RoboAgent (original) (raw)
Your browser does not support the video tag.
RoboAgent: A universal agent with 12 Skills
Universal RoboAgent exhibiting its skills across diverse tasks in unseen scenarios
Towards a universal robotic agent
A causality dilemma: The grand aim of having a single robot that can manipulate arbitrary objects in diverse settings has been a distant goal for several decades. This is in-part because of the paucity of diverse robotics datasets to train such agents, at the same time absence of generic agents than can generate such dataset.
Escaping the vicious circle: To escape this vicious circle our focus is on developing an efficient paradigm that can deliver a universal agent capable acquiring multiple skills under a practical data budget and generalizing them to diverse unseen situations.
RoboAgent is a culmination of effort spanning over two years. It builds on the following modular and recompensable ingredients -
- RoboPen - a distributed robotics infrastructure build with commodity hardware capable of long term uninterrupted operations.
- RoboHive - a unified framework for robot learning across simulation and real-world operations.
- RoboSet - a high quality dataset representing multiple skills with everyday objects in diverse scenarios.
- MT-ACT - an efficient language conditioned multi-task offline imitation learning framework that multiplies offline datasets by creating a diverse collection of semantic augmentations over the existing robot’s experiences and employs a novel policy architecture with efficient action representation to recover performant policies under a data budget.
RoboSet: Diverse multi-skill multi-task multi-modal dataset
Building a robotic agent that can generalize to many different scenarios requires a dataset with broad coverage. With the recognition that scaling efforts will generally help (e.g. RT-1 presents results with ~130,000 robot trajectories), our goal is to understand the principles of efficiency and generalization in learning system under a data budget. Low data regimes often results in over-fitting. Our main aim is to thus develop a powerful paradigms that can learn a generalizable universal policy while avoiding overfitting in this low-data regime.
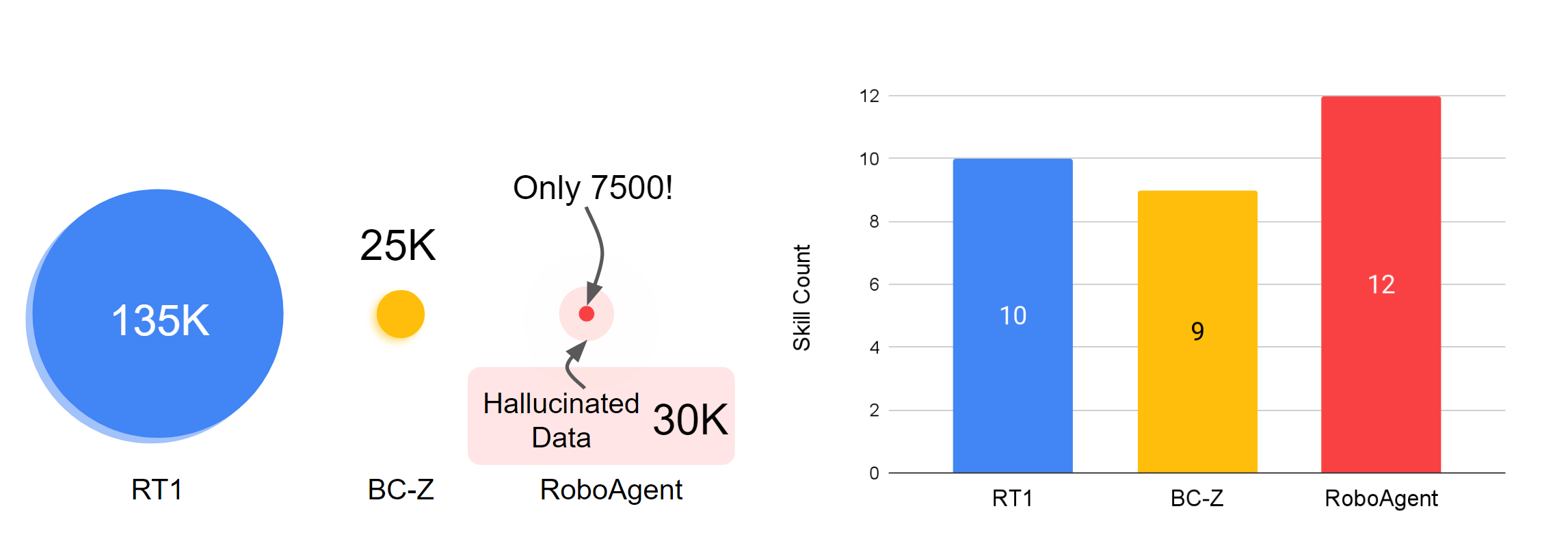 Skill vs DataSet landscape in Robot Learning.
Skill vs DataSet landscape in Robot Learning.
The dataset RoboSet(MT-ACT) used for training RoboAgent consists of merely 7,500 trajectories (18x less data than RT1). The dataset was collected ahead of time, and was kept frozen. It consists of high quality (mostly successful) trajectories collected using human teleoperation on commodity robotics hardware (Franka-Emika robots with Robotiq gripper) across multiple tasks and scenes. RoboSet(MT-ACT) sparsely covers 12 unique skills in a few different contexts. It was collected by dividing everyday kitchen activities (e.g. making tea, baking) into different sub-tasks, each representing a unique skill. The dataset includes common pick-place skills but also includes contact-rich skills such as wipe, cap as well as skills involving articulated objects.
 A snapshot of our robot system and the objects used during data collection.
A snapshot of our robot system and the objects used during data collection.
In addition to the RoboSet(MT-ACT) we use for training RoboAgent, we are also releasing RoboSet a much larger dataset collected over the course of a few related project containing a total of 100,050 trajectories, including non-kitchen scenes. We are open-sourcing our entire RoboSet to facilitate and accelerate open-source research in robot-learning.
MT-ACT: Multi-Task Action Chunking Transformer
RoboAgent builds on two critical insights to learn generalizable policies in low-data regimes. It leverages world priors from foundation models to avoid mode collapse and a novel efficient policy representations capable of ingesting highly multi-modal data.
- Semantic Augmentations: RoboAgent injects world priors from existing foundation models by creating semantic augmentations of the RoboSet(MT-ACT). The resulting dataset multiplies robots experiences with world priors at no extra human/robot cost. We use SAM to segment target objects and semantically augment them to different objects with shape, color, texture variations.
- Efficient Policy Representation: The resulting dataset is heavily multi-modal and contains a rich diversity of skills, tasks, and scenarios. We adapt action-chunking to multi-task settings to develop MT-ACT -- a novel efficient policy representation that can ingest highly multi-modal dataset while avoiding over-fitting in low data budget settings.
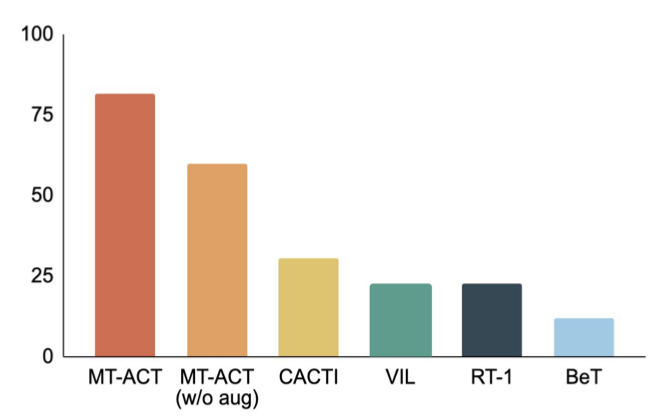
RoboAgent is more sample-efficient than existing methods.
Figure on the right compares our proposed MT-ACT policy representation against several imitation learning architectures. For this result we use environment variations that include object pose changes and some lighting changes only. Somewhat similar to previous works, we refer to this as L1-generalization. From our results we can clearly see that using action-chunking to model sub-trajectories significantly outperforms all baselines, thereby reinforcing the effectiveness of our proposed policy representation for sample efficient learning.
RoboAgent performs well across multiple levels of generalization.
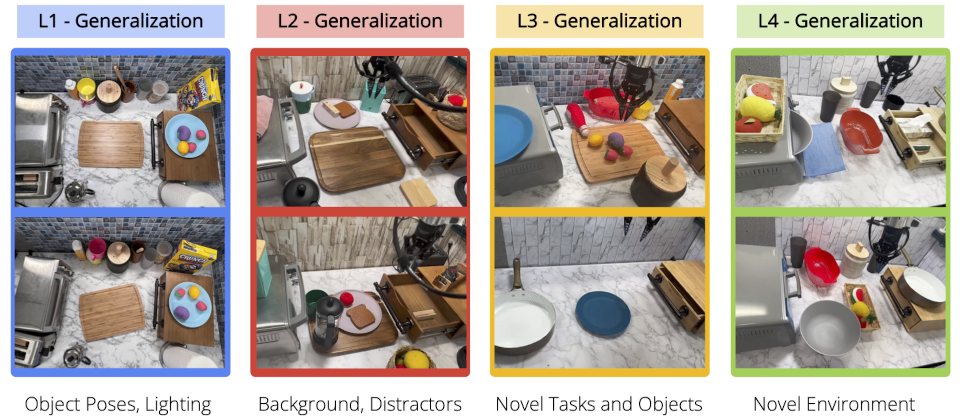
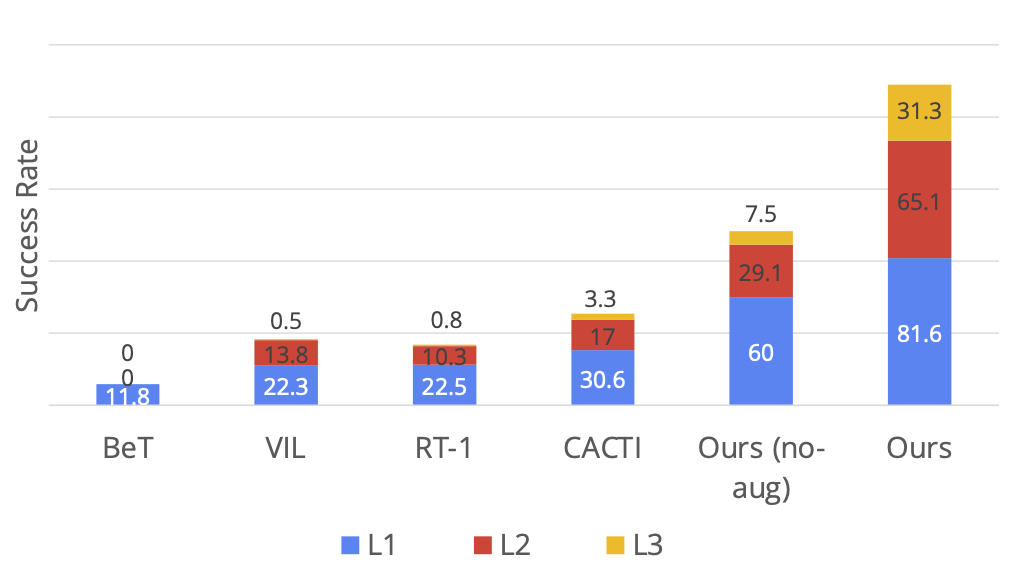
Above figure shows the different levels of generalization we test our approach on. We visualize levels of generalization, L1 with object pose changes, L2 with diverse table backgrounds and distractors and L3 with novel skill-object combinations. Next we show how each method performs on these levels of generalization. In a rigorous evaluation study under, we observe that MT-ACT significantly outperforms all other methods especially on harder generalization levels (L3).
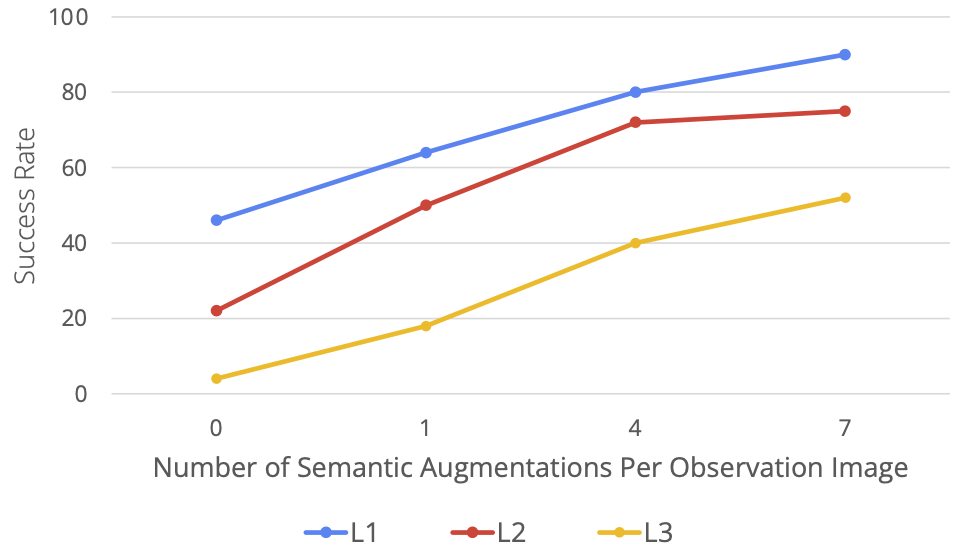
RoboAgent is highly scalable.
Next we evaluate how RoboAgent performs with increasing levels of semantic augmentations. We evaluate this on one activity (5-skills). Below figure shows that with increased data (i.e. more augmentations per frame) the performance significantly improves across all generalization levels. Importantly, the performance increase is much larger for the harder tasks (L3 generalization).
RoboAgent can exhibit skills across diverse activities
Baking Prep
Clean Kitchen
Serve Soup
Make Tea
Stow Bowl
Acknowledgements
We acknowledge various contributions, large and small, from the authors of following projects without which RoboAgent wouldn't be possible --RoboHive,RoboSet,Polymetis, and the entire Embodied AI team at Meta.
RoboAgent has also significantly benefitted from brainstorming sessions from --Aravind Rajeswaran,Chris Paxton,Tony Zhao,Abhishek Gupta, and individual contributions fromGiri Anantharaman,Leonid Shamis,Tingfan Wu,Priyam Parashar,Chandler Meadows,Sahir Gomez, andLiyiming Ke. We thank Gaoyue Zhou,Raunaq Bhirangi, Sudeep Dasari , Yufei Ye, Mustafa Mukadam,Shikhar Bahl, Mandi Zhao,Wenxuan Zhou, Jason Ma, and Unnat Jain for helpful discussions at different stages of the project.
@misc{bharadhwaj2023roboagent,
title={RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking},
author={Homanga Bharadhwaj and Jay Vakil and Mohit Sharma and Abhinav Gupta and Shubham Tulsiani and Vikash Kumar},
year={2023},
eprint={2309.01918},
archivePrefix={arXiv},
primaryClass={cs.RO}
}