OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments (original) (raw)
Danyang Zhang1, Jixuan Chen1, Xiaochuan Li1,
Siheng Zhao1, Ruisheng Cao1, Toh Jing Hua1, Zhoujun Cheng1, Dongchan Shin1, Fangyu Lei1, Yitao Liu1, Yiheng Xu1, Shuyan Zhou3, Silvio Savarese2, Caiming Xiong2, Victor Zhong4, Tao Yu1
1The University of Hong Kong, 2Salesforce Research, 3Carnegie Mellon University, 4University of Waterloo
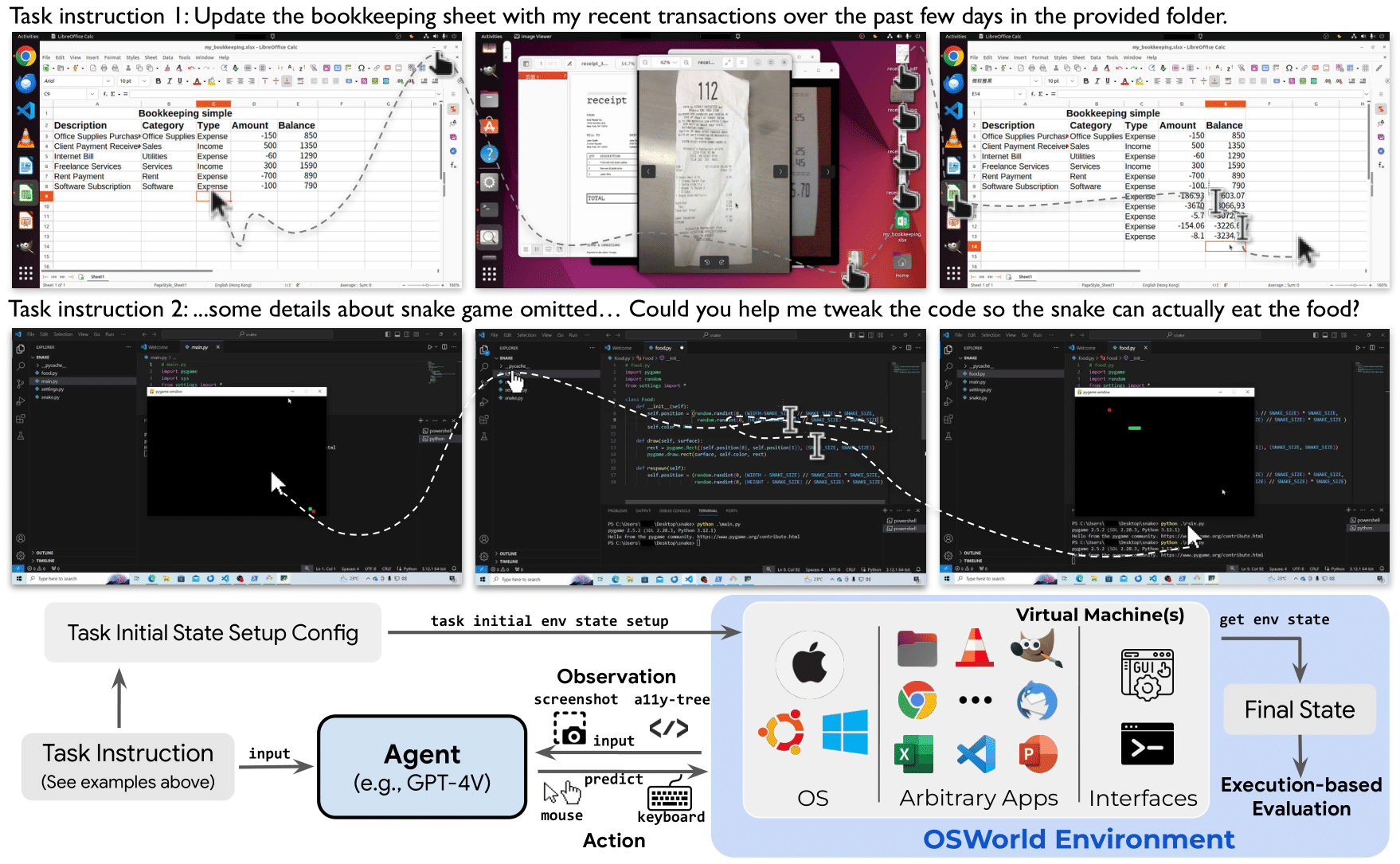
**OSWorld** is a first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across operating systems. It can serve as a unified environment for evaluating open-ended computer tasks that involve arbitrary apps (e.g., task examples in the above Fig). We also create a benchmark of 369 real-world computer tasks in **OSWorld** with reliable, reproducible setup and evaluation scripts.
Abstract
Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce **OSWorld**, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. **OSWorld** can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon **OSWorld**, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on **OSWorld** reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using **OSWorld** provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks.
OSWorld Environment Infrastructure
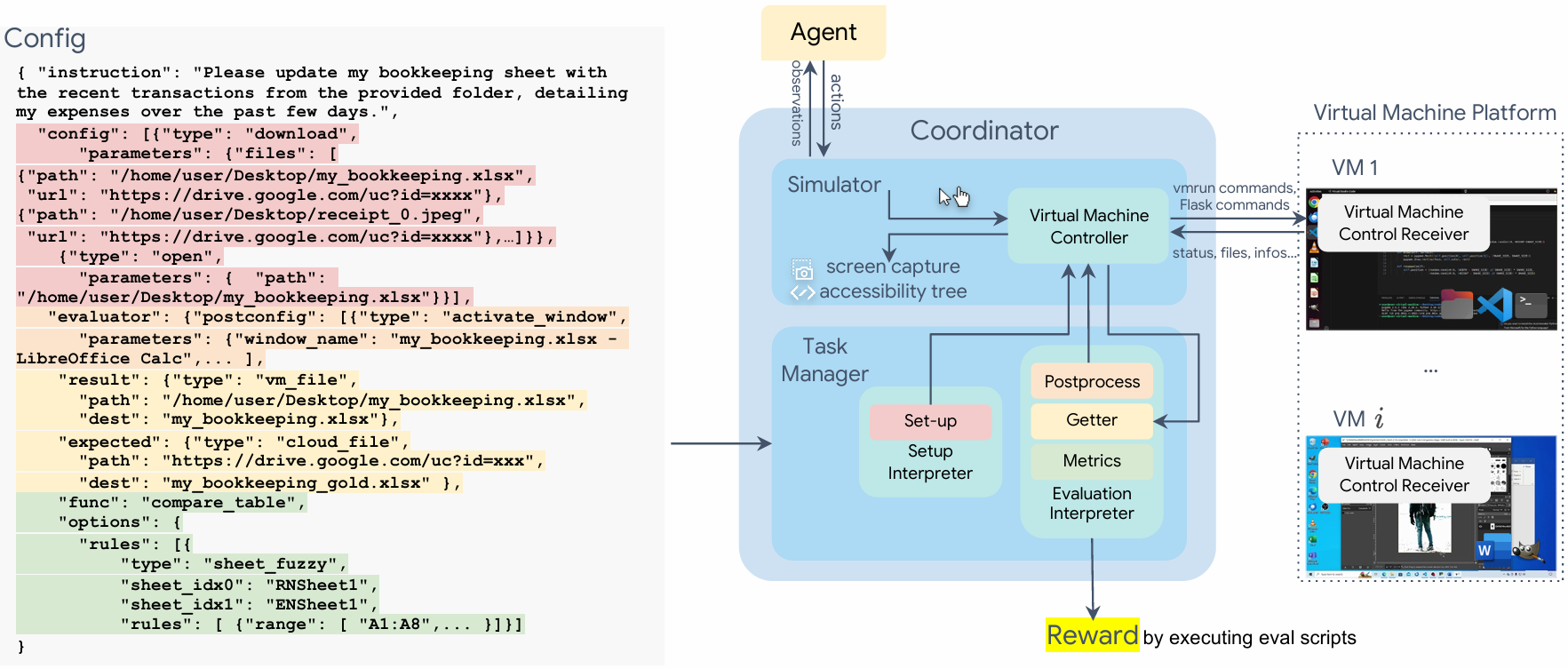
The **OSWorld** environment uses a configuration file for initializing tasks *(highlighted in red)*, agent interaction, post-processing upon agent completion *(highlighted in orange)*, retrieving files and information *(highlighted in yellow)*, and executing the evaluation function *(highlighted in green)*. The corresponding configuration items are highlighted in colors that match their respective components within the environment. Environments can run in parallel on a single host machine for learning or evaluation purposes. Headless operation is supported.
Data Statistics and Comparison
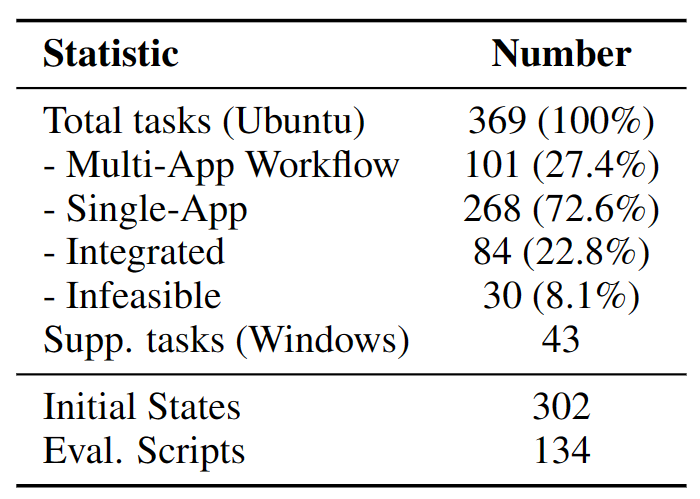
Below we present an overview of the main statistics of **OSWorld**, showcasing the outline and a broad spectrum of tasks. **OSWorld** contains a total of 369 tasks (and an additional 43 tasks on Windows for analysis).
Key statistics ofOSWorld.
The "Supp. tasks" refers to the Windows-based tasks, that could only be used after activation due to copyright restrictions.
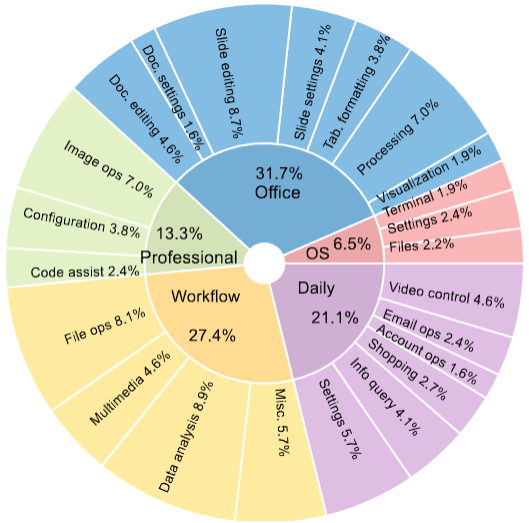
Distribution of task instructions in OSWorld
based on the app domains and operation types to showcase the content intuitively.
We make a comparison of **OSWorld** against some other different benchmarks for digital agents as presented below.
**The columns indicate:** whether they provide a controllable executable environment *(Control. Exec. Env.)*, the ease of adding new tasks involving arbitrary applications in open domains *(Environment Scalability)*, support for multimodal agent evaluation *(Multimodal Support)*, support for and inclusion of cross-app tasks *(Cross-App)*, capability to start tasks from an intermediate initial state *(Intermediate Init. State)*, and the number of execution-based evaluation functions *(# Exec.-based Eval. Func.)*.
| | OSWorld | | | -------------------------- | -------- | | # Instances (# Templates) | 369 | | Control. Exec. Env. | Computer | | Environment Scalability? | ✔️ | | Multimodal Support? | ✔️ | | Cross-App? | ✔️ | | Intermediate Init. State? | ✔️ | | # Exec.-based Eval. Func. | 134 |
Benchmark
We adopt state-of-the-art LLM and VLM from open-source representatives such as UI-TARS, Agent-S, Qwen, Mixtral and CogAgent, and closed-source ones from Operator, GPT, Gemini, and Claude families on **OSWorld**, as LLM and VLM agent baselines. We also explore methods such as the Set-of-Marks aided approach, which has been demonstrated to improve spatial capabilities for visual reasoning. **We are actively updating the benchmark with new LLMs, VLMs and methods. Pull requests welcomed!**
Analysis
We conduct a qualitative analysis in the aspect of models, methods, and human to find out factors influencing the performance of VLMs in digital agent tasks and their underlying behavioral logic. We investigate the impact of task attributes_(such as difficulty, feasibility, visual requirement, and GUI complexity), input measurements(such as screenshot resolution, the influence of trajectory history, and the effect of UI layout)_, and explore whether there are patterns in the agent's performance across different operating systems. Here is an overview of our analysis outcome.
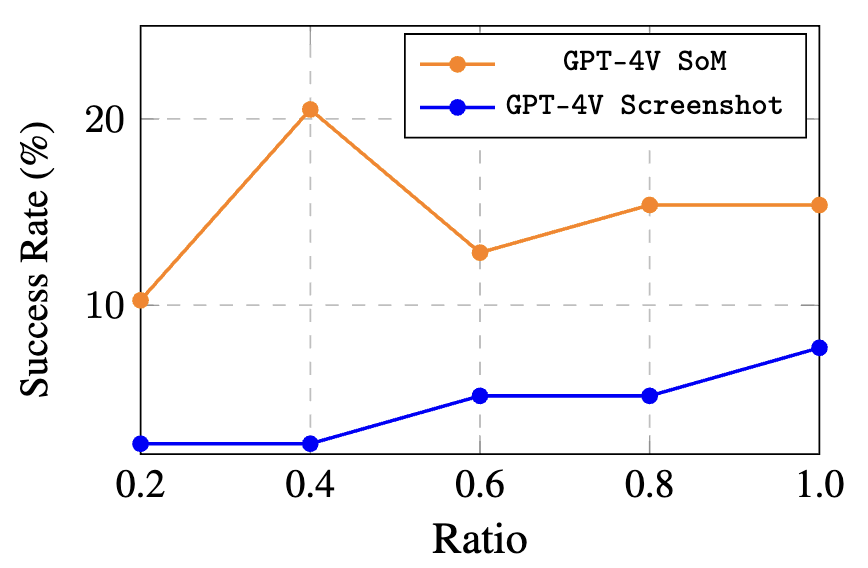
Higher screenshot resolution typically leads to improved performance.
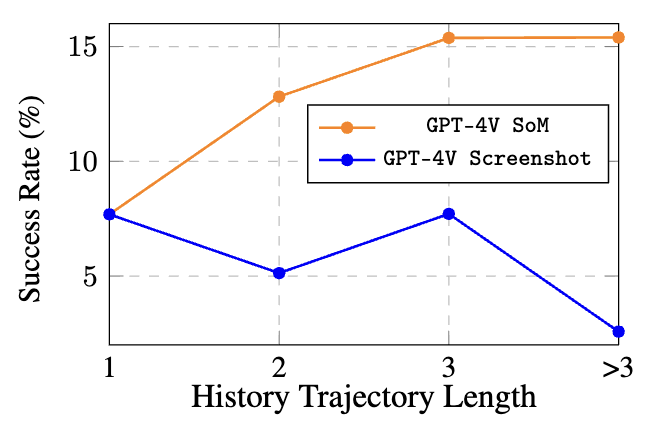
Longer text-based trajectory history context improves performance, unlike screenshot-only history, but poses efficiency challenges.
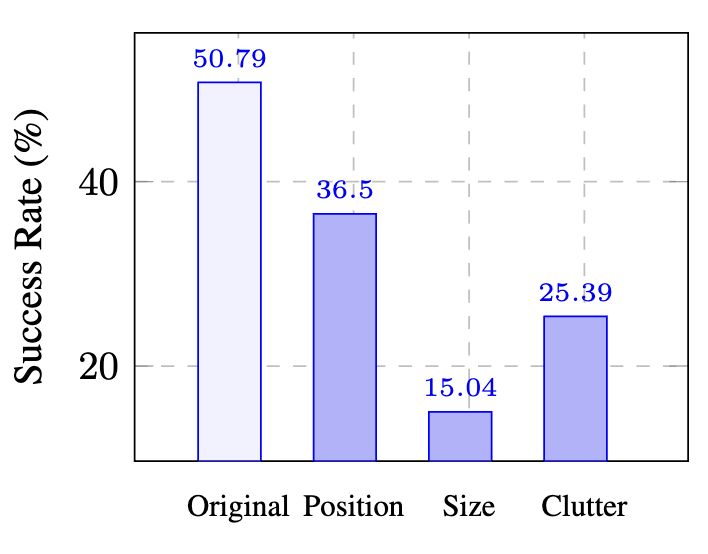
Current VLM agents are not robust to UI layout and noise.

The performance of VLM agents across different OS is in strong correlation. This implies that insights and methodologies developed within the OSWorld framework can be effectively transferred to Windows environments with a high degree of reliability.

A success case of LLM/VLM agent baselines.
Videos
Special thanks to the following YouTubers and enthusiasts for their reports. We are delighted to see the community's interest. If you would like a brief video introduction and their thoughts, feel free to check them out!
@Yannic Kilcher
@Wes Roth
@hu-po
@Dylan Curious
@WorldofAI
@Gourcer
@AI Explained
@Fireship
@1littlecoder
Acknowledgement
We thankSida Wang,Peter Shaw,Alane Suhr,Luke Zettlemoyer,Haoyuan Wu,Junli Wang,Chengyou Jia,Junlin Yang,Junlei Zhang,Chen Henry Wu,Pengcheng Yin, Shunyu Yao,Xing Han Lu, Siva Reddy, Ruoxi Sun, Zhiyuan Zeng, and Lei Li for their helpful feedback on this work
FAQ
What is the username and password for the virtual machines?
The username and password for the virtual machines are as follows:
- Ubuntu: user / password
- Windows: TBD
How to setup the account and credentials for Google and Google Drive?
See Account Guideline.
How can I configure a proxy for the VM if I'm behind a GFW?
See Proxy Guideline.
What are the running times and costs under different settings?
| Setting | Expected Time* | Budget Cost (Full Test Set/Small Test Set) |
|---|---|---|
| GPT-4V (screenshot) | 10h | 100(100 (100(10) |
| Gemini-ProV (screenshot) | 15h | 0 (0) |
| Claude-3 Opus (screenshot) | 15h | 150(150 (150(15) |
| GPT-4V (a11y tree, SoM, etc.) | 30h | 500(500 (500(50) |
*No environment parallelism. Calculated in April 2024.
BibTeX
@misc{OSWorld,
title={OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments},
author={Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu},
year={2024},
eprint={2404.07972},
archivePrefix={arXiv},
primaryClass={cs.AI}
}