Ryuz's tech blog (original) (raw)
はじめに
まだまだ現役で利用されているシーンも多いかとは思いますが、下記のようなUSBに接続するタイプのアクセラレータが 2018年~2019年ごろ発売され始めて以降、特に進化したバージョンが現れてニュースを騒がせたりしていない気がします(私が知らないだけかもしれませんが)。
今更なのですが、少しスペックを見ながら考察してみようと思います。
仕様調査
仕様を調べてみて、あまり不確かでない情報や ChatGPT の回答などもあるのですが、なんとなくそれっぽい値をかき集めてみました。
| Intel Neural Compute Stick 2 | Coral USB Accelerator | |
|---|---|---|
| インターフェース | USB 3.1 gen1 ? | USB 3.1 gen1 |
| 演算能力 | 4 TOPS | 4 TOPS |
| プロセッサ | Intel Movidius Myriad X VPU | Google Edge TPU |
| プロセッサの周波数 | 700MHz | 500MHz? |
| メモリ | 4GB 32bit@1600MHz | 8MB (on chip) ? |
| 消費電力 | 1~2.5W? | 2 W per TOPS |
| 価格 | 69ドル | 74.99ドル |
推定で書いてる個所もあるので、間違いがあったらすみません。
計算帯域を考えてみる
どちらも USB3.1 Gen1 のように予想されるので、恐らく理論限界の転送性能は 5Gbps(625MByte/s) ではないかと思います。一応 USB3 以降は全二重通信なので、往復路のそれぞれで 5Gbps が期待できるのかと思います(もっとも、実際の実行帯域としては半分ぐらいでは無いかとは思いますが、理論値で計算します)。
この時、理論限界の帯域が出たとしても INT8 一個の転送の間に 5GHz のプロセッサだとの 8サイクル分の計算が出来る事になります。昨今のマルチコアでSIMD命令も持っているCPUだと8サイクルに 100 OPS ぐらい計算してしまいかねず、これより十分多い量の演算をしないとペイしないことになります。
アクセラレータはどちらも 4TOPS という事なので、恐らく 1秒当たり 2T 回の積和演算ができる計算かと思います。これは 625MByte/s に対して1Byte(INT8)に 6,400 OPS の計算、積和だと 3,200 回適用できることになります。ひとまずこの段階で計算量的にはペイしそうです。
一旦シンプルに1層で100x100 ぐらいの DenseAffine を計算することにすると、1データあたり 1層で100回の積和となるので、32層ぐらいの深さのネットがバランスが取れた規模となるのかと思います。
もちろんこれが CNN や Transformer とかネットのアーキテクチャが変わってくるとまた変わってくると思いますが、大雑把な規模感としてそんな感じかなと思います。
もちろんこれは、パラメータは事前に転送済みの前提で、パラメータの入れ替えも並行して行うとパラメータ転送帯域が律速することが用意に想像できます。
先の 100x100 Dense Affine の例だと、パラメータは 10,000個 ですので、データ100個に対して、都度都度これを再転送していたらデータ転送の100倍以上の帯域をパラメータ転送で消費してしまいかねません。これは LLM などの大パラメータのネットを使おうとすると凄まじく巨大なメモリを持っていない限り成り立たないことになる気がします。
電力を考えてみる
USB3.0 では標準で 4.5W の給電が可能なようです。現時点で 2W 程度使っているようですのでマージン考えると割とすでに現実的な数字です。
今後、半導体プロセスの微細化が続て電力効率の増加は期待できるとは思いますが、以前のように指数関数的な性能向上は望めなくなってきているので、「USB電力で駆動できる範囲」での伸びしろはそれほど多くないのかもしれません。
電源アダプタなどで補助電源を繋ぐ手もあるかもしれませんが、そこまでするなら転送帯域も含めて PCIe のカードにした方が良いような気もします。
なんとなくまとめ
纏めようのない流れになってしまったのですが、感覚的に、これらの既存USBアクセラレータは、現在のデバイスやインターフェース規格の上でかなりバランスよく完成してしまっており、デバイスやインターフェース規格にブレークスルーが起こらないと大きな進展が起こらないのではないかという気もし始めました。
なかなか興味深いデバイスだったので今後の発展に期待したいところだったのですが、ある程度収まるところに収まっている印象です。
おまけの駄文
今回の記事を書いていてふと思いだしたのですが USB2.0 時代に EZ-FPGA というものがありました。
USB3.0 版で同じぐらい安くてお気軽な FPGA ボードがあるといろいろ遊べるのになと、ふと思ってみた次第です。 どこかにいいものないかなぁ?
参考にしたURLのメモ
- https://www.intel.com/content/dam/support/us/en/documents/boardsandkits/neural-compute-sticks/NCS2_Product-Brief-English.pdf
- https://www.taxan.co.jp/jp/information/products_topics/pdf/ncs2_brochure.pdf
- https://community.intel.com/t5/Intel-Distribution-of-OpenVINO/How-many-Flops-of-NCS2/m-p/1223152
- https://community.intel.com/t5/Intel-Distribution-of-OpenVINO/How-much-memory-is-available-in-NCS-2-how-large-model-can-fit/m-p/1143053
- https://www.qnap.com/ja-jp/product/mustang-v100
- https://coral.ai/docs/accelerator/datasheet/
はじめに
今更と言うところはあるのですが、FPGAプログラミングを知らない人に説明する機会も増えてきたので少し記事にしておきます。
FPGA とは
昔電子工作したときに撮影した写真が出てきたので張っておきますが、いわゆるこんなやつです。

こんなやつです
タイプはいろいろあって、小さいものから大きなものまで。写真のように裏にI/Oピンなどの端子が並んでいるBGAタイプのものもあれば、周りにピンが生えているQFPタイプなどいろいろありますが、まあ見た目はCPUなどと同じで、中に入っている半導体シリコンがパッケージに収まっています。
とはいえ実際に使う時は、例えば私なんかは下記などをよく使うわけですが、パソコンのCPU同様に、冷却機構に隠れて直接は見えなかったりすることもあります(剝き出しで使う事も多いですが)。なのでとにかく電気的が端子がいっぱい出ているものという事だけ知っておいてください。
なぜこんな話をしているかと言うと、CPU/GPUのプログラミングと違ってFPGAプログラミングではデバイスから生えているピンを気にしないといけないからです。
普通に組み込みソフト書いている方はもちろん、Raspberry PI や Arduino や M5Stack などなど、今では親しみやすい IoT デバイスも多いので、そういうものに触れておられる方には I/Oピンと言われるとピンとくるのではないかと思います。
プログラミングで扱う範囲
さてここで、ソフトウェアプログラマがプログラミングで扱う範囲の話をします。
パソコンなどの場合
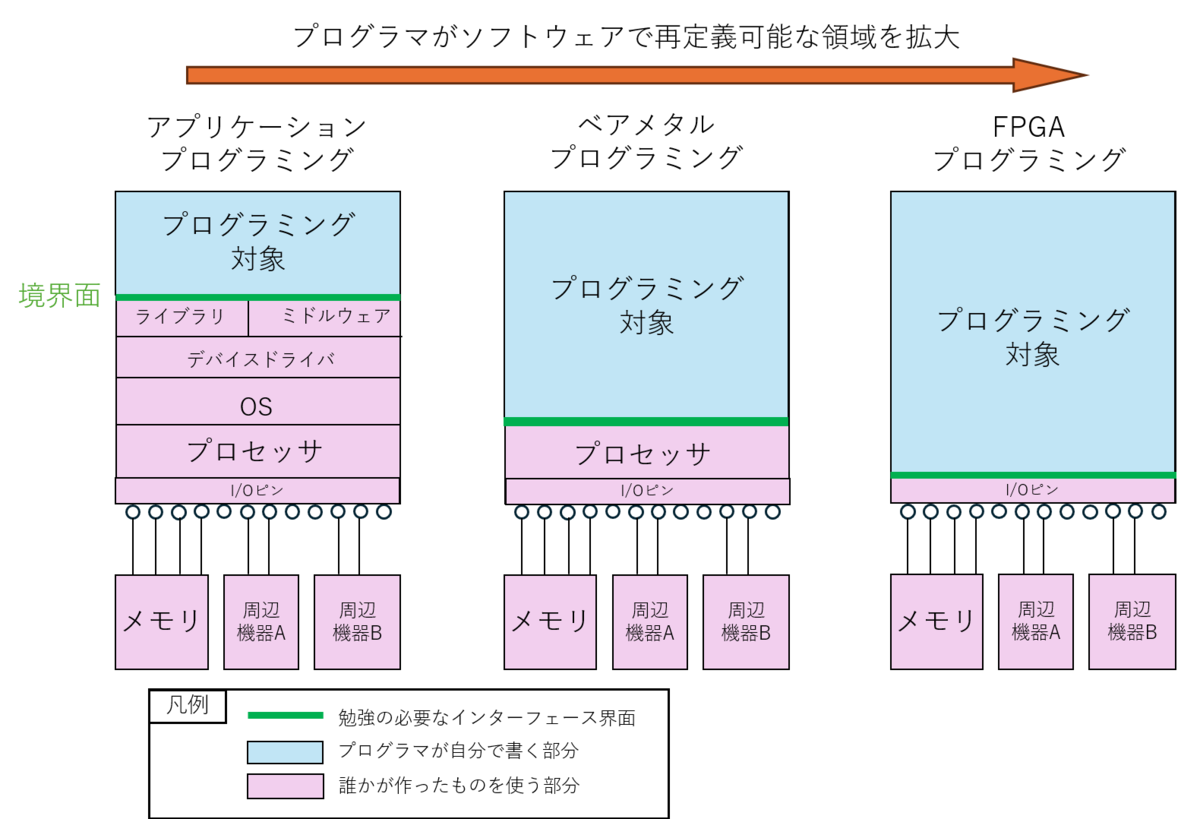
プログラミングできる範囲
例えば、Python で何かアプリを書いてみようとなったとき、プログラミング言語はもちろん、例えば Flask や Django などのWebフレームワークであったり、PyTorch や numpy や matplotlib や scipy などのライブラリであったり、いろんなものを勉強しながらプログラミングされるかと思います。
この時、勉強するのが、自分が今から作ろうとする部分と、既に世の中にあり使おうとしているものの境界面のインターフェース仕様ではないかと思います。
これは既にある大変便利な機能の恩恵に預かれる半面、誰かが用意してくれた環境の中で出来る事以上の事ができない という事になりますので、誰もやった事の無い新しい事を研究開発したい とか 今の仕様じゃやりたいことがやれない とか、不都合が出るケースもあります。
組み込みマイコンの場合
これが例えば、ベアメタルのプログラミングになるとこれまたやれることが大きく変わってきます。特殊なスケジューリングをするOSのようなものを自作する事もできますし、割り込みを禁止して全力でADCの値をポーリングする処理を書いてみたり、部分的にキャッシュを無効にして処理するなどもできますし、お作法を無視したアグレッシブな実験がいろいろできます。
また、外部I/Oの制御を自分でプログラムする事も多いです、ちなみに手元にあった RaspberryPI が下記です。

RaspberryPI
RaspberryPI でマイコンの一部の端子が基板上のピンヘッダに引き出されています。これらのピンはピンごとに役割が決まっており GPIO や SPI や I2C などなど、それぞれのマイコンのハードウェア仕様で許されている範囲でプログラムから設定したり制御したりできます。
一方でこの際には、既存のOSやドライバは何も助けてくれませんので、マイコン上のプロセッサの仕様や外部デバイスの仕様を勉強することになります。プロセッサがどのように命令を実行してくれるのか、使うマイコンはどのような機能を内蔵していて、どこに何が繋がっているのか、よく理解した上で「0xFFFF0100 番地に1を書けばピンヘッダに繋いでいる外部スイッチがONになってモーターが回り始めるはずだ」と言ったプログラミングすることになります(番地は適当です)。
いずれにせよ、プログラマが勉強すべき、インターフェース仕様の界面(図の緑の位置)が変わることがとても重要なファクターだと思っております。
FPGAの場合
そして、FPGA プログラミングはここで、さらに、従来はプロセッサがやっていた部分まで、ソフトウェアプログラマが自由にプログラミングできる世界となります。
もっともCPUの上で動かすことを前提に作られているプログラミング言語は使えなくなるので、SystemVerilog や VHDL など、CPU自体をプログラミングする事すらできるさらにRTL(register transfer level)と呼ばれるようなレベルの言語にも触れていく事になります。
ここで先ほどの I/O の話に繋がるわけですが、FPGA はプログラミングはかなり I/Oピンに近いところまでソフトウェアプログラムの手の内に委ねられます。
FPGAの外部のピンがどういう動きをするか自体をプログラミングする ことが出来てしまうのでかなり何でもできます。
一応、
- 電源やGNDなどのピンは決まっている
- 電圧はI/Oバンクと呼ばれるグループ単位で供給される
- クロックは決まったピンにしか入れられない
- 高速シリアルや SDRAMなどピンが決まっているものもある
など、LSIの仕様で決まっている縛りもあります。
逆に言うと、FPGA で理解すべきインターフェースの界面はこれらのハードウェアデバイスであらかじめ決められた縛りなどであり、これらを駆使して思い通りにプログラマが外部仕様を決めていく事になります。
そして、いわゆるプロセッサが存在しない FPGA ではどのような方式で計算を進めるかの定義自体をソフトウェアプログラマが決めることが出来ます。FPGAのなかにソフトウェアでCPUを作り出すことも出来れば、全く新しい計算アーキテクチャをプログラムすることも出来ます。
FPGAでどんなプログラムが出来るのか?
FPGA の内部構造がどうなっていて、どうして自由にロジックがプログラムできるのかは、検索すればいろいろ出てくると思いますので、ここでは詳しくは触れませんが、どういう時にCPU/GPUを使わずにわざわざプログラマブルロジックを使うと嬉しいのかを少し紹介してみます。
面白い外部インターフェースを作る
インターフェースを自由に弄れるという事は例えばパソコンでは出来ない下記のよう事がいろいろ思いつきます
- 数ナノ秒ずつ位相をずらした信号を出力して特殊計測する
- エンコーダの値をマイクロ秒単位でフィードバックしてモーターの精密制御をする
- イメージセンサの露光制御と照明制御を同期させて特殊撮影を行う
- 全部のピンを通信用にして巨大ネットワークスイッチを作る
などなどいくらでも思いつけそうです。
面白い計算をする
こちらも、char, short, int, float, double などの決まった型の計算機しか持たない CPU などと比べて
- 特殊なサイズの型を定義して演算する
- 四則演算とは違う不思議な演算子を定義して計算を行う
- 論理演算のような小さな演算を数十万並列で実行する
- ものすごく長いパイプラインでバケツリレー的演算をする
- 宛先付きのデータが流れながら演算が行われていく
などなど、これもまた、決まった型の決まった演算以外の事をやろうとすると CPU は極端に性能が落ちる事がありますので、FPGAが役立つケースが多々あります。
どこから手を付けるべきか
それでは実際問題どこから FPGA に手を付けていけばいいのかという話ですが、SystemVerilog や VHDL など、これらを記述する言語の勉強は確かに必要にはなるのですが、
- LEDチカチカから始めてみる
- UART とかを作ってみる
- CPU を作るようなことを考える
などと、手の届くところから始めるのも良い気がします。
過去記事紹介
手前味噌ですが、自分の過去記事とかを幾つかリンクしておきます。
おわりに
CPUやGPUなど既存のプロセッサを使いこなすというのはもちろん非常に価値のある事ですが、世の中の常識から外れた新しい事を試そうとすると、実はFPGAはすごく強い味方になります。
また今の FPGA は、マイコンのように、「プログラムを修正しては、ビルドし直して再実行」というのが比較的簡単に行えますので、基本的にソフトウェア実行媒体として扱う事ができます。
確かに難易度は高く、取っつきにくいという話はよく聞くのですが、あなたのプログラミングの範囲を広げる という観点で、興味を持って頂けると嬉しいなと思った次第です。
最後に少し興味深いブログにリンクを張って終わりにしておきます。
はじめに
先般 MN-Ccore Challenge なるものが開催され、私もスキマ時間に気分転換的にちょこちょこ挑戦していたのですが(本業関係者への言い訳)、とても面白いアーキテクチャだなと思いました(順位はまあその力及ばず微妙な感じでしたが)。
普段 FPGAプログラミングが多い私ですが、いろいろ新しい観点で脳に刺激を頂きました。
今更私なんかが考察する余地もない気はしますが、折角なのでプログラミングではなく、プロセッサアーキの方を少しだけ感想程度に記録しておければと思います。
いろいろ資料も公式に公開されていますし、コンテストも終わったようなので(実は終了日を勘違いしていました)、安心してあれこれと自分用の勉強の教材にして楽しませて頂きたいなと思います。
なお、ほんとに素人考察なので、あんまりマサカリは投げないでおいてあげてください(言い訳)。
どんな構成なのか
最初に「ソフトウェア開発者マニュアル(SDM)」を読んでみて、書き起こしたのが下記の図です。

SDMを読んで最初に書いた図
私が適当に書いたので間違ってるかもしれませんが、とりあえず、階層構造というか、ピラミッド構造というか、そういう風になっているようです。階層ごとにメモリがあり上下の階層に対していろいろな転送(場合によっては縮約演算も)がPEの演算と並行して指示出来るようです。
このとき同じく階層構造をもつものとしてとして思い出したのが PEZY Computing さんの PEZY-SC2 などの資料で見た構造です。
一方で、最近の AI系のコアだと、Versal の AI コアでもある AMD の XDNAであったり、 Tenstorrent の Whormhole / Blackhole であったり フラットな二次元メッシュ構造をよく見るような気がするので、それぞれにどういうメリットデメリットがあるのかは興味深いところです。
MN-Core はというべきか、 MN-Core もと言うべきか、キャッシュメモリが存在しないアーキテクチャなので、階層間での明示的データ転送が一つの大きな肝になってくるのでは無いかと思いました。
階層があるかどうかで、お隣さんなど他のノードとの距離とデータ交換コストの重みに違いがあるわけなので、このあたりの向き不向きが適用するアプリによってありそうな気がしなくもありません。
レジスタファイルではなくメモリ
次に肝心な計算ユニットであるPEですが、公式の図に私が勝手に赤字で落書きさせて頂いたのが下記ですが、なんとプロセッサなのにいわゆるレジスタファイル(汎用レジスタ)がなさそうです。シングルポートのメモリや、書き込み専用と読み込み専用のデュアルポートになっているメモリなど、比較的シンプルなメモリが演算器にそのまま繋がっています(つまり普通のCPUだとL1キャッシュに相当するメモリ階層がダイレクトに演算器に繋がっているとも解釈できそうです)。

レジスタファイルではなくメモリ
これはFPGAプログラマ的には凄くいいなと思いました。以前こんな記事 やこんな記事を書きましたが、FPGAの大敵である大量ポートのレジスタファイルなどは不要で、FPGAにあるBlockRAM でも同じような構成は低コストで再現できそうです。おそらくLSIにおいてもトランジスタ効率の良い実装なのでは無いでしょうか?
ではなぜこんなことが出来るのかと考えてみると、4サイクルを1ステップとする命令体系 にあるような気がします。普通は1つの命令で4データ処理すると言われると、4並列のSIMDを想像してしまいますが、MN-Core では1命令を4サイクルで実行します。
以前私がバレルプロセッサを作った際にこんな記事を書きましたが、同じように依存関係のないデータが並んでいれば、ハザードを起こさずにパイプラインを深くすることが出来るはずです(SIMDで並列実行できるようなデータ同士には演算順序の依存関係はないので)。そうすると多少レイテンシのかかるメモリや演算器であっても汎用レジスタのように利用可能になってくるようです。
プログラマがSIMD命令に慣れている ことを逆手にとって、**SIMDっぽい命令体系を直列実行してパイプラインハザードを回避している** と捉えるとすごく面白い気がします(注:個人の感想です)。
また、4サイクルで1ステップと言いつつ、アドレスだけは4サイクル分個別に投入できる命令体系です。これはもう命令ストリームではなく、アドレスストリームとも言えるのでは無いでしょうか?FPGAプログラミングでいろんなところでSRAMへのアドレスジェネレータが重要になることがあるので、感覚的にはアドレスだけ命令密度が高いのもしっくりくるところがあったりもします。 まとまった単位で扱わないと性能の出ないDRAMに比べて、ランダムアクセスが得意なのがSRAMなので、ローカルSRAMにデータを持ってきた後はそこをフルランダムアクセスしてプログラムから使えるのはある意味でデバイス特性をフルに引き出していると言えるのかもしれません。
対して ALUなどの演算種別の切り替えは 4サイクルに一回で十分 という割り切りも、毎サイクルどころか1サイクルに異種の命令を何個も並列発行する現在のアオウトオブオーダーのスーパースカラプロセッサに隠れた無駄を指摘しているアンチテーゼにも思えます。
B/F(Byte per FLOP)など帯域の観点でも、ALUやMAUに対するL1メモリのデータ供給能力は十二分に見えます。ここも L1メモリ(通常はキャッシュ)からの帯域をレジスタファイルで補っている一般的なアウトオブオーダーのスーパースカラプロセッサと大きく違うところだと感じました。
乗算器について
特にAIなどで重要になる演算のうちトランジスタリソース消費の多いのが乗算と思われますが、MN-Core では ALU や 縮約転送 に乗算は無いようですので、基本的にハードマクロ乗算器は MAU に集まっていることになるようです。そして 倍精度、単精度、疑似単精度、半精度 をそれぞれ小さくなるほど一度に大量に演算できる仕組みがうまく構築できているように感じました。B/F の関係で大量の演算ほどメモリ帯域が必要となるため、半精度のみ2長語転送ができたりして、ここがコンテストで高得点を出す肝の1つにもなったりもしていたようでした。 (乗算は精度倍にするのにリソース2倍以上消費してしまうので、帯域と精度のバランス調整が難しそうですが、とてもうまく収まってるようです)
何れにせよ非常に柔軟に構成変更できる乗算器が、フォワーディング($mauf)すれば次の演算に使えているのでレイテンシ4サイクルで計算できているわけで、さすがと言ったところです(FPGAだとこうはいかない)。またこの柔軟性のおかげで倍精度の必要な Top500/Green500 でも高い評価を出しつつ、半精度で十分なケースもあるAIにも柔軟に対応できているのかなと思います。
ちなみに行列演算を見てみると、1命令でMAU 1つにつき倍精度だと 32MAC、単精度で128MAC、疑似単精度で 256MAC、半精度で 1024MAC となるようです。 AVX-2 などの SIMD だと、倍精度を単精度にしても2倍にしかなりませんが、ちゃんとデータ幅が半分になる毎に 4 倍、16倍と乗算器トランジスタリソースのオーダーで演算量が増えています。 これは、「倍精度の時は2つの命令に分けて演算する(dmmulu+dmfmad)」、「半精度の時は2長語転送ができる」などの工夫で成立しているようです。
ちなみに一番小さい乗算である半精度で仮数部9bit ですので、最低でも INT8 以上の精度を持つ事になり、FPGA などが得意とする、INT8以下に強く量子化されたネットワーク(極論するとバイナリネットワーク)のようなものの推論に関しては(学習は別)スコープ外なのかと思いますので、FPGAも住み分けて生き残れそうでちょっと安心したりもしました。
どこをプログラミングしているのか?
通常のCPUであれば 「ALU に何をさせるか」をプログラミングさせるかと思います。一方で、MN-Core ではどうやら、ニモニックこそそれっぽく見せかけているものの(人に優しい)、その実体(機械語)はマルチプレクサのスイッチをプログラムする仕組みになっているようです。なのでALUなどの出力を一度に複数の種類のメモリに書き込んだり出来てしまいます。

マルチプレクサの切り替えをプログラム
そしてこれらは決して巨大マルチプレクサではなく、一個一個はそれこそFPGAに持ってきても許容できる程度のコンパクトなものになっています(注:FPGAはマルチプレクサ苦手なものが多いです)。そしてこれらもまた4サイクルに一回切り替えられれば十分という、従来の固定観念を見直させてくれるなかなか興味深い構成となっているように思いました。
マルチプレクサの切り替えは データ経路のプログラミング に他ならないので、その点はHailoとか、ルネサスさんのDRPなどに通じる部分もひょっとするとあるのかもしれません。
FPGAプログラミングとの違い
それでもやはり汎用計算機の宿命なのかなと思ったのが、PE内で ALU なり MAU なりで演算されたデータはまた元のところに戻ってきてぐるぐる回りながら演算する構成であるところでしょうか。フォワーディングレジスタのおかげでかなり面白いデータ流が作れそうですが、やはりサイクル内ではMABに閉じた流れにはなりそうに思いました。
私が画像処理の経験が多かったせいかもしれませんが、FPGAプログラミングではALUのような多目的な演算器ではなく固定の演算を並べて配置する事が多いので、データはある演算器で計算したら次の演算器に渡されるといった、パイプラインを構成する事が多いように思います。もちろんそれはFPGAはASIC化されてないFPGAのままだから出来るプログラミングではあるのですが、やはり少し毛色の違いは感じてしまいました。
AVX-262144 というネタも飛び出しておりましたが、全部のPEが同時に全部同じことをする という並列プログラミングの宿命なのかもしれません(それで FizzBuzz も解けてしまうのだから驚きなのですが)。
おわりに
「LSI上に存在するトランジスタリソースを如何に高密度に演算に割り当てるか?」という問題と「如何に汎用性を持たせるか?」という2つの相反する問題に、それぞれ何らかの尺度の中で限界まで挑んでいるのが昨今のプロセッサかと思います。
そんな中でかなり演算性能に重みを振って理論限界に迫っているプロセッサの一つが MN-Core なのかとは思います。限界に近づくほどにいろんな特徴が見えくるのは感じました。
FPGA大好き人間の私にも、随所で参考になりそうなものはいろいろありましたので、今後のFPGAプログラミングの参考にさせて頂きたいなと思った次第です。
余談ですが、きっとPFNさんの中では試作段階でFPGAでの評価とかもされてるのではないかと想像しますが、FPGAにも優しい設計になっていそうな気はしました。
あと、今回のチャレンジで上位スコアを取るような方々が特定の問題を解くためのFPGAプログラミングなんかしたらとんでもなく凄いコードが出てくるんだろうなと、凄い人たちの凄さを改めて体感した次第でした。
(追記:コンテストでは私はあまり触らなかったので理解できてないのがメモリ帯域や容量配置などなのバランスなのですが、機会があればそれらも調べて身みたい気がします。)
追記
本ブログ記事、牧野先生ご本人から X で取り上げて頂いておりました。感謝申し上げます。 下記に連なる書き込みで、コンパイラの最適化を容易にするための意図であったり、2004年の論文のご紹介などを頂いており、大変勉強になりました。 🙇♂️
会議資料から逃避中なので https://t.co/33YevIWyaq MN-Coreを素人考察してみるを。いや素人じゃないよねというか基本的にそうですみたいな。
— Jun Makino (@jun_makino) 2024年9月25日
さらに追記
なんと、30位だったにも関わらず、抽選で Par賞 を頂きました!! 有難うございます! 最後の Inversion がインチキ解法だったのでちょっと心苦しいのですが、ここは有難くPCのメモリ増設に充てさせていただきます。
はじめに
FPGAなどでデータ処理をする場合、その並列性を活かして高性能な処理をするという事はしばし求められることです。
その際にしばし使われるデータ並列とパイプライン並列を整理しておきたいと思います。
データ並列と言うと、AVX-2 のような SIMD(Single Instruction Multiple Data) や GPGPU のような SIMT(Single Instruction Multiple Threads) などでお馴染みかと思います。
一方でパイプライン並列は Verilog など RTL言語で FPGA等を開発する方々と違い、C言語などでプログラミングする方々にはあまりなじみが無い可能性もあるかと思います。
そこで少し具体例を元にこれらを見直してみたいと思います。
少し具体的な例を考えてみる
本当にこんな処理を行う事があるかどうかは一旦置いておいて、画像データに対して
- 処理1 : 逆γ補正を行いリニアな量に戻す (リニアワークフロー)
- 処理2 : 黒レベル補正(オフセット減算)
- 処理3 : ゲインアップ(ゲインを乗算)
- 処理4 : 上限クリップ(1.0以上をクリップ)
- 処理5 : 下限クリップ(0.0以下をクリップ)
- 処理6 : γ補正(ディスプレイの特性に戻す)
というような処理をすべてのピクセルに対して行う事を考えてみて、簡単の為にどの処理も1サイクルで完了するという事にします。
この処理を FPGA で実装すると恐らく下記のような演算器を並べたブロック図の構成になるのではないかと思います。

FPGAのデータ処理例
時間軸で見ると下記のような感じです。

パイプライン処理の例
まず、同じ演算を横並びにする「データ並列」について考えます。 入力データは、メモリに格納されていたり、イメージセンサから直接取り出されたりします。またどうように計算結果もメモリに書き込まれたり、あるいは直接ディスプレイに送られたりします。
ここではデータの並列幅について考えることになります。入力元は例えば DDR4-SDRAM であれば 64bit幅で 2400MHz であったりとかで並列に複数ピクセル分のデータが供給されます。またイメージセンサから直接入力する場合も、昨今のものは高速シリアルが並列に何レーンもありますので、こちらもやはり1サイクルに複数のピクセルが並列にやってくるものは増えています。 逆に言うと、この時に データ帯域幅以上のデータ並列を行う意味は FPGA にはありません。 それ以上のデータ並列があっても演算器が遊んでしまうだけです。
次に、「パイプライン並列」について考えます。こちらは 行いたい演算のアルゴリズム で計算の深さが決まります。そしてまた演算の深さ以上の回路リソースは活かされることはありません。
この時点で、データ入出力の帯域とアルゴリズムで、最大能力が決まり、それ以上のFPGAの演算能力は持て余すだけとなります。同じことは CPU や GPU にも言えます。
ですのでデータ帯域当たりにより多くの処理を行おうとすると、より一回のメモリアクセスで深い演算を行えるアルゴリズムを考えるということが重要になります。いわゆる B/F の話であり、多くの科学計算でより性能の出るアルゴリズムの工夫が行われているわけです。
この時、データ並列もパイプライン並列もどちらも明示的に扱える FPGA はいろいろと有利さもあるのではないかと考えていたりもします。
例えば筆者の LUT-Network での画像認識などはFPGAを活用した非常に深いパイプラインの例かと思います。

筆者の LUT-Network のパイプラインの例
筆者はしばしこの手の回路をイメージセンサからの入力やディスプレイ出力に直結し、外部メモリを使わないようなことをよくやりますが、メモリほどのデータ帯域の無いイメージセンサであっても多くの演算量を効率的に適用することが出来るケースがあります。
CPU や GPU を考えてみる
CPUやGPUのSIMDやSIMT の特徴は、文法上はデータ並列しか存在せず(CPUの中ではパイプライン処理はされますが)、全てを並列に考えるのが特徴になるかと思います。
試しに CUDA で書いてみたものが下記です(動かしてはいないので間違いはあるかもですが)。
global void Kernel1(const float *src, float *dst, int stride) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y;
float x = src[y * stride + x];
x = pow(x, 2.2f);
x = x - 0.2f;
x = x * 1.5f;
x = min(x, 1.0f);
x = max(x, 0.0f);
x = pow(x, 1.0f / 2.2f);
dst[y * stride + x] = x;}
これは、1ピクセルごとに1スレッドを割り当てるパターンです。CUDAではこれが 32スレッド集まった WARP という単位でまとめて実行される SIMT の構成を取ります。
この場合プログラム上は画像のピクセル数だけの並列記述となるので、データの帯域よりも並列演算器の並列度が大きい という事が起こります。 ではこのとき実行はどうなっているかを想像すると、恐らく下記のようになっていると、思われます。
- 多くのスレッドのうち物理的に割り当て可能な範囲で WARP にスレッドが割り当て実行が開始される
- 各スレッドはデータの読み出しを行いデータ帯域の中で最初に読み込みが終わったWARPが処理を開始する
- 以降、データが読みだされた順に次々と別のWARPが処理を開始する
- 処理の終わったWARPから順にまだ未割当のスレッドを割り当てる
- すべてのスレッドが完了するまで続ける
という、なかなか複雑な事が起こると予想しています。
下記、筆者の想像なので間違っているかもしれませんが、イメージ図です。
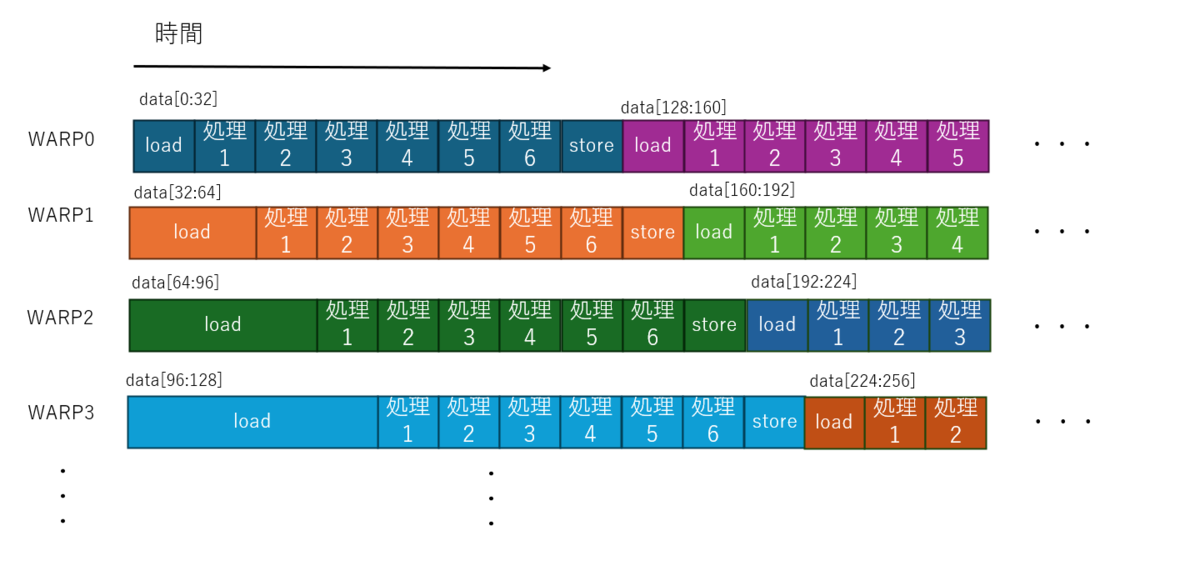
CUDA動作の想像図
本当に一斉に起動するのか? とか、load と sotre が重なってるところは片方待つのでは? とか、キャッシュの挙動は? とかいろいろ気になる複雑な話はいっぱいあるわけですが、細かいところを無視して想像するとこんな感じではないかと思います。
結果論から言うと、一応はデータ供給幅に応じた単位でパイプライン並列的な動きにはなるのかとは思います。
しかしながらこれらを明示的に行っている FPGA に比べて、複雑度が高いのは間違いないかと思います。また、CPU/GPUは基本的にはロードストアアーキテクチャであり、メモリからメモリへしか計算できないという特徴がありますのでしばしメモリ帯域へのコスト要件も高くなりがちです。
メリットとしては
- データ並列しか意識しなくてもある程度自動的にパイプライン並列にもなる
- 一つのコードを書いておけば、メモリ帯域やコア数の違ういろんなGPUで同じコードが実行できる
と言ったところが予想され、逆にデメリットを列挙すると
- 各コアが持つ何でも出来る演算器が毎サイクル1種の演算しかしない
- 演算が浅く、コア数 > バス帯域 となると多くのコアが load 待ちでストールする
- メモリ帯域やキャッシュなどにコストが転嫁されがち
- 一度メモリに入れないと計算できない
- リアルタイム保証もやりにくい
などではないかと思います。
おわりに
結局のところアルゴリズムとマッピング先のハードウェアが決まっていると、性能限界は自ずと決まってくる気はしています。
そうなってくると、性能限界を目指して実装を頑張るよりもアルゴリズムの方をハードウェアに合わせて改修する方が面白みがありそうな気もしています。
このときにGPGPUなどをターゲットにしたアルゴリズムは多数ある反面、FPGA向けのアルゴリズム改善は人口が少ない分、比較的差別化しやすい気がしています。そういったことを考えるときに二つの軸の並列性を念頭に置いておくことが何かの役に立てば幸いです。
情報量にエントロピーという概念があります。エントロピーと言うと物理学で習うエントロピー増大の法則を思い浮かべるわけですが、そちらのエントロピーには時間が経過するとエントロピーが増大するというエントロピー増大の法則があります。
ここで、情報エントロピーのほうに話を戻して、N bit のデータのすべてが 0(もしくはすべてが1)という初期状態を考えてみます。
そして、「一定時間ごとにランダムにどれか1bit が反転する」という設定をしてみます。
そうすると、基本的に情報エントロピーにもエントロピー増大の法則的なものが現れる気はしていて、N が十分大きければ、おおよそランダムに 0 と 1 が同じ割合になるまでエントロピーはほぼ増大する方向に遷移していくと予想されます。
極稀に偶然エントロピーが減ることもあると思いますが、確率的な傾向としては概ね増大するはずで、これは物理世界でも同じだと思います。
ただし、N よりも十分大きなオーダーの時間経過があると奇跡的偶然の連続ですべての bit が 0(もしくは1) になる可能性も秘めています。
N bit という空間の状態数のスケールよりも、経過可能な時間スケールの方がオーダーが大きいとそうなるかと思います。
また、ここで我々が時間として認識しているものが、本来の時間とは異なり「エントロピーの増加」という事象を「時間の経過」としてと錯覚しているだけだと仮定し、情報エントロピーと物理的なエントロピーが同じようなものだと仮定してみます。
そうすると、N bit で表現可能な 2N 個の状態がそれぞれ遷移可能な状態と繋がったグラフとなり、その中のエントロピーが増大する方向への有向グラフとなり得ます。
そして、 観測者はエントロピーの低い状態を起点にエントロピーの高い状態へ時間が流れているように感じるという仮説を置くと、
- 時間の始点(すべてのbitが0または1の状態に相当)が存在する
- エントロピーが上がりきる(0と1が同数になる)と時間経過は終端に達する(終端は始点に比べて非常に多数存在する)
- きわめて低い確率で時間が巻き戻る(エントロピーが減る)奇跡が連発してエントロピーの低い初期状態に戻る事はありえる(ただし観測者は時間逆行は認知できない)
- 実は起こりうる事象(状態)はすべて起こり得る
- ある状態においてエントロピー増大だけで今の状態へ遷移可能な過去だけが考古学的なの過去の可能性の検証対象
- ある状態においてエントロピー増大だけで今の状態から遷移可能な未来だけが、未来予想の対象
- ある状態においてエントロピー増大方向の遷移では今の状態から過去にも未来にも通過しえない状態は所詮パラレルワールドでの妄想
というような妄想をしてみます。
まあ、「時々時間は止まってるけど認知できないから気づかない」理論とか、「世界五分前仮説」みたいな、検証も反証も出来ないカント以前の哲学というか、単なるトンデモ科学の一種だとは思ってますが、なんとなくお酒を飲みながら、エントロピーという用語で妄想してみたので書いてみました。
そして、永遠の謎、物理学における「観測者」っていったいなんなんだろう・・・
なんとなく、駄文を書いてみます。
技術者という職業を突き詰めていくと、はその技術力を売ってその対価としてお賃金を頂く職業なわけです。
ただ見渡す限り、メンバーシップ型雇用が主体のわが国では、純粋な職業技術者として人を雇っているところはそれほど多くはなくて、多くのサラリーマン技術者はスキルを売って対価を得ているという感覚は持ちにくいようになっているような気はします。
私自身も25年ほどのエンジニア人生振り返ってみて、 技術以外を求められたことも沢山ありますし、どうしても「どうしたら技術力が上がるか」ではなく「どうすればもっと組織に貢献できるか」を問われ続けてきたように思います。
そうすると、自己の組織内での価値を高めるのに、技術力を上げるという以外の選択肢を取ってきた人の方が多かったように思いますし、実際そうしないと出世して給料を上げる事が出来ない仕組みになっていました。早い話が「技術は若い者が下働き的にやるものであって、偉くなったら管理職になるのがあたりまえ」的なやつですね。
また、もう一点、技術者がスキルアップに集中できない理由として、スキルと対価が必ずしも正しく比例しない点、があるように思います。
技術力はある意味でツールであって、ダメツールを使って神器をつくる事はできなくとも、高性能ツールを使ってゴミを作る ことは出来ちゃうからです。そしてどういうわけか、何を作るかを決定する権利が無いわりに、出来上がったものがゴミである理由がツールにも転嫁されがちです。
また、スキルの値段 というのがとても難しいように思います。これはエンジニアに限った話でもなく、例えばリンゴ農家さんが、「よりおいしいリンゴ」を作る努力をした場合、「おいしくないリンゴ」より「おいしいリンゴ」の方が高くは売れますが、「おいしいりんご」自体の市場の相場はリンゴ農家さんの農業技術のコントロールの外にあるからだと思います。
「おいしいりんご」自体の市場の相場を高めるには、ブランド戦略だったり、他商品やキャラクターとのコラボだったり、新しい健康食品の開発だったり、いろんな手があるとは思いますが、そこに労力を割いた分だけ、リンゴそのものを美味しくする労力が割けなくなります。
話を技術者に戻すと、結局技術者の給料は、その技術を使った最終製品の売り上げから回ってきています。 したがって、優秀な技術者を集めてもゴミばかり作ってしまう組織だらけの国、と、優秀な技術者を集めて価値の高いものを作れる国、では、自ずと技術者のスキルに対する相場が大きく変わってきます。
身もふたもない言い方をすると、技術者の能力が同じなら、その国の技術者の平均給与は、その国にどれだけ優秀な経営がなされている組織があるか で決まってくる可能性すらあるように思えてきます。
組織自体が巨大化/硬直化してくると、経営者だけ優秀な人間連れてきてもどうにもならないケースも多々知っておりますので、優秀な経営 を生み出すのはとても難しい事かとは思っております。
一方で、技術者がもしスキルを伸ばして生きていきたいと思うなら、どの組織に属するかを常に考えて判断するのは非常に重要に思います。
私も少し前にいよいよ転職をしたわけですが、このような考えも背景にあったという事で、思い返して、少し駄文を書いてみた次第です。
はじめに
今日は、最近のプロセッサをウォッチしている中での素人の妄想を書いてみます。
プロセッサの性能と規模の法則としてポラックの法則というものがあります。
これは簡単に言うとプロセッサの性能を2倍、3倍、4倍にするには、プロセッサに適用するトランジスタの数を4倍、9倍、16倍に増やしていかないといけないというものです。半導体の微細化が進んでムーアの法則でプロセッサに使えるトランジスタ数が増えていっても、プロセッサがさほど高性能化しないことをよく表している法則に思います。
ポラックの法則はまだシングルプロセッサが周波数競争をしていた時代からあった法則ですが、現在の周波数が頭打ちして並列度を上げていくしかない状況においてもある程度理にかなった法則な気がしています。
この要因の1つにNが増えたときに対角線がNの二乗で増えていくという、安直な話が深く関連しているのではないかと考えてみました。

対角線の増え方
この話は、だいぶ前に下記の記事で Masayukis 氏に LVT Multiport RAM を教えて頂いた話とか、
半導体雑談会で HBM を教えて頂いた後に、下記などを参考に調べてみたりとか、
ありとあらゆるところで、いわゆる クロスバースイッチ が課題になっている気がしています。
スーパースカラプロセッサの並列実行
身近なパソコンでもスーパースカラ実行が行われるようになり、OoO(Out of Order) 実行できるプロセッサは今や身近にどこにでもあるものになりました。
Instructions per second - Wikipedia によると 1コアで1サイクルに並列実行できる命令数(instruction per clock per core)は 10を超えるようなものも出ているようです。
一般的に並列実行可能な実行ユニットが増えると少なくとも実行ユニットで同時実行できるだけ同時に命令デコードできないといけませんし、デコードした結果はあらゆる命令を含むのでどの実行ユニットにも命令供給できないといけません。実行ユニットもいろいろあって面倒なのでここでは全部同じALUがあるというシンプルなモデルでオーダーだけを考えてみます。 ALUはレジスタファイルから値を読みだして演算してまたレジスタファイルに書き戻します。レジスタファイルもALUの並列数が増えるとレジスタリネーミングなどを行う為にレジスタ数自体も増えますし、レジスタファイルからはも同時実行に必要な数だけレジスタファイルから読みだせないといけませんし、同時に演算した結果は一度にに書き込めないと意味がありません。そして汎用レジスタを謡う以上はALUはすべてのレジスタを演算対象に出来ないといけないのでフルクロスバスイッチになるはずです。
超テキトーな絵を書くと、下記のようにあちこちにクロスバスイッチ的なものが挿入されることになりそうに思います。
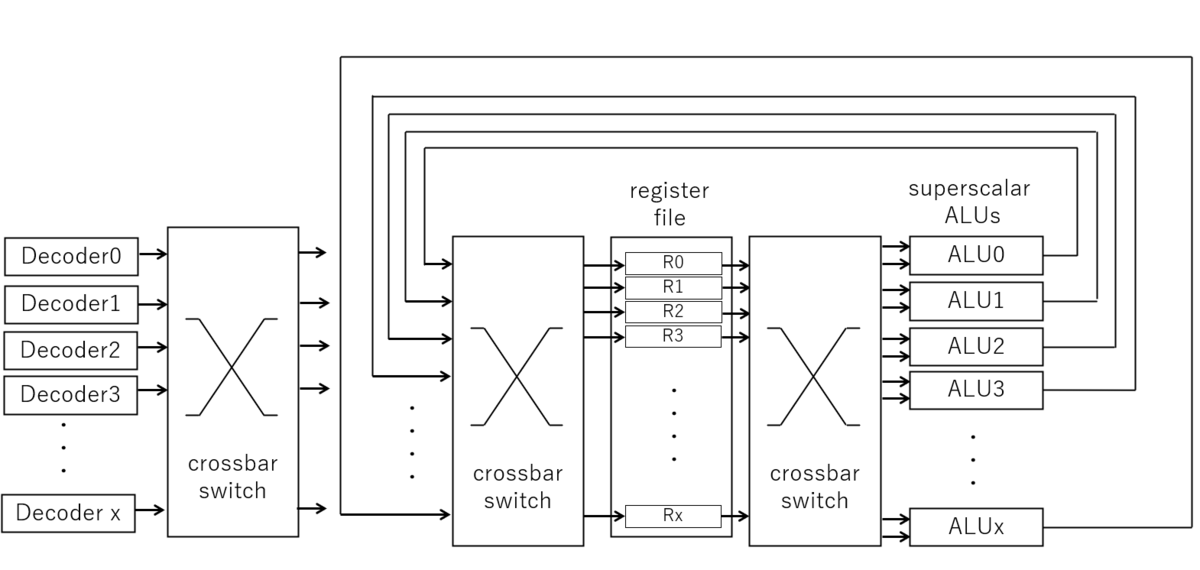
超テキトーなスーパースカラのモデル図
そして並列実行数が増えるとクロスバスイッチは目に見えて複雑になってるはずです。
レジスタ周りのクロスバスイッチはこんなことになってないか?
実際には、こんなシンプルな話ではなく、OoO を行う為にありとあらゆる機構が入っていて、ものすごい数の実行可能かの並列判定だったり、リオーダーバッファでの並び替えであったり、リネーミングを引くためのCAM(Content Addressable Memory)であったり、いろいろあるんだと想像されます。
Cardyak 氏のポストを勝手ながら引用させて頂くと、昨今のプロセッサは凄いことになっているようです。
— Cardyak (@Cardyak) 2024年6月1日
メモリもすごいことに
HBM については、雑談会で教えてもらうまで知らなかったのですが、DDR4-SDRAM みたいなものが 8並列とかそんな感じに入っているものなのですね(DDR5-SDRAMも既にDDR4-SDRAMが2並列に入っているような構造のようですが)。
AMD-Xilinx の Versal の HBM 周りをPG313から引用させてもらうと、下記のような NoC と switch のお化けのようです。

Versal の HBM のアクセス機構
CPUやGPUではさらに HBM が 4 つとか 6つとかついていますので、例えば HBM が 4 つに、コアが32個あるような CPU だと、32x32 の対応関係を作らないと行けなくなります。
ここで全部をクロスバスイッチではなく、NoC などと組み合わせる Versal のようなアプローチは個人的には正解に思います。 フル接続のクロスバーは NxN のリソースを消費するのに、同時接続数は N しかないのでトランジスタの稼働率としてはクロスバスイッチはとてももったいなく思えるからです(ダークシリコンの問題もあるのでちょうどいいという可能性もありますが)。
一方で、先に述べたプロセッサの中のレジスタファイルの前後なんかはそんなことは難しい気はするので、これはこれでそのうち破綻するんじゃないかと心配してみたりもします。
こちらにある HBM 12個なんか、12x8 で 96並列のメモリになるわけですが、中はどうなっているのでしょうね?
おわりに
ムーアの法則もいつまで続くのかわかりませんが(もう終わった説もありますが)、とにもかくにも半導体のプロセス進化は今も進んでいます。 プロセッサの効率を考えたときに、一個のプロセッサを高速化する話も、マルチコアとマルチメモリで並列化する話も、どちらも 対角線的な接続 が今後ますます強いボトルネックになっていく気がしています。
FPGAしか知らない筆者ですが、FPGAでやるとマルチプレクサだらけになる世界しか想像できないので、ASICでもFPGAほどではないにせよオーダーとしてはやはり二乗のオーダーでインパクトがあるのではないかと想像しています。
ソフトウェアのアルゴリズムではよく O記法で O(N2)などと演算オーダーを表しますが、最高次数以外を無視します。なぜなら N が大きくなるとそれ以外は微々たるものになるからです。
結局のところ、疎結合を許容しない限りこのオーダーは変わらないわけで、いずれまた 汎用レジスタより専用レジスタ、UMA より NUMA、スーパースカラよりシンプルなMIMD、OpenMP より MPI などのようになっていく日が来そうな気がしなくもないな、など素人の戯言を述べたところで、今日の妄想を締めたいと思います。