Rui Shao's Homepage (original) (raw)
| Professor School of Computer Science and Technology, Harbin Institute of Technology (Shenzhen) Email: shaorui[AT]hit.edu.cn, rshaojimmy[AT]gmail.com [Google Scholar] [GitHub] [LinkedIn] [CV] [中文简历] [中文主页] |  |
|---|---|
| News 05/2025: One paper about GUI agent is accepted by ACL Main 2025 .05/2025: Invited to serve as ICMR 2025 Panel Co-Chairs and BMVC 2025 Area Chair.05/2025: One paper about Robot Skill Learning is accepted by ICML 2025 as Spotlight (2.6%). 02/2025: Three papers about Ego-Centric video MLLM, MLLM agent and Embodied MLLM are accepted by CVPR 2025. 01/2025: One paper about SmartPhone Multimodal Agent accepted by ICLR 2025 as Spotlight (5.1%). 12/2024: The extension of our ECCV 2022 paper (SeqDeepFake) has been accepted by International Journal of Computer Vision (IJCV). Cheers! 10/2024: We have built GitHub Orgnization of JiuTian-VL that will post all information about our JiuTian MLLM.10/2024: I have one paper about the adapter of large vision models accepted by International Journal of Computer Vision (IJCV). Cheers!10/2024: Two papers about MLLMs are accepted at NeurIPS 2024, including contributions from a 2nd-year undergraduate. Cheers!07/2024: One paper about Audio-Visual Multimodal Large Language Model accepted by ECCV 2024.02/2024: Our Multimodal Large Language Model (MLLM)- JiuTian-LION has been accepted by CVPR 2024. Cheers!02/2024: The extension of our CVPR 2023 paper has been accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). Cheers! 11/2023: We have released the arXiv paper for our Multimodal Large Language Model (MLLM)- JiuTian-LION . Enjoy it!08/2023: We have built the GitHub Repo for our Multimodal Large Language Model (MLLM)- JiuTian . Enjoy it!04/2023: I have released the code and dataset of our CVPR 2023 work in our GitHub Repo . Enjoy it!02/2023: I have one paper accepted by CVPR 2023. Code and dataset will be released soon. Please stay tuned! 07/2022: I have one paper accepted by ECCV 2022. We have released the code and dataset in our project page 05/2022: I have released the code of Federated Generalized Face Presentation Attack Detection in TNNLS 2022. Codes 04/2022: I have one paper accepted by IEEE Transactions on Neural Networks and Learning Systems (TNNLS) .03/2022: I have released the code of Open-set Adversarial Defense with Clean-Adversarial Mutual Learning in IJCV 2022. Codes 01/2022: The extension of our ECCV 2020 paper has been accepted by International Journal of Computer Vision (IJCV). 08/2020: I have released the code of Open-set Adversarial Defense in ECCV 2020. Codes 07/2020: I have one paper accepted by ECCV 2020. See you online! 11/2019: I have released the code of Regularized Fine-grained Meta Face Anti-spoofing in AAAI 2020. Codes 11/2019: I have one paper accepted by AAAI 2020. See you at New York City, USA! 10/2019: I have one paper one paper accepted by IET Image Processing. 07/2019: I have released the code of Multi-adversarial Discriminative Deep Domain Generalization for FAS in CVPR 2019. Codes 07/2019: I have released the code of Joint Discriminative Learning of Deep Dynamic Textures for 3D Mask FAS in TIFS 2019. Codes 02/2019: I have one paper accepted by CVPR 2019. See you at Long Beach, USA! 02/2019: One paper is accepted by IEEE Transactions on Industrial Electronics. 08/2018: I have one paper accepted by IEEE Transactions on Information Forensics and Security .07/2018: I have released the code of Hierarchical Adversarial Deep Domain Adaptation in ACMMM 2018. Codes 07/2018: I have one paper accepted by ACM MM 2018. See you at Seoul, Korea! 08/2018: I have a new homepage. |
About Me
I am currently a Professor at School of Computer Science and Technology, Harbin Institute of Technology (Shenzhen). Prior to that, I was a postdoc at Nanyang Technological University, Singapore, working with Prof. Ziwei Liu and Prof. Chen Change Loy.
I received my PhD degree from Department of Computer Science, Hong Kong Baptist University in 2021, supervised by Prof. Pong C. Yuen, and my bachelor degree from School of Information and Communication Engineering, University of Electronic Science and Technology of China (UESTC) in 2015. I also spent a memorable high-school time in Shenzhen Foreign Languages School. I visited the Johns Hopkins University for 6 months in 2020.
I am interested in computer vision and multimodal learning. My current research focuses on Multimodal Large Language Model (MLLM) (e.g., "JiuTian" MLLM ) and its agent applications (e.g., Embodied AI and GUI Agent).
Looking for self-motivated Ph.D/M.S./Undergraduate students. [2025硕士/博士招生, 4-5名硕士, 2名博士]
Looking for PostDocs in MLLM, Embodied AI and Agent.
Biography
- 2021-2023, Research Fellow, MMLab@NTU, Singapore
- 2021.7- 2021.11, Researcher, SenseTime, Shenzhen, China, participating project of MMhuman3D codebase.
- 2017-2021, Ph.D., Department of Computer Science, Hong Kong Baptist University, Hong Kong, China
- 2020.2-2020.7, Visiting scholar at Johns Hopkins University, working with Prof. Vishal M Patel, Baltimore, U.S.
- 2011-2015, B.S., School of Information and Communication Engineering, University of Electronic Science and Technology of China, Chengdu, China
Pre-prints (* denotes corresponding authors)
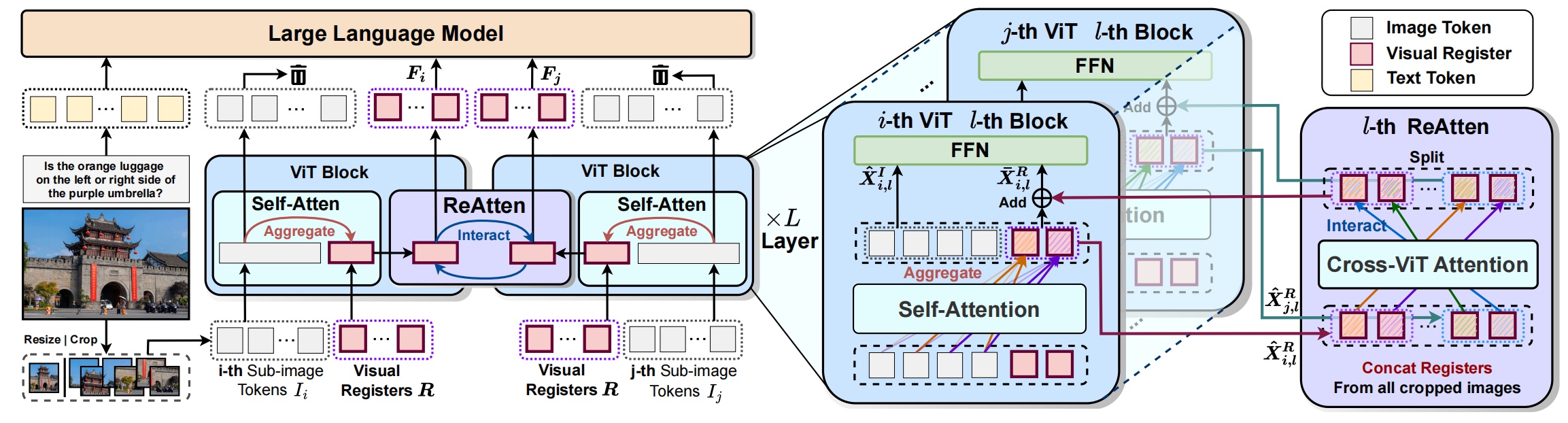 |
FALCON: Resolving Visual Redundancy and Fragmentation in High-resolution Multimodal Large Language Models via Visual Registers Renshan Zhang, Rui Shao*, Gongwei Chen, Kaiwen Zhou, Weili Guan, Liqiang Nie* [arXiv] |
|---|---|
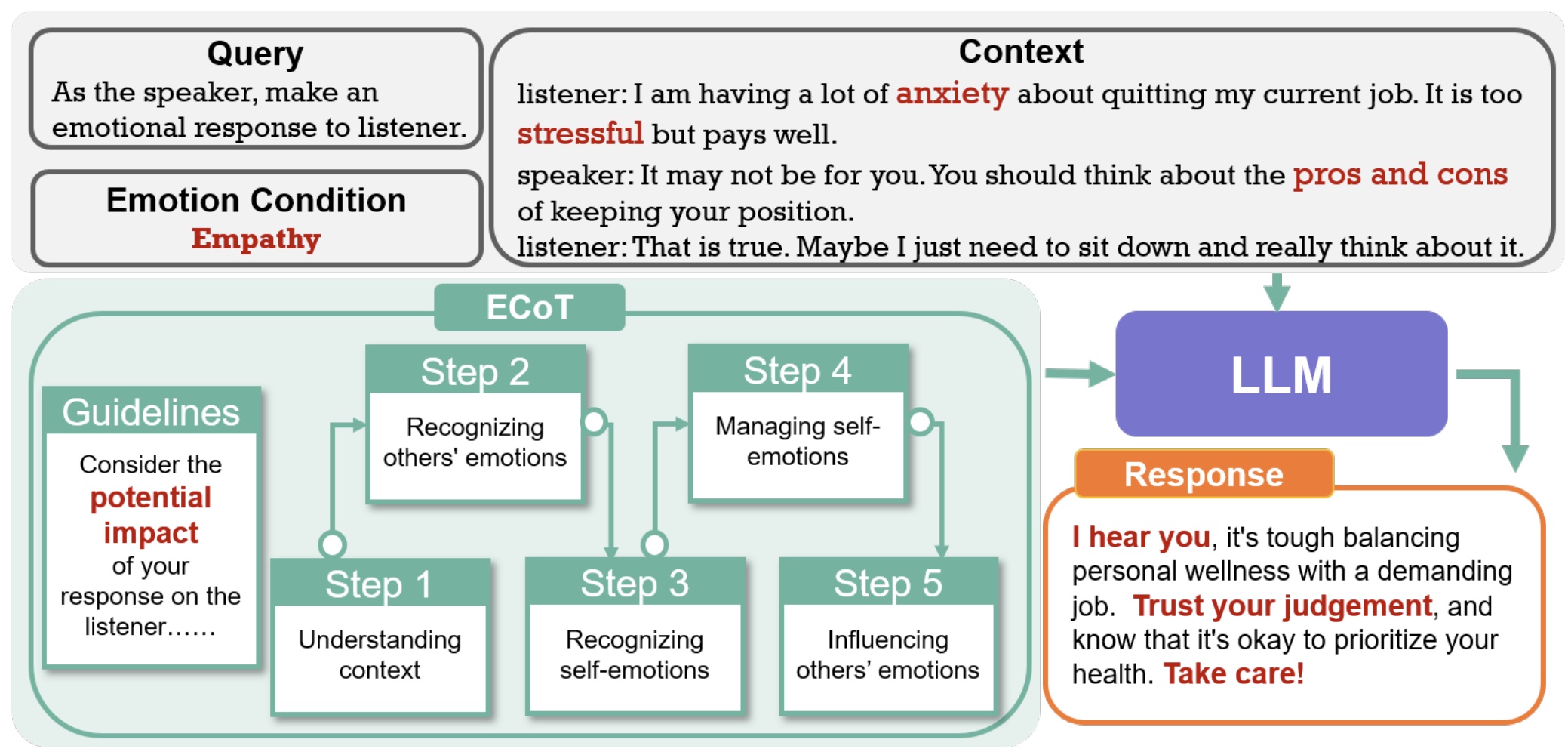 |
Enhancing Emotional Generation Capability of Large Language Models via Emotional Chain-of-Thought Zaijing Li, Rui Shao*, Gongwei Chen, Dongmei Jiang, Liqiang Nie [arXiv] |
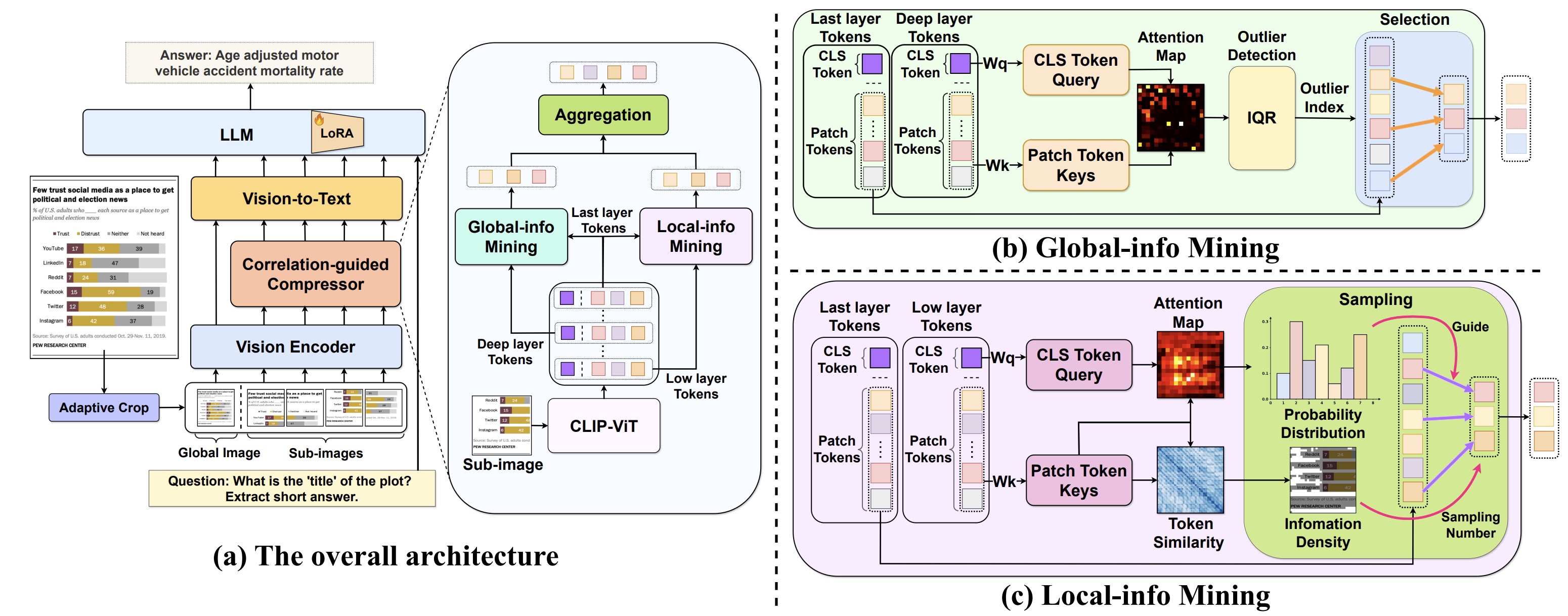 |
Token-level Correlation-guided Compression for Efficient Multimodal Document Understanding Renshan Zhang, Yibo Lyu, Rui Shao*, Gongwei Chen, Weili Guan, Liqiang Nie* [arXiv] |
Selected Publications (* denotes corresponding authors)
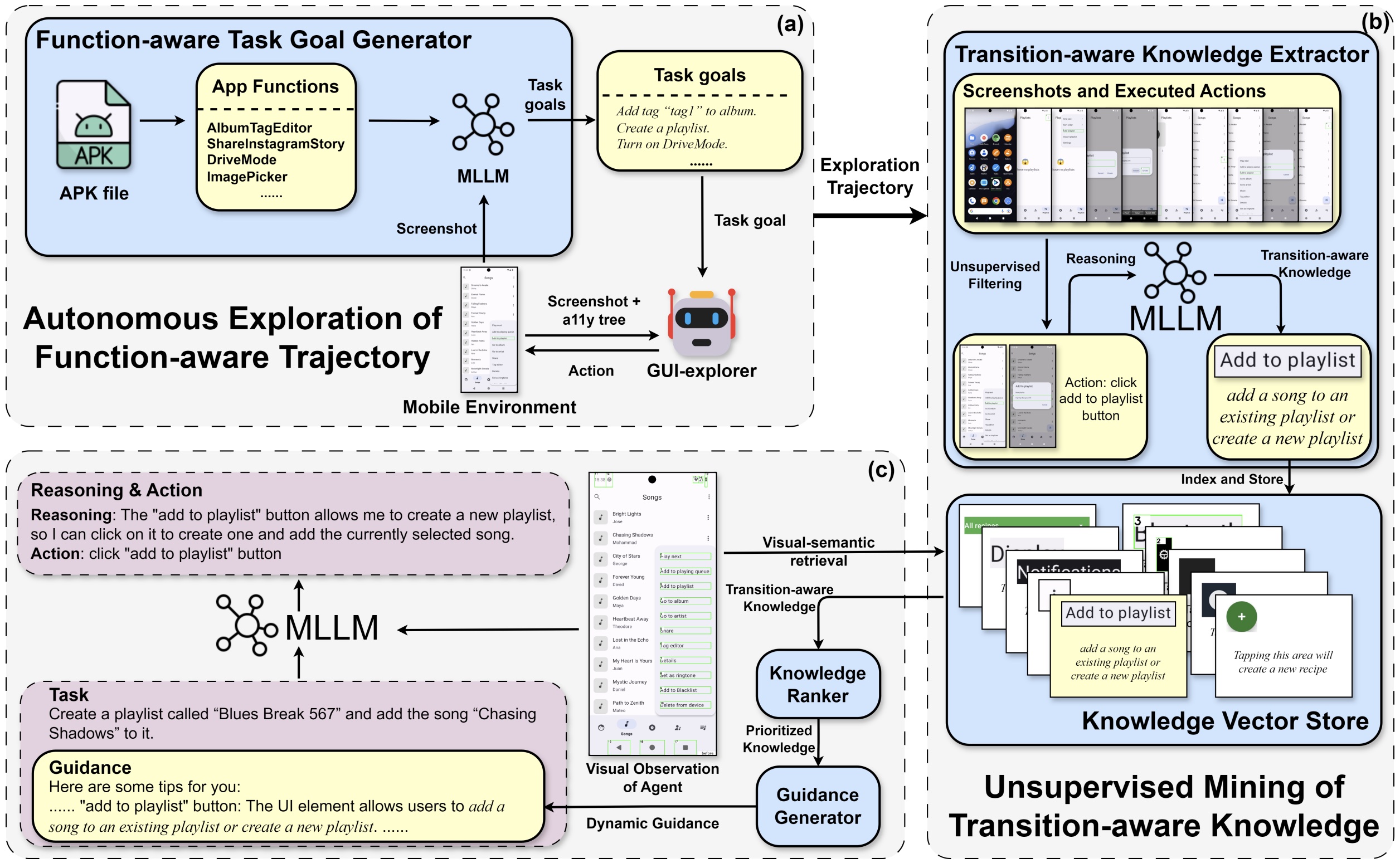 |
GUI-explorer: Autonomous Exploration and Mining of Transition-aware Knowledge for GUI Agent Bin Xie, Rui Shao*, Gongwei Chen, Kaiwen Zhou, Yinchuan Li, Jie Liu, Min Zhang, Liqiang Nie_The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Main, 2025._ [arXiv] [Code] [Project Page] |
|---|---|
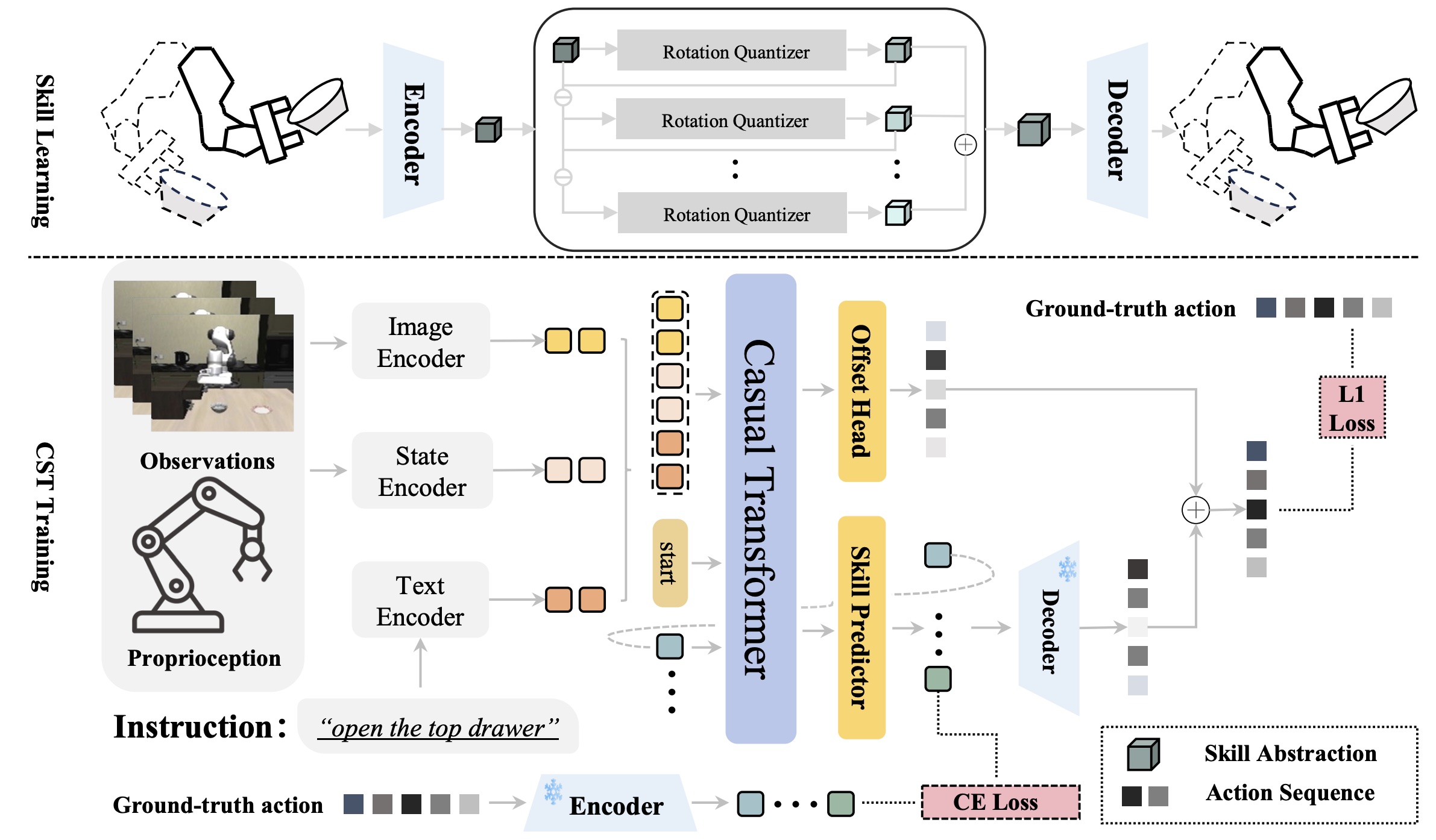 |
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization Hao Li, Qi Lv, Rui Shao*, Xiang Deng, Yinchuan Li, Jianye HAO, Liqiang Nie_International Conference on Machine Learning (ICML), 2025. Spotlight (2.6%)_ [arXiv] [Code] [Project Page] |
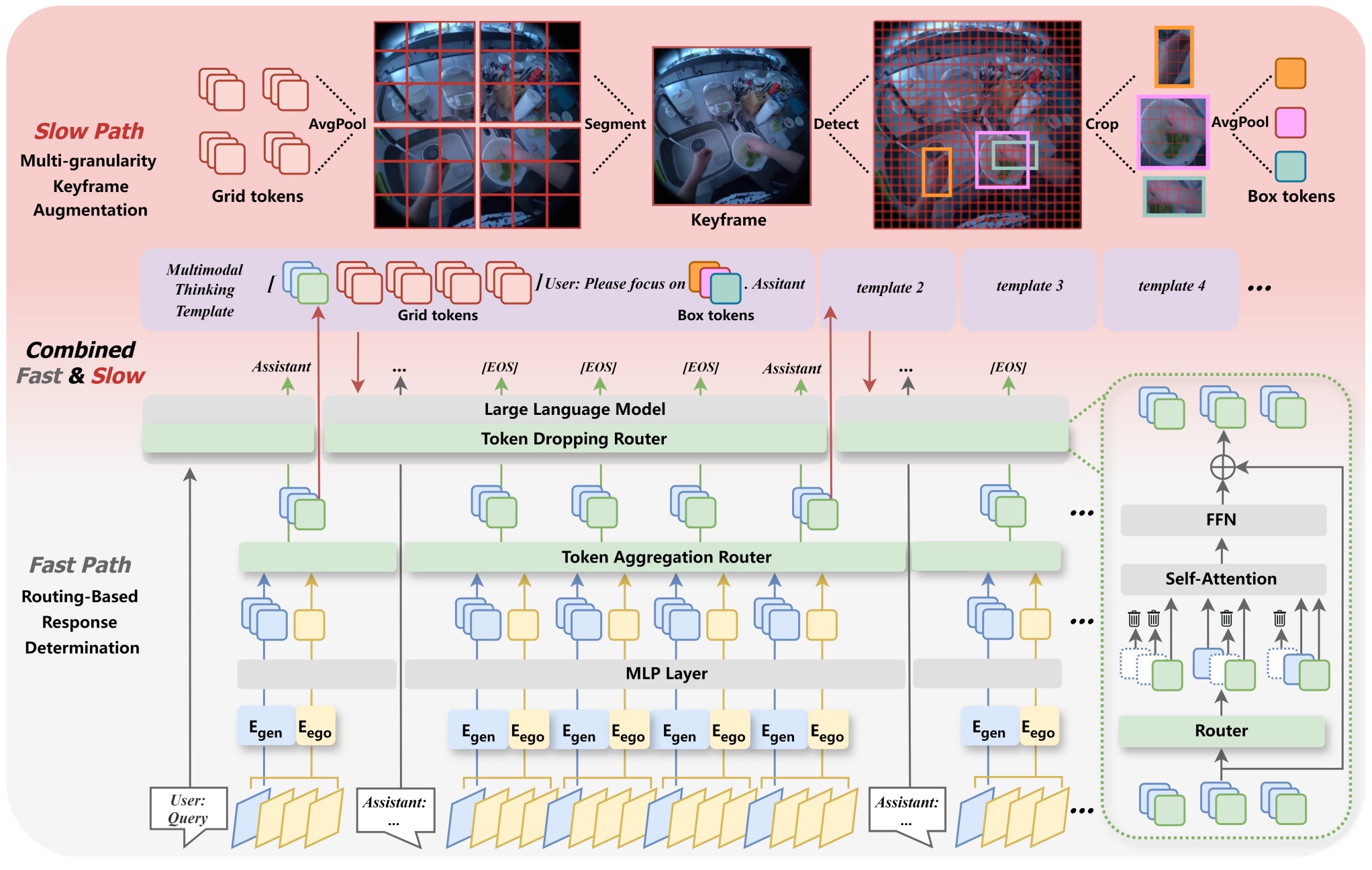 |
LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant Wei Li, Bing Hu, Rui Shao*, Leyang Shen, Liqiang Nie_IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025._ [arXiv] [Code] |
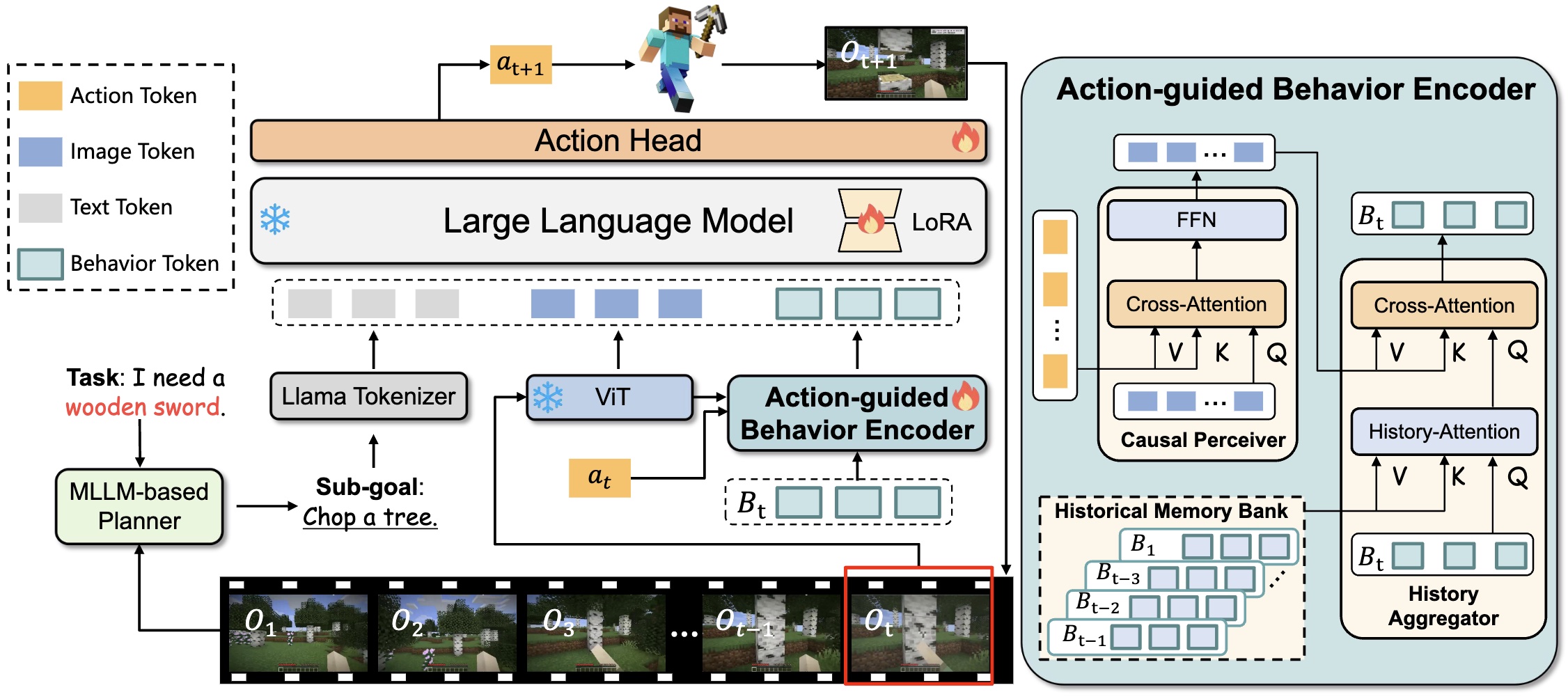 |
Optimus-2: Mulitimodal Minecraft Agent with Goal-Observation-Action Conditioned Policy Zaijing Li, Yuquan Xie, Rui Shao*, Gongwei Chen, Dongmei Jiang, Liqiang Nie*IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [arXiv] [Code] [Project Page] |
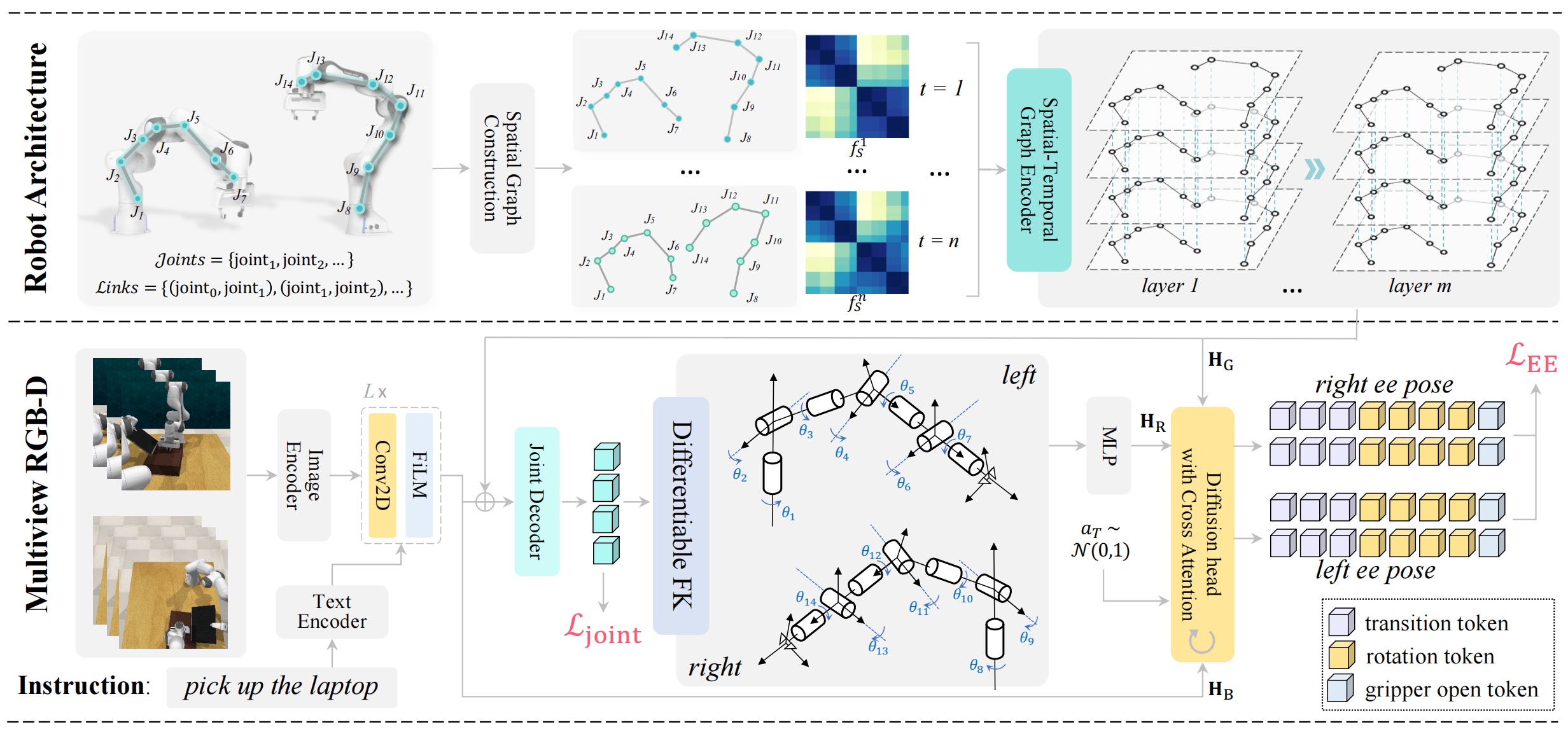 |
Spatial-Temporal Graph Diffusion Policy with Kinematics Modeling for Bimanual Robotic Manipulation Qi Lv, Hao Li, Xiang Deng, Rui Shao, Yinchuan Li, Jianye HAO, Longxiang Gao, MICHAEL YU WANG, Liqiang Nie_IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025._ [arXiv] [Code] |
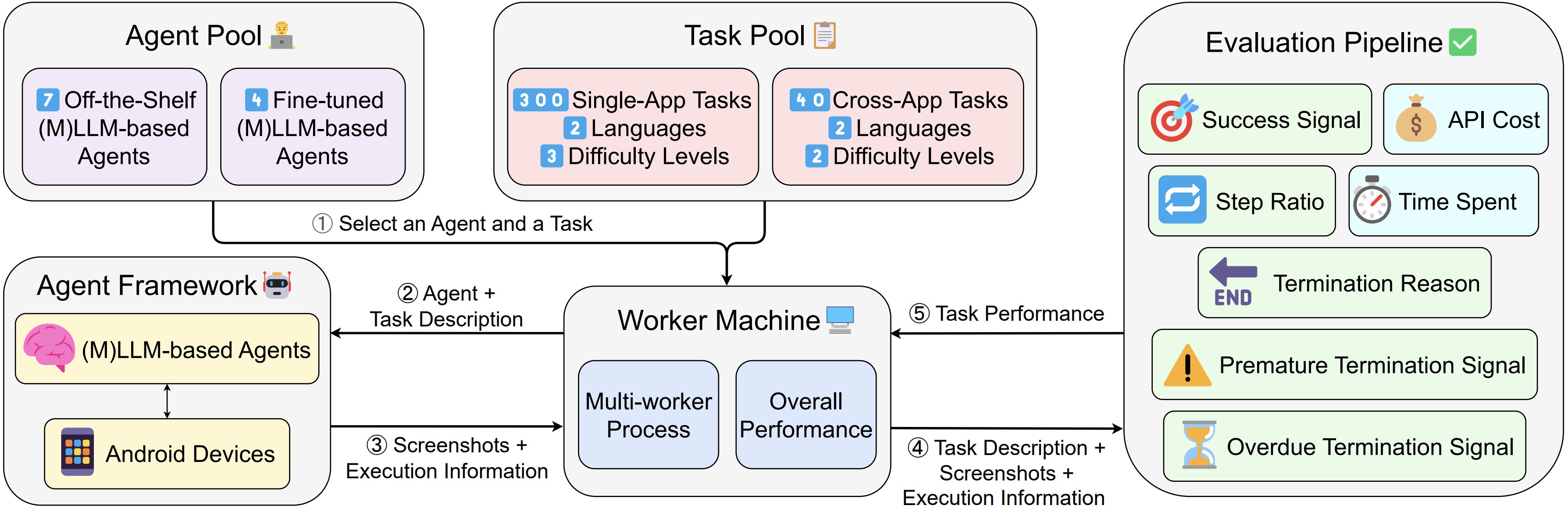 |
SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation Jingxuan Chen, Derek Yuen, Bin Xie, Yuhao Yang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, Kaiwen Zhou, Rui Shao*, Liqiang Nie, Yasheng Wang, Jianye Hao, Jun Wang, Kun Shao*The Thirteenth International Conference on Learning Representations (ICLR), 2025. Spotlight (5.1%) [arXiv] [Code] [Project Page] |
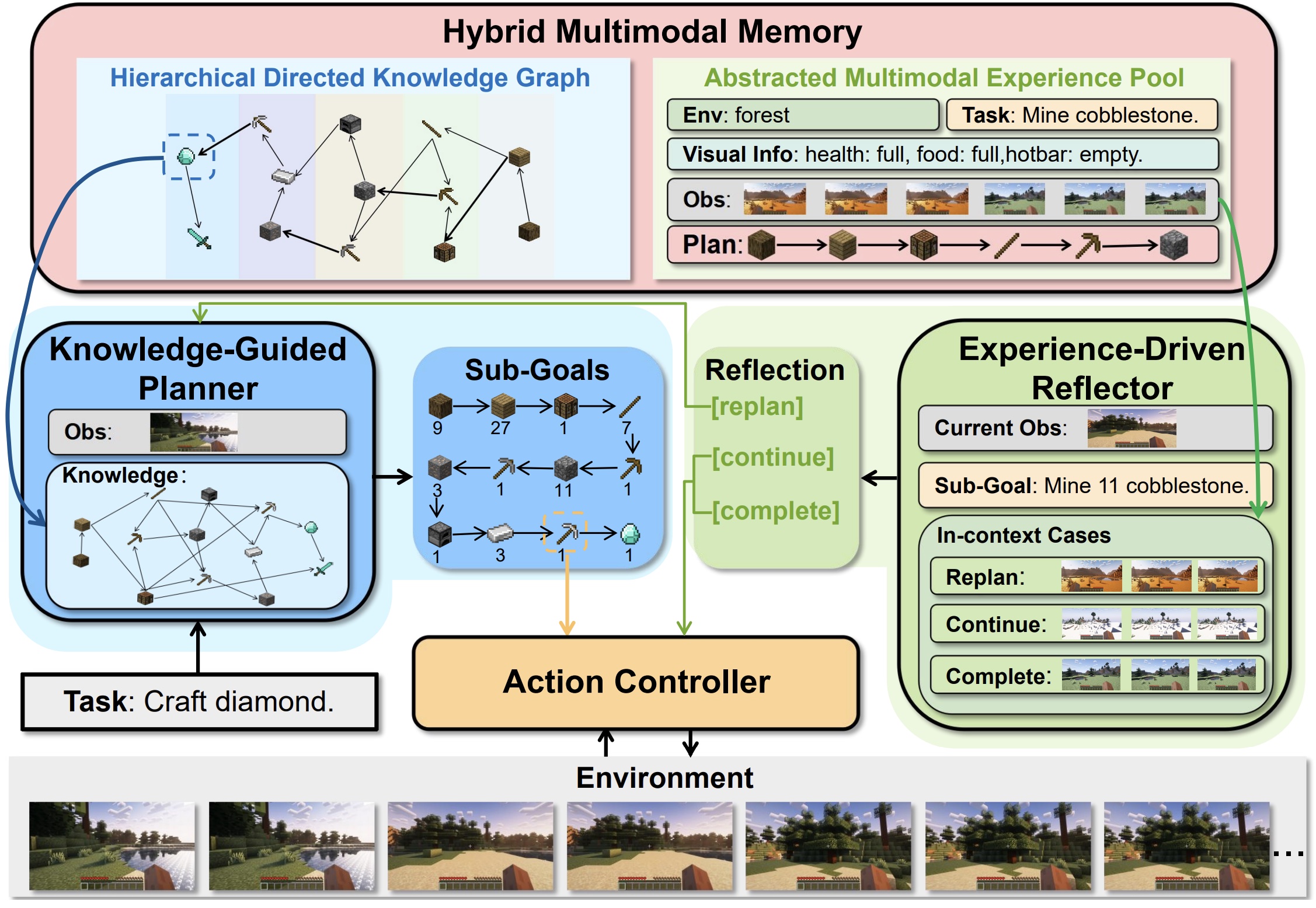 |
Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks Zaijing Li, Yuquan Xie, Rui Shao*, Gongwei Chen, Dongmei Jiang, Liqiang Nie*Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024. [arXiv] [Code] [Project Page] |
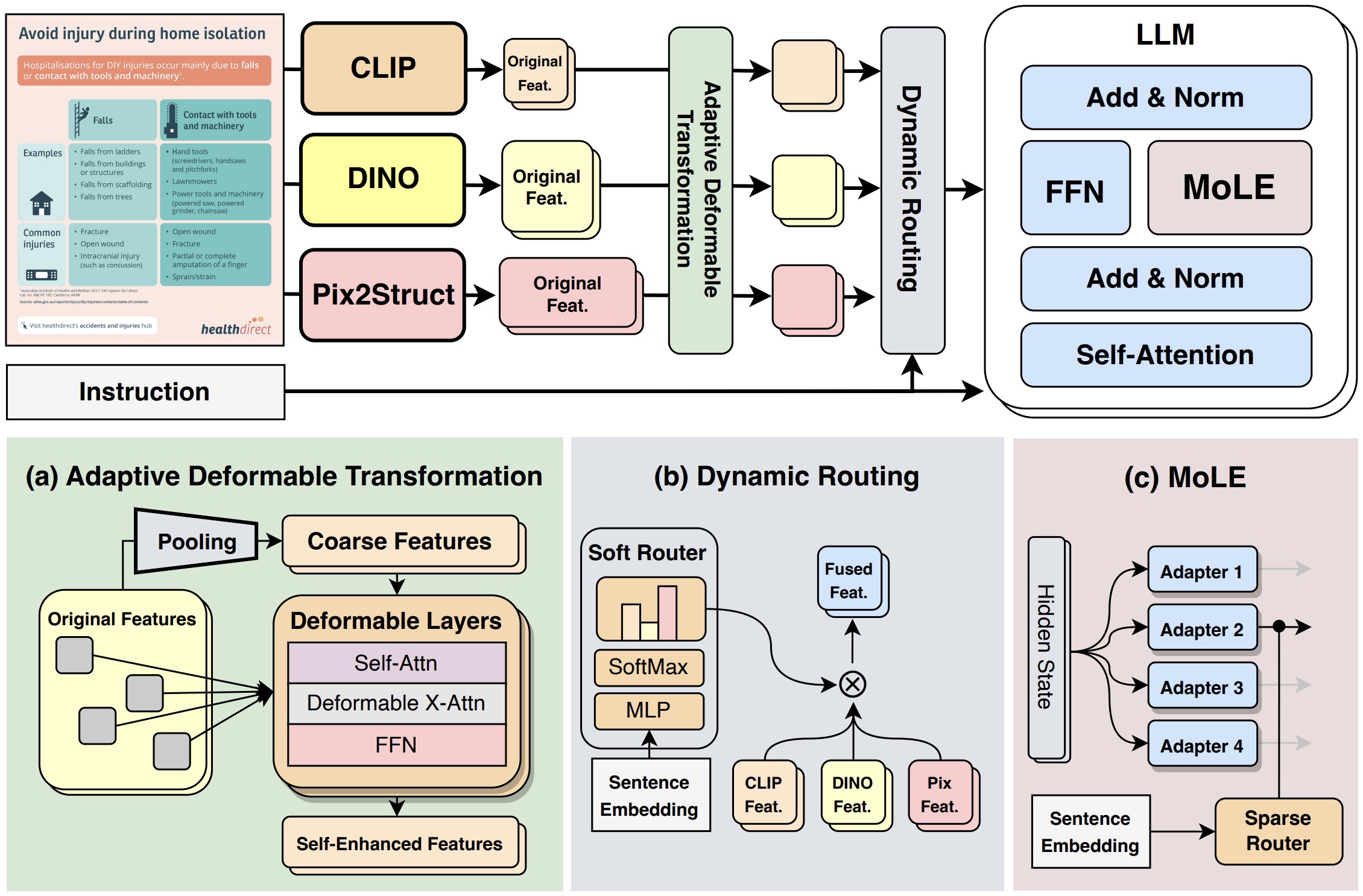 |
MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models Leyang Shen, Gongwei Chen, Rui Shao*, Weili Guan, Liqiang Nie*Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024. [arXiv] [Code] |
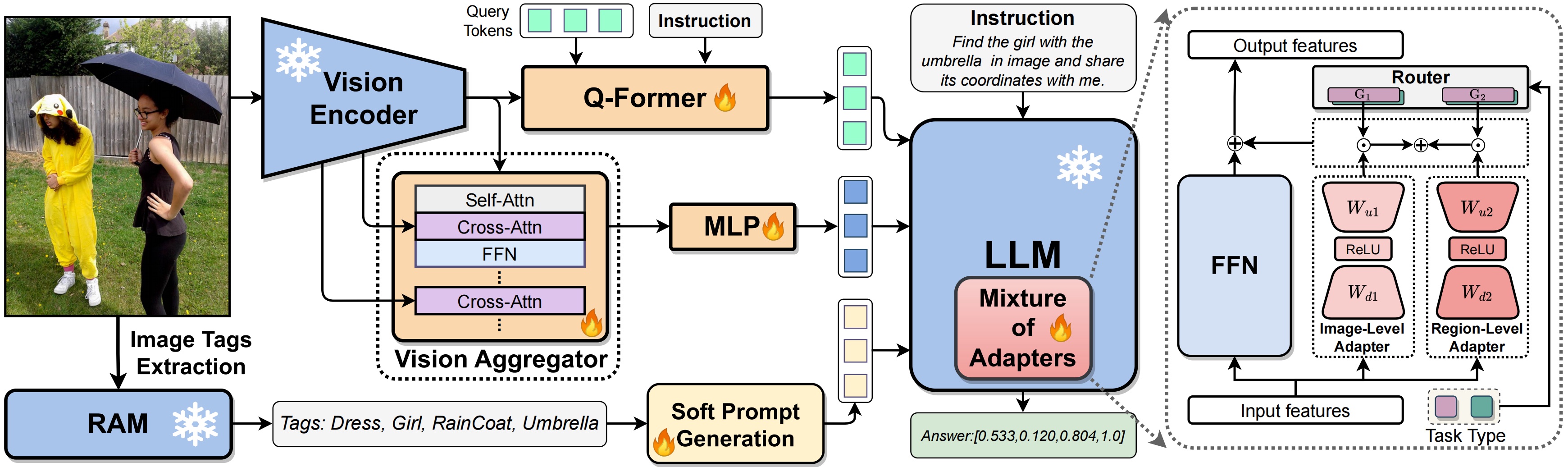 |
LION: Empowering Multimodal Large Language Model with Dual-Level Visual Knowledge Gongwei Chen, Leyang Shen, Rui Shao*, Xiang Deng, Liqiang Nie*IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. [arXiv] [Code] [Project Page] [Press] |
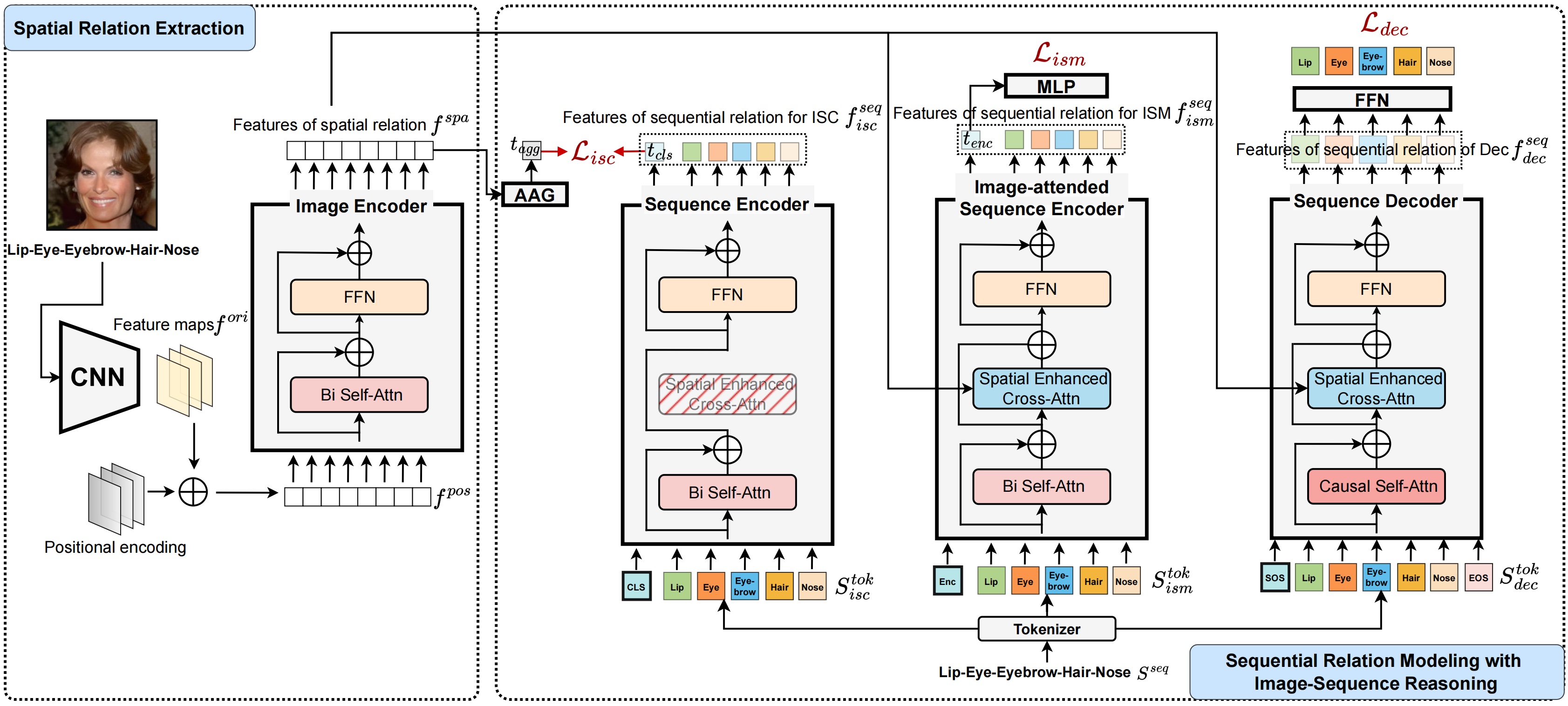 |
Robust Sequential DeepFake Detection Rui Shao, Tianxing Wu, Ziwei Liu_International Journal of Computer Vision (IJCV), 2025_ [arXiv] [PDF] [Code] |
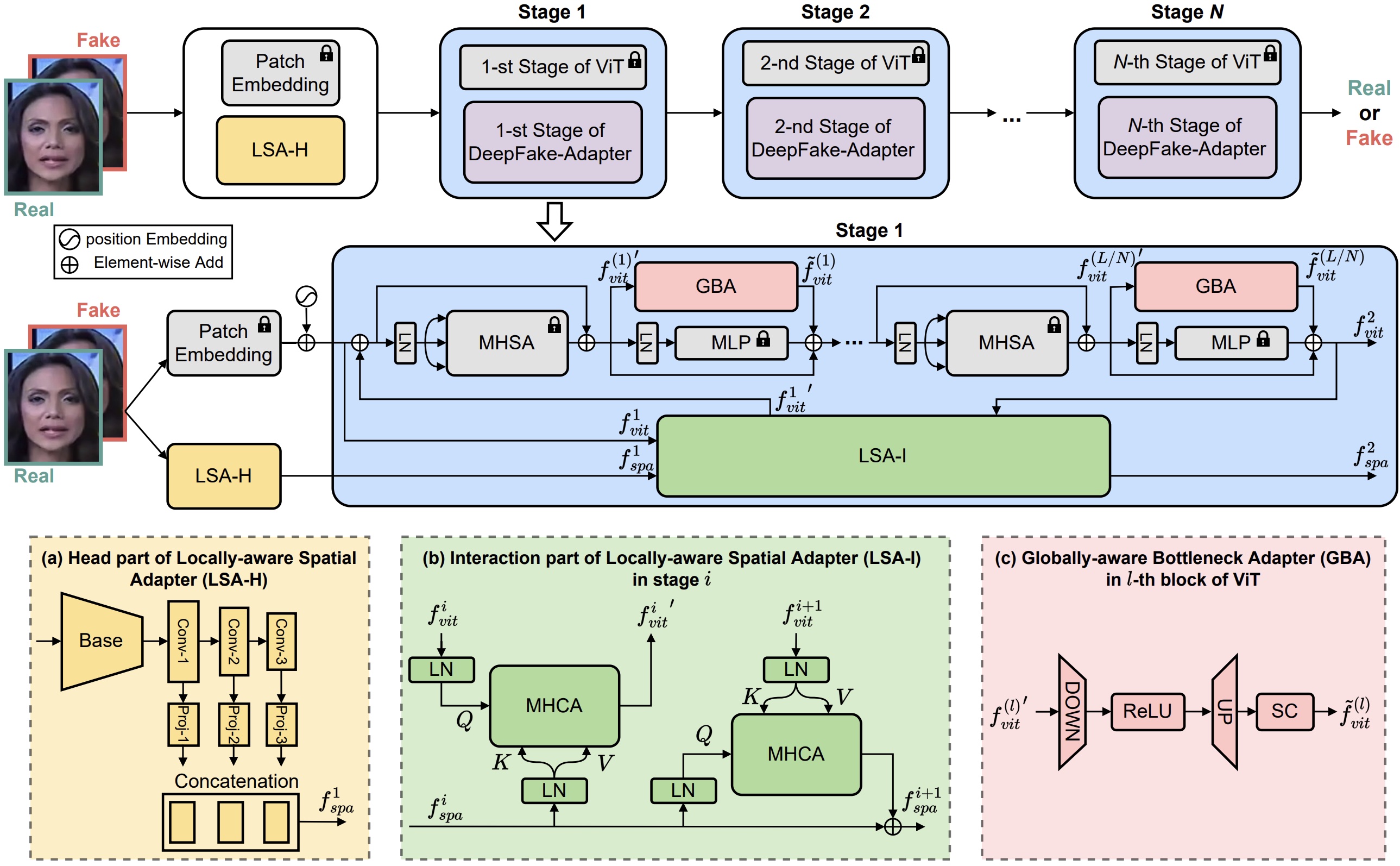 |
DeepFake-Adapter: Dual-Level Adapter for DeepFake Detection Rui Shao, Tianxing Wu, Liqiang Nie, Ziwei Liu_International Journal of Computer Vision (IJCV), 2025_ [arXiv] [PDF] [Code] |
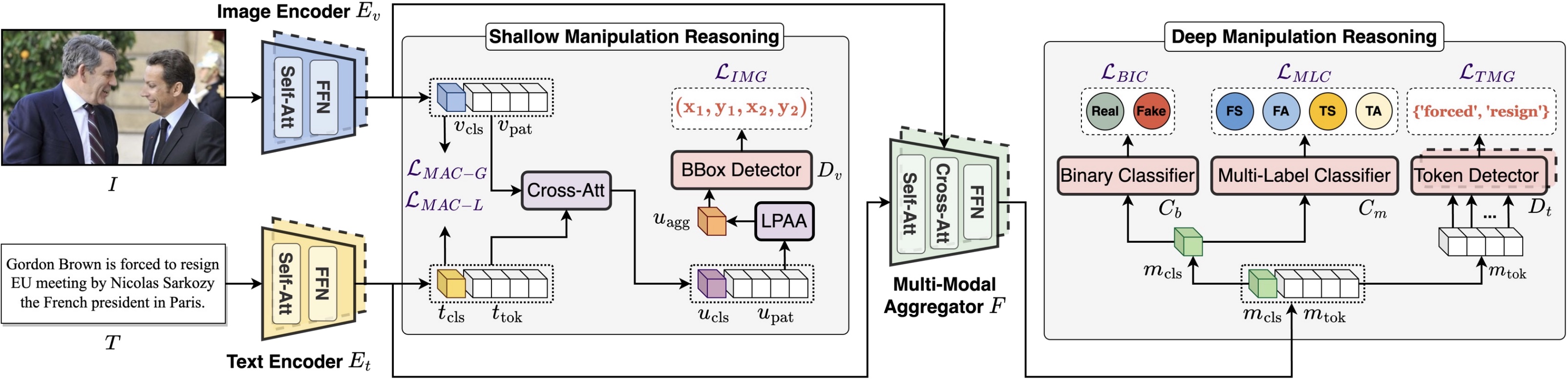 |
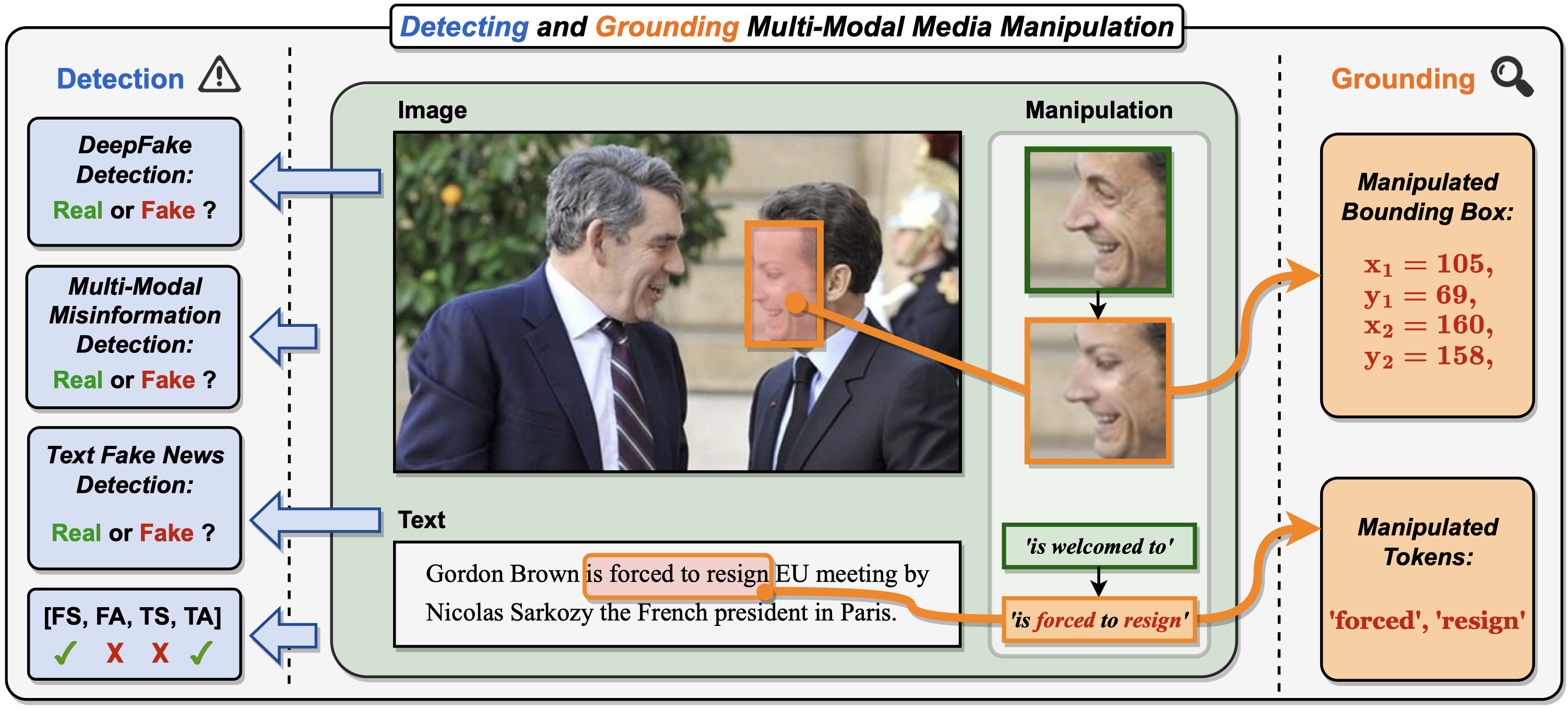
Detecting and Grounding Multi-Modal Media Manipulation and Beyond Rui Shao, Tianxing Wu, Jianlong Wu, Liqiang Nie, Ziwei Liu_IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024_ [arXiv] [Code] [Project Page] [Press] |
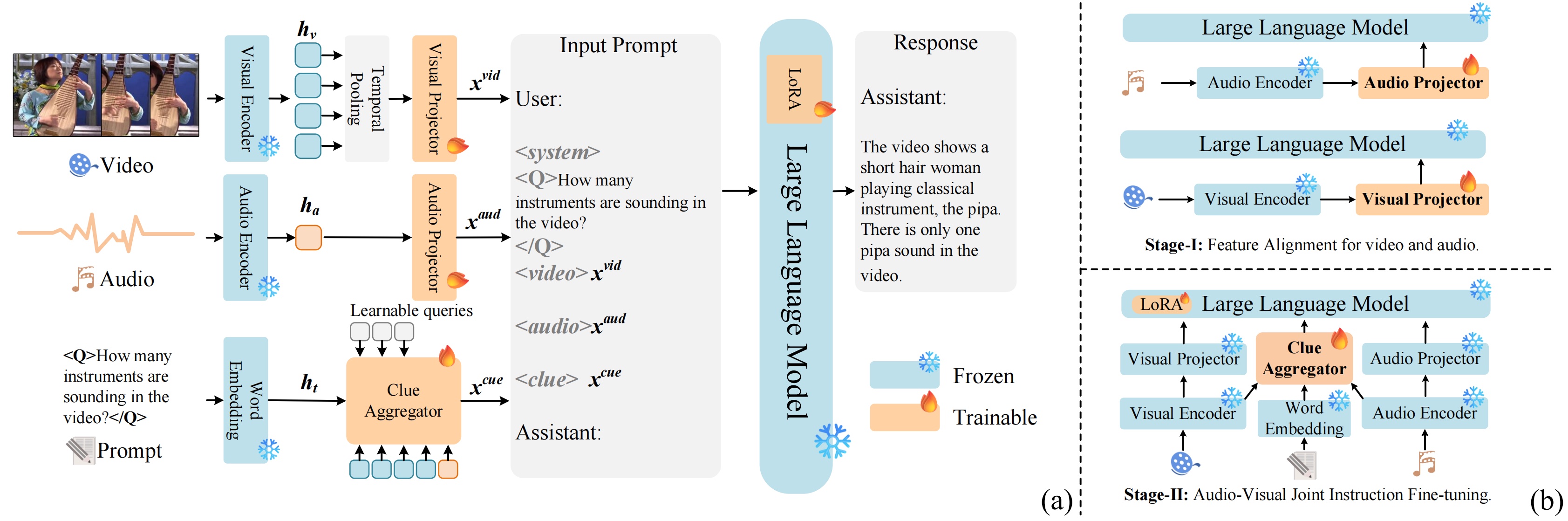 |
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios Qilang Ye, Zitong Yu, Rui Shao, Xinyu Xie, Philip Torr, Xiaochun Cao_European Conference on Computer Vision (ECCV), 2024._ [arXiv] [Code] [Project Page] |
 |
Detecting and Grounding Multi-Modal Media Manipulation Rui Shao, Tianxing Wu, Ziwei Liu_IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023._ [arXiv] [Code] [Project Page] [Press] |
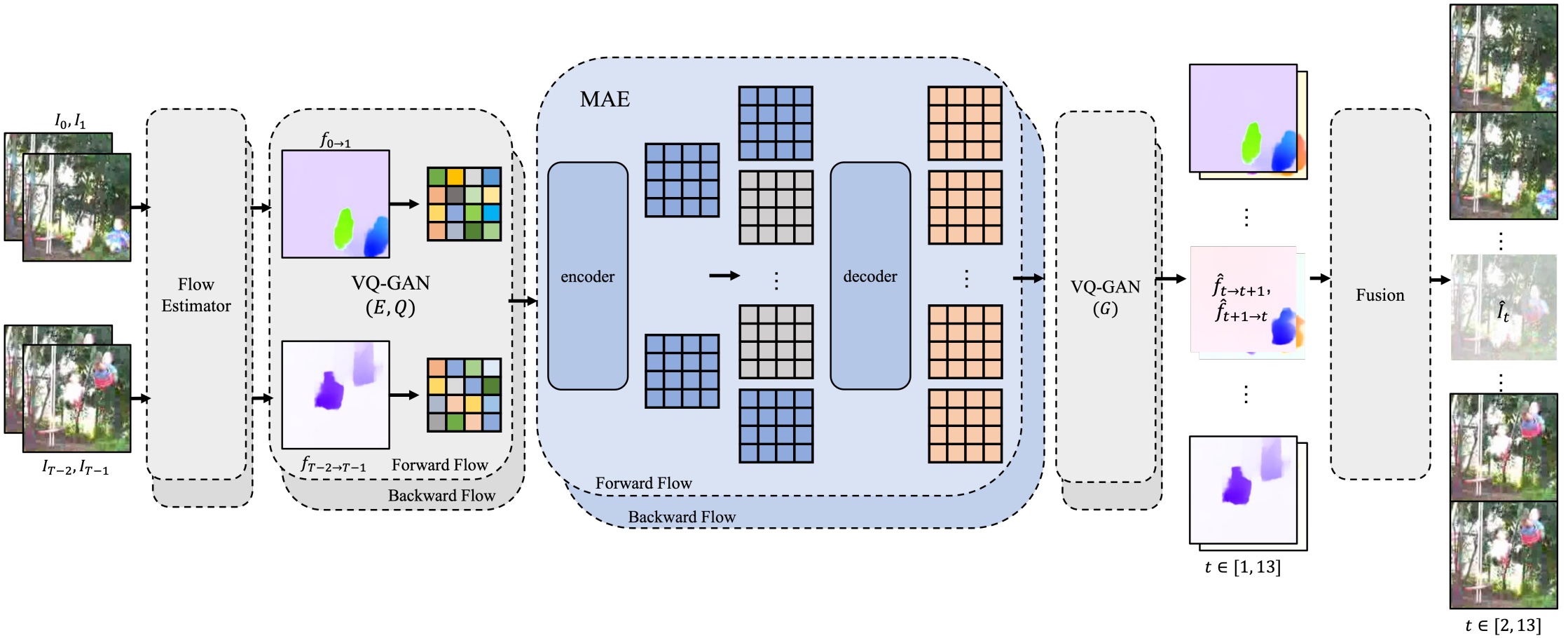 |
Video Infilling with Rich Motion Prior Xinyu Hou, Liming Jiang, Rui Shao, Chen Change Loy_British Machine Vision Conference (BMVC), 2023._ [arXiv] [Code] |
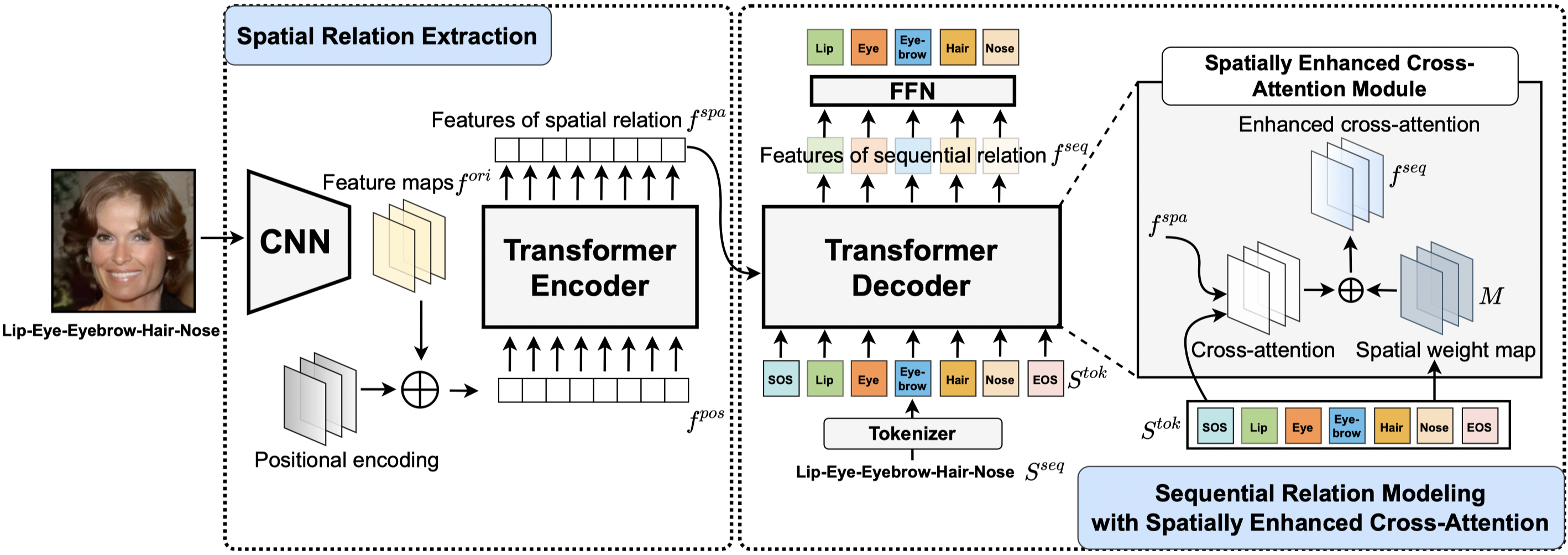 |
Detecting and Recovering Sequential DeepFake Manipulation Rui Shao, Tianxing Wu, Ziwei Liu_European Conference on Computer Vision (ECCV), 2022._ [arXiv] [Code] [Project Page] [Poster] [Press1] [Press2] [Press3] [Press4] |
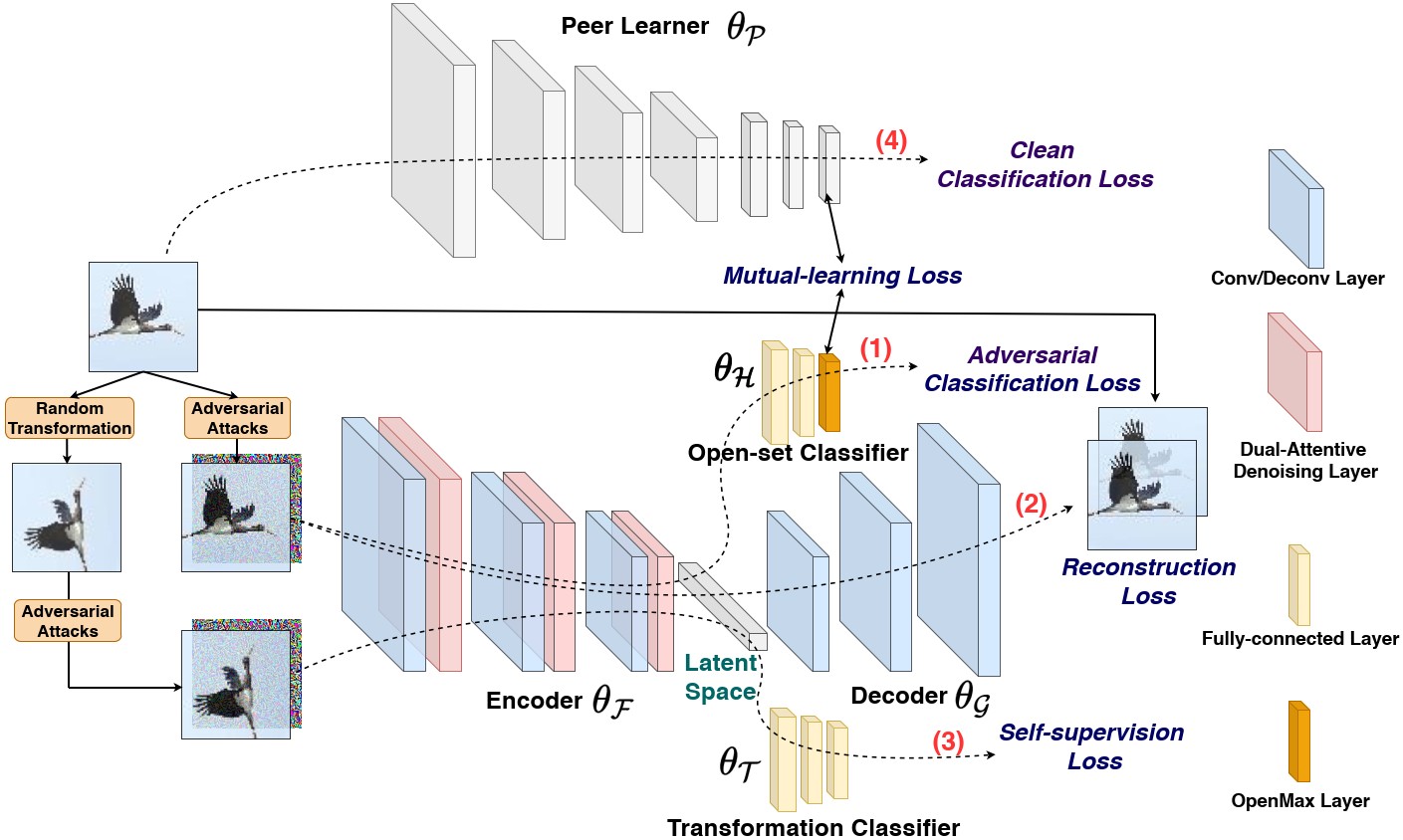 |
Open-set Adversarial Defense with Clean-Adversarial Mutual Learning Rui Shao, Pramuditha Perera, Pong C. Yuen, Vishal M. Patel_International Journal of Computer Vision (IJCV), 2022_ [arXiv] [PDF] [Code] |
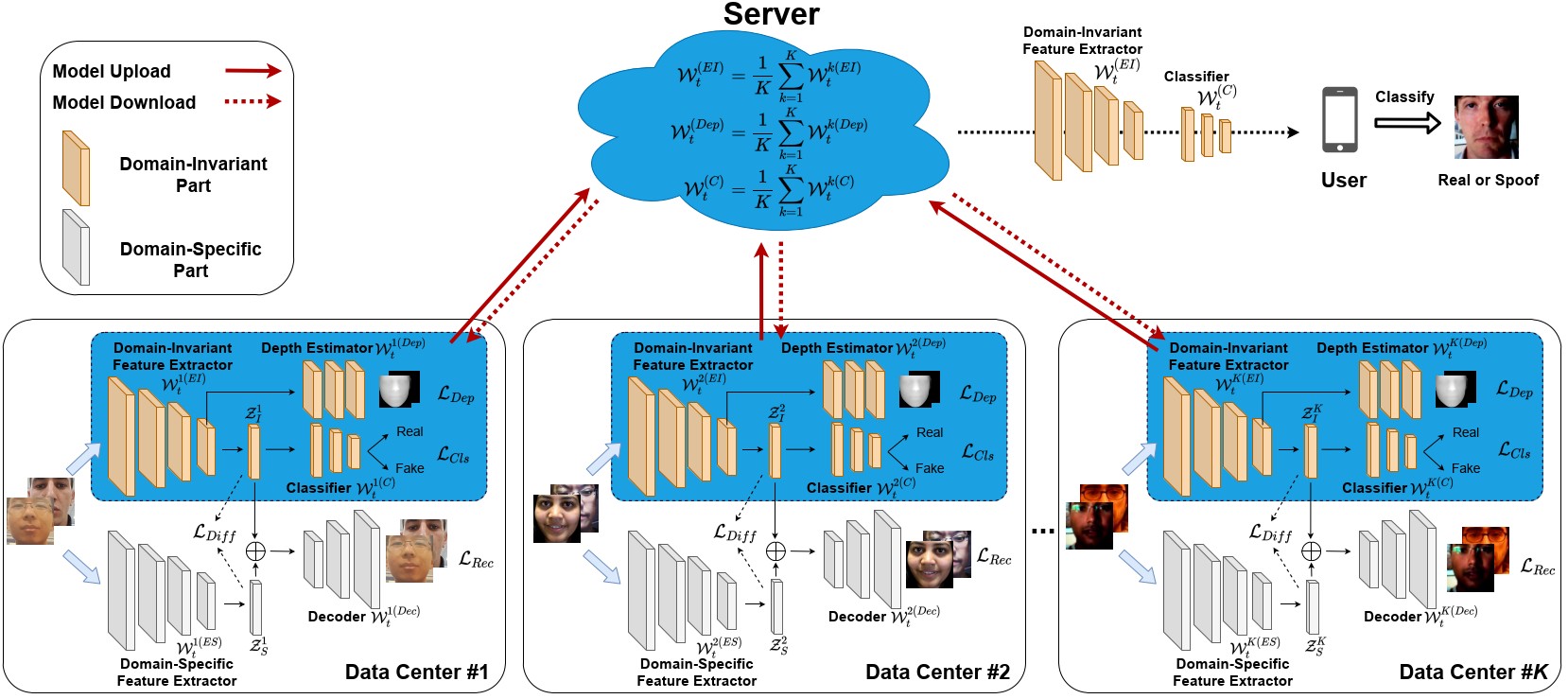 |
Federated Generalized Face Presentation Attack Detection Rui Shao, Pramuditha Perera, Pong C. Yuen, Vishal M. Patel_IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2022._ [arXiv] [PDF] [Code] |
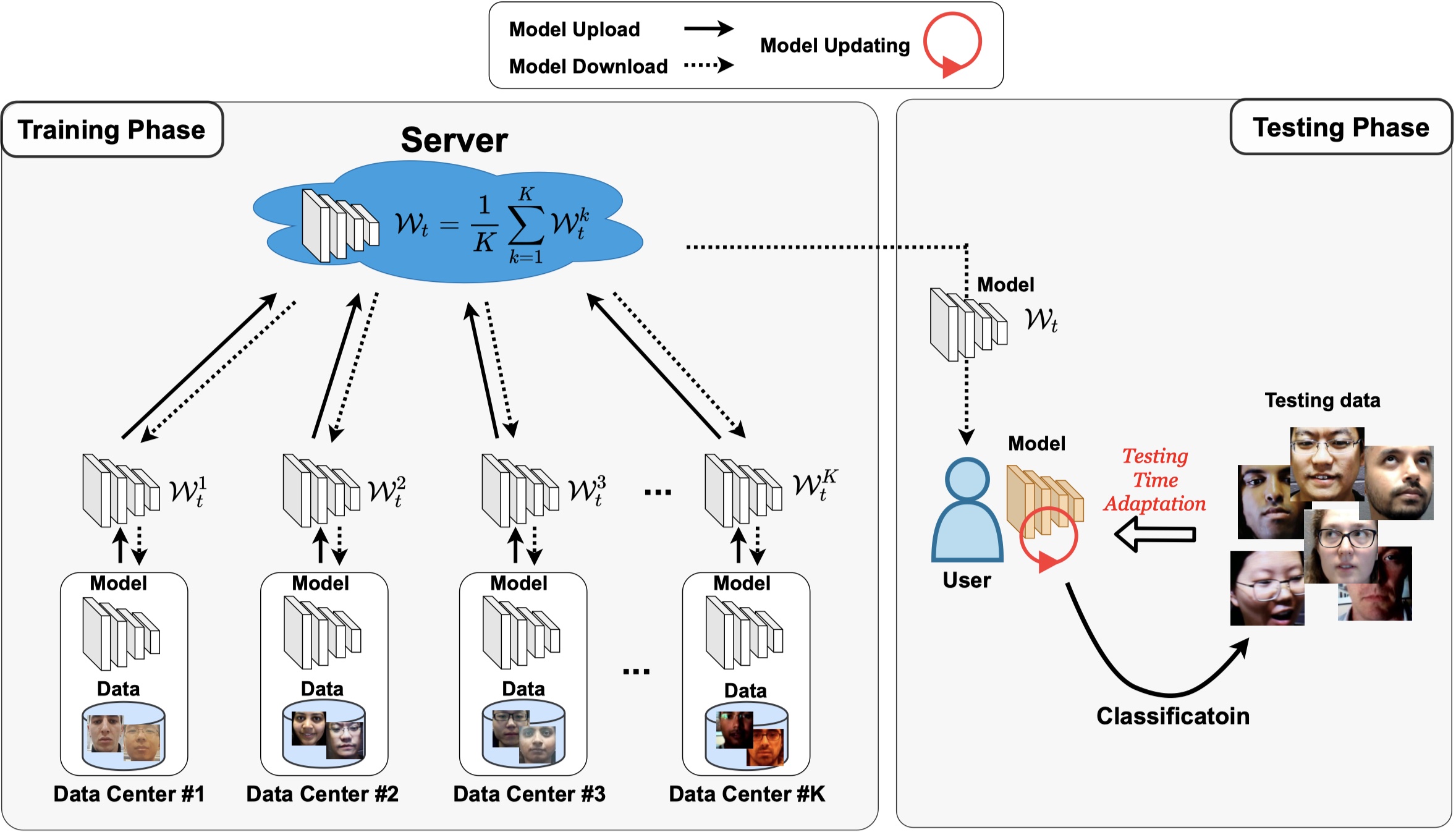 |
Federated Test-Time Adaptive Face Presentation Attack Detection with Dual-Phase Privacy Preservation Rui Shao, Bochao Zhang, Pong C. Yuen, Vishal M. Patel_IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2021_ [arXiv] [PDF] |
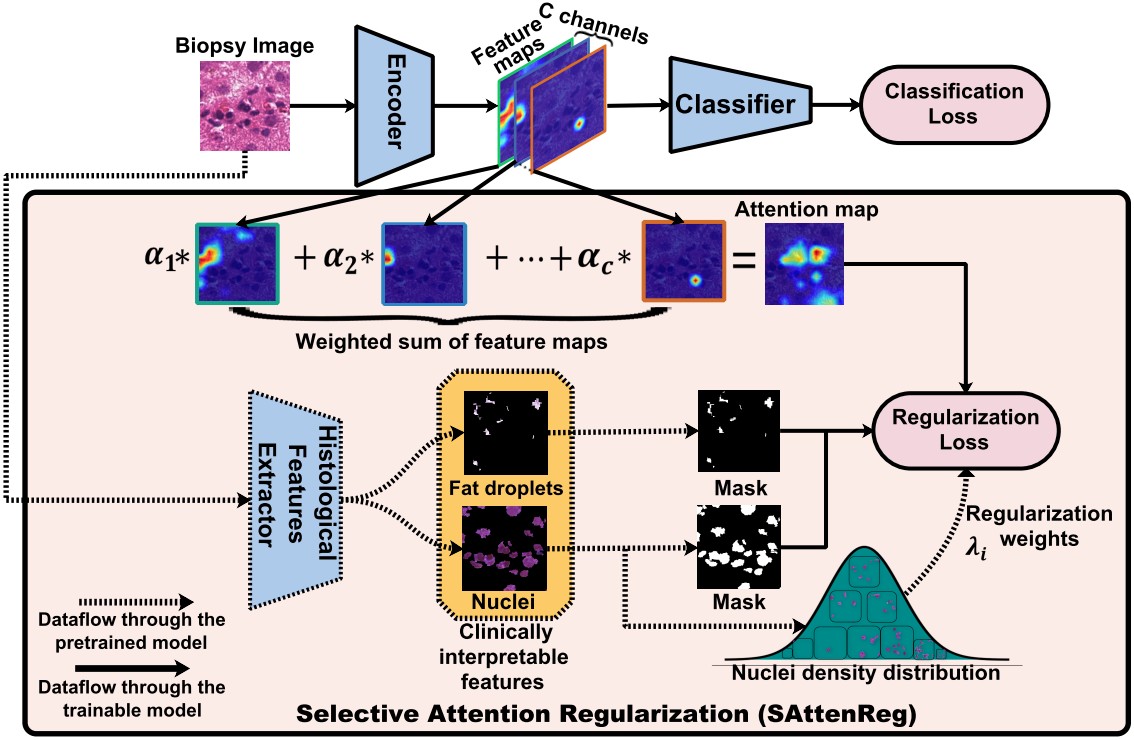 |
Focusing on Clinically Interpretable Features: Selective Attention Regularization for Liver Biopsy Image Classification Chong Yin, Siqi Liu, Rui Shao, Pong C. Yuen,Medical Image Computing and Computer Assisted Interventions (MICCAI), 2021 [PDF] |
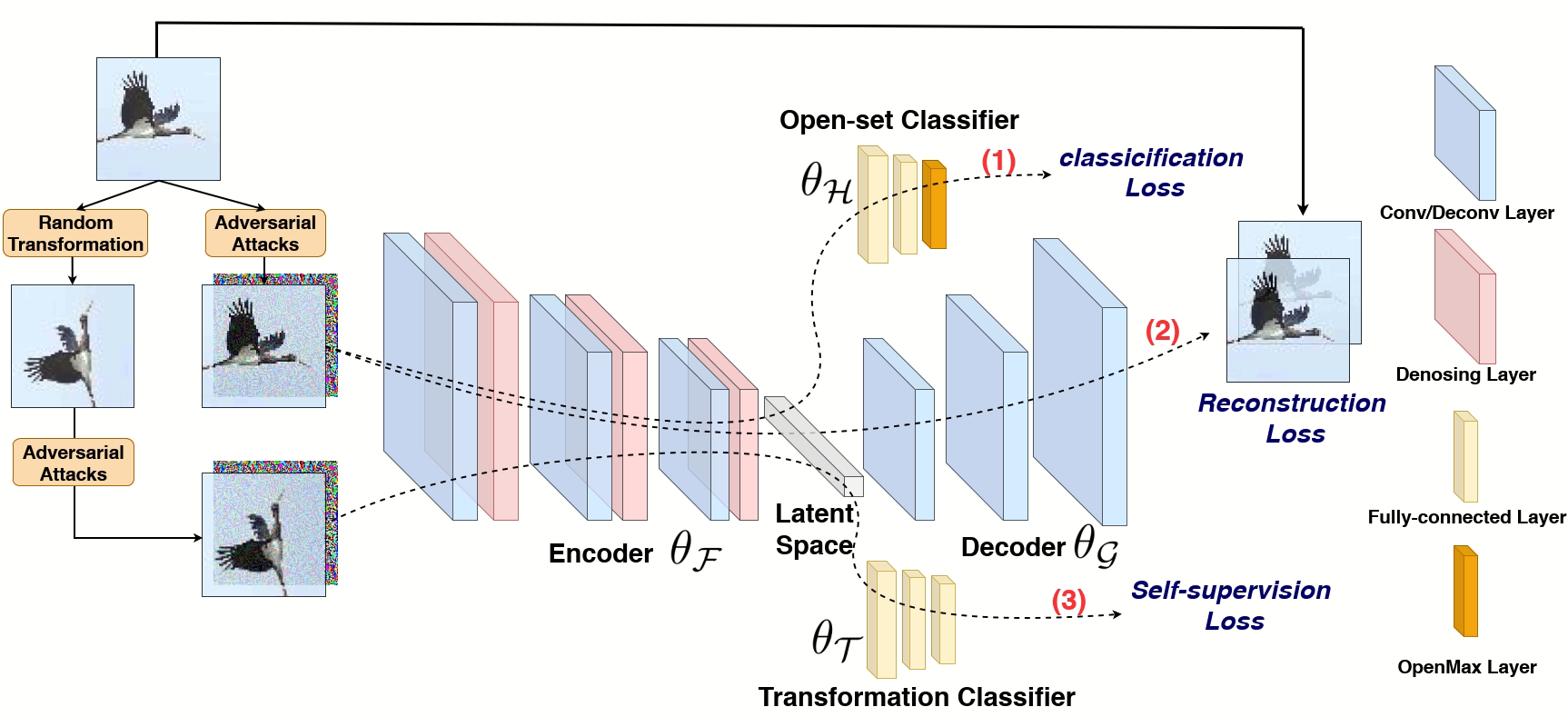 |
Open-set Adversarial Defense Rui Shao, Pramuditha Perera, Pong C. Yuen, Vishal M. Patel_European Conference on Computer Vision (ECCV), 2020_ [arXiv] [PDF] [Code] |
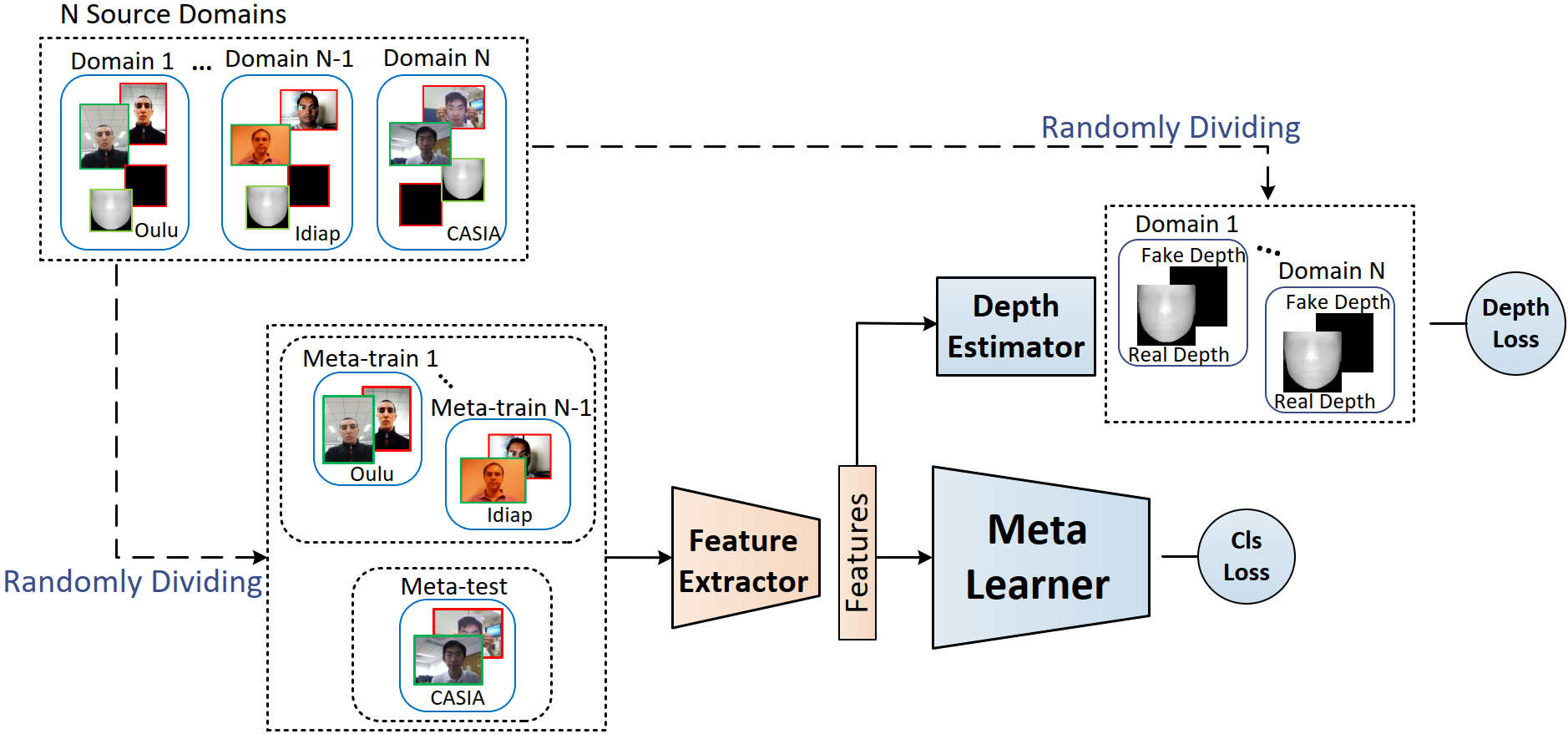 |
Regularized Fine-grained Meta Face Anti-spoofing Rui Shao, Xiangyuan Lan, Pong C. Yuen_Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), 2020_ [arXiv] [[PDF](./linkfile/AAAI2020/6873-Article Text-10102-1-10-20200525.pdf)] [Poster] [Code] |
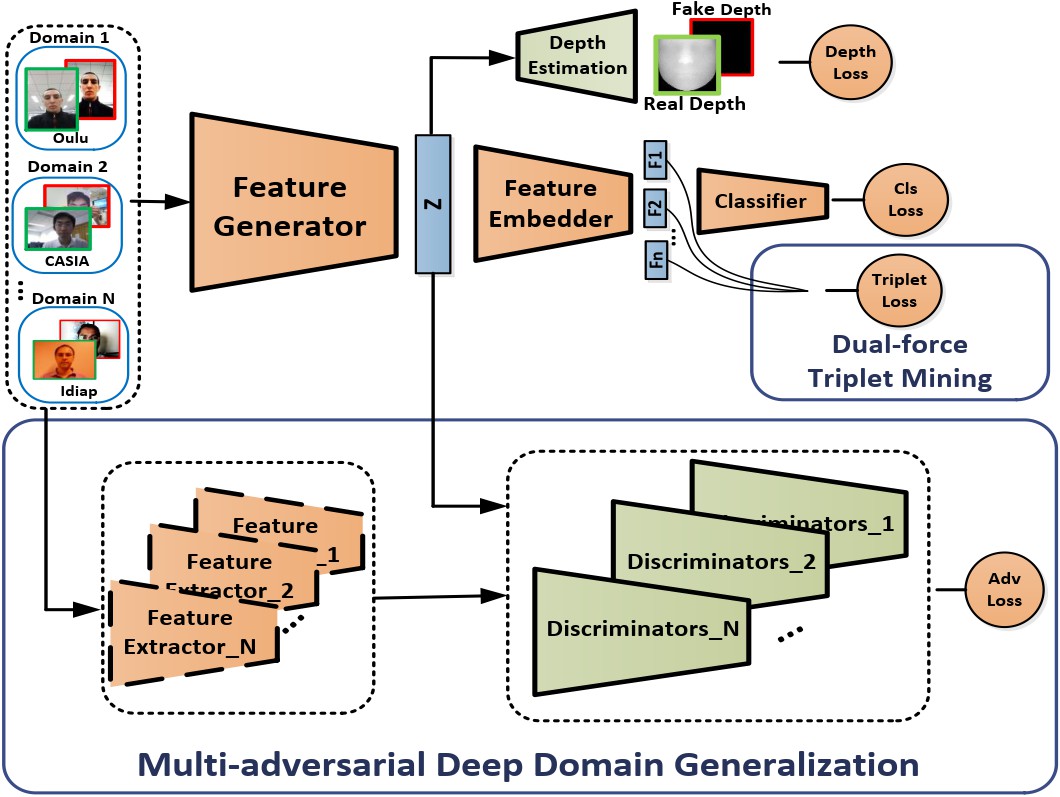 |
Multi-adversarial Discriminative Deep Domain Generalization for Face Presentation Attack Detection Rui Shao, Xiangyuan Lan, Jiawei Li, Pong C. Yuen_IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019_ [PDF] [Poster] [Code] [Model] |
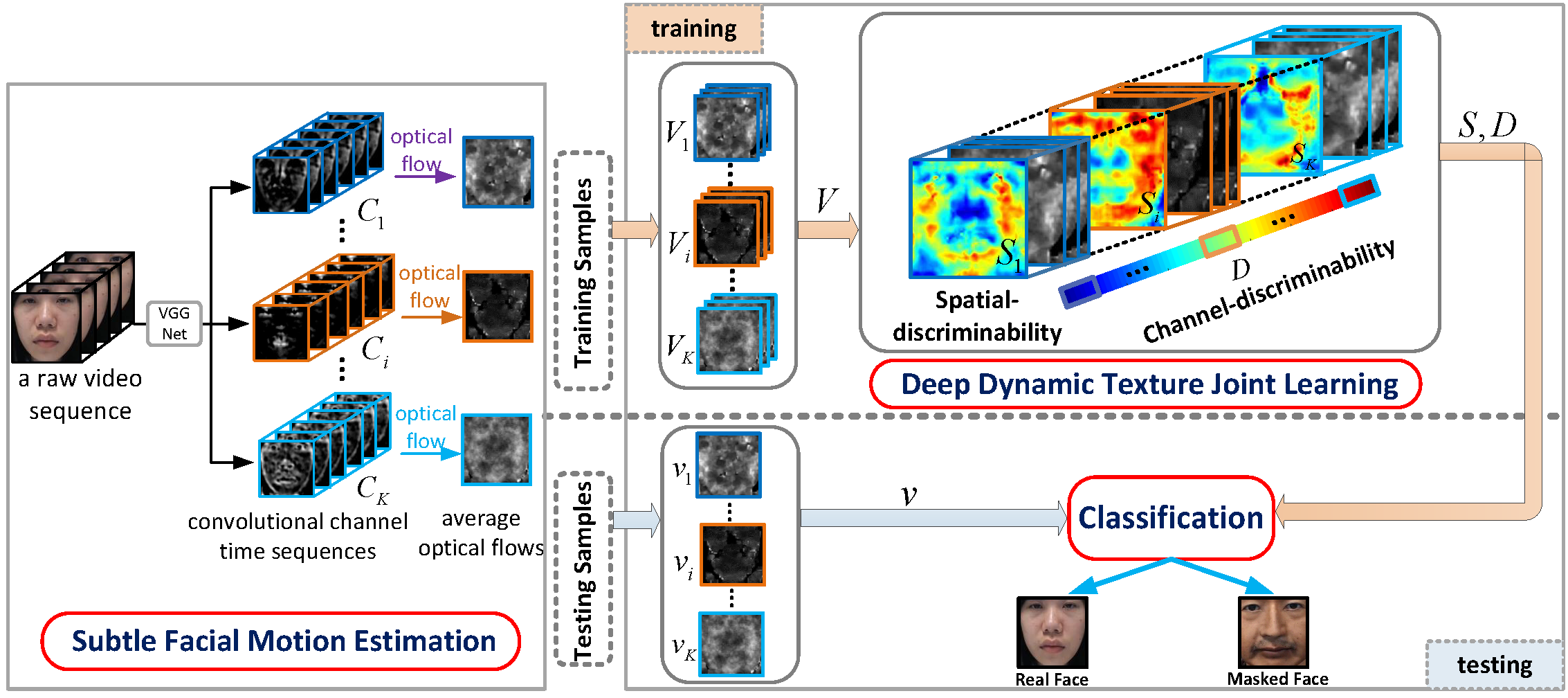 |
Joint Discriminative Learning of Deep Dynamic Textures for 3D Mask Face Anti-spoofing Rui Shao, Xiangyuan Lan, Pong C. Yuen IEEE Transactions on Information Forensics and Security (TIFS), 2019 [PDF] [Code] |
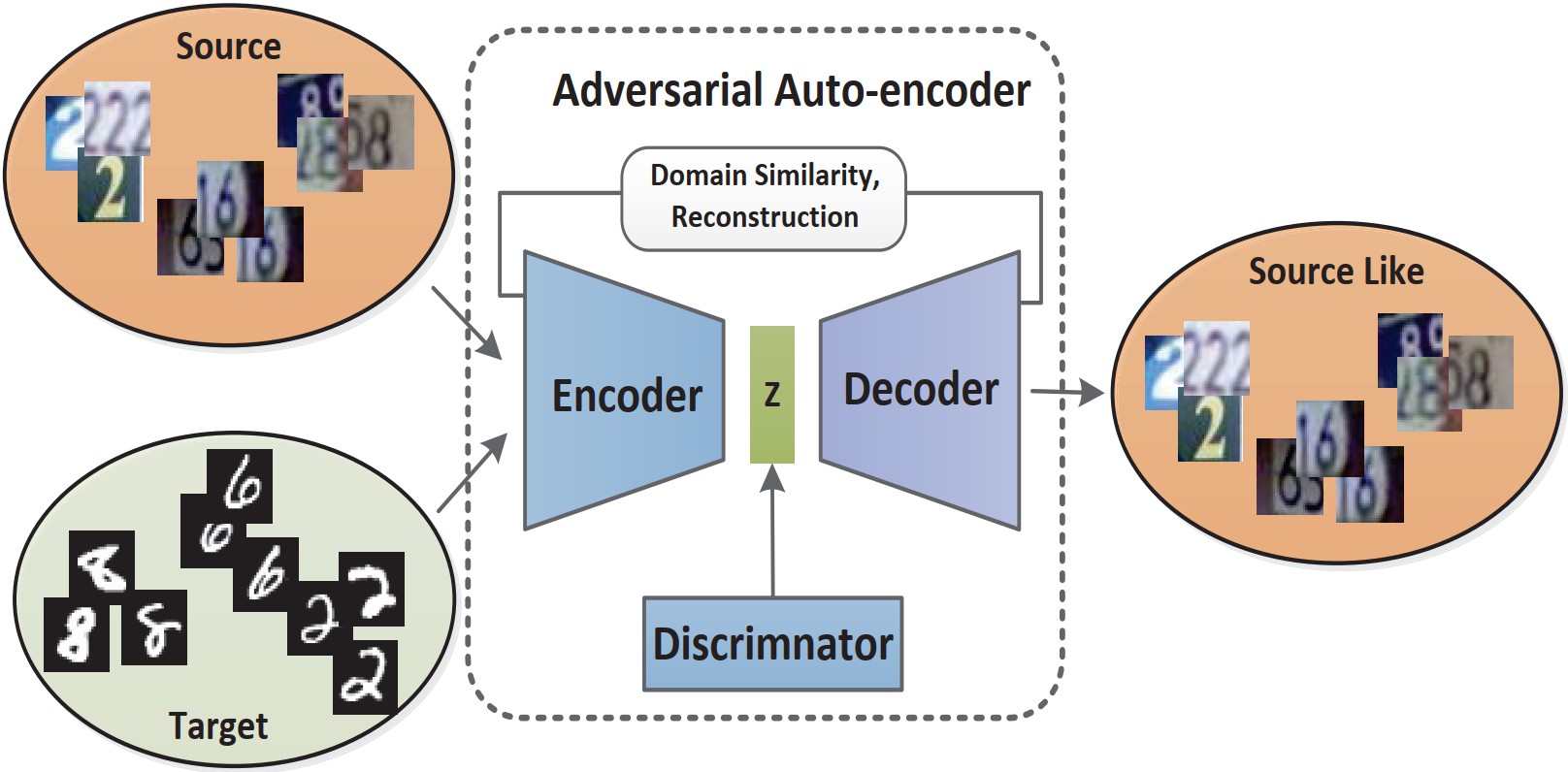 |
Adversarial Auto-encoder for Unsupervised Deep Domain Adaptation Rui Shao, Xiangyuan Lan IET Image Processing. (IET-IPR), 2019 [PDF] |
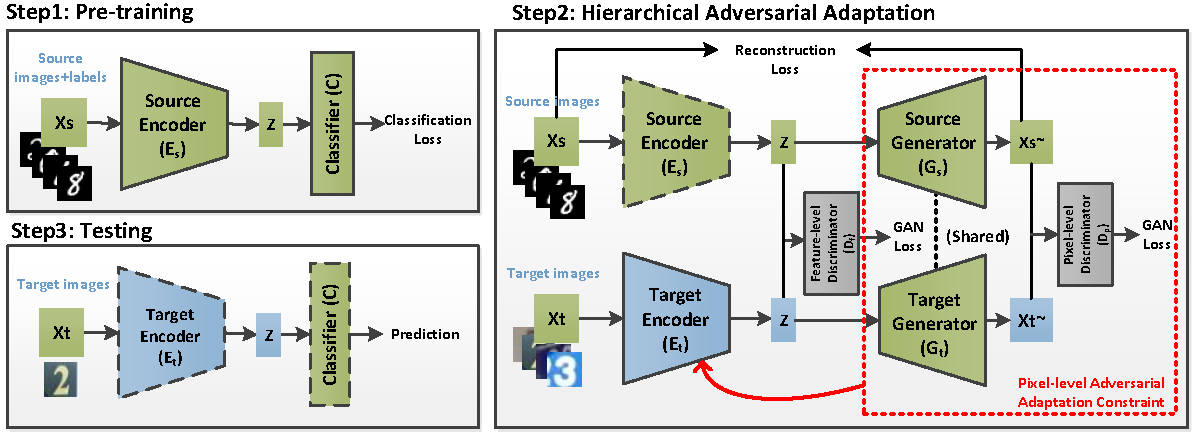 |
Feature Constrained by Pixel: Hierarchical Adversarial Deep Domain Adaptation Rui Shao, Xiangyuan Lan, Pong C. Yuen ACM international conference on Multimedia (ACM MM), 2018 [PDF] [Poster] [Code] |
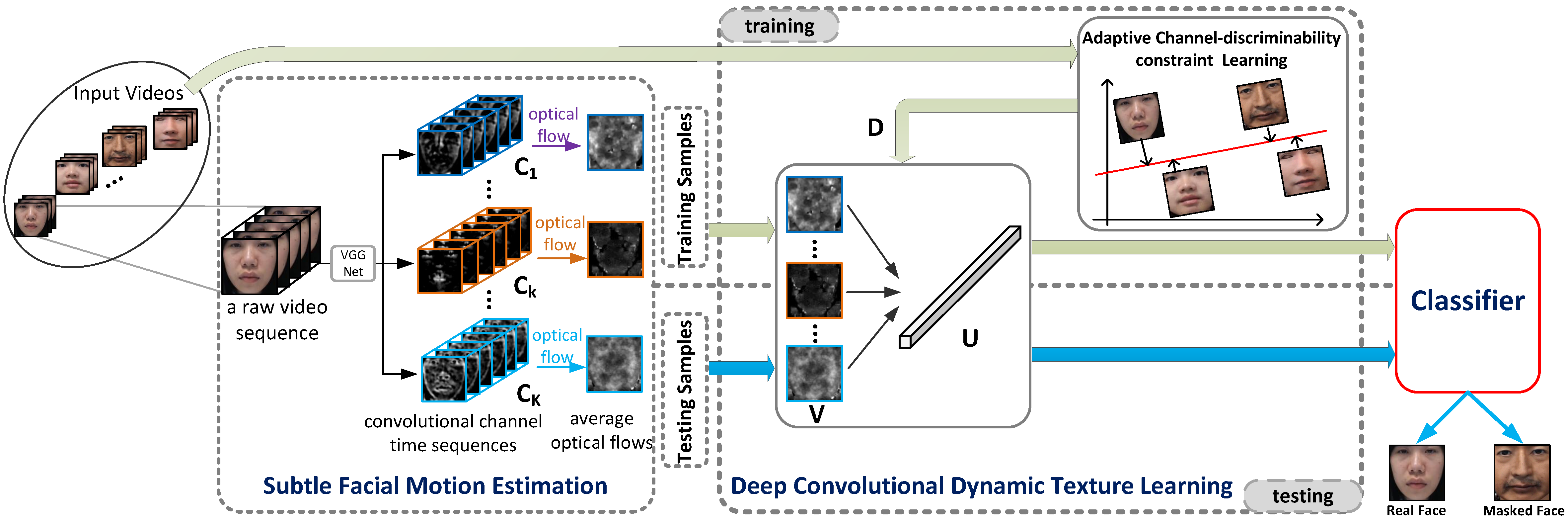 |
Deep Convolutional Dynamic Texture Learning with Adaptive Channel-discriminability for 3D Mask Face Anti-spoofing Rui Shao, Xiangyuan Lan, Pong C. Yuen International Joint Conference on Biometrics (IJCB), 2017 [PDF] |
 |
Learning Modality-Consistency Feature Templates: A Robust RGB-Infrared Tracking System Xiangyuan Lan, Mang Ye, Rui Shao, Bineng Zhong, Pong C. Yuen, Huiyu Zhou IEEE Transactions on Industrial Electronics (TIE), 2019 [PDF] |
Services
- ICMR 2025 Panel Co-Chairs
- Area Chair: ACM Multimedia 2024, BMVC 2024 2025
Collaborators
- Prof. Ziwei Liu, Nanyang Technological University
- Prof. Vishal M Patel, Johns Hopkins University
- Dr. Xiangyuan Lan, Peng Cheng Laboratory
- Dr. Pramuditha Perera, Johns Hopkins University, AWS AI Lab