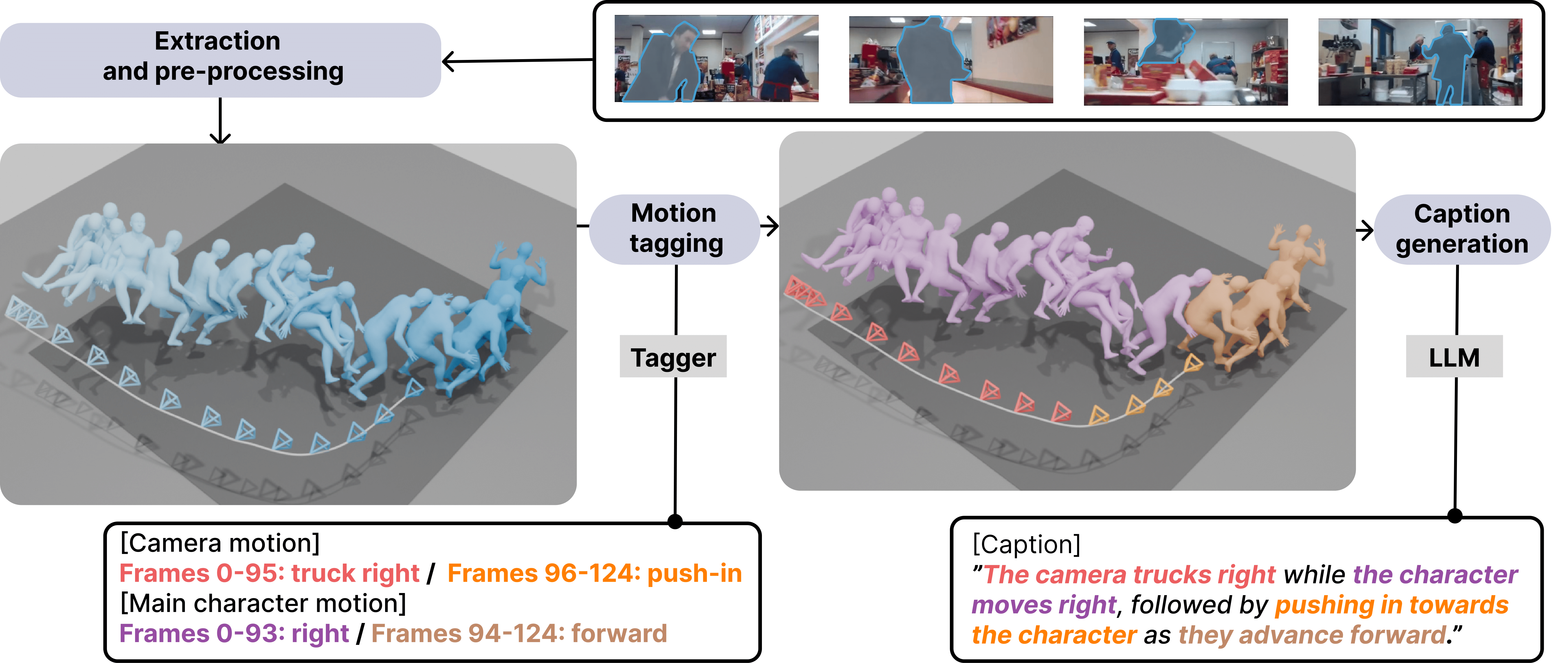
E.T. the Exceptional Trajectories: Text-to-Camera-Trajectory Generation with Character Awareness.
ECCV 2024
Stories and emotions in movies emerge through the effect of well-thought-out directing decisions, in particular camera placement and movement over time. Crafting compelling camera motion trajectories remains a complex iterative process, even for skilful artists. To tackle this, in this paper, we propose a dataset called the Exceptional Trajectories (E.T.) with camera trajectories along with character information and textual captions encompassing description of both camera and character. To our knowledge, this is the first dataset of its kind. To show the potentialities of the E.T. dataset, we propose a diffusion-based approach, named DIRECTOR, which generates complex camera trajectories from textual captions that describe the relation and synchronisation between the camera and characters. Finally, to ensure a robust and accurate evaluation, we train CLaTr on the E.T. dataset, a language-trajectory feature representation used for metric calculation. Our work represents a significant advancement in democratizing the art of cinematography for common users.
@article{courant2024et, author = {Robin Courant and Nicolas Dufour and Xi Wang and Marc Christie and Vicky Kalogeiton}, title = {E.T. the Exceptional Trajectories: Text-to-camera-trajectory generation with character awareness}, journal = {arXiv}, year = {2024}, }

Don't drop your samples! Coherence-aware training benefits Conditional diffusion
CVPR 2024(Highlight)
Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. We show that CAD is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging coherence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low coherence have been discarded.
@article{dufour2024dont, title={Don't drop your samples! Coherence-aware training benefits Conditional diffusion}, author={Dufour, Nicolas and Besnier, Victor and Kalogeiton, Vicky and Picard, David}, booktitle={CVPR}, year={2024}, }
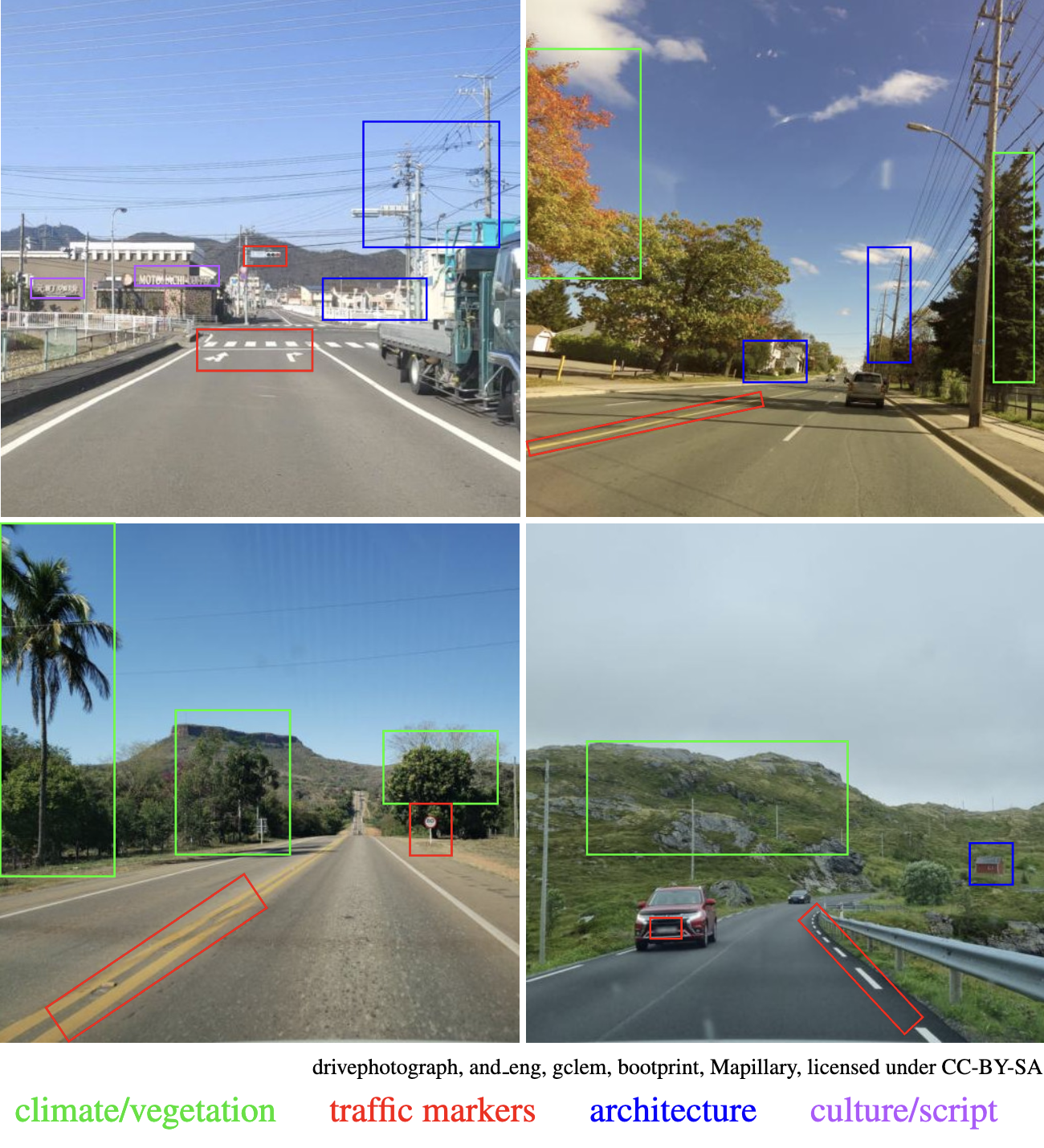
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
*, Ioannis Siglidis*, Constantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao XU, Hongyu Zhou, Loic Landrieu
CVPR 2024
Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies.
@article{astruc2024openstreetview5m, title={OpenStreetView-5M: The Many Roads to Global Visual Geolocation}, author={Guillaume Astruc and Nicolas Dufour and Ioannis Siglidis and Constantin Aronssohn and Nacim Bouia and Stephanie Fu and Romain Loiseau and Van Nguyen Nguyen and Charles Raude and Elliot Vincent and Lintao XU and Hongyu Zhou and Loic Landrieu}, journal={CVPR}, year={2024} }
2023
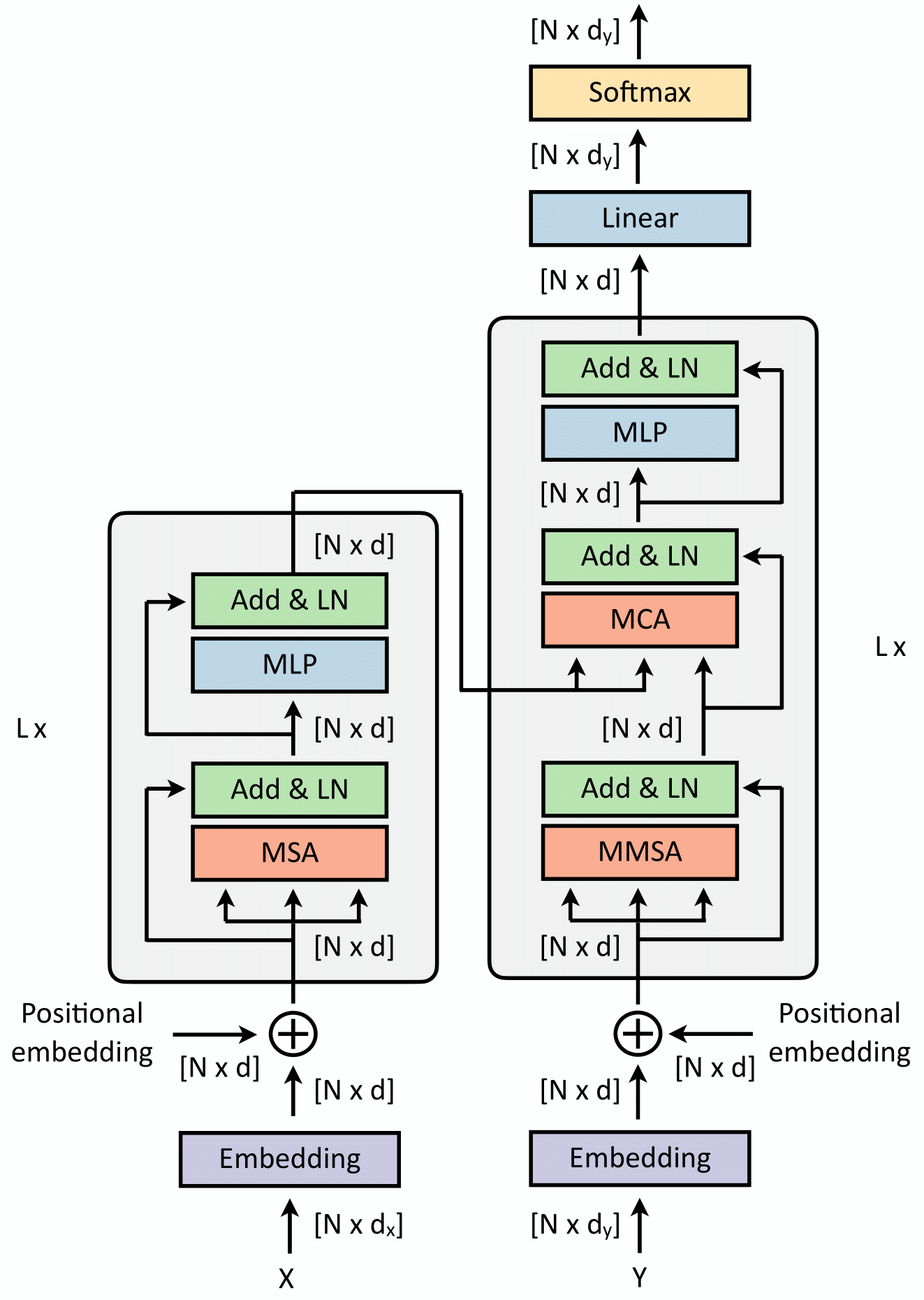
Machine Learning for Brain Disorders: Transformers and Visual Transformers
Springer, Machine Learning for Brain Disorders
Transformers were initially introduced for natural language processing (NLP) tasks, but fast they were adopted by most deep learning fields, including computer vision. They measure the relationships between pairs of input tokens (words in the case of text strings, parts of images for visual Transformers), termed attention. The cost is exponential with the number of tokens. For image classification, the most common Transformer Architecture uses only the Transformer Encoder in order to transform the various input tokens. However, there are also numerous other applications in which the decoder part of the traditional Transformer Architecture is also used. Here, we first introduce the Attention mechanism (Section 1), and then the Basic Transformer Block including the Vision Transformer (Section 2). Next, we discuss some improvements of visual Transformers to account for small datasets or less computation(Section 3). Finally, we introduce Visual Transformers applied to tasks other than image classification, such as detection, segmentation, generation and training without labels (Section 4) and other domains, such as video or multimodality using text or audio data (Section 5).
@incollection{courant2012transformers, title={Transformers and Visual Transformers}, author={Courant, Robin and Edberg, Maika and Dufour, Nicolas and Kalogeiton, Vicky}, booktitle={Machine Learning for Brain Disorders}, pages={193--229}, year={2012}, publisher={Springer} }
2022
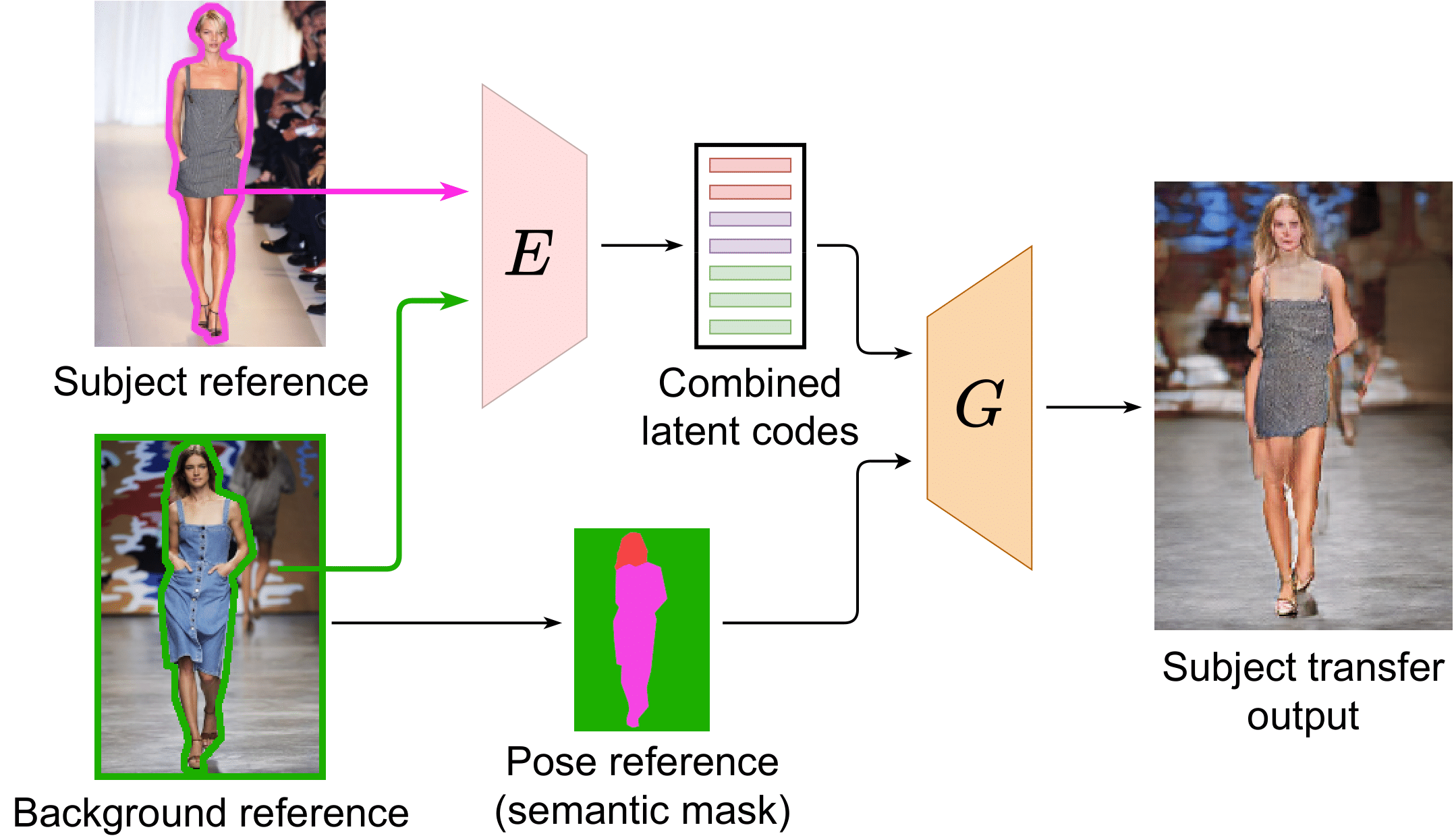
SCAM! Transferring humans between images with Semantic Cross Attention Modulation
ECCV 2022
A large body of recent work targets semantically conditioned image generation. Most such methods focus on the narrower task of pose transfer and ignore the more challenging task of subject transfer that consists in not only transferring the pose but also the appearance and background. In this work, we introduce SCAM (Semantic Cross Attention Modulation), a system that encodes rich and diverse information in each semantic region of the image (including foreground and background), thus achieving precise generation with emphasis on fine details. This is enabled by the Semantic Attention Transformer Encoder that extracts multiple latent vectors for each semantic region, and the corresponding generator that exploits these multiple latents by using semantic cross attention modulation. It is trained only using a reconstruction setup, while subject transfer is performed at test time. Our analysis shows that our proposed architecture is successful at encoding the diversity of appearance in each semantic region. Extensive experiments on the iDesigner and CelebAMask-HD datasets show that SCAM outperforms SEAN and SPADE; moreover, it sets the new state of the art on subject transfer.
@article{dufour2022scam, title={Scam! transferring humans between images with semantic cross attention modulation}, author={Dufour, Nicolas and Picard, David and Kalogeiton, Vicky}, booktitle={European Conference on Computer Vision}, pages={713--729}, year={2022}, organization={Springer} }
Teaching
Apr 2024 - Jun 2024
Teaching Assistant for INF473V - Modal d'informatique - Deep Learning in Computer Vision at Ecole Polytechnique
- Helped supervise the practical sessions of the course.
- Created a Kaggle competition for the students end of the course project. The goal was to create a classifier but we only provided them with the val and test data. They needed to create their own training data with pretrained diffusion models. The goal was to classify among 37 different cheeses.
Feb 2023 - Jun 2023
Teaching Assistant for INF473V - Modal d'informatique - Deep Learning in Computer Vision at Ecole Polytechnique
- Helped supervise the practical sessions of the course.
- Built a new practical session on Transformers.
- Created a Kaggle competition for the students end of the course project. The goal was to classify synthetic images in a weakly supervised setting.
Nov 2022
Teaching Assistant for INF573 - Image Analysis and Computer Vision at Ecole Polytechnique
- Helped supervise students projects.