PhysBench (original) (raw)
Benchmarking and Enhancing VLMs for
Physical World Understanding
1University of Southern California, 2UC Berkeley,3Toyota Research Institute
*Equal Contribution
ICLR 2025
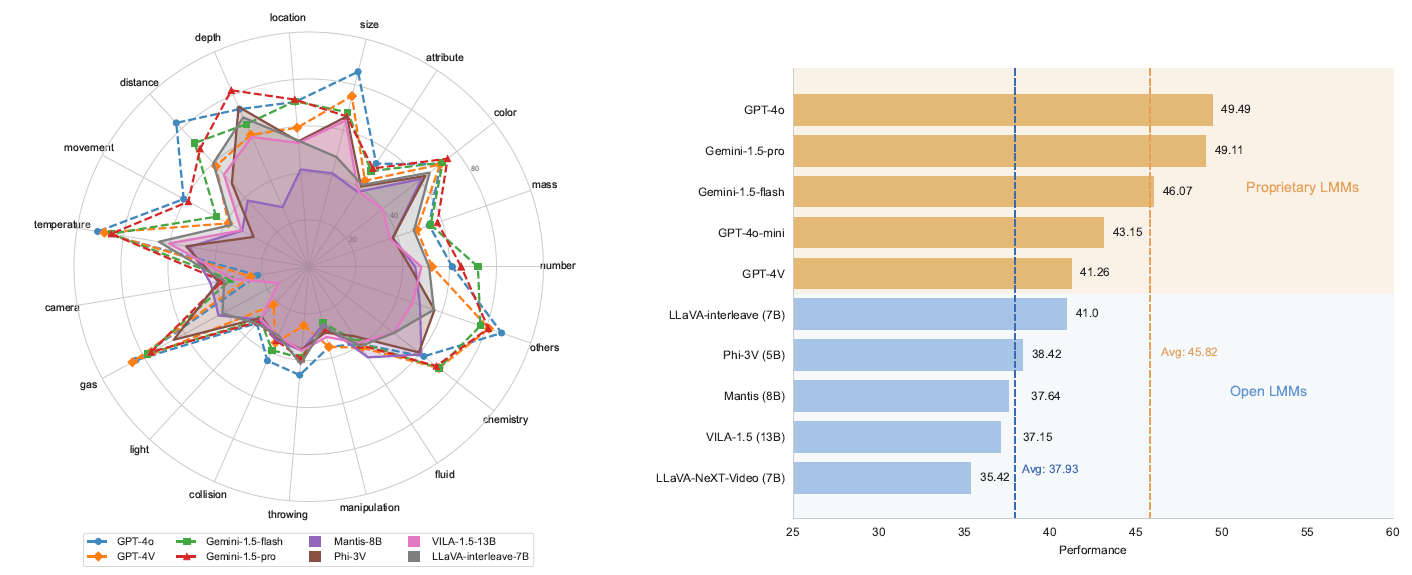
(a) The performance of 8 representative open-source VLMs across 19 sub-tasks in  PhysBench. The closer it is to the circular boundary, the better.
PhysBench. The closer it is to the circular boundary, the better.
(b) The overall performance of those 8 VLMs. Closed-source models generally perform better.

Common VQA tasks typically involve questions about visual content and general knowledge. PhysBench emphasizes understanding the physical world, encompassing 4 dimensions.
Introduction
Vision-Language Models (VLMs) have emerged as promising tools for building embodied agents, whereas their lack of physical world understanding hampers their effectiveness in real-world applications. To address this challenge, we present PhysBench, a comprehensive benchmark designed to evaluate and enhance VLMs' understanding of the physical world across diverse and complex tasks.
PhysBench is categorized into four major classes: physical object properties, physical object relationships, physical scene understanding, and physics-driven dynamics, covering 19 subclasses and 10 distinct capability dimensions.
Our extensive experiments on 75 representative VLMs reveal significant gaps in physical world understanding, likely due to the absence of physical knowledge in their training data. To improve VLMs' physical understanding, we propose an agent-based method called PhysAgent, which leverages prior physical knowledge and expert model assistance to enhance physical world understanding capabilities.
Furthermore, we demonstrate that improving VLMs’ understanding of the physical world can significantly facilitate the deployment of embodied agents in real-world scenarios, moving towards bridging the gap between human and machine intelligence in comprehending the physical world.
Leaderboard on PhysBench
Accuracy scores for General VLM on the test subset (10,002 entries) of PhysBench.
Accuracy scores for Image VLM and Video VLM on the test subset without interleaved data entries (8,099 entries) of PhysBench.
Method types: Seq ⏩: Sequential input of images after frame selection from videos,, Merge 🖼️: merging video frames into a single image
🚨 To submit your results to the leaderboard, please send to this email with your result json files.
🚨 For more submission details, please refer to this link and this link.
PhysBench Dataset
Overview
We propose PhysBench, which comprehensively evaluates VLMs' perception of the physical world across four major task categories:
- (1) Physical Object Properties: Assessment of physical attributes of objects such as mass, size, density, tension, friction, bending stiffness, elasticity, and plasticity.
- (2) Physical Object Relationships: Evaluation of spatial relationships involving object movement, speed, and position.
- (3) Physical Scene Understanding: Interpretation of environmental factors, including light sources, viewpoints, temperature, and so on.
- (4) Physics-based Dynamics: Understanding of physical events like collisions, throwing, fluid dynamics, explosions, and similar phenomena.

Sampled PhysBench examples from four major dimensions

A comparison between PhysBench. and other physical understanding question-answering benchmarks reveals that PhysBench is a comprehensive dataset, covering a wide range of tasks related to physical world understanding.
The complete PhysBench is organized into 19 subclasses and 10 distinct capability dimensions. You can download the dataset on Hugging Face Dataset.
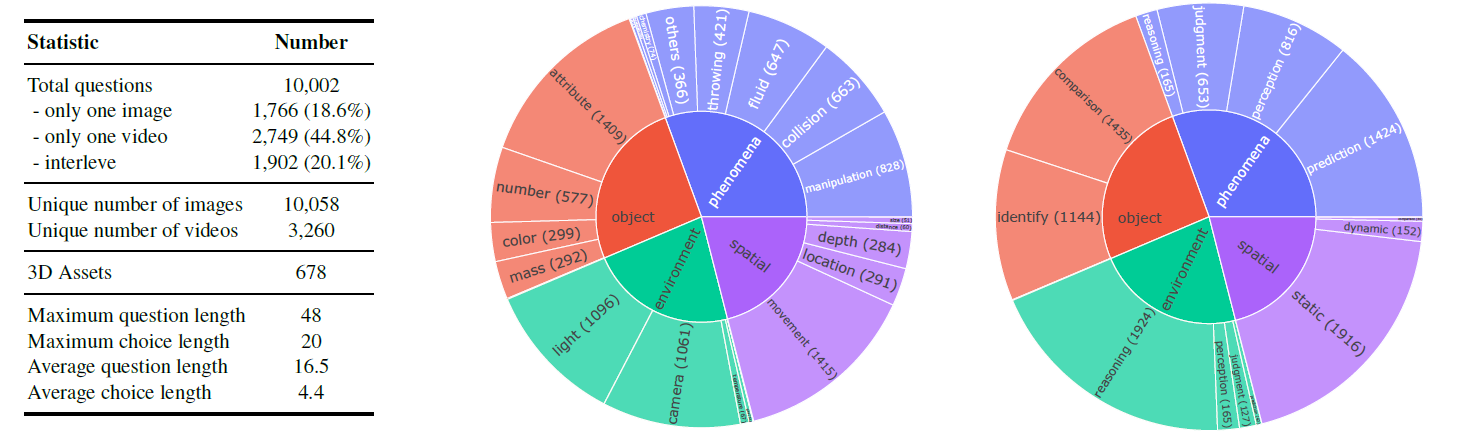
Key statistics of PhysBench.
Statistics
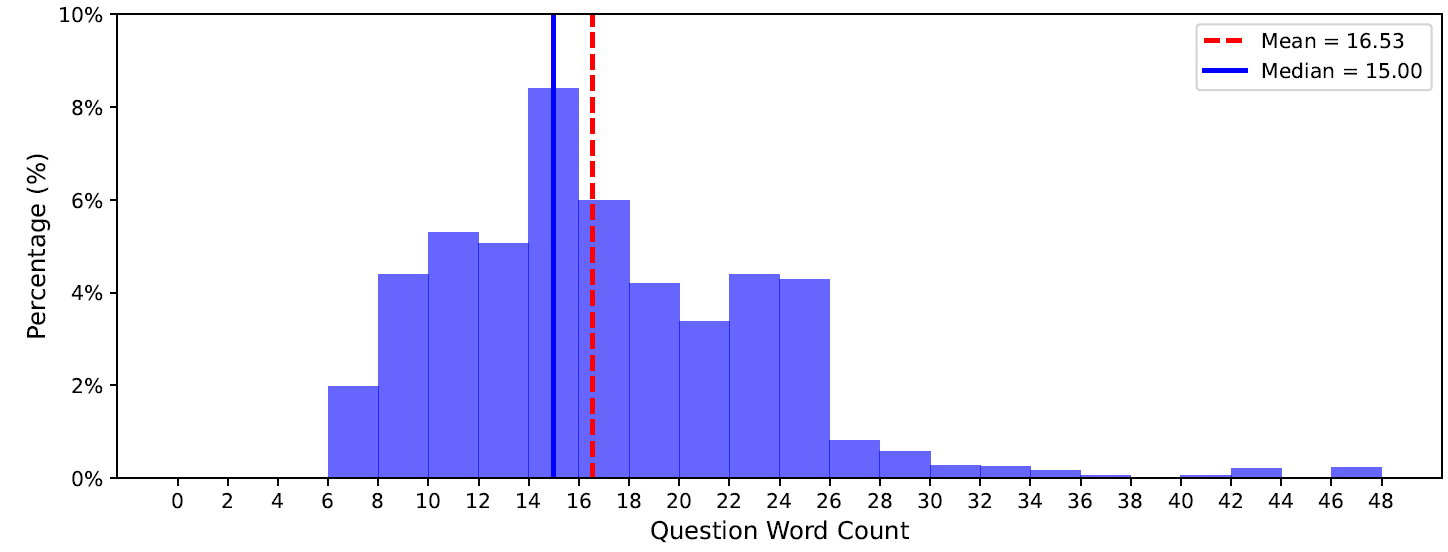
The distribution of the number of words per question in PhysBench.
Questions with a length greater than 48 are categorized as 47 for visualization simplicity.
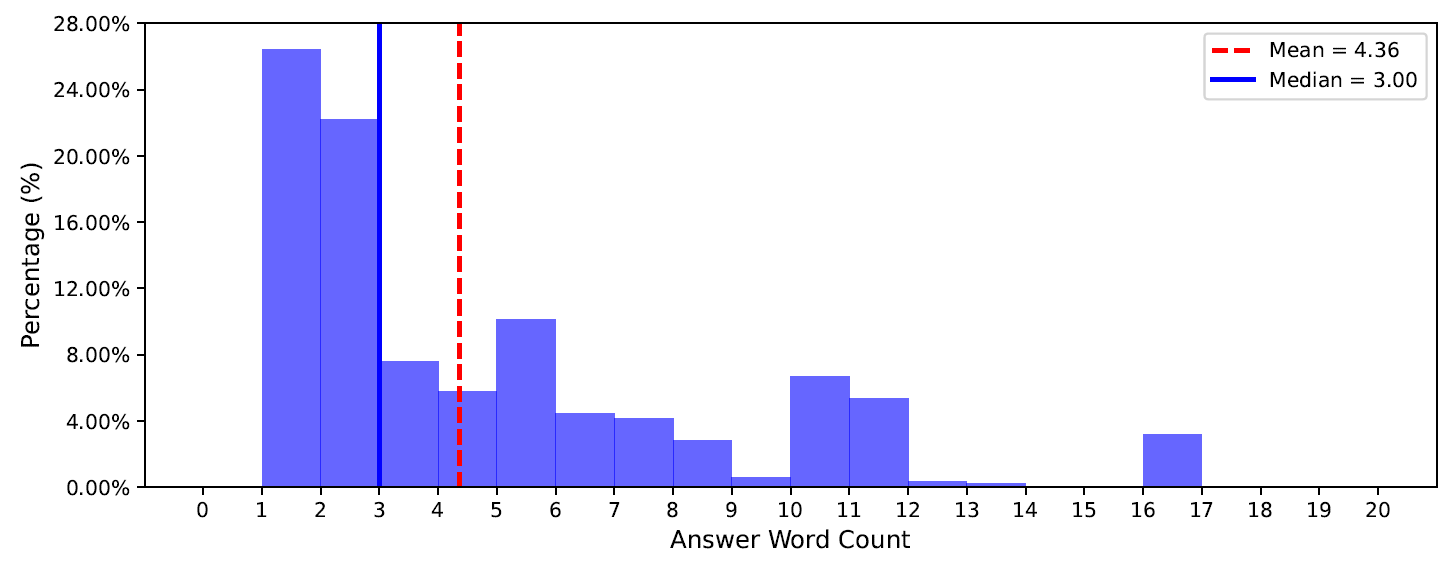
The distribution of the number of words per question in PhysBench.
Options with a length greater than 20 are categorized as 20 for visualization simplicity.
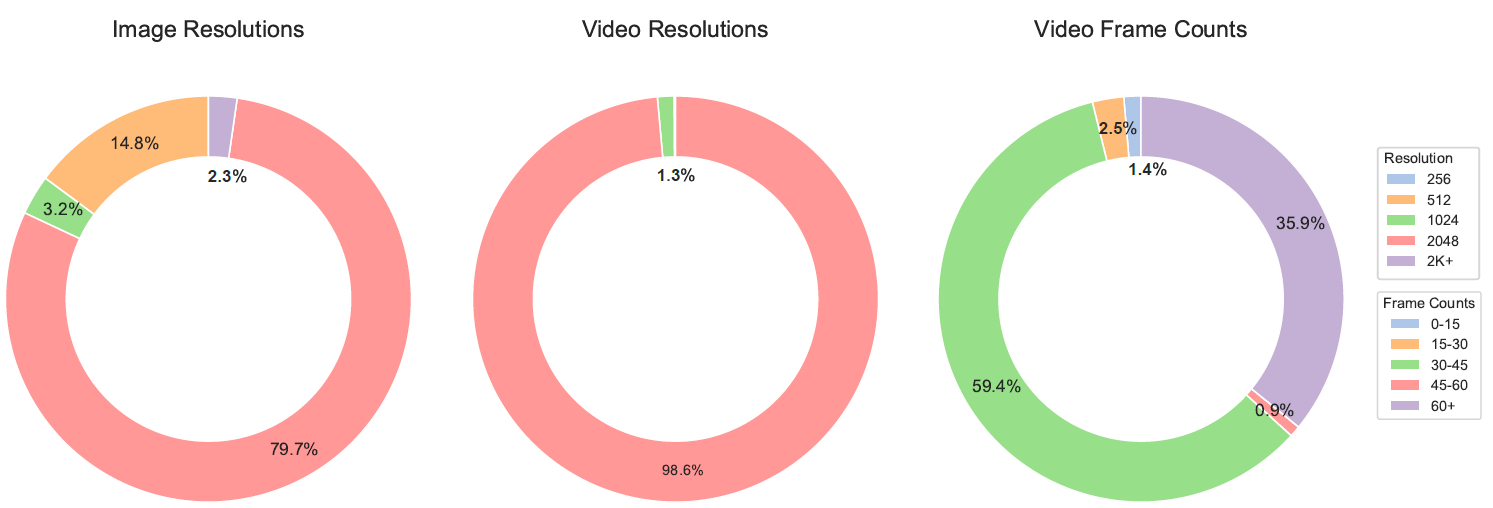
The distribution charts for image and video resolution, as well as video frame counts.
From left to right: the distribution of image resolution,
the distribution of video resolution, and the distribution of video frame counts.
Can VLMs Understand the Physical World?
To assess whether VLMs can understand the physical world, we evaluated 75 representative VLMs on PhysBench and found that:
- VLMs exhibit limited understanding of the physical world.
- Closed-source models generally perform better.
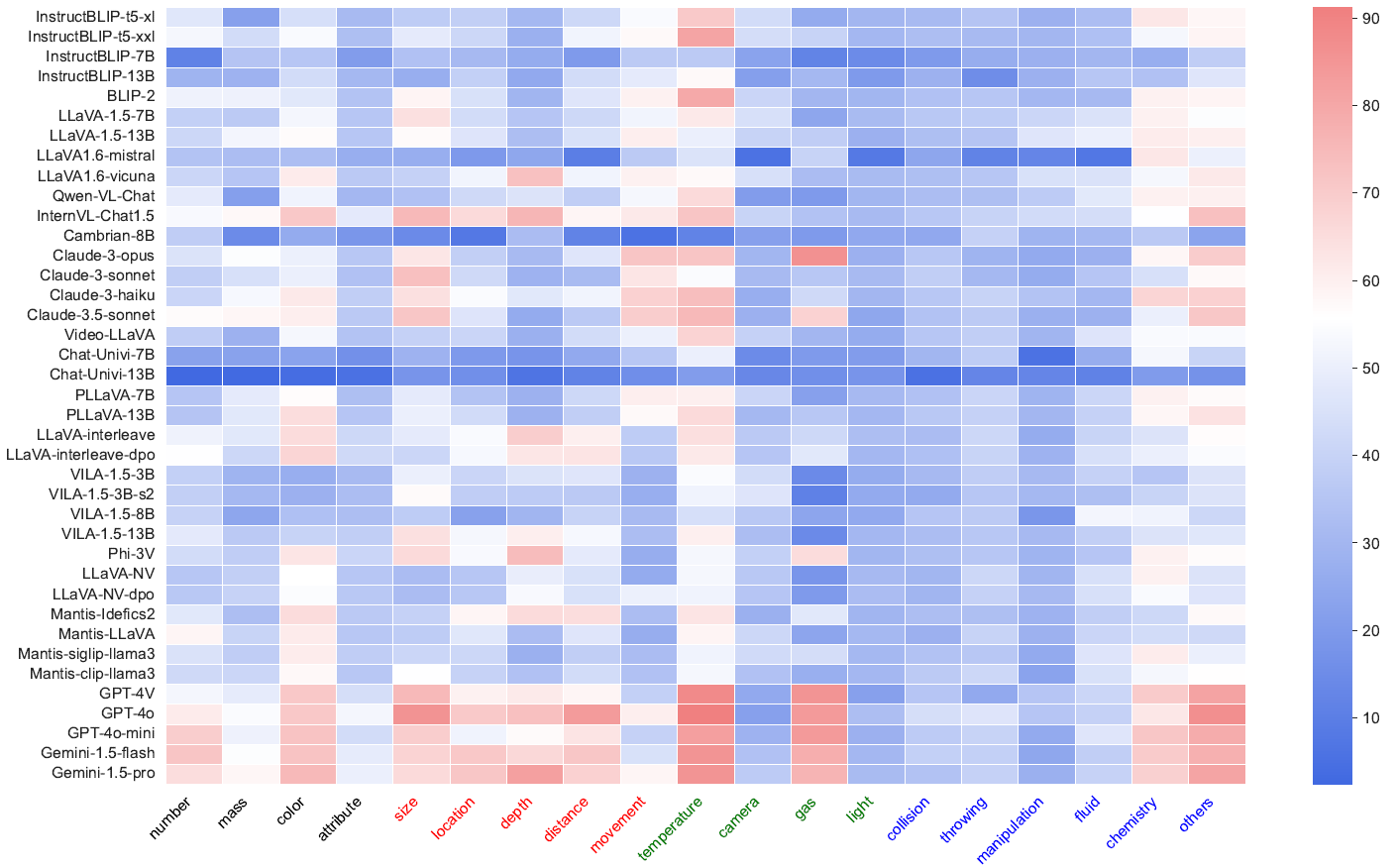
The visualization of model performance across 19 sub-tasks is presented, where different colors represent the respective categories.
The four colors, from left to right, represent physical object properties, physical object relationships, physical scenes, and physical-based dynamics.
Why Do VLMs Struggle with Physical World Understanding?
To assess whether VLMs can understand the physical world, we evaluated 75 representative VLMs on PhysBench and found that:
- Physical world understanding differs significantly from common VQA tasks. We established a correlation map with the common VQA benchmark. Our analysis identifies a notable distinction between PhysBench and traditional VLM benchmarks, with PhysBench demonstrating a closer alignment with MMMU, which necessitates complex reasoning and diverging from the majority of other benchmarks.
- VLMs's physical world understanding ability does not scale with model size, data, or frames.While keeping the data size constant, increasing the model size or, alternatively, increasing the data size while keeping the model size unchanged, led to inconsistent results. Similarly, increasing the number of frames also yielded unstable outcomes.
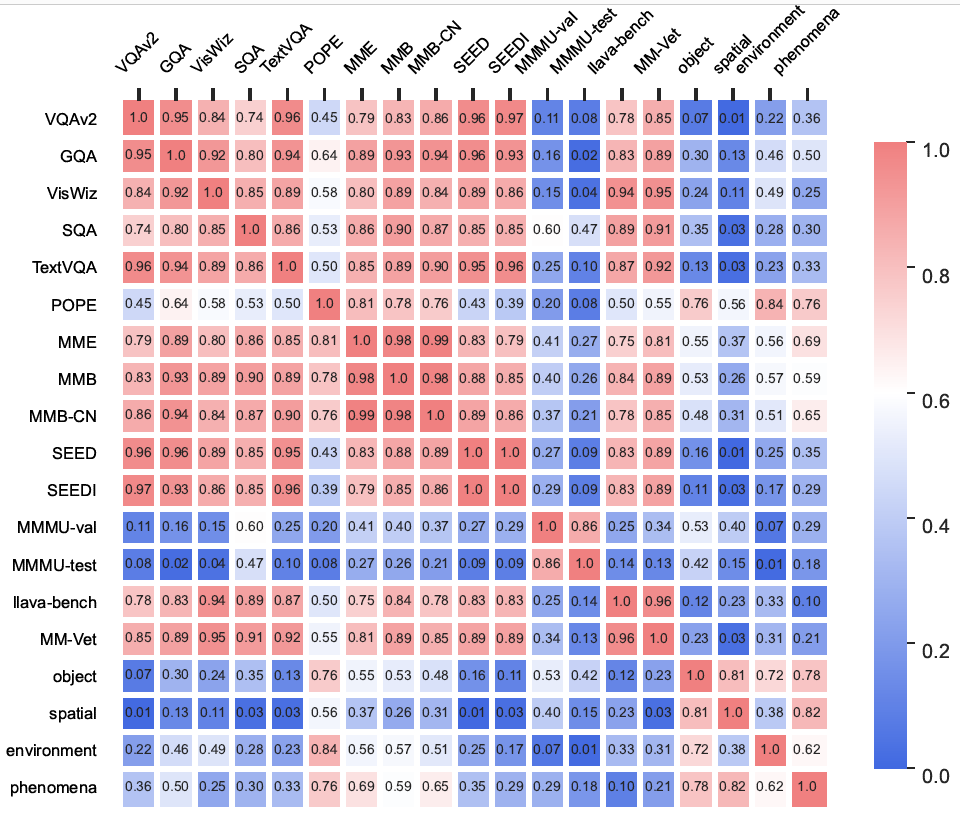
Correlation map between 4 tasks in PhysBench. and 15 other vision-language benchmarks.
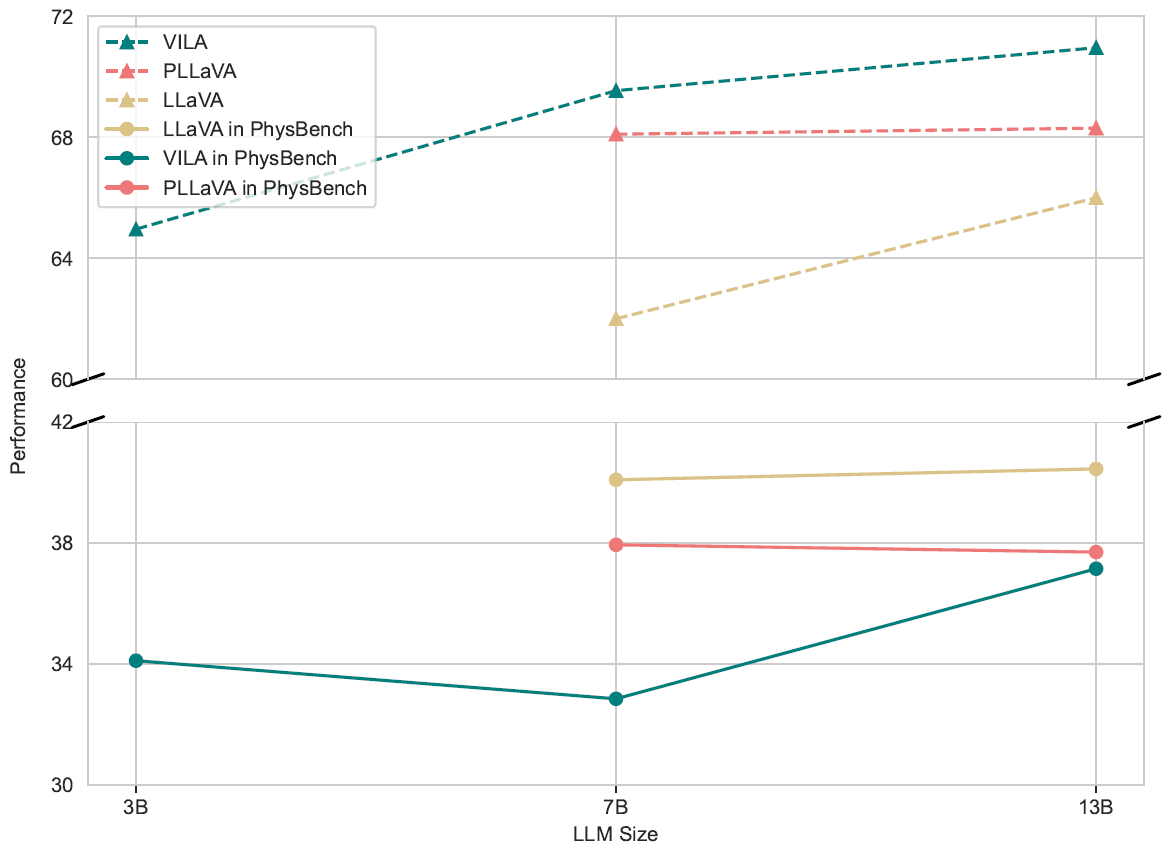
Model Size Scalability.
Data Scalability.
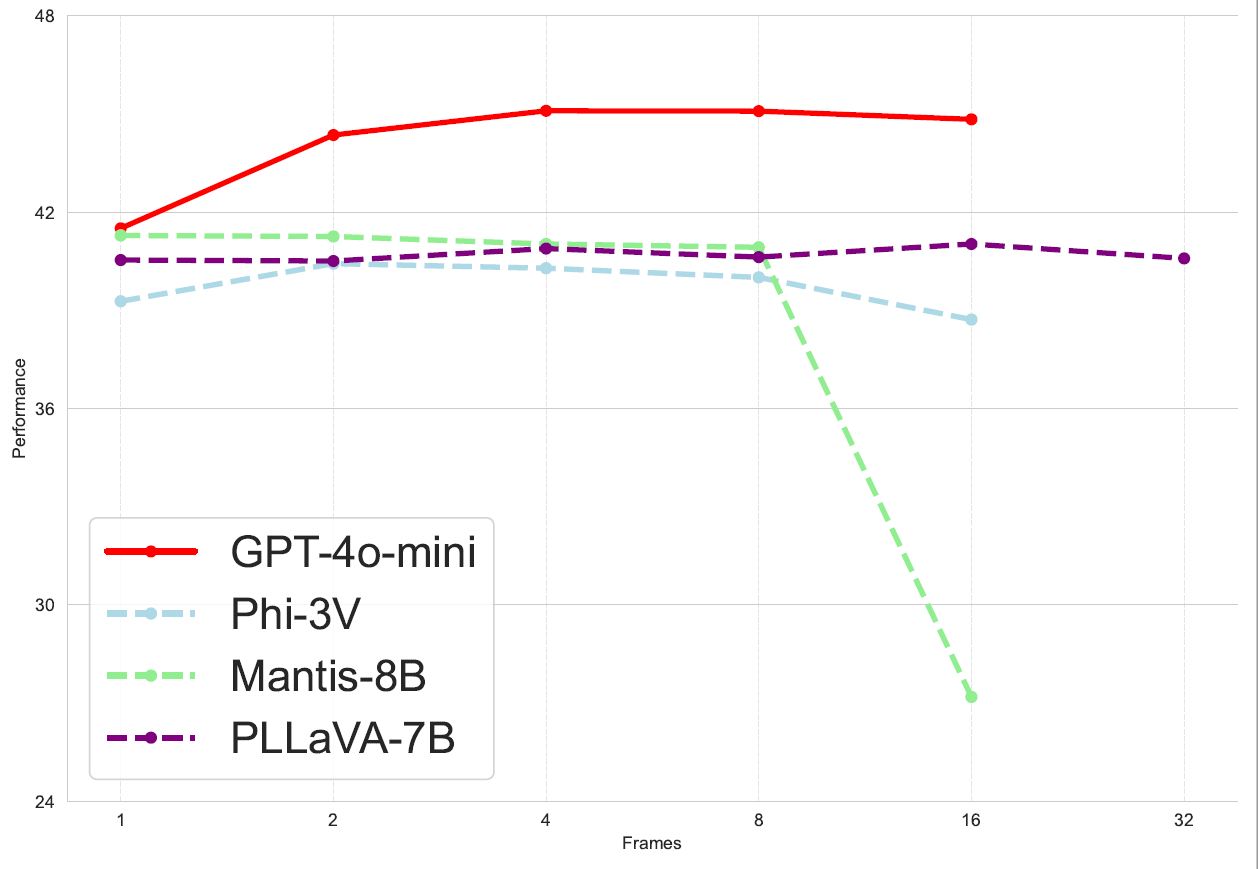
Frame Scalability.
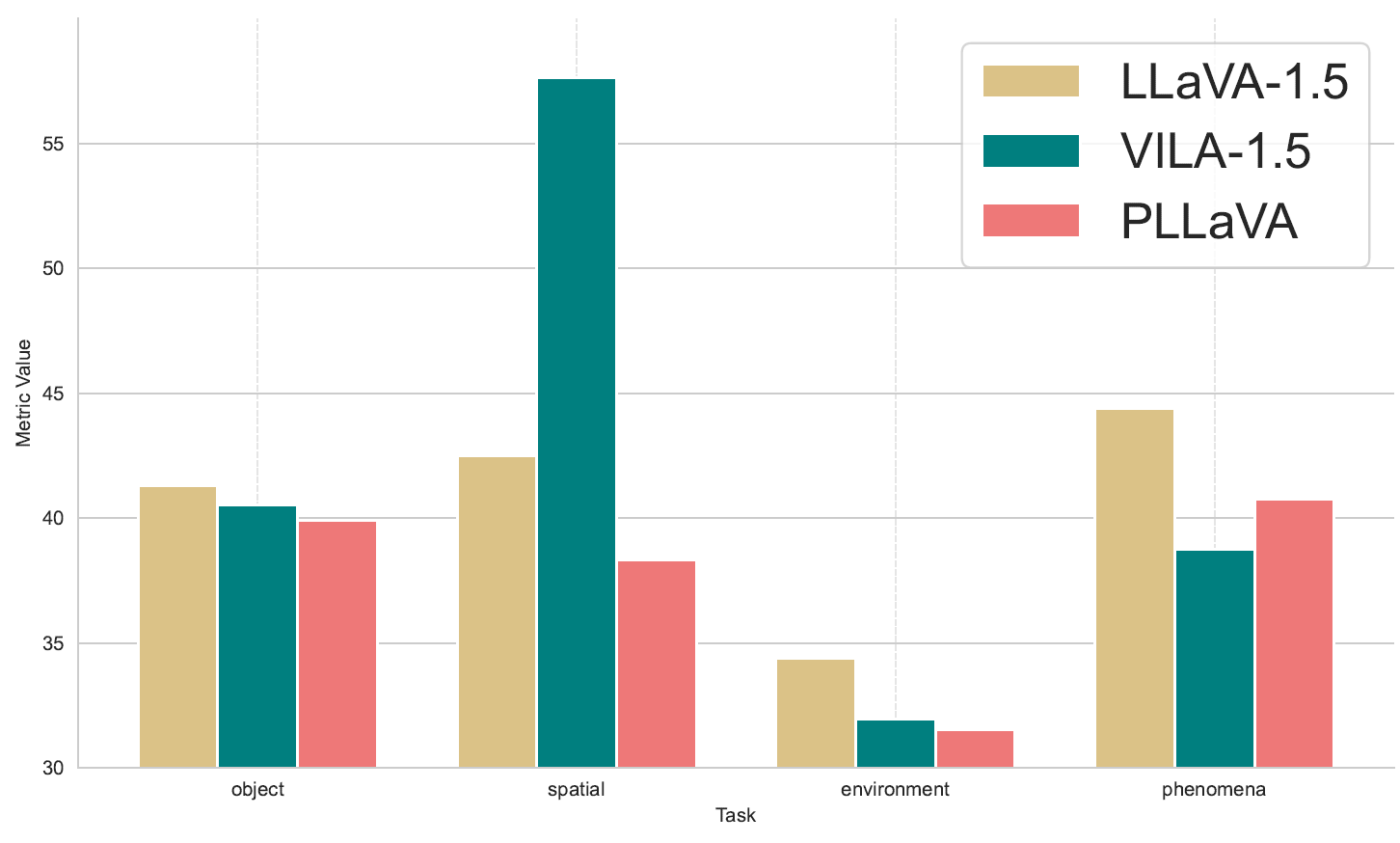
We were perplexed by the fact that increasing the amount of training data did not improve the VLM's understanding of the physical world. To investigate further, we examined the training datasets of LLaVA-1.5, VILA-1.5, and PLLaVA-1.5 and identified a lack of physical world knowledge in these datasets. Additionally, keywords frequently encountered in PhysBench are notably rare in the training data of these model.This deficiency in relevant data likely contributes to the VLM's poor comprehension of physical world concepts. We further support this hypothesis by analyzing the error distribution and fine-tuning the VLM in subsequent experiments.
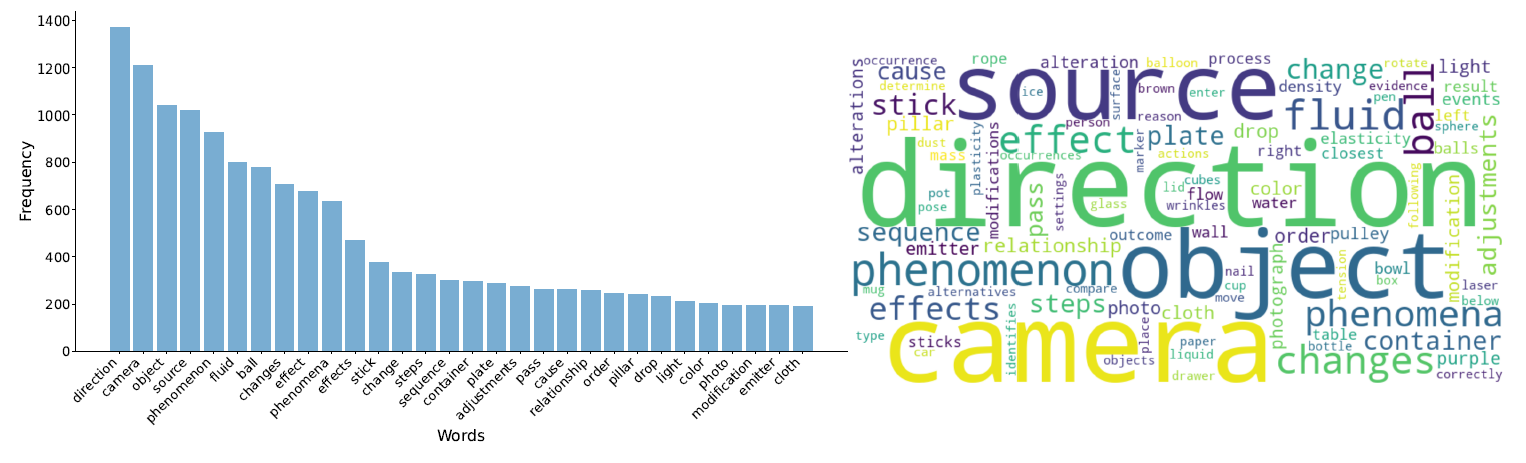
Word Statics and Word Cloud for PhysBench.
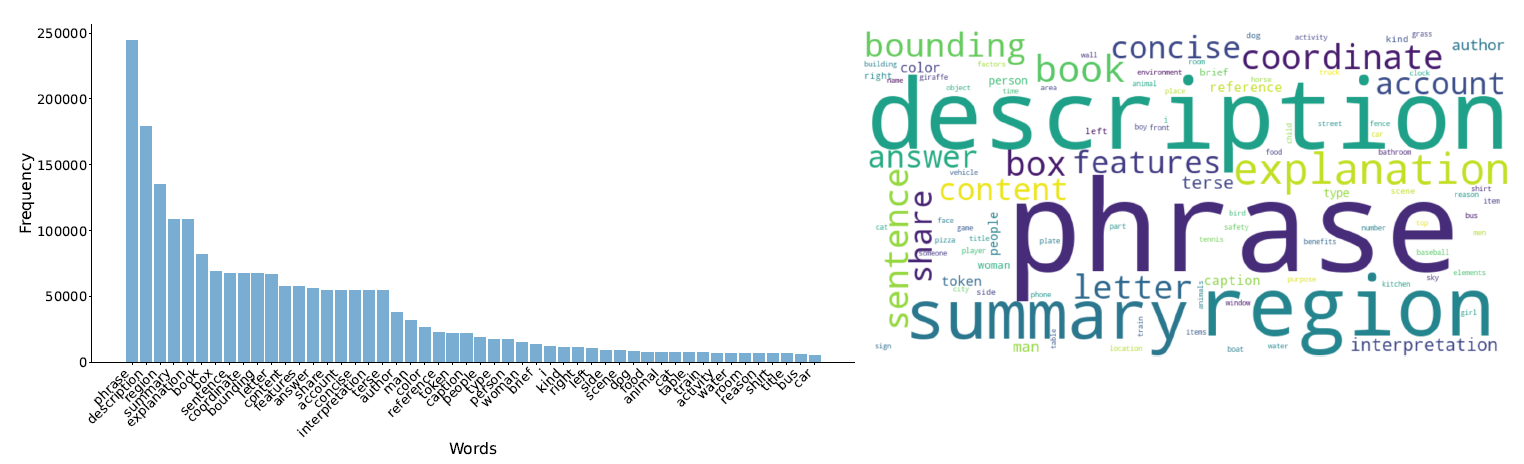
Word Statics and Word Cloud for LLaVA-1.5-13B Training Data.
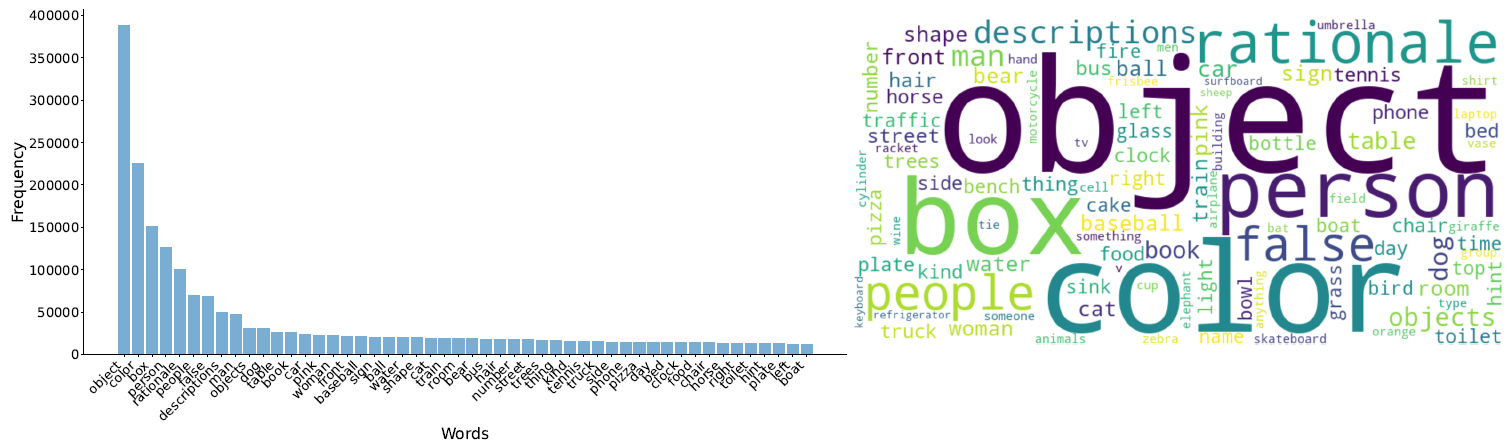
Word Statics and Word Cloud for VILA-1.5-13B Training Data.
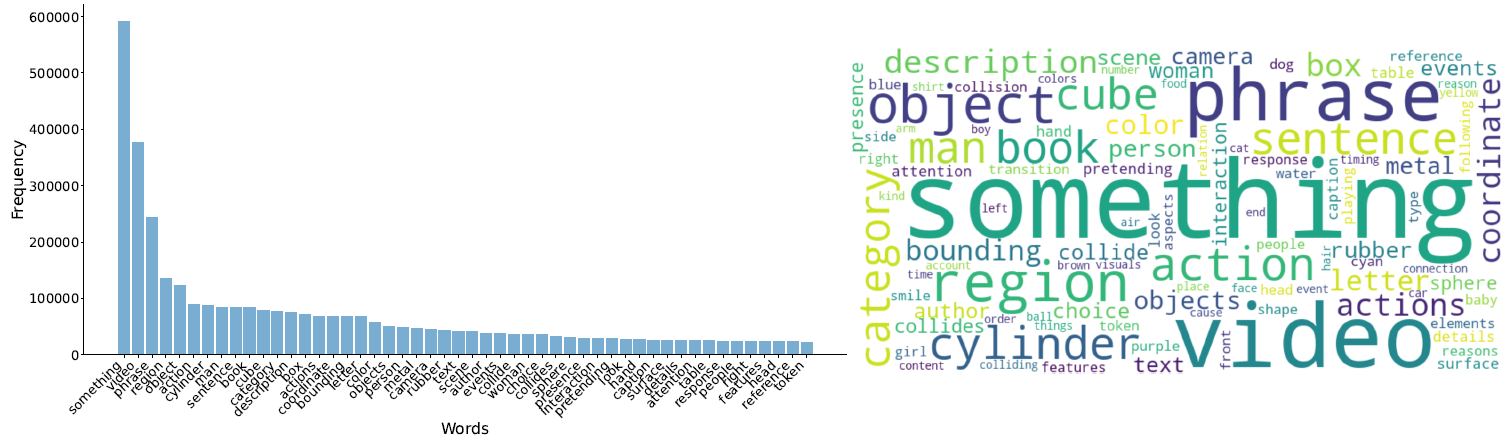
Word Statics and Word Cloud for PLLaVA-13B Training Data.
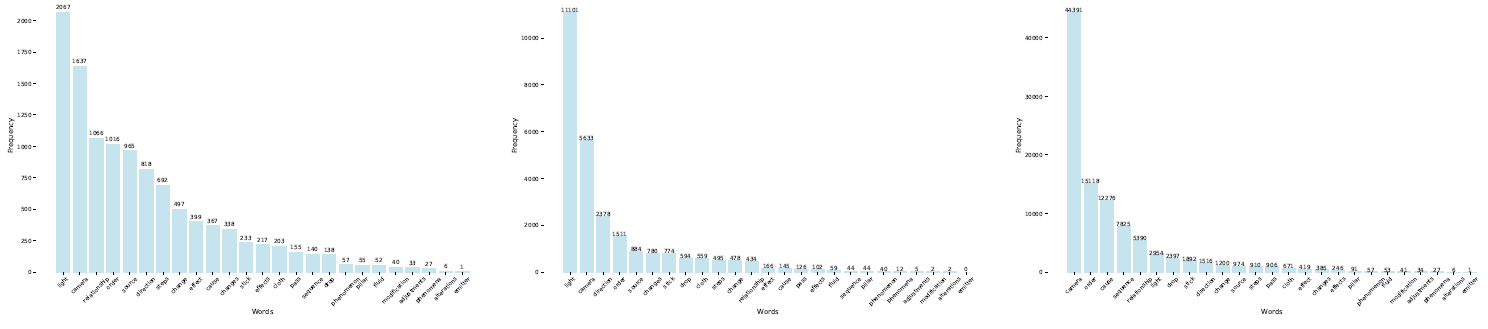
The frequency of common terms in PhysBench within the training data of the LLaVA-1.5-13B, VILA-1.5-13B, and PLLaVA-13B models.
To investigate the poor performance of VLMs on PhysBench, we randomly selected 500 questions and obtained explanations from three models—GPT-4o, Phi-3V, and Gemini-1.5-flash. Expert annotators classified the root causes of the mispredictions into six categories: perception errors, reasoning errors, lack of knowledge, refusal to answer, failure to follow instructions, and annotation errors in the dataset. We find that perceptual and knowledge gaps constitute the majority of errors.
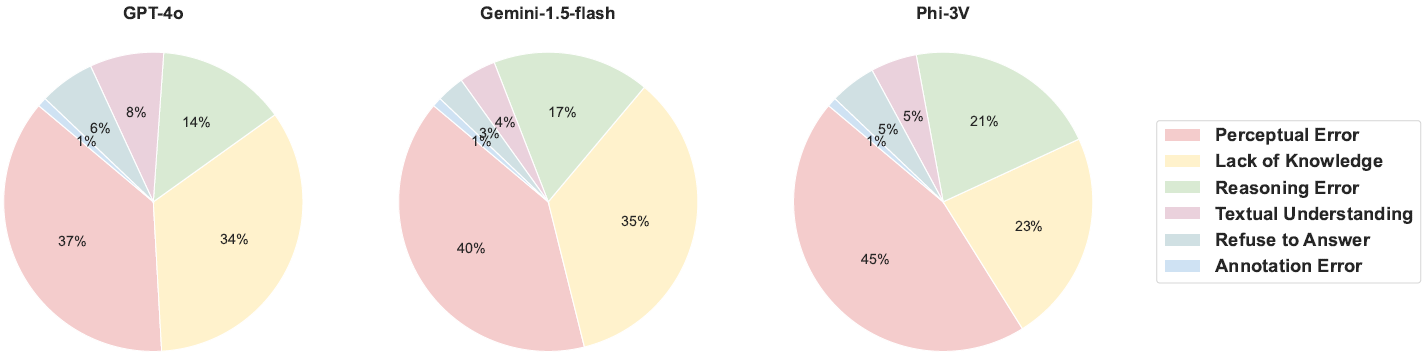
Distribution of error types for GPT-4V, Gemini-1.5-flash, Phi-3V.
Our error analysis revealed that inadequate physical world knowledge and reasoning capabilities were key contributors to the models’ poor performance. To investigate whether introducing additional examples could enhance performance, we conducted tests on 200 entries of PhysBench, pairing each with a similar example. These additional examples were incorporated through fine-tuning or in-context learning. As shown in the below figure, the performance improvements after adding physical world knowledge examples indicate that VLMs can transfer physical knowledge to some extent. This suggests that the original data’s lack of physical world knowledge was a significant factor in the models’ suboptimal performance.
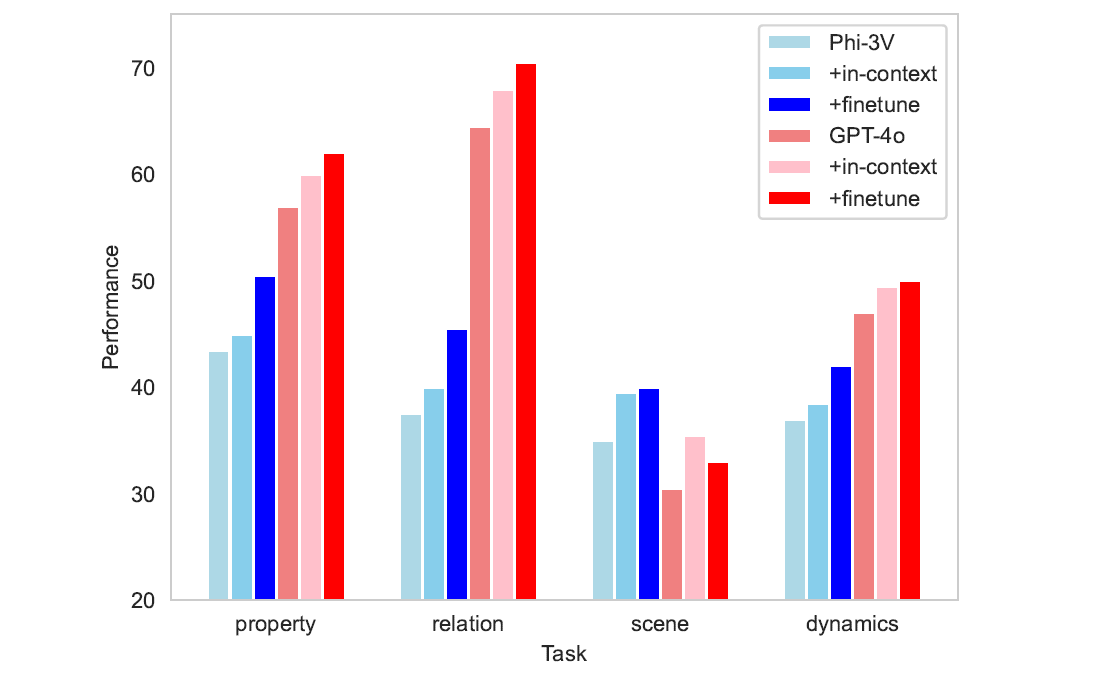
Physics knowledge transfer study.
BibTeX
@article{chow2025physbench,
title={PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding},
author={Chow, Wei and Mao, Jiageng and Li, Boyi and Seita, Daniel and Guizilini, Vitor and Wang, Yue},
journal={arXiv preprint arXiv:2501.16411},
year={2025}
}