Extensions of net reclassification improvement calculations to measure usefulness of new biomarkers (original) (raw)
. Author manuscript; available in PMC: 2012 May 2.
Published in final edited form as: Stat Med. 2010 Nov 5;30(1):11–21. doi: 10.1002/sim.4085
Summary
Appropriate quantification of added usefulness offered by new markers included in risk prediction algorithms is a problem of active research and debate. Standard methods, including statistical significance and c statistic are useful but not sufficient. Net reclassification improvement (NRI) offers a simple intuitive way of quantifying improvement offered by new markers and has been gaining popularity among researchers. However, several aspects of the NRI have not been studied in sufficient detail.
In this paper we propose a prospective formulation for the NRI which offers immediate application to survival and competing risk data as well as allows for easy weighting with observed or perceived costs. We address the issue of the number and choice of categories and their impact on NRI. We contrast category-based NRI with one which is category-free and conclude that NRIs cannot be compared across studies unless they are defined in the same manner. We discuss the impact of differing event rates when models are applied to different samples or definitions of events and durations of follow-up vary between studies. We also show how NRI can be applied to case-control data. The concepts presented in the paper are illustrated in a Framingham Heart Study example.
In conclusion, NRI can be readily calculated for survival, competing risk, and case-control data, is more objective and comparable across studies using the category-free version, and can include relative costs for classifications. We recommend that researchers clearly define and justify the choices they make when choosing NRI for their application.
Keywords: discrimination, model performance, NRI, risk prediction, biomarker
1. Introduction
Risk prediction models are key components of prevention strategies adopted in a wide range of medical fields. Risk scores exist for cardiovascular disease and its component diseases (coronary heart disease, stroke, atrial fibrillation), different forms of cancer, hypertension, diabetes and many others [1-7]. These algorithms led to substantial advances in reduction of disease burden by education, prevention and treatment. However, at the same time, there is ample opportunity for improvement as in many instances intermediate and lower risk groups contribute the highest numerical numbers of events. Hence, researchers have been looking for new biomarkers and genetic factors that could improve risk prediction. Multitudes of candidate genotypic and phenotypic markers had been postulated and it quickly became apparent that existing statistical methods may not be sufficient to determine which of these new markers were actually useful. Standard methods proved either too liberal: significance of p-value is achieved easily in large sample or genetic studies, or too conservative: area under the curve (AUC) or c statistic hardly moves after a few good risk factors are already included in the model. Some researchers introduced a distinction between risk prediction and risk classification and suggested that measures going beyond statistical significance and c statistic are necessary [8].
To overcome these shortcomings Pencina and D’Agostino et al. [9] proposed two new measures to quantify the degree of correct reclassification: net reclassification improvement (NRI) and integrated discrimination improvement (IDI). They were developed for dichotomous outcomes and details can be found in [9]. Many interesting properties and extensions of the IDI have been presented in the statistical literature [10-12]. On the other hand, the NRI seems to have gained popularity in medical journals, most likely due to its simplicity [7, 13]. However, several issues have not been addressed with regard to NRI and its correct applications. These are the focus of the current paper.
Since many commonly used risk prediction models are based on time-to-event data, it is imperative to have an estimator of NRI applicable to survival data, which contains not only events and non-events, but also subjects who discontinue the study prematurely [14, 15]. Furthermore, extensions to competing risk models would be valuable given increasing interest in long-term risk prediction [16]. Similarly, extensions of NRI to case-control data is needed, as many biomarker studies are conducted using this design. The issue of weighting used in the calculation of NRI has been raised by several authors [12, 17, 18] and requires attention. The number and choice of categories and their impact on the magnitude and conclusions derived from the use of NRI merit special consideration. It is likely that these two may heavily influence observed values of NRI. Moreover, it is possible to define NRI without the use of categories and properties of such metric should be explored. Finally, we need to address the effect of event rates on the magnitude of NRI, particularly in the context of calculations based on a validation sample.
In the following we propose a prospective formulation for the NRI which offers immediate application to survival and competing risk data as well as allows for easy weighting with observed or perceived costs. Furthermore, we address the issue of the number and choice of categories on NRI and contrast category-based NRI with one which is category-free. We discuss the issues of validation and event rate when models are applied to different samples or when incidence or prevalence and duration of follow-up vary between studies. We also show how NRI can be applied to case-control data. The concepts presented in the paper are illustrated in a Framingham Heart Study example with the same data and risk prediction model that was used in the original NRI paper [9] for easy comparisons.
1. Prospective form of NRI
Consider a situation in which predicted probabilities of a given event of interest come from two different risk prediction algorithms denoted here as “new” and “old”. Divide the predicted probabilities based on these two algorithms into a set of clinically meaningful ordinal categories of absolute risk and then cross-tabulate these two classifications. Define upward movement (up) as a change into higher category based on the new algorithm and downward movement (down) as a change in the opposite direction. The net reclassification improvement is defined as:
| NRI=P(up∣event)−P(down∣event)+P(down∣nonevent)−P(up∣nonevent) | (1) |
|---|
Using the Bayes rule we re-write formula (1) in a different but equivalent form:
| NRI=P(event∣up)·P(up)−P(event∣down)·P(down)P(event)+P(nonevent∣down)·P(down)−P(nonevent∣up)·P(up)P(nonevent) | (2) |
|---|
Substitute P(nonevent) = 1-P(event) and P(nonevent∣*) = 1 − P(event∣*), where * denotes ‘up’ or ‘down’, we obtain:
| NRI=P(event∣up)·P(up)−P(event∣down)·P(down)P(event)+(1−P(event∣down))·P(down)−(1−P(event∣up))·P(up)1−P(event) | (3) |
|---|
After some simplification the above reduces to:
| NRI=(P(event∣up)−P(event))·P(up)+(P(event)−P(event∣down))·P(down)P(event)·(1−P(event)) | (4) |
|---|
So far NRI (1) was presented as a sum of two components, one for events and one for non-events with weighting proportional to event incidence. This suggested a “retrospective” interpretation of the index for incidence studies. The above expression changes to “prospective” interpretation and allows for broad set of definitions of reclassification that can be accommodated. This new formulation of the NRI requires a reclassification rule and then calculation of event rates among those who are reclassified upwards, downwards and the whole sample. It can be interpreted as a measure of event rate increase among those who are reclassified upwards and event rate decrease among those who are reclassified downwards.
The extension of formulas (3) or (4) to survival analysis is immediate, with P(event), P(event∣up) and P(event∣down) all estimated using the Kaplan-Meier approach. Proportions of people moving up and down (i.e. P(up) and P(down)) are always available, so the computation of NRI according to formulas (3) or (4) is straightforward. Of note, equations (3) and (4) also allow for application to competing risk models with Kaplan-Meier rates adjusted for the competing risk (cf. Gaynor et al. [19]).
Assuming that out of a total of n individuals, nU are reclassified upwards and nD downwards, (3) can be written as:
| NRI=P(event∣up)·nU−P(event∣down)·nDn·P(event)+(1−P(event∣down))·nD−(1−P(event∣up))·nUn·(1−P(event)) | (5) |
|---|
The quantities in the numerators represent expected numbers of events reclassified upwards and downwards (first numerator) and expected numbers of non-events reclassified downwards and upwards (second numerator). The denominators are total expected cases of events and non-events, respectively. This is a representation analogous to the one proposed by Steyerberg and Pencina [15] for applications of NRI to survival models. Formula (5) does not depend on the number or even existence of risk categories as it assumes probabilities of event among those reclassified upwards or downwards would be obtained pooling all individuals with the same reclassification. Read literally, the approach of Steyerberg and Pencina [15] assumed the existence of risk categories and proposed calculation of Kaplan-Meier estimators within each cell of the reclassification table. For large samples both approaches are equivalent; for smaller samples the one presented here might be preferable due to elimination of cells with very small numbers of events. As mentioned before, what we present here is more general, not requiring the existence of categories. We address this point further in section 4.
2. Cost considerations and weighted NRI
In his commentary to the original NRI article, Greenland [17] suggested that the measure would be more meaningful if cost considerations were taken into account. Here we propose a weighted form of the NRI (wNRI) which builds in cost considerations.
Assume that the savings associated with the upward reclassification of a person who eventually develops an event can be quantified by s1 while the savings associated with downward reclassification of a person who does not develop an event can be quantified by s2. In the simplest case of two risk categories s1 can be viewed as the savings which result from starting treatment for a person bound to have an event and s2 as savings from avoiding unnecessary treatment in non-events. When there are more than 2 categories, estimating s1 and s2 that are common for all upward and downward reclassification may not be possible and a finer partition of costs may be necessary leading to a definition that looks more like the one given in [15].
Here, however, the total savings expected from the use of the new rather than the old risk prediction algorithm can be calculated as:
s1·(P(event∣up)·nU−P(event∣down)·nD)+s2·(P(nonevent∣down)·nD−P(nonevent∣up)·nU)
Average savings per person are obtained by dividing the above by the total sample size, n, which produces a weighted form of the NRI, with weights related to cost savings:
| wNRI=s1·(P(event∣up)·P(up)−P(event∣down)·P(down))+s2·(P(nonevent∣down)·P(down)−P(nonevent∣up)·P(up)), | (6) |
|---|
where we made use of the fact that P(up)=nUn and P(down)=nDn.
Total savings in terms of those bound to experience events who now start treatment and those without events who now do not start treatment need to be compared to costs of measuring the marker. If costs are less than savings, then it is cost saving to measure marker. If costs exceed savings, then further formal cost-effectiveness analysis is required.
We observe that taking s1=1P(event) and s2=1P(nonevent), the above definition reduces to representation (2) of the previous section, a relationship already suggested in [12]. The expressions 1P(event) and 1P(nonevent) may have little in common with true costs, especially if we think of cost as monetary, but it is of limited relevance, since what really matters is the ratio of s1s2. We can always rescale wNRI or re-scale the per-person cost of obtaining the new algorithm inputs over the cost of the old algorithm inputs.
In the case of two risk categories determined by one threshold, an alternative weighting might be proposed. If categories are sensibly defined, decision theory suggests that the category threshold is the decision threshold [20, 21], which means weights are proportional to the sizes of the two intervals into which the (0, 1) interval is partitioned. For example, with the 0.20 threshold, 10-year risk ≥ 0.20 implies we take one decision (e.g. treatment with medication) while <0.20 means only life-style intervention or no intervention at all. The relative weight of true positives to true negatives implied is then 0.80 to 0.20 or simply 4:1. Keeping with the convention of the original NRI, where the harmonic mean of weights s1 and s2 is equal to 1, we would take s1=5 and s2=1.25 in this example. Note that the two-category case if the threshold is equal to incidence (or prevalence) decision analytic and original weights are equal.
When there are more than two categories obtaining values of s1 and s2 that are not arbitrary and would be acceptable to a wide range of readers and reviewers constitutes a formidable task which usually will go beyond of what is expected from a medical research article. Thus the ad hoc “statistical” costs suggested by s1=1P(event) and s2=1P(nonevent), which imply that it is “P(nonevent)P(event)” times more important to reclassify upwards future event than it is to reclassify downwards future non-event, may not be unreasonable in many settings. Moreover, they afford a more objective measure that would not change from marker to marker, model to model or paper to paper, a property whose value should not be overlooked.
3. Problem of Categories. Continuous NRI
The original article which introduced the NRI illustrated its application with a 3-category risk stratification [9]. However, others have applied it with 4 or no categories [13, 22, 23]. There is nothing implicit in the definition of the NRI which requires risk stratification into categories. The only requirement is that we define what upward and downward reclassification is.
While in some fields risk categories are firmly established and patient care depends on these categories (for example, primary prevention of cardiovascular disease (CVD)), other fields attempt to create meaningful risk categories but there is insufficient information to either justify or promote them (all cause mortality, diabetes, atrial fibrillation). Moreover, even when categories are firmly established (CVD prevention), their application is confused by different definitions of the endpoint of interest and thus different incidence rates for different models (hard CVD, full CVD, hard coronary heart disease (CHD), full CHD and so on). This can lead to different NRI values for the same marker added to different models.
What complicates matters further is the dependence of category-based NRI on the selection and number of categories. We illustrate this phenomenon with a very simple example. Assume 8 subjects, 4 events and 4 non-events with predicted probabilities of event based on a given old (and useless) model of 0.2, 0.4, 0.6 and 0.8 for events and 0.2, 0.4, 0.6 and 0.8 for non-events. Furthermore, assume that the addition of a new marker adds 0.16 to predicted probabilities for all event subjects and subtracts 0.16 for all non-event subjects. If we assume only two risk categories, below and above 0.5, the NRI equals 14+14=0.50 (event subject with original probability 0.4 moves up and non-event subject with original probability 0.6 moves down). For NRI with 3 risk categories determined by cut-off points of 0.33 and 0.67 we get NRI=24+24=1.00 (event subjects with initial 0.2 and 0.6 move up and non-events with initial 0.4 and 0.8 move down). With 4 categories determined by cut-offs at 0.25, 0.50 and 0.75 we get NRI=34+34=1.50 and “no category” NRI with upward and downward movement defined by any upward or downward change in predicted risks is equal to the maximum possible value of 1+1 = 2.00. Similarly, it is not difficult to observe that NRI will also depend on the choice of categories. For this reason, it may not always be true in practice that more categories will mean higher NRI.
The above discussion suggests that the category-less or continuous NRI is the most objective and versatile measure of improvement in risk prediction. Its definition remains consistent with formulas (1)-(4) with the only difference in the meaning of upward and downward reclassification. In the following sections we show its alternative interpretations and invariance to changing event rates. We argue that in cases where no established categories exist, it is more prudent to use a version of NRI which does not require categories, rather than trying to create them for one particular application. Moreover, in cases where a priori categories do exist, it is still worth to report the continuous NRI for comparison purposes with other applications.
In summary, two versions of NRI can be considered: one with categories which should be used if categories are already established in the field and influence care decisions and one without categories which can be used universally. We introduce the following notation:
- NRI(0.20) for two-category NRI with cut-off at 0.20;
- NRI(0.06,0.20) to denote NRI with three categories, established by cut-off points of 0.06 and 0.20;
- NRI(>0) or “continuous NRI” for NRI with no categories;
Furthermore “event NRI” and “nonevent NRI” would indicate the two very useful subcomponents of the total NRI, with the former calculating the amount of correct reclassification among events and the latter among nonevents. We recommend reporting these along with the single summary NRI for fuller interpretation:
eventNRI=P(up∣event)−P(down∣event)=P(event∣up)P(up)−P(event∣down)P(down)P(event)noneventNRI=P(down∣nonevent)−P(up∣nonevent)=P(nonevent∣down)P(down)−P(nonevent∣up)P(up)P(nonevent)
Of course, NRI = event NRI + nonevent NRI. We note that the original NRI was presented as a sum and not average of the two subcomponents for “historical reasons” – this way it matches the approach taken in the definition of integrated discrimination improvement (IDI) which in turn parallels the definition of Youden’s index [24] and difference in logistic regression R-squares [10, 25]. However, an average (12NRI or 12wNRI) could have an easier interpretation of average weighted improvement in classification (if categories are present) or in discrimination (if no categories are present).
In general we do not recommend using more than 3 categories unless they are already established and there is a justifiable need for that many. It seems to us that 3 categories offer sufficient categorization – high category for individuals with high risk (who should be treated), low category for those with low risk (who do not need treatment) and the middle category for everyone else. The use of categories can only be justified by explicit care recommendations for individuals in each category and it is often unlikely that these would materially differ between two middle categories (for example 0.05-0.10 and 0.10-0.20 in cardiovascular disease prevention). If one feels a partition finer than 3 is needed, then the category-free NRI offers a better option.
We do realize that in some cases, category-based presentation may be more effective in terms of communication of results. Generally, we do not recommend an ad hoc creation of categories as they should be based on multiple factors, including cost considerations. However, if one feels they are absolutely necessary to convey the message and there are no categories established in the field, we recommend that categories are formed in a way which takes into account the event rate, severity of the disease under study and potential care recommendations based on the risk categories created.
We conclude this section with a comment about a modification of the “original” NRI introduced by Cook et al. [26]. They define “clinical NRI” as the amount of reclassification observed only in the “middle risk” group. It is important to note that such “clinical NRI” is meant to address a different question than the “original NRI”. The “original NRI” attempts to quantify the amount of improvement if the new marker was to be measured on everyone in the population of interest. “Clinical NRI” quantifies the amount of improvement offered by a strategy in which only individuals in the middle risk group have the new marker obtained, have their risk recalculated based on a function which includes the new marker and are reclassified if the new probability leads to a different risk category. As these two NRIs are based on different groups of individuals they cannot be directly compared unless individuals in the high and low risk group who do not change categories in this strategy are included and “clinical NRI” is translated into “original NRI”. The latter approach might offer a more complete picture of the effect of the two-step strategy outlined above.
4. Relationships with other measures
In this section we show how in the binary case the two extreme versions of NRI, one without categories and one with only two categories, are related to existing measures of diagnostic accuracy and model performance. First, we show how NRI(>0) is composed of the same building blocks as the difference in c statistics but arranged in a different way. Denote by Q predicted probabilities of event based on the “new” risk prediction algorithm and by P based on the “old” one. Then we have:
| 12NRI(>0)=P(Qi>Pi∣i=event)−P(Qj>Pj∣j=nonevent)ΔC=P(Qi>Qj∣i=event,j=nonevent)−P(Pi>Pj∣i=event,j=nonevent) | (7) |
|---|
Equality (7) is proven in the Appendix. The comparisons used in the calculation of NRI(>0) are made between the two risk prediction rules but within event groups while for change in c statistic they are made within the two rules but between event groups. This illustrates the fact that NRI(>0) can be viewed as another measure of improvement in discrimination. Of note, similarly to the c statistics, it is not affected by event incidence and thus can be compared across different studies.
The category-less NRI(>0) can also be viewed as the most appropriate summary measure for the “reclassification plot” proposed by Steyerberg et al. [27]. It is constructed by plotting predicted probabilities based on the new risk prediction rule versus predicted probabilities based on the old rule, denoting events and non-events with different symbols. A 45 degree line of “no change” is added to the graph for ease of visual inspection: for “new” prediction rules which meaningfully improving reclassification events are expected to lie above the 45 degree line (increase in predicted probability) and non-events below (decrease in predicted probability). An example of such plot for data presented in Section 8 is given in Figure 1.
Figure 1.
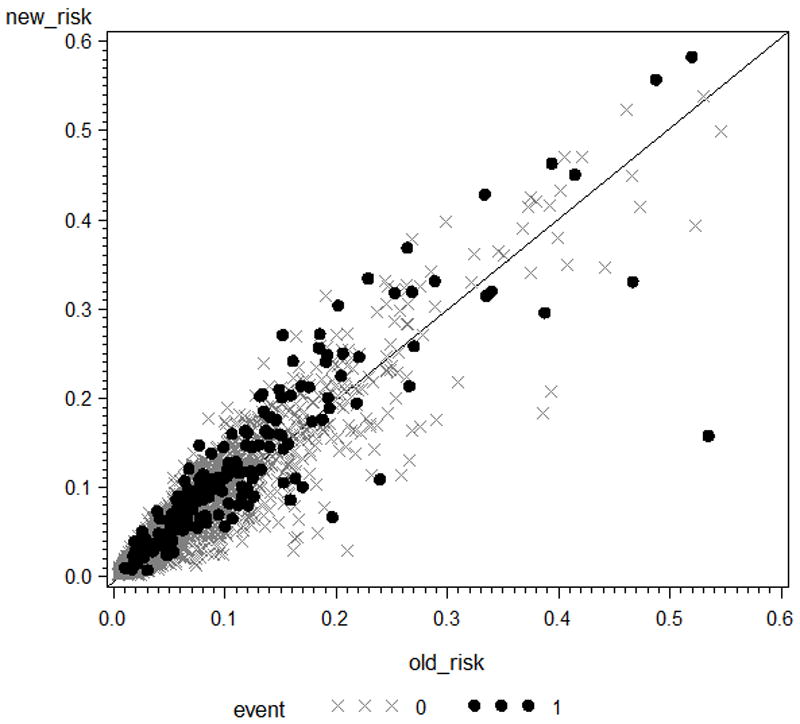
Reclassification plot
Interestingly, the two-category (single cut-off) NRI is also related to the difference in c statistics, but this time these c statistics correspond to the areas under receiver operating characteristic (ROC) curves constructed in binary classification. For binary classification with threshold u, the area under the single-point ROC is equal to 12(Sensitivity(u)+Specificity(u)) and hence, when comparing two models, we have:
ΔC(u)=12(ΔSensitivity(u)+ΔSpecificity(u)).
At the same time:
ΔSensitivity(u)=P(up∣event)−P(down∣event),ΔSpecificity(u)=P(down∣nonevent)−P(up∣nonevent),
and hence:
ΔC(u)=12ΔYouden(u)=12NRI(u),
where Youden(u) is used to denote the Youden [24] index for the cut-off u. Hence, the two-category NRI is equal to twice the difference in ROC areas for binary classification and to the increase in Youden index.
6. Differing Event Rates and Validation
In section 4 we alluded to the fact that category-based NRI is influenced by the relationship between category cut-offs and event rate. Hence, it may be misleading to apply the same fixed categories to events defined differently or time horizons of different duration which lead to varying incidence rates. This problem is absent when we use the category-free NRI which is not affected by event rates. When categories are present the situation is more complicated. First, one needs to ascertain that the endpoint of interest and duration of follow-up agree with those used to define the cut-off points. For example, in primary prevention of cardiovascular disease the cut-off points of 6 and 20% were established for hard coronary heart disease (defined as myocardial infarction or coronary death) with 10-year incidence rate of 0.09 for men and 0.03 for women (combined rate 0.06). When duration of follow-up is extended to 30 years or broader endpoint is considered, categories of 0.06 and 0.20 may no longer be meaningful. For example, 30-year incidence of hard cardiovascular disease, which includes strokes, (Pencina et al. [16]) was 0.18 for men and 0.08 for women (combined rate 0.13). If category-based NRI was to be applied in this case, one might need to modify the categories. If proportionality of costs and event rates could be assumed, since the event rates are roughly 2:1 between 30-year HCVD and 10-year HCHD, categories of 0.12 and 0.40 could be an option. This is an ad hoc solution and further exploration is needed to assess its properties. On the other hand, a full cost effectiveness analysis would be required to formally justify the threshold selection. In summary, when using NRI with a priori established categories, one should not ignore the duration of follow-up and definition of the event of interest.
The above discussion has consequences for calculating NRI in a validation sample. It is not uncommon that the event rate of the validation sample will be a little different than in the development sample. This poses a potential problem in distinguishing how much of the change in NRI is due to necessary correction for over-optimism and how much is contributed by slight misspecification of categories. The answer is straight-forward for NRI(>0): all is due to the correction for over-optimism. The answer is not as simple for category-based NRIs – one might need to perform sensitivity analyses adjusting the categories. In general, the problem will be of smaller magnitude when NRI values are large (we have a useful new marker) or when the differences in incidence are small. At this point it might be helpful to observe that in some cases validated or cross-validated NRI may not be different or could even be higher than the one calculated on the development sample. This may be due to the issue with differing event rates raised above but also due to the fact that NRI is a measure of differences. It is conceivable that performance of models without and with the new marker goes down in the validation sample, but their difference is preserved or even goes up.
If an outside validation sample is not available, it is still important to correct for potential over-fitting. One way to accomplish this is through cross-validation of predicted probabilities based on the “new” and “old” risk prediction rules. A commonly used approach would randomly partition the sample into 5 or 10 equal subsamples (corresponding to 5 or 10-fold cross-validation), take out the first subsample and develop the prediction rules of interest on the remaining 4 or 9 subsamples combined. Then data from the subsample not used in development would be used to generate predicted probabilities according to the rule developed on all data except for this one subsample. The process is repeated for all subsamples. Thus we obtain a set of cross-validated predicted probabilities, two (based on the “new” and “old” rule) for each individual in the data set. These are to be used in the calculation of NRI. For smaller samples and to increase stability, one might repeat this process numerous times.
7. Case-Control Studies
So far our focus was primarily on NRI calculated using data coming from a study with prospective follow-up. However, many biomarker studies, especially at earlier stages of development, are conducted using the case-control design. It is natural to ask whether NRI can be calculated in these situations. Here we present a method of extending NRI to case-control studies which use logistic regression as the analytic method. We adopt an approach analogous to the one used by Huang and Pepe for extending the predictiveness curve to case-control data [28].
NRI is based on predicted probabilities of event and event indicators. The latter are available “by definition” in case control studies but the former need some work. Predicted probabilities from a logistic regression conducted on case-control data are not meanigful as they do not represent the true risk for the population under study. However, the logistic regression coefficients are estimable in case-control data except for the intercept [29]. If we know the true disease incidence (or prevalence) we can adjust the case-control intercept to obtain a meaningful logistic regression model from which predicted probabilities of event can be easily derived.
Denote the logit of event probability in the case control model with k predictors by
| L(β0,β1,…,βk)=log(p1−p)=β0+β1X1+…+βkXk, | (8) |
|---|
where _β_0 is the model intercept and _β_1,…, βk are regression coefficients for risk factors _X_1,…, Xk. Assume that in our sample there are nE subjects who experienced the event and nN who did not and the incidence or prevalence can be estimated based on a different sample and denoted by ρ. It can be shown [28] that adding log(ρ1−ρ·nNnE) to the intercept of model (8) transforms it into a model that is scaled correctly for predicting risk with incidence or prevalence ρ. It is important to note that this method relies on the assumption that cases and controls are random (i.e. representative) samples of the underlying population. Otherwise, the intercept adjustment is invalid. This assumption might be violated in early case-control studies, where selection is often present, with extreme cases and very healthy controls constituting the analytic sample. When the above assumption is satisfied, we can suggest the following algorithm for estimating NRI from case control data:
- Fit logistic two models to case-control data, one without and one with the new marker to obtain regression coefficients _β_0, _β_1,…, βk and _β_’0, _β_’1,…, β’k, β_’_k+1
- For every subject calculate adjusted predicted probabilities using the model without (“old”) and with (“new”) new marker as
pold=(1+exp(−L(β0+log(ρ1−ρ·nNnE),β1,…,βk)))−1andpnew=(1+exp(−L(β0’+log(ρ1−ρ·nNnE),β1’,…,βk’,βk+1’)))−1 - Estimate NRI using pold and pnew and event and nonevent status in the case-control sample using sample estimates in formula (1).
Two observations need to be noted. First, the above procedure is not necessary for the category-less NRI(>0). Since the same constant is added to the logits of models without and with the new marker, and for each subject only the ordering of predicted probabilities matters, it is easy to show that this ordering remains unchanged after the adjustment. Thus NRI(>0) can be applied directly and remains meaningful for case-control data.
Second, the point estimator for NRI from adjusted case-control data should agree with the one that would have been obtained if prospective (or cross-sectional) data was available. However, the standard errors need not be the same due to different composition of the sample. Frequently, in case-control data the ratio of events to nonevents is higher than in the true population. This means that the precision of estimation for events relative to nonevents is higher in this type of case-control data. We note that in case–control as well as in any binary outcome data the asymptotic standard errors can be estimated as:
SE(eventNRI)=p^up,events+p^down,eventsnE−(p^up,events−p^down,events)2nESE(noneventNRI)=p^down,nonevents+p^up,noneventsnN−(p^down,nonevents−p^up,nonevents)2nNSE(NRI)=SE(eventNRI)2+SE(noneventNRI)2
where the respective p̂ ’s are estimated based on sample data as discussed by Pencina and D’Agostino et al. [9]: p^up,events=#events moving up#events, p^down,events=#events moving down#events, p^up,nonevents=#nonevents moving up#nonevents, p^down,nonevents=#nonevents moving down#nonevents.
8. Practical Applications
To illustrate the concepts described in previous sections and to contrast the NRI from the original paper [9] with survival NRIs with and without categories, we will use the same data set. Some 3264 women and men aged 30 to 74 who attended the fourth Framingham Offspring cohort examination between 1987 and 1992 free of cardiovascular disease were eligible for this analysis. All participants gave written informed consent and the study protocol was approved by the Institutional Review Board of the Boston Medical Center. The outcome of interest was 10-year incidence of coronary heart disease. Cox proportional hazards models were fit using sex, diabetes and smoking as dichotomous and age, systolic blood pressure (SBP), total (TCL) and HDL cholesterol (in one of the two models) as continuous predictors. C statistics for model without and with HDL as the new marker were calculated using the method described in [30]. The three NRIs of section 4 were calculated on event probabilities obtained from the proportional hazards regression models. To correct for over-optimism we performed 10-fold cross-validation repeated 49 times and report median results. The 95% confidence intervals were estimated using 999 bootstrap replications following the approach outlined in [31]. NRI(0.20) was calculated with original and decision-analytic weights, as described in section 3.
The cross-validated results are summarized in tables 1-3. We first observe that the 10-year incidence rate is 0.06, consistent with event rate used in the study that led to the derivation of 0.06 and 0.20 as cut-off points for risk categories. Hence these categories seem reasonable. We observe that in our example, NRI increases with increasing refinement of categories – it is the lowest when we look only at 2 categories: 4.5% in table 1, and increases to 30.7% for NRI without categories (table 3). This implies that one cannot compare NRIs with categories to NRIs without categories and should be clear which one is being reported. Of note, in our example, the category-based NRIs are attenuated more upon cross-validation than is the category-free NRI: without cross-validation the NRIs in tables 1, 2 and 3 would have been 6.1%, 11.8% and 30.3%, respectively. In fact, there is a marginal increase in cross-validated continuous NRI. We also note that the non-cross-validated survival-based NRI(0.06,0.20) of 11.8% is very close to the 3-category NRI of 12.1% reported in the original paper [9] which ignored the survival nature of the data.
Table 1.
Reclassification table for two categories with cut-off point at 0.20
| All | Reclassified Upwards | Reclassified Downwards | NRI | ||
|---|---|---|---|---|---|
| Kaplan-Meier rate of CHD Event | 0.060 | 0.316 | 0.129 | ||
| Expected Number of Event Subjects | 196 | 12.9 | 4.1 | Among Event Subjects | 4.5% |
| Expected Number of Non-event Subjects | 3068 | 28.1 | 27.9 | Among Non-event Subjects | -0.0% |
| Overall Original (95% bootstrap confidence interval) | 4.5% (0.2%, 9.0%) | ||||
| Overall Decision Analytic (95% bootstrap confidence interval) | 1.2% (-0.2%, 2.7%) |
Table 3.
Reclassification table with no categories
| All | Reclassified Upwards | Reclassified Downwards | NRI | ||
|---|---|---|---|---|---|
| Kaplan-Meier rate of CHD Event | 0.060 | 0.078 | 0.043 | ||
| Expected Number of Event Subjects | 196 | 122.1 | 73.9 | Among Event Subjects | 24.6% |
| Expected Number of Non-event Subjects | 3068 | 1440 | 1628 | Among Non-event Subjects | 6.1% |
| Overall Original (95% bootstrap confidence interval) | 30.7% (15.6%, 45.2%) |
Table 2.
Reclassification table for two categories with cut-off points at 0.06 and 0.20
| All | Reclassified Upwards | Reclassified Downwards | NRI | ||
|---|---|---|---|---|---|
| Kaplan-Meier rate of CHD Event | 0.060 | 0.141 | 0.057 | ||
| Expected Number of Event Subjects | 196 | 28.4 | 10.6 | Among Event Subjects | 9.1% |
| Expected Number of Non-event Subjects | 3068 | 172.6 | 175.4 | Among Non-event Subjects | 0.1% |
| Overall Original (95% bootstrap confidence interval) | 9.2% (2.8%, 16.0%) |
Tables 1-3 also give Kaplan-Meier (KM) rates for those reclassified up and down. In general, if the model is improved by the new marker, we would expect the KM rate for those reclassified upwards to exceed the overall KM rate and the rate for those who moved down to be below the overall KM rate. This is true in tables 2 and 3: for example, in table 2 the KM rate for those moving up is 0.151 > 0.060 while KM rate for those going down is 0.041 < 0.060. When this relationship does not hold, NRI is likely to be smaller (cf. table 1). Even though the magnitudes of the 3 NRIs presented are different, when we compare event NRI and nonevent NRI across all examples, we notice that in all of them the event NRI is larger than the nonevent NRI, which might suggest that addition of HDL cholesterol helps increase predicted risk for those who experience events (in other words, “catch events”) to a larger degree than it does decrease predicted risk for those without events (“catch nonevents”).
In table 1 we notice that wNRI(0.20) with decision analytic weighting (weights 5.0 for events and 1.25 for nonevents) is markedly lower than NRI(0.20) with original weights based on incidence (weights 16.7 for events, 1.1 for non-events). Our observation indicates how sensitive NRI is to the selection of weight. As mentioned in section 3, in decision analysis, the choice of threshold reflects the weight: 0.20 is synonymous with the 4:1 weighting of importance of events versus non-events [20] and thus no other options would be considered (including weighting based on incidence). As observed above, in the HDL example presented here, the improvement in reclassification is more pronounced for events than for nonevents. Moreover, we required the harmonic and not arithmetic mean of weights to be fixed, which resulted in event weights of 5.0 for decision analytic and 16.7 for original NRI(0.20) which explains the difference in magnitude. The important lesson from our example is that NRIs weighted differently are different quantities and need to be interpreted on their own scales and cannot be compared. It also gives further support to the recommendation to report event and nonevent NRIs in addition to the combined measure.
Using the numbers from table 3, we can illustrate the relationship given in (8): on one hand 12NRI(>0)=12·0.307=0.153 and on the other P(Qi>Pi∣i=event)−P(Qj>Pj∣j=nonevent)=122.1196−14403068=0.622−0.469=0.153. In contrast, the corresponding difference in C statistics is only 0.760 − 0.751 = 0.009. This illustrates, albeit on different scales, how much more sensitive NRI(>0) is as a measure of improvement in discrimination.
9. Conclusions
In this paper we developed a general form for the net reclassification improvement which presents NRI as a prospective measure which quantifies the correctness of upward and downward reclassification or movement of predicted probabilities as a result of adding a new marker. The new form offers immediate extension to survival and competing risk data and allows for building in cost considerations. We have also contrasted NRIs which use categories with NRI that does not as well as NRIs which apply original vs. decision analytic weights. We have shown that the category-less NRI(>0) which defines upward and downward movement as any change in predicted probabilities is a measure of discrimination that is not influenced by correct scaling of the model and for binary data can be expressed in terms similar to the AUC. This makes NRI(>0) immediately applicable in validation sample and in case-control data. On the other hand category-based NRIs are measures of reclassification and are influenced by event rates and risk cut-offs. If established risk thresholds exist and treatment decisions are made based on risk categories, NRI which uses these categories can be useful. However, care needs to be taken to correctly define the event of interest and duration of follow-up. We have suggested a few possible ideas applicable to both observational and case-control data.
Net Reclassification Improvement is designed to quantify improvement in performance and hence its magnitude is more important than statistical significance. For this reason we recommend presenting NRI with its confidence interval rather than relying on p-values. Further research is needed to determine meaningful or sufficient degree of improvement as well as to suggest preferred methods to construct asymptotic or bootstrap confidence intervals.
Our theoretical considerations and practical examples have shown that NRI depends on the number and choice of categories (with no categories being one of the choices) and the weighting used. For this reason NRIs cannot be compared across studies unless they are defined in the same manner. In particular, the category-less NRI(>0) offers the widest and most standardized application. If presenting other versions, it is essential that researchers clearly define and justify their choices.
Acknowledgments
This work was supported by NIH/ARRA Risk Prediction of Atrial Fibrillation (1 RC1HL101056) and the National Heart, Lung, and Blood Institute’s Framingham Heart Study (contract N01-HC-25195)
Appendix
Here we prove equality (7): 12NRI(>0)=P(Qi>Pi∣i=event)−P(Qj>Pj∣j=nonevent).
Assuming predicted probabilities follow a continuous distribution and any movement is considered meaningful (implying that every person has to move either up or down) we obtain P(Qi > Pi ∣ i = event) + P(Qi < Pi ∣ i = event) = 1 or equivalently:
P(up ∣ event) + P(down ∣ event) = 1 implying:
P(up ∣ event) − P(down ∣ event) = 2 · P(up ∣ event) − 1.
Similarly: P(down ∣ nonevent) − P(up ∣ nonevent) = 1 − 2 · P(up ∣ nonevent).
Thus: NRI(> 0) = P(up ∣ event) − P(down ∣ event) + P(down ∣ nonevent) − P(up ∣ nonevent) = 2 · P(up ∣ event) − 1 + 1 − 2 · P(up ∣ nonevent) = 2 · (P(up ∣ event) − P(up ∣ nonevent)).
Contributor Information
Michael J. Pencina, Boston University, Department of Mathematics and Statistics, 111 Cummington Street, Boston, MA 02215
Ewout W. Steyerberg, Erasmus MC, Public Health, P.O. Box 1738, Rotterdam, 3000 DR, Netherlands
Ralph B. D’Agostino, Sr., Boston University, Department of Mathematics and Statistics, 111 Cummington Street, Boston, MA 02215
References
- 1.D’Agostino RB, Vasan RS, Pencina MJ, et al. General cardiovascular Risk Profile for Use in Primary Care. Circulation. 2008;117:743–753. doi: 10.1161/CIRCULATIONAHA.107.699579. [DOI] [PubMed] [Google Scholar]
- 2.Wilson PWF, D’Agostino RB, Levy D, et al. Prediction of coronary heart disease using risk factor categories. Circulation. 1998;97:1837–1847. doi: 10.1161/01.cir.97.18.1837. [DOI] [PubMed] [Google Scholar]
- 3.D’Agostino RB, Wolf PA, Belanger A, Kannel WB. Stroke Risk Profile: Adjustment for Antihypertensive Medication. Stroke. 1994;25:40–43. doi: 10.1161/01.str.25.1.40. [DOI] [PubMed] [Google Scholar]
- 4.Schnabel RB, Sullivan LM, Levy D, et al. Development of a risk score for atrial fibrillation (Framingham Heart Study): a community-based cohort study. Lancet. 2009;373:739–745. doi: 10.1016/S0140-6736(09)60443-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Gail MH, Brinton LA, Byar DP, et al. Projecting individualized probabilities of developing breast cancer for white females who are being examined annually. J Natl Cancer Inst. 1989;81:1879–86. doi: 10.1093/jnci/81.24.1879. [DOI] [PubMed] [Google Scholar]
- 6.Parikh NI, Pencina MJ, Wang TJ, et al. A Risk Score for Predicting Near-Term Incidence of Hypertension: The Framingham Heart Study. Ann Intern Med. 2008;148:102–110. doi: 10.7326/0003-4819-148-2-200801150-00005. [DOI] [PubMed] [Google Scholar]
- 7.Meigs JB, Shrader P, Sullivan L, et al. Genotype Score in Addition to Common Risk Factors for Prediction of Type 2 Diabetes. NEJM. 2008;359:2208–2219. doi: 10.1056/NEJMoa0804742. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Cook NR. Use and Misuse of the Receiver Operating Characteristics Curve in Risk Prediction. Circulation. 2007;115:928–935. doi: 10.1161/CIRCULATIONAHA.106.672402. [DOI] [PubMed] [Google Scholar]
- 9.Pencina MJ, D’Agostino RB, Sr, D’Agostino RB, Jr, Vasan RS. Evaluating the added predictive ability of a new marker: From area under the ROC curve to reclassification and beyond. Statist Med. 2008;27:157–72. doi: 10.1002/sim.2929. [DOI] [PubMed] [Google Scholar]
- 10.Pepe MS, Feng Z, Gu JW. Commentary on ‘Evaluating the added predictive ability of a new marker: From area under the ROC curve to reclassification and beyond’. Statist Med. 2007 doi: 10.1002/sim.2991. [DOI] [PubMed] [Google Scholar]
- 11.Uno H, Tian L, Cai T, et al. Comparing Risk Scoring Systems Beyond the ROC Paradigm in Survival Analysis. [November 26, 2009];Harvard University Biostatistics Working Paper Series. 2009 paper 107. [Google Scholar]
- 12.Pencina MJ, D’Agostino RB, Sr, D’Agostino RB, Jr, Vasan RS. Comments on Integrated discrimination and net reclassification improvements – practical advice. Statist Med. 2008;27:207–12. [Google Scholar]
- 13.Ingelsson E, Schaefer E, Contois J, et al. Clinical Utility of Different Lipid Measures for Prediction of Coronary Heart Disease in Men and Women. JAMA. 2007;298:776–785. doi: 10.1001/jama.298.7.776. [DOI] [PubMed] [Google Scholar]
- 14.Cook NR, Ridker PM. Advances in Measuring the Effect of Individual Predictors of Cardiovascular Risk: The Role of Reclassification Measures. Ann Intern Med. 2009;150:795–802. doi: 10.7326/0003-4819-150-11-200906020-00007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Steyerberg EW, Pencina MJ. Reclassification calculations with incomplete follow-up. Ann Intern Med. 2009 doi: 10.7326/0003-4819-152-3-201002020-00019. [DOI] [PubMed] [Google Scholar]
- 16.Pencina MJ, D’Agostino RB, Larson MG, et al. Predicting the 30-year risk of cardiovascular disease The Framingham Heart Study. Circulation. 2009;119:3078–3084. doi: 10.1161/CIRCULATIONAHA.108.816694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Greenland S. Evaluating the added predictive ability of a new marker: The need for Reorientation toward Cost-Effective Prediction. Statist Med. 2008;27:199–206. doi: 10.1002/sim.2995. [DOI] [PubMed] [Google Scholar]
- 18.Vickers AJ, Elkin EB, Steyerberg E. Net reclassification improvement and decision theory. Statist Med. 2009;28:525–6. doi: 10.1002/sim.3087. [DOI] [PubMed] [Google Scholar]
- 19.Gaynor JJ, Feuer EJ, Tan CC, et al. On the use of cause-specific failure and conditional failure probabilities: examples from clinical oncology data. J Am Stat Assoc. 1993;88:400–9. [Google Scholar]
- 20.Peirce CS. The numerical measure of the success of predictions. Science. 1884;4:453–4. doi: 10.1126/science.ns-4.93.453-a. [DOI] [PubMed] [Google Scholar]
- 21.Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Med Decis Making. 2006;26:565–574. doi: 10.1177/0272989X06295361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Ridker PM, Paynter NP, Rifai N. C-reactive protein and parental history improve global cardiovascular risk prediction: the Reynolds Risk Score for men. Circulation. 2008;118:2243–51. doi: 10.1161/CIRCULATIONAHA.108.814251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Harrell FE. [Nov 26, 2009];ImproveProb() routine in R statistical software. [Google Scholar]
- 24.Youden WJ. Index for rating diagnostic tests. Cancer. 1950;3:32–35. doi: 10.1002/1097-0142(1950)3:1<32::aid-cncr2820030106>3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- 25.Hu B, Palta M, Shao S. Properties of R-square statistics for logistic regression. Statist Med. 2006;25:1383–1395. doi: 10.1002/sim.2300. [DOI] [PubMed] [Google Scholar]
- 26.Cook NR. Comments on “Evaluating the added predictive ability of a new marker: From area under the ROC curve to reclassification and beyond”. Statist Med. 2008;27:157–172. doi: 10.1002/sim.2929. [DOI] [PubMed] [Google Scholar]
- 27.Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, Pencina MJ, Kattan MW. Assessing the Performance of Prediction Models. A Framework for Traditional and Novel Measures. Epidemiology. 2010;21:128–138. doi: 10.1097/EDE.0b013e3181c30fb2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Huang Y, Pepe M. Semiparametric methods for evaluating risk prediction markers in case-control studies. Biometrika. 2009;96:991–997. doi: 10.1093/biomet/asp040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Breslow NE. Statistics in Epidemiology: the case-control study. JASA. 1996;91:14–28. doi: 10.1080/01621459.1996.10476660. [DOI] [PubMed] [Google Scholar]
- 30.Pencina MJ, D’Agostino RB. Overall C as a measure of discrimination in survival analysis: model specific population value and confidence interval estimation. Statist Med. 2004;23:2109–2123. doi: 10.1002/sim.1802. [DOI] [PubMed] [Google Scholar]
- 31.Hosmer DW, Lemeshow S. Confidence interval estimates of an index of quality performance based on logistic regression models. Statist Med. 1995;14:2161–2172. doi: 10.1002/sim.4780141909. [DOI] [PubMed] [Google Scholar]