Spider 2.0 (original) (raw)
About Spider 2.0
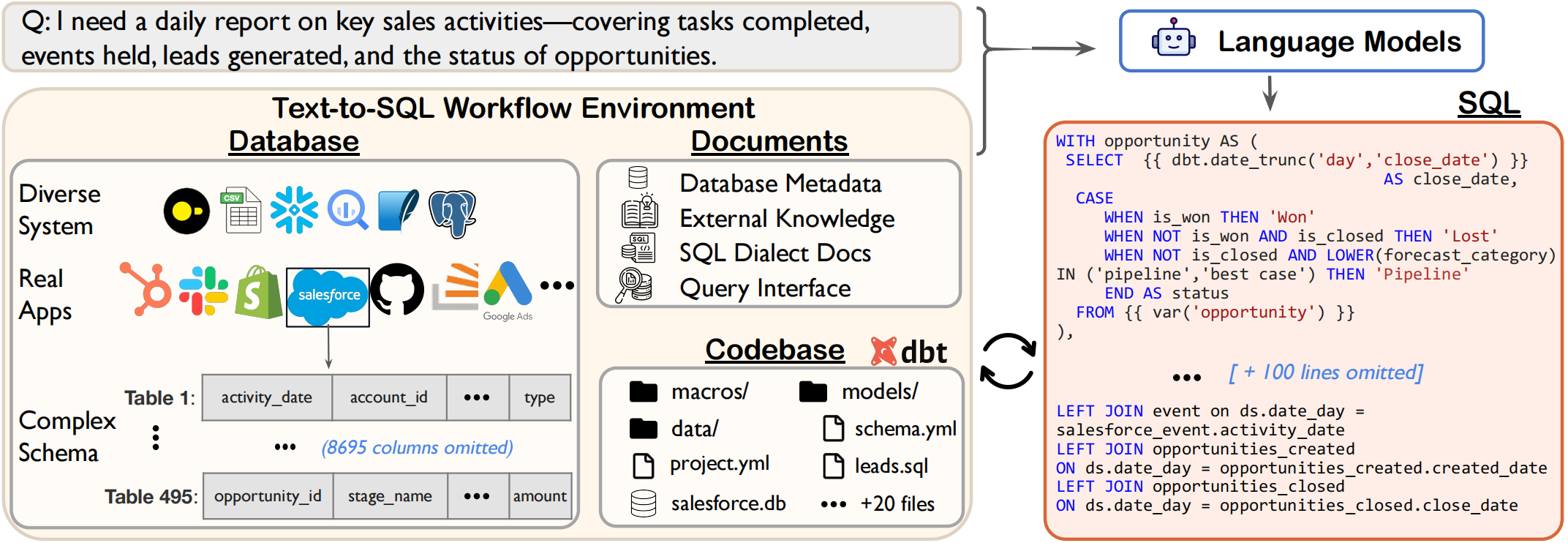
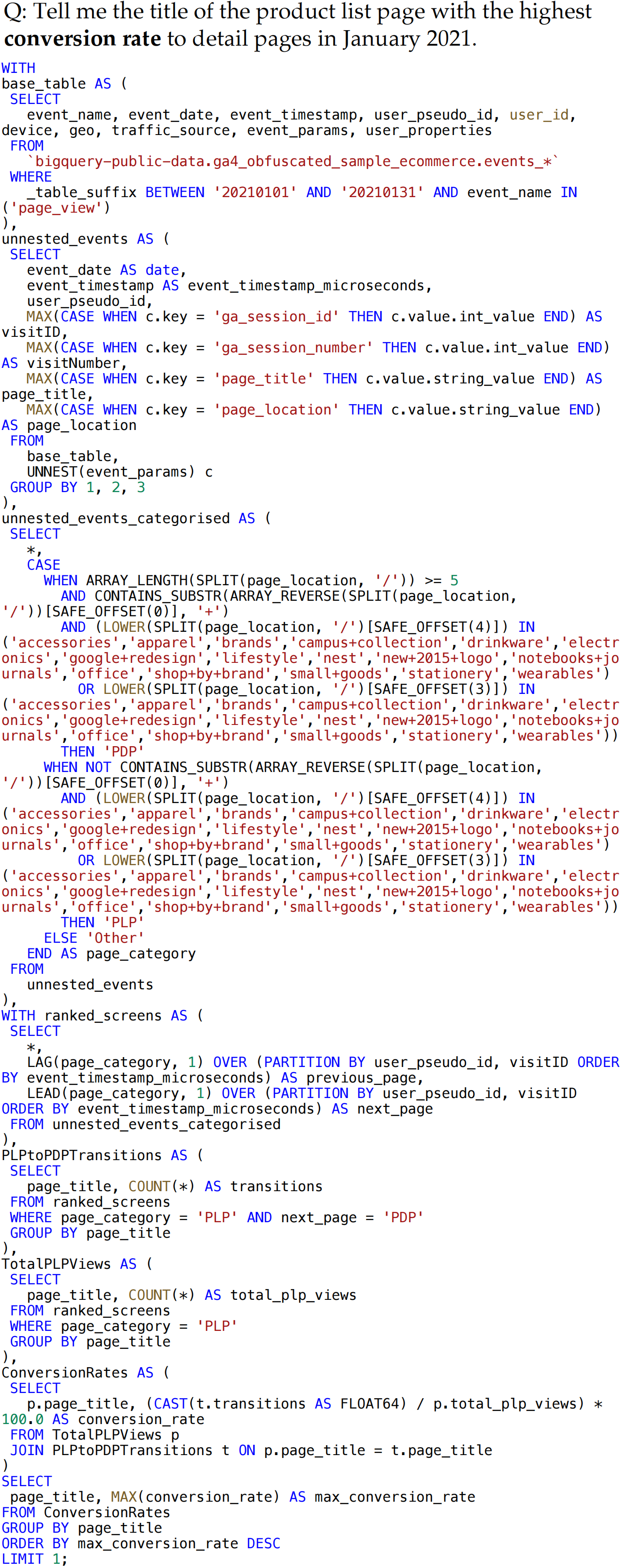
Spider 2.0 is an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges.
News
Milestone
As of now, all methods combined can solve 66.91% (366/547) of the examples in Spider 2.0!
Why Spider 2.0?
In 2018, we introduced Spider 1.0 , SParC, and CoSQL as part of the Yale Semantic Parsing and Text-to-SQL Challenge Series, attracting over 300 submissions from leading research labs worldwide.
Now, in the era of Large Language Models (LLMs), we present Spider 2.0 to advance code generation, particularly text-to-SQL capabilities.
This new benchmark offers a more realistic and challenging test of LLMs' performance on complex enterprise-level text-to-SQL workflows, involving complex data environments (e.g., >3000 columns), multiple SQL dialects (e.g., BigQuery, Snowflake), and diverse operations (e.g., transformation, analytics).
Notably, even the advanced LLMs-o1-preview solve only 17.1% of Spider 2.0 tasks. For widely-used models like GPT-4o, the success rate is only 10.1% on Spider 2.0 tasks, compared to 86.6% on Spider 1.0, underscoring the substantial challenges posed by Spider 2.0.
| Setting | Task Type | #Examples | Databases | Cost |
|---|---|---|---|---|
| Spider 2.0-Snow | Text-to-SQL task | 547 | Snowflake(547) | NO COST!😊 |
| Spider 2.0-Lite | Text-to-SQL task | 547 | BigQuery(214), Snowflake(198), SQLite(135) | Some cost incurred |
| Spider 2.0-DBT | Code agent task | 68 | DuckDB (DBT)(68) | NO COST!😊 |
Acknowledgement
We thank Snowflake for their generous support in hosting the Spider 2.0 Challenge. We also thank Minghang Deng, Tianbao Xie, Yiheng Xu, Fan Zhou, Yuting Lan, Per Jacobsson, Yiming Huang, Canwen Xu, Zhewei Yao, and Binyuan Hui for their helpful feedback on this work. The website and submission guidelines are greatly inspired by BIRD-SQL, and we thank them for their contributions.

Data Examples
Have Questions?
Citation
@article{lei2024spider, title={Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows}, author={Lei, Fangyu and Chen, Jixuan and Ye, Yuxiao and Cao, Ruisheng and Shin, Dongchan and Su, Hongjin and Suo, Zhaoqing and Gao, Hongcheng and Hu, Wenjing and Yin, Pengcheng and others}, journal={arXiv preprint arXiv:2411.07763}, year={2024} }