せどり情報局 (original) (raw)
利益商品のリサーチ自動化を実現するために、OFFモールから商品の「商品価格」「商品コード」「商品URL」をリスト化する方法です。OFFモールの商品なので基本的には中古品となります。
OFFモールでの商品の検索方法
- OFFモールのトップページ(https://netmall.hardoff.co.jp/)にアクセスし、一番上の検索窓は空欄のままで虫眼鏡マークをクリックして検索します。

- 右側に検索結果の商品が3列表示されます。また、左側には検索条件を指定するためのメニューが表示されます。

- 探したい商品を絞り込むために検索条件を指定します。
例えば、検索オプションで「プライスダウンのみ表示する」にチェックをすると、値下げされたお得商品のみを探すことができます。また商品ランクでは、中古商品の状態を指定することが出来ます。せどりで転売するつもりであれば、「B:日常使用の中古・傷汚れ少」以上を選択するのが良いです。
- 指定した条件に合った商品が検索されます。

プログラミング方法
商品ページへのリンク部分のソースコードは以下のようになっています。複数商品が

一方、検索条件に「プライスダウンのみ表示する」を指定しない場合のソースコードは以下のようになっています。複数商品が

商品URLの抽出

今回は上記のタグから商品URLを抽出します。商品URLは、商品
for elem in driver.find_elements(By.CSS_SELECTOR, '.itemcolmn_item'):
item_url = elem.find_element(By.XPATH, 'a').get_attribute('href')1行目:
seleniumの仕様で、class名に空白を含む場合には「By.CLASS_NAME」や「By.XPATH」では検索が出来ません。空白を含む場合には「By.CSS_SELECTOR」を使う必要があります。"aaa bbb" → ".aaa.bbb"といように、最初に「.(ピリオド)」を付け、空白も「.(ピリオド)」で置き換えます。
"itemcolmn_item itemcolmn_item--pricedown"
"itemcolmn_item "
CSS_SELECTORの指定では上記は2つとも".itemcolmn_item"の指定で検索することが可能です。これで、プライスダウン品か否かによらず、商品ごとのループ処理を共通化することができます。
2行目:
「By.XPATH」を使って相対パス指定で直下にあるタグを検索します。検索結果のタグの「href」属性値を商品URLとして取得します。
商品コードの抽出

上記のタグから商品コードを抽出します。OFFモールのページにはJANコードが記載されていません。中古品なのでJANコードがあるとは限らないためです。商品コードには商品の型番などが記入されていることが多く、メルカリ等で売値を調べる時に、この商品コードを使います。
item_code = elem.find_element(By.CLASS_NAME, 'item-code').text「By.CLASS_NAME」を指定して、class="item-code"のタグを検索します。検索された
商品価格の抽出

上記のタグから商品価格を抽出します。ここでもclass名に空白が使われています。item_price = elem.find_element(By.CSS_SELECTOR, '.font-en.item-price-en').text item_price = item_price.replace(',','').replace('円','')
1行目:
class名に空白が使われているので、「By.CSS_SELECTOR」を使って、class="font-en item-price-en"のタグを検索します。検索されたタグのテキスト情報を取得します。
2行目:
取得したテキストは「2,200円」と、区切り文字(カンマ)や「円」が入ったままになっています。数字として扱いやすいように、replace関数を使って「,」や「円」を削除します。
Pythonサンプルプログラム
import os
from selenium import webdriver
from selenium.webdriver.chrome import service as fs
from selenium.webdriver.common.by import By
# ChromeとChrome Driverのパス設定
base_path = os.path.dirname(__file__)
Chrome = base_path + '/chrome/chrome.exe' # Chromeのパス
ChromeDriver = base_path + '/chrome/chromedriver.exe' # Chrome Driverのパス
chrome_service = fs.Service(executable_path=ChromeDriver)
driver = webdriver.Chrome(service=chrome_service)
# OFFモールの検索結果にアクセス
url = "https://netmall.hardoff.co.jp/search/?s=7&pricedown=1&rank=1&rank=2&rank=3&rank=4"
driver.get(url)
# 商品ごとにループ処理
for elem in driver.find_elements(By.CSS_SELECTOR, '.itemcolmn_item'):
item_url = elem.find_element(By.XPATH, 'a').get_attribute('href') # 商品URL
item_code = elem.find_element(By.CLASS_NAME, 'item-code').text # 商品コード
item_price = elem.find_element(By.CSS_SELECTOR, '.font-en.item-price-en').text # 商品価格
# 商品コードがある場合に、「商品URL」「商品コード」「商品価格」を出力する
if item_code != '':
print(f'{item_url}\t{item_code}\t{item_price}')以下はサンプルプログラムの実行結果です。

サンプルプログラムの動かし方は以下の記事を参考にしてください。

Windowsタスクマネージャーからプロセス一覧を取得することで二重起動を防止します。
Windowsのプロセス一覧の取得
以下は、PythonからWindowsタスクマネージャーの情報を取得するサンプルプログラムです。
import subprocess
# プロセス一覧を取得
proc = subprocess.Popen('tasklist', shell=True, stdout=subprocess.PIPE)
# 一行ずつ表示
for line in proc.stdout:
print(line.decode('shift-jis'))Windowsのコマンドプロンプトでは文字コードに「Shift JIS」が使われているため、「Shift JIS」でデコードしないと文字化けになってしまいます。実行結果は以下となります。
イメージ名 PID セッション名 セッション# メモリ使用量
========================= ======== ================ =========== ============
System Idle Process 0 Services 0 8 K
System 4 Services 0 10,364 K
Registry 212 Services 0 52,812 K
smss.exe 724 Services 0 1,052 K
csrss.exe 932 Services 0 5,880 KChromedriverの二重起動を防止判定
Windowsプロセス一覧に「chromedriver.exe」があるか否かを判定する方法のサンプルプログラムです。
judge = True
for line in proc.stdout:
# 行頭が'chromedriver.exe'か否かを判定
if line.decode('shift-jis').startswith('chromedriver.exe'):
judge = False
break
if judge: # 起動可
print('chromedriver.exeを起動します')
else: # 起動不可
print('chromedriver.exeは実行中です')Chromedriverのプロセスを強制終了
DOSコマンドの「taskkill」を使ってプロセスを終了させる方法です。「/im」オプションで指定したイメージ名(実行ファイル名)のプロセスを終了させることができます。「/f」オプションを指定することで強制終了させます。
subprocess.Popen('taskkill /f /im chromedriver.exe', shell=True, stdout=subprocess.PIPE)

本ツールはスクレイピングを使ったせどりツールです。Ver0.2にアップデートしました。
ダウンロード方法
以下のリンクからダウンロードして適当なフォルダに保存してください。
ツールで出力する情報
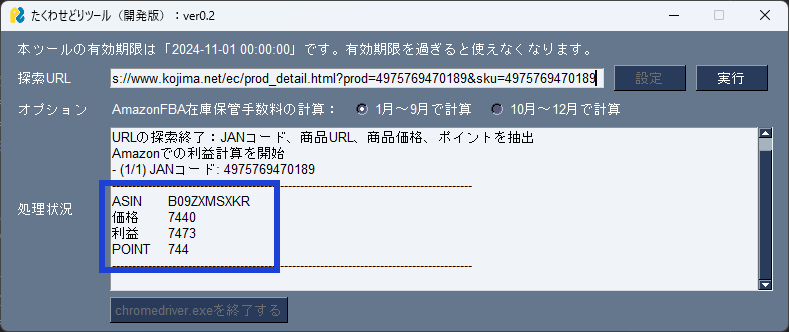
個別の商品ページを指定した場合
個別の商品ページを検索した場合には、①ASIN、②ネットショップでの購入価格、③Amazonで販売した場合の利益(Amazon手数料を引いた額)、④ネットショップで獲得できるポイントを出力します。
複数商品が記載されている検索結果ページを指定した場合
以下の情報をExcelファイルに出力します。
- A列:ASIN
- B列:JANコード
- C列:商品URL
- D列:楽天やヤフショで購入できる価格
- E列:獲得ポイント(ログインしないと正確なポイント算出は出来ないので参考値です)
- F列:AmazonFBAで販売した場合の利益(Amazon手数料を引いた額)

ツールで探索できるサイト
- 楽天の商品ページ:
「https://item.rakuten.co.jp/XXX」のサイト - 楽天の検索結果ページ:
「https://search.rakuten.co.jp/XXX」のサイト - 楽天のエディオンスペシャルセールのページ:
「https://www.rakuten.ne.jp/gold/edion/contents/mmXXXXXX」のサイト - Yahooショッピングの商品ページ:
「https://store.shopping.yahoo.co.jp/XXXX」のサイト - Yahooショッピングの検索結果ページ:
「https://store.shopping.yahoo.co.jp/XXXX/search.html」のサイト - コジマネットの商品ページ:
「https://www.kojima.net/ec/prod_detail.html」のサイト - コジマネットの検索結果のページ:
「https://www.kojima.net/ec/prod_list.html」のサイト
ツールの使い方
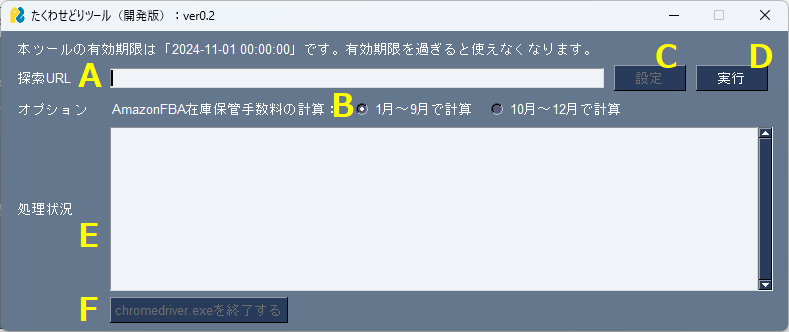

- 「A:探索URL」に検索したいURLを記入します。
- 「B:販売時期」を選択します。AmazonFBAで販売する場合、販売時期によって在庫保管手数料が変わりますので販売時期を「1月~9月」「10月~12月」のどちらかから選択してください。
- 楽天エディオンスペシャルセールのURLを「A:探索URL」に入れた場合に、「C:設定」ボタンが押せるようになります。「C:設定」ボタンを押すと「G:商品カテゴリ」を選択する画面が表示されます。検索したい商品カテゴリを選択してください。
- 「D:実行」ボタンを押して探索を実行します。探索が開始されるとChromeブラウザが立ち上がり、自動で処理が進みます。Chromeブラウザは最小化しても問題ありませんが、「×」ボタンで終了しないようにしてください。
- 探索中は「E:処理状況」にログが表示されます。
- 「E:処理状況」に「chromedriver.exeを強制終了させる場合には、下にあるボタンを押してください。」と出力された場合には「F:chromedriver.exeを終了する」ボタンを押してください。
その他
下記の場合には、一番下にある「コメントを書く」からご連絡ください。
- URLを入れてもうまく動かなかった場合(URLをご連絡ください)
- 機能を追加して欲しい場合
- 探索できるサイトを増やしてほしい場合
免責事項
- 本ツールの著作権はtakuwa-sedoriが所有しています。個人的な目的以外で使用することは禁止されています。
- 本ツールの利用は、ユーザーご自身の責任において行っていただきます。何らかのトラブルや損失・損害等が発生しても、当サイトは一切責任を負わないものとします。
- サイトによってスクレイピングが禁止されている場合があります。各サイトの利用規約に沿った利用をお願いします。本ツールの合法性、正確性、道徳性、最新性、適切性、著作権の許諾や有無など、その内容については一切の保証は出来ません。
- JANコード→ASIN変換に、こちらのサイトを利用させていただいています。(https://creepfablic.site/tools/jantoasin#google_vignette)
出来ること
利益商品を探すためのツールで、以下のような情報を自動作成します。

A列:ASIN
B列:JANコード
C列:商品URL
D列:楽天やヤフショで購入できる価格
E列:獲得ポイント(ログインしないと正確なポイント算出は出来ないので参考値です)
F列:AmazonFBAで販売した場合の利益(Amazon手数料を引いた額)
F列(利益)+獲得ポイント(E列+各ユーザ倍率) > D列(購入価格) となる商品が利益商品となります。
ダウンロード
以下のリンクからダウンロードして適当なフォルダに保存してください。新しいバージョンをご利用ください。
一番下に「コメントを書く」がありますので、うまく動かなかった場合には、動かなかったURLを記入の上、ご連絡ください。また、今後少しずつ、機能拡張を予定しております。こんな機能が欲しいなどのご連絡もコメントでお願いします。
ツールの使い方
ダウンロードしたTakuwaTool.exeを実行すると以下のような画面が表示されます。終了する場合は右上の「×」を押してください。
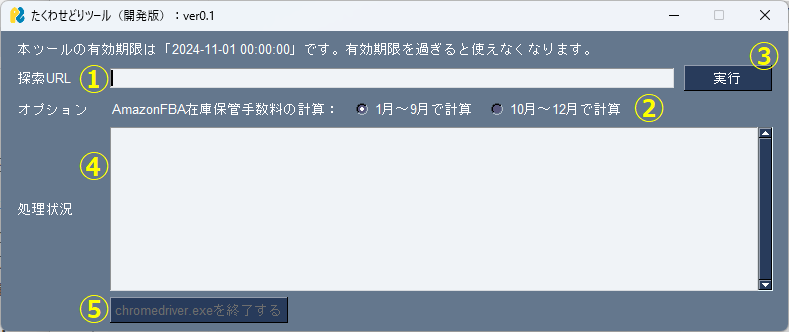
①に探索したいURLを記入してください。記入できるURLは以下のようなページです。
- 楽天の検索結果ページ(例 https://search.rakuten.co.jp/search/mall/-/100026/?sid=206032)
- ヤフショの検索結果ページ(例 https://store.shopping.yahoo.co.jp/joshin/search.html?p=#CentSrchFilter1)
- コジマネットの検索結果ページ(例 https://www.kojima.net/ec/prod_list.html?cate=pc&grpId=spe-disp-000006201001)
- エディオンスペシャルセールのページ(例 https://www.rakuten.ne.jp/gold/edion/contents/mm240919/index.html)
②AmazonFBAで販売する場合、販売時期によって在庫保管手数料が変わります。販売時期を選択してください。
③ボタンを押すことで①のURLを探索します。探索が開始されるとChromeブラウザが立ち上がり、自動で処理が進みます。Chromeブラウザは最小化はOKですが、「×」ボタンで終了しないようにしてください。
④処理の状況が出力されます。
⑤④に「chromedriver.exeを強制終了させる場合には、下にあるボタンを押してください。」と出力された場合に押してください。
正常に処理が終了すると、TakuwaTool.exeと同じフォルダに「item_list*.xlsx」というファイルが生成されます。

注:エディオンスペシャルセールのように、1ページに膨大な量の商品が記載されている場合、処理にかなりの時間がかかります。ご注意ください。
免責事項
- 本ツールの利用は、ユーザーご自身の責任において行っていただきます。何らかのトラブルや損失・損害等が発生しても、当サイトは一切責任を負わないものとします。
- サイトによってスクレイピングが禁止されている場合があります。各サイトの利用規約に沿った利用をお願いします。本ツールの合法性、正確性、道徳性、最新性、適切性、著作権の許諾や有無など、その内容については一切の保証は出来ません。
- JANコード→ASIN変換に、こちらのサイトを利用させていただいています。(https://creepfablic.site/tools/jantoasin#google_vignette)
- 本ツールの著作権はtakuwa-sedoriが所有しています。個人的な目的以外で使用することは禁止されています。
利益商品のリサーチ自動化を実現するために、Amazonでの販売価格を抽出する方法です。
やりたいこと
Amazon FBA料金シミュレータを使って、Amazonでの販売価格を調べます。Amazon FBA料金シミュレータでは、JANコードでも検索可能なはずですが、現在は不具合のため一部のJANコードでは検索が出来ないようです。そのため、JANコードからASINに変換してから、Amazon FBA料金シミュレータで販売価格を調べます。
- JANコードからASINを取得します。取得方法は以下の記事を参照してください。
takuwa-sedori.hatenablog.com - Amazon FBA料金シミュレータ(*)にアクセスします。サインインするか聞かれるので「ゲストとして続ける」を押します。
(*)https://sellercentral.amazon.co.jp/hz/fba/profitabilitycalculator/index?lang=ja_JP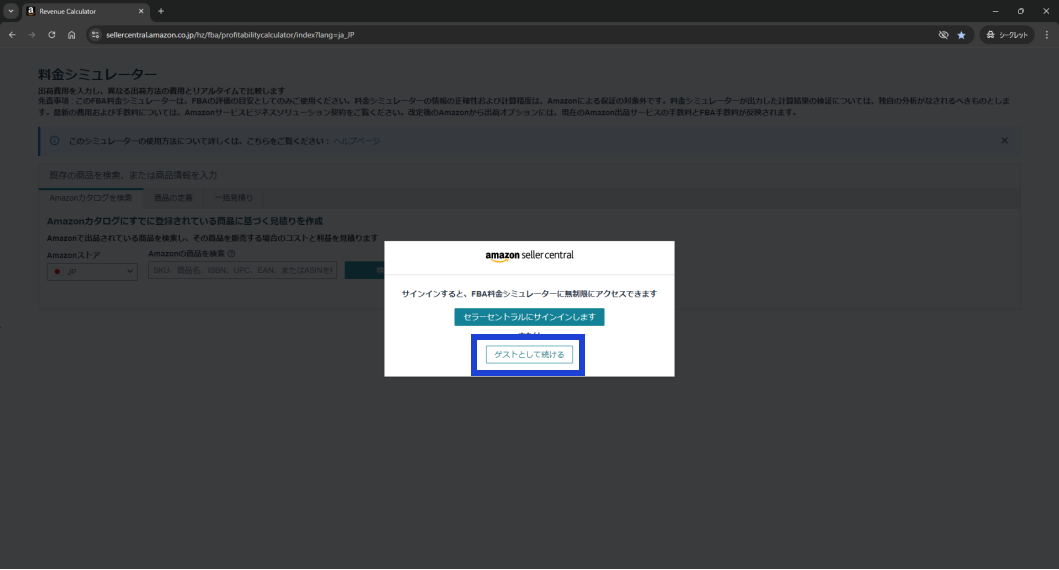
- 検索ボックスにASINを記入して「検索」ボタンを押します。JANコードでも検索可能なはずですが、現在は不具合でJANコードで検索できない場合がありますので、ASINで検索を行います。
 JANコードの検索で失敗した場合には、以下のように一致する商品が見つからないというエラーが表示されます。
JANコードの検索で失敗した場合には、以下のように一致する商品が見つからないというエラーが表示されます。
- 検索結果として、AmazonFBAで出荷した場合(左部)と、自己配送で出荷した場合(中央部)の料金シミュレーションが表示されます。今回はAmazonFBAでの料金を調べます。
在庫保管手数料が「1月~9月」と「10月~12月」で異なるので、販売時期に合わせて適切な方を選びます。
Amazonの手数料を除いた純利益が下の方に表示されます。下図の例では、13,591円で販売した場合に、Amazon手数料を除いた11,222円の入金になることを表しています。この金額よりも安く仕入れられるかどうかがポイントとなります。
プログラミング方法
「ゲストとして続ける」ボタンの押下
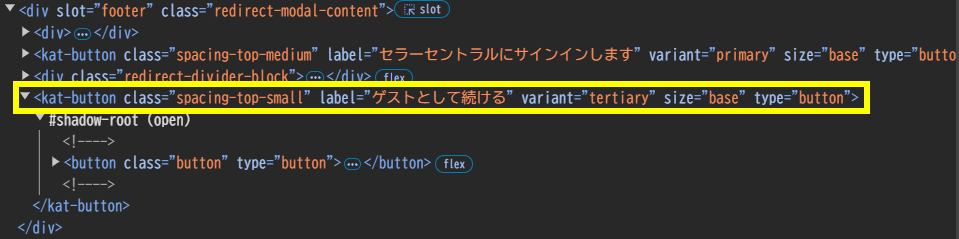
「ゲストとして続ける」ボタンのソースコードは上記のようになっています。ボタンを押すプログラムは以下のようになります。
driver.find_element(By.CLASS_NAME, 'spacing-top-small').click()class="spacing-top-small"のタグを検索し、click()でボタンを押します。
検索ボックスにASINを記入して検索


検索ボックスや検索ボタンのソースコードは上記のようになっています。検索ボックスにASINを記入し、「検索」ボタンを押すプログラムは以下のようになります。
driver.find_element(By.CLASS_NAME, 'input-asin').send_keys('XXXXX')
driver.find_element(By.CLASS_NAME, 'button-search').click()1行目:
class="input-asin"となるタグを検索、検索結果としてタグが検索されます。検索されたタグに「send_keys」でASINを記入します。
2行目:
class="button-search"となるタグを検索、検索結果としてタグが検索されます。検索されたタグを「click」で押します。
在庫保管手数料の選択
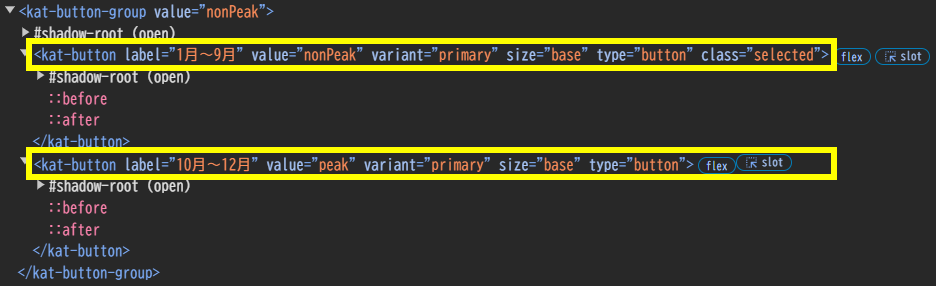
「1月~9月」「10月~12月」の選択部分のソースコードは上記のようになっています。プログラムでの選択方法は以下のようになります。
driver.find_element(By.XPATH, '//kat-button[@value="nonPeak"]').click()
driver.find_element(By.XPATH, '//kat-button[@value="peak"]').click()1行目が「1月~9月」ボタンを選択する方法、2行目が「10月~12月」ボタンを選択する方法となります。value属性の値を指定してタグを検索、検索されたタグを「click」で押します。
純利益の取得
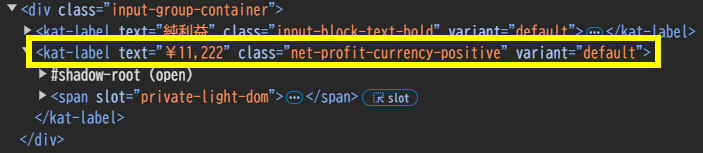
純利益が記載されている箇所のソースコードは上記のようになっています。ここから純利益の金額を取得するプログラムは以下のようになります。
profit = driver.find_element(By.CLASS_NAME, 'net-profit-currency-positive').get_attribute('text')
profit = profit.replace('¥','').replace(',','')1行目:
class="net-profit-currency-positive"となるタグを検索、検索結果としてタグが検索されます。次に検索されたタグのtext属性値を取得します。
2行目:
検索された値は「¥11**,**222」なので、数値として扱うためには「¥」や「,」が不要となります。replace関数を使って「¥」や「,」を削除します。
なお、「検索」ボタンを押してから、検索結果が返ってくるまで少し時間が必要となります。検索結果が返ってくる前に「在庫保管手数料の選択」や「純利益の取得」を実行するとエラーになるため、エラーが出なくなるのを待ってから実行する必要があります。
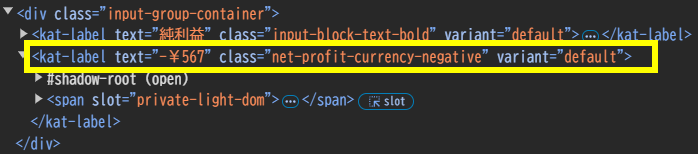
Amazonでは値段が高すぎる場合にカート価格が表示されない場合があります。そのような場合には正しい商品価格が取得できず(商品価格=¥1)、純利益がマイナスになってしまいます。純利益がプラスの場合にはclass="net-profit-currency-positive"というタグでしたが、純利益がマイナスの場合にはclass="net-profit-currency-negative"というタグになります。
Pythonサンプルプログラム
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.chrome import service as fs
from selenium.webdriver.common.by import By
CHROMEDRIVER = 'C:/demo/chromedriver.exe' # Chrome Driverのパス
asin_list = ['B0CHVR65ZK', 'B0B5SHFPBB', 'B07574QXCS'] # 検索するASINリスト
# Chromeブラウザを起動する
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
driver = webdriver.Chrome(service=chrome_service)
# ASINごとのループ処理
for asin in asin_list:
# AmazonFBA料金シミュレータを開く
url = 'https://sellercentral.amazon.co.jp/hz/fba/profitabilitycalculator/index?lang=ja_JP'
driver.get(url)
driver.find_element(By.CLASS_NAME, 'spacing-top-small').click() # 「ゲストとして続ける」ボタンの押下
driver.find_element(By.CLASS_NAME, 'input-asin').send_keys(asin) # 検索ボックスへのASIN記入
driver.find_element(By.CLASS_NAME, 'button-search').click() # 「検索」ボタンの押下
# 検索結果が返ってくるまで無限にループする
while True:
try:
# 在庫保管手数料として「10月~12月」を選択する
driver.find_element(By.XPATH, '//kat-button[@value="peak"]').click()
except NoSuchElementException:
# 在庫保管手数料の選択が出来ない場合には、再度繰り返す
continue
try:
# 純利益がプラスの場合
profit = driver.find_element(By.CLASS_NAME, 'net-profit-currency-positive').get_attribute('text')
except NoSuchElementException:
# 純利益がマイナスの場合
profit = driver.find_element(By.CLASS_NAME, 'net-profit-currency-negative').get_attribute('text')
# 純利益の表記から「¥」と「,」を削除する
profit = profit.replace('¥', '').replace(',', '')
# コンソールに「ASIN」と「利益」を表示する
print(f'ASIN={asin}\tprofit={profit}')
break
# Chromeブラウザを閉じる
driver.close()
driver.quit()
以下はサンプルプログラムの実行結果です。

サンプルプログラムの動かし方は以下の記事を参考にしてください。
ASINは商品を識別するためにAmazon独自のコードで、Amazonで商品を検索したい時などに必要となる場合があります。JANコードからASINを検索する方法は色々とありますが、変換ツールを無料で公開されている方がいるので、スクレイピングでこのサイトを利用させていただきます。
やりたいこと(JANコードからASINの取得)
- こちらのサイト(https://creepfablic.site/tools/jantoasin)を使わせていただきます。

- 検索ボックスにJANコードを入力して「変換」ボタンを押します。
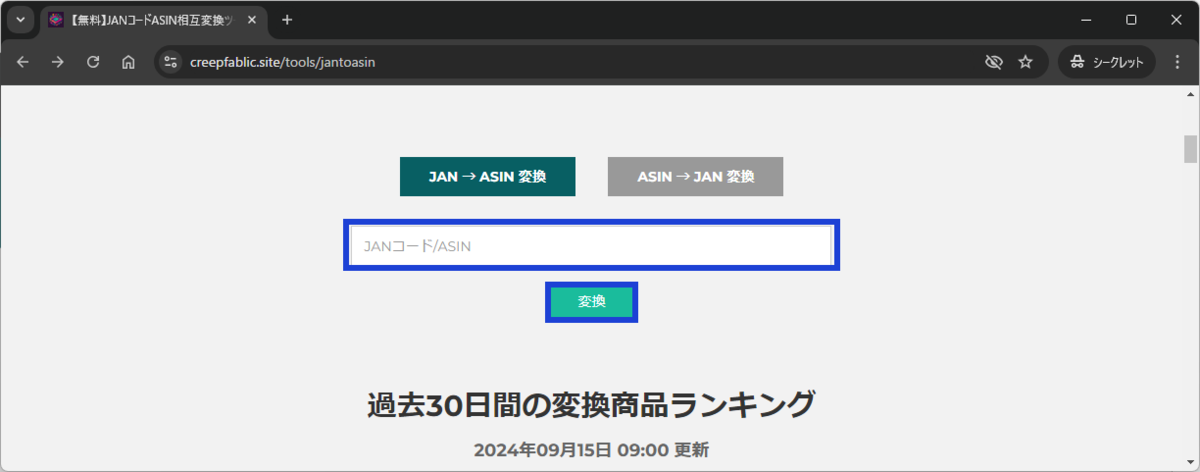
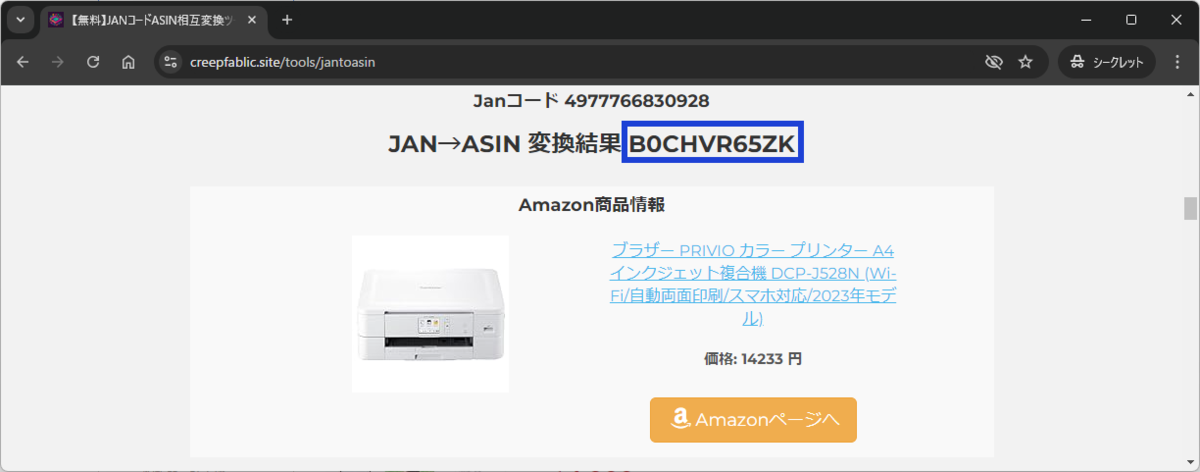
- 検索結果が以下のように表示されます。
JANコード入力と「変換」ボタン押下

検索ボックスは上記のようなソースコードになっています。

また、「変換」ボタンは上記のようなソースコードになっています。
jan_code = '4977766830928'
driver.find_element(By.ID, 'id-JANCODE').send_keys(jan_code)
driver.find_element(By.CLASS_NAME, 'form-send').click()1行目:
JANコードの例です。
2行目:
class="id-JANCODE"のタグを検索し、タグがヒットします。次に、検索ボックスであるにsend_keyで値を代入します。上記例では1行目で設定した「4977766830928」というJANコードを代入しています。
3行目:
「変換」ボダンをクリックします。
検索結果からのASIN抽出

検索結果は上記のようなソースコードになっています。
txt = driver.find_element(By.XPATH, '//div[@class="centered"]/h3').text
asin = txt.replace('JAN→ASIN 変換結果:','')1行目:
まずASINが記載されている
タグを抽出します。「By.XPATH」を使って、class="centered"のタグの下にあるタグを検索します。
2行目:
ASINの前の文字列「JAN→ASIN 変換結果:」が不要なので、replace関数を使って削除します。
Pythonサンプルプログラム
from selenium import webdriver
from selenium.webdriver.chrome import service as fs
from selenium.webdriver.common.by import By
CHROMEDRIVER = 'C:/demo/chromedriver.exe' # Chrome Driverのパス
# Chromeブラウザを起動する
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
driver = webdriver.Chrome(service=chrome_service)
# JANコード→ASIN変換ツールのページを開く
url = 'https://creepfablic.site/tools/jantoasin'
driver.get(url)
# ASINに変換するJANコードの配列
jan_code_list = ['4977766830928', '4981254065464', '4549292100037']
# JANコード毎に処理をループ
for jan_code in jan_code_list:
driver.find_element(By.ID, 'id-JANCODE').send_keys(jan_code) # 検索ボックスにJANコードを記入
driver.find_element(By.CLASS_NAME, 'form-send').click() # 「変換」ボタンを押下
asin = driver.find_element(By.XPATH, '//div[@class="centered"]/h3').text.replace('JAN→ASIN 変換結果:','') # ASIN取得
# コンソールに「JANコード」と「ASIN」を出力
print(f'JANコード={jan_code}\tASIN={asin}')
# Chromeブラウザを閉じる
driver.close()
driver.quit()
以下はサンプルプログラムの実行結果です。
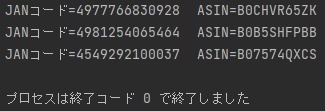
サンプルプログラムの動かし方は以下の記事を参考にしてください。

タグを検索します。
2行目:
ASINの前の文字列「JAN→ASIN 変換結果:」が不要なので、replace関数を使って削除します。
Pythonサンプルプログラム
from selenium import webdriver
from selenium.webdriver.chrome import service as fs
from selenium.webdriver.common.by import By
CHROMEDRIVER = 'C:/demo/chromedriver.exe' # Chrome Driverのパス
# Chromeブラウザを起動する
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
driver = webdriver.Chrome(service=chrome_service)
# JANコード→ASIN変換ツールのページを開く
url = 'https://creepfablic.site/tools/jantoasin'
driver.get(url)
# ASINに変換するJANコードの配列
jan_code_list = ['4977766830928', '4981254065464', '4549292100037']
# JANコード毎に処理をループ
for jan_code in jan_code_list:
driver.find_element(By.ID, 'id-JANCODE').send_keys(jan_code) # 検索ボックスにJANコードを記入
driver.find_element(By.CLASS_NAME, 'form-send').click() # 「変換」ボタンを押下
asin = driver.find_element(By.XPATH, '//div[@class="centered"]/h3').text.replace('JAN→ASIN 変換結果:','') # ASIN取得
# コンソールに「JANコード」と「ASIN」を出力
print(f'JANコード={jan_code}\tASIN={asin}')
# Chromeブラウザを閉じる
driver.close()
driver.quit()
以下はサンプルプログラムの実行結果です。
サンプルプログラムの動かし方は以下の記事を参考にしてください。