カンムテックブログ (original) (raw)
エンジニアの佐野です。カンムはバックエンドに PostgreSQL を置きつつサーバを Go で書いています。DB のトランザクションの取り回しは概ね次の様なイディオムになっているのですが、先日 Commit() が漏れている箇所を見つけまして...。結果としてそれについては大きな問題はなく秋の夜長に遅めの肝試しをする程度で済んだのですが、これは事故に繋がるためトランザクションの Commit 漏れ(defer Rollback() 漏れも)を検出する Linter を書きました。
tx, err := db.BeginTx(ctx, nil) if err != nil { return err } defer tx.Rollback()
if err := tx.Commit(); err != nil { return err }
Linter の方針
次のような方針とします
- 意図的にコミットを書かず Rollback() させる前提の実装もあるかもしれないが、Commit() が書かれていないものは指摘の対象とする。ようは tx, err := Begin() もしくは tx, err := BeginTx() があったらそれと対になる defer tx.Rollback() と tx.Commit() のペアがちゃんと実装されているかチェックする。
- Go での DB トランザクションの取り回し方はいろいろあるとは思うがカンムで主流のイディオムになっている前提とする。これはいきなり汎用的なツールとせずにまずはカンム内の問題を解決することに焦点を当てるため。
txchk
上記方針にて txchk という Linter を書きました。txchk は golang.org/x/tools/go/analysis.Analyzer を利用して開発しています。golang.org/x/tools/go/analysis.Analyzer は静的解析用のパッケージでこれを使うと比較的簡単に Linter を書くことができます。またコマンドの実装を次のように golang.org/x/tools/go/analysis/singlechecker.Main() 経由で Analyzer を呼ぶようにすることで go vet に組み込んで go vet -vettool=$(which txchk) ./... として使えるようにすることもできます。
package main
import ( "github.com/kanmu/txchk" "golang.org/x/tools/go/analysis/singlechecker" )
func main() { singlechecker.Main(txchk.Analyzer) }
go vet -vettool=$(which txchk) ./...
以下が txchk を書いて Go のコミット漏れを調査してその漏れを一掃したパッチです。結構見つかりました...冒頭およびPR 本文にも書いてありますが結果として漏れていても問題はなかったです。現在は txchk を CI の lint ステージに組み込んで go vet 経由で動かしています。
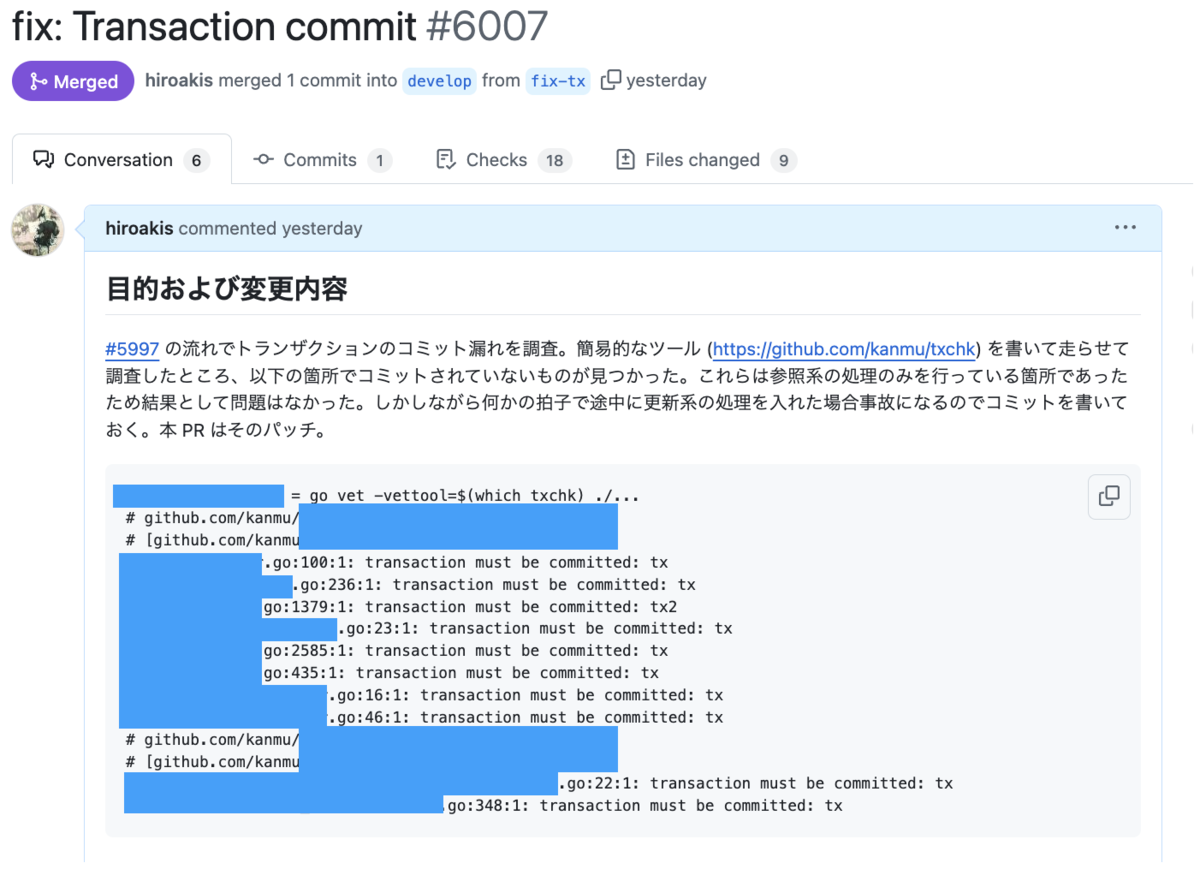
txchk の処理の流れと txchk の概観
処理の流れは次の通りです。
- ターゲットとなる Go のリポジトリのすべての関数を対象に各関数を先頭から走査
- Begin() または BeginTx() している箇所を見つける
- Begin() または BeginTx() が見つかったらその左辺を走査して1つめの戻り値の変数名 (例: tx) を記憶
- それ以降の処理を走査して tx.Commit() を呼んでいればコミットされているとみなす
- 関数を最後まで走査し、tx.Commit() が無かったら Lint エラーとする
- (Rollback() についても上記と同様の処理を行う)
この処理の概観は以下の通りです。
package txchk
import ( "go/ast" "go/token" "strings"
"golang.org/x/tools/go/analysis" "golang.org/x/tools/go/analysis/passes/inspect" "golang.org/x/tools/go/ast/inspector" )
var Analyzer = &analysis.Analyzer{ Name: "txchk", Doc: Doc, Run: run, Requires: []*analysis.Analyzer{ inspect.Analyzer, }, }
const Doc = "txchk"
func run(pass *analysis.Pass) (interface{}, error) { inspect := pass.ResultOf[inspect.Analyzer].(*inspector.Inspector)
nodeFilter := []ast.Node{ (*ast.FuncDecl)(nil), }
inspect.Preorder(nodeFilter, func(n ast.Node) { pos := pass.Fset.Position(n.Pos())
switch node := n.(type) {
case *ast.FuncDecl:
if strings.HasPrefix(node.Name.Name, "Test") || strings.HasPrefix(node.Name.Name, "test") {
return
}
for _, stmt := range node.Body.List {
switch s := stmt.(type) {
case *ast.AssignStmt:
for _, expr := range s.Rhs {
if callExpr, ok := expr.(*ast.CallExpr); ok {
found := findTransactionTypeBegin(callExpr)
if found {
beginPos := pass.Fset.Position(s.Pos()).Line
for i, lh := range s.Lhs {
if i == 0 {
if ident, ok := lh.(*ast.Ident); ok {
committed := isCommitImplemented(pass.Fset, node.Body, beginPos, ident.Name)
if !committed {
pass.Reportf(s.Pos(), "transaction must be committed: %s", ident.Name)
}
rollbacked := isRollbackImplemented(pass.Fset, node.Body, beginPos, ident.Name)
if !rollbacked {
pass.Reportf(s.Pos(), "transaction must be rollbacked: %s", ident.Name)
}
}
}
}
}
}
}
}
}
}}) return nil, nil }
処理の解説
ひとつずつ解説していきます。まず以下の部分は analysis.Analyzer を使って Linter を書くときのガワのようなものです。
var Analyzer = &analysis.Analyzer{ Name: "txchk", Doc: Doc, Run: run, Requires: []*analysis.Analyzer{ inspect.Analyzer, }, }
const Doc = "txchk"
func run(pass *analysis.Pass) (interface{}, error) { inspect := pass.ResultOf[inspect.Analyzer].(*inspector.Inspector)
nodeFilter := []ast.Node{
}
var err error inspect.Preorder(nodeFilter, func(n ast.Node) {
} return nil, err }
「フィルタ」にて処理したい箇所を指定、その箇所について「好きな処理」を書きます。今回はすべての関数を対象にしたいので (*ast.FuncDecl)(nil) をフィルタに入れていますが、例えばソースコード内に定義された構造体をターゲットに対して何らかの静的解析を施したい場合は (*ast.StructType)(nil) をフィルタに書くことで inspect.Preorder(nodeFilter, func(n ast.Node) には構造体のノードのみが入ってくるようにすることができます。「好きな処理」ではその通りフィルタされたノードについてやりたいことを書いていけばよいです。
続いて「Begin() または BeginTx() している箇所を見つける」処理ですが、ノードが *ast.FuncDecl のものについて node.Body.List を for...range で回すことでその関数を先頭から走査します。そして *ast.AssignStmt 、つまり代入があったとき、その右辺 (s.Rhs) を調査し、その右辺が *ast.CallExpr (関数呼び出し)であれば、それが Begin か BeginTx かを調べます。
switch node := n.(type) {
case *ast.FuncDecl:
if strings.HasPrefix(node.Name.Name, "Test") || strings.HasPrefix(node.Name.Name, "test") {
return
}
for _, stmt := range node.Body.List {
switch s := stmt.(type) {
case *ast.AssignStmt:
for _, expr := range s.Rhs {
if callExpr, ok := expr.(*ast.CallExpr); ok {
found := findTransactionTypeBegin(callExpr)...
findTransactionTypeBegin() の実装は次の様になっています。これは db.Begin() もしくは db.BeginTx() を探す実装で、再起処理をしているのは Begin() や BeginTx() が app.DB.Begin() のようになっていたりする場合もそれを辿って Begin() および BeginTx() を見つけられるようにするためです。
func findTransactionTypeBegin(node *ast.CallExpr) bool { if fun, ok := node.Fun.(*ast.SelectorExpr); ok { if fun.Sel.Name == "Begin" || fun.Sel.Name == "BeginTx" { return true } } if n, ok := node.Fun.(*ast.CallExpr); ok { return findTransactionTypeBegin(n) } return false }
そして Begin() または BeginTx() が見つかったら左辺 (s.Lhs) を走査して1つめの戻り値の変数名が格納されている ident.Name を「コミットが実装されているか?」を調査する関数 (isCommitImplemented()) に渡して、 ident.Name (例: tx) について tx.Commit() が実装されているかを調べます。
found := findTransactionTypeBegin(callExpr)
if found {
beginPos := pass.Fset.Position(s.Pos()).Line
for i, lh := range s.Lhs {
if i == 0 {
if ident, ok := lh.(*ast.Ident); ok {
committed := isCommitImplemented(pass.Fset, node.Body, beginPos, ident.Name)...
isCommitImplemented() は次の通りです。tx.Rollback() を探すときも似たような処理になるので isTransactionFinished() のラッパにしています。TransactionTypeCommit, TransactionTypeRollback はそれぞれ type TransactionType int と iota で定義した列挙です。
func isCommitImplemented(fset *token.FileSet, body *ast.BlockStmt, beginPos int, txIdentName string) bool { return isTransactionFinished(fset, body, beginPos, txIdentName, TransactionTypeCommit) }
func isRollbackImplemented(fset *token.FileSet, body *ast.BlockStmt, beginPos int, txIdentName string) bool { return isTransactionFinished(fset, body, beginPos, txIdentName, TransactionTypeRollback) }
func isTransactionFinished(fset *token.FileSet, body *ast.BlockStmt, beginPos int, txIdentName string, tranType TransactionType) bool { for _, stmt := range body.List { pos := fset.Position(stmt.Pos()) if pos.Line < beginPos { continue }
switch s := stmt.(type) {
case *ast.IfStmt:
if s.Init != nil {
if assignStmt, ok := s.Init.(*ast.AssignStmt); ok {
for _, expr := range assignStmt.Rhs {
if callExpr, ok := expr.(*ast.CallExpr); ok {
if findTransactionTypeByIdentName(callExpr, txIdentName, tranType) {
return true
}
}
}
}
}
if isTransactionFinished(fset, s.Body, pos.Line, txIdentName, tranType) {
return true
}
case *ast.BlockStmt:
if isTransactionFinished(fset, s, pos.Line, txIdentName, tranType) {
return true
}
case *ast.ExprStmt:
if callExpr, ok := s.X.(*ast.CallExpr); ok {
if findTransactionTypeByIdentName(callExpr, txIdentName, tranType) {
return true
}
if n, ok := callExpr.Fun.(*ast.FuncLit); ok {
if isTransactionFinished(fset, n.Body, pos.Line, txIdentName, tranType) {
return true
}
}
}
case *ast.ReturnStmt:
for _, rtn := range s.Results {
if callExpr, ok := rtn.(*ast.CallExpr); ok {
if findTransactionTypeByIdentName(callExpr, txIdentName, tranType) {
return true
}
}
}
case *ast.AssignStmt:
for _, expr := range s.Rhs {
if callExpr, ok := expr.(*ast.CallExpr); ok {
if findTransactionTypeByIdentName(callExpr, txIdentName, tranType) {
return true
}
if n, ok := callExpr.Fun.(*ast.FuncLit); ok {
if isTransactionFinished(fset, n.Body, pos.Line, txIdentName, tranType) {
return true
}
}
}
}
case *ast.DeferStmt:
if findTransactionTypeByIdentName(s.Call, txIdentName, tranType) {
return true
}
if n, ok := s.Call.Fun.(*ast.FuncLit); ok {
if isTransactionFinished(fset, n.Body, 0, txIdentName, tranType) {
return true
}
}
}} return false }
型スイッチが続いているのですが、これは tx.Commit() の書かれ方にいくつかのパターンがありそれを網羅するためです。
if err := tx.Commit(); err != nil { }
if cond { tx.Commit() }
return tx.Commit()
tx.Commit()
...etc
カンム内ではだいたいこのような書き方をしているのでチーム内で主流なものはカバーします。ちなみに以下のように for...range の中に書くこともできるのですが、このような奇っ怪なものはサポートしないものとします。
for _, err := range []error{err, tx.Commit()} { if err != nil { return err } }
isCommitImplemented() の処理中で登場する findTransactionTypeByIdentName() は次のようになっています。 Begin() や BeginTx() を探す findTransactionTypeBegin() と似ているのですが identName が一致しているかどうかを調べている点で違いがあります。
func findTransactionTypeByIdentName(node *ast.CallExpr, identName string, tranType TransactionType) bool { if fun, ok := node.Fun.(*ast.SelectorExpr); ok { if fun.Sel.Name == tranType.String() { if pkgIndent, ok := fun.X.(*ast.Ident); ok { if pkgIndent.Name == identName { return true } } } } if n, ok := node.Fun.(*ast.CallExpr); ok { return findTransactionTypeByIdentName(n, identName, tranType) } return false }
これは Begin() は1関数内に1つだけとは限らず tx1, err := Begin() と tx2, err := Begin() が存在しているケースがありそれに対応するためです(tx1 の Commit() と tx2 の Commit() をそれぞれ探したい)。
isCommitImplemented() が関数を下まで走査し、tx.Commit() が見つからなかったら pass.Reportf() で Linter エラーを通知します。
committed := isCommitImplemented(pass.Fset, node.Body, beginPos, ident.Name)
if !committed {
pass.Reportf(s.Pos(), "transaction must be committed: %s", ident.Name)
}
rollbacked := isRollbackImplemented(pass.Fset, node.Body, beginPos, ident.Name)
if !rollbacked {
pass.Reportf(s.Pos(), "transaction must be rollbacked: %s", ident.Name)
}Rollback() についても同様の処理を行います。以上にて Begin() や BeginTx() が書かれている関数内の処理について、それと対になる tx.Commit() と defer tx.Rollback() が存在しているかを調べる Linter ができあがりました。
まとめ
Go の静的解析のエコシステムに乗ることで比較的簡単に Linter が書けました。レビューで毎回見る箇所や毎回指摘している箇所、チーム内のコーディングルールのようなものがあったらそれを Linter 化してしまうのもありです。それによって書き手もレビュアーもよりビジネスロジックに集中して開発できるようになります。
おわり
SREの菅原です。
カンムのサービスのバッチ処理は基本的にEventBridge Scheduler+ECSで動いており、バッチのスケジュールはterraformで以下のように定義されています。
module "kanmu_batch" {
バッチまわりはモジュール化
source = "../modules/batch"
for_each = { hogehoge-batch = { schedule_expression = "cron(0 0 * * ? *)" command = ["/batch/bin/hoge", "hikisu"] is_enabled = true } fugafuga-batch = { schedule_expression = "cron(5 0 * * ? *)" command = ["/batch/bin/fuga", "hikisu"] is_enabled = true } # ... }
schedule_expression = each.value.schedule_expression command = each.value.command
...
schedule_expressionに指定するのはEventBridgeのcron式、またはrate式なのですが、cron式でDay-of-monthに値を指定した場合、Day-of-weekは?にする必要があるなど、いくつか間違いやすいポイントがあります。
aws_scheduler_scheduleリソースがterraform plan実行時にチェックしてくれると助かるのですがそのような機能はないため、terraform applyを実行してはじめて間違いに気付くことになります。
単純なミスがあるのにterraform planが通ってしまいレビュー後のterraform applyで手戻りが発生すると余計な時間を割くことになるので、terraform providerを使ってschedule_expressionをチェックできるようにしてみました。
terraform-provider-cronplan
schedule_expressionのチェック用に自作したterraform-provider-cronplanは、Data SourceとFunctionが一つずつ定義されているシンプルなproviderです。
provider::cronplan::exprというFunctionを使って、terraform plan実行時にschedule_expressionをチェックすることができます。
module "kanmu_batch" { source = "../modules/batch"
for_each = { hogehoge-batch = { schedule_expression = provider::cronplan::expr("cron(10 * * * ? *)") command = ["/batch/bin/hoge", "hikisu"] is_enabled = true }
上記の例ではschedule_expressionに問題がなければ普通にスケジュールが作成されますが、schedule_expressionに間違いがあるとエラーになります。
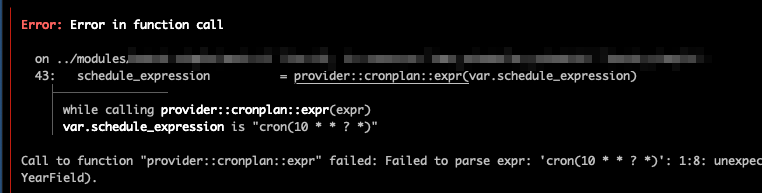
cron式の些細なシンタックスエラーはterraform planで分かるようになったので、DXがそれなりに改善できたと思います。
EventBridgeのcron式の仕様について
terraform-provider-cronplanのcron式のチェックに使っているのは、趣味で開発しているcronplanというGolangのライブラリです。
開発するにあたってEventBridgeのcron式の仕様を調べたのですが、マニュアルドキュメントがあるぐらいできちんとした仕様は見つけられませんでした。
そもそもcron式全般についてきちんとした仕様を見つけられることができず*1、特にvixie-cron等のUnixのcron式のSUN(日曜日)が0であるのに対し、一部Javaライブラリのcron式ではSUNが1になっている点にだいぶ混乱しました。
EventBridgeは後者のJavaライブラリを踏襲しているようで分かりにくい部分もあるのですが、LやWのような特殊な(かつ業務上必要になる)拡張が入っているのはありがたかったです。
Day-of-weekのLについて
EventBridgeのcron式の仕様は見つけられなかったのですがcronplanの実装を続けているうちに、バックエンドの実装はこれではないか?あるいは仕様が準拠しているのではないか?というライブラリがありました。
Quartzは古くからあるJavaのJob Schedulingライブラリのようで、Secondsがある点を除けばEventBridgeのcron式の動作と一致しています。 特にDay-of-weekのLの変わった仕様がEventBridgeと同じです。
Lは末日を表す文字でDay-of-monthフィールドでLやL-1を指定することで月末、月末の1日前を表すことができます。LはDay-of-weekフィールドにも指定することができ、たとえば6Lと指定すると月の最終週の金曜日を表すことができます。
このLはDay-of-weekフィールドに単体で指定することができるのですが
cron(0 0 ? * L *)
というcron式が何を意味しているか分かりますか?
正解は
cron(0 0 ? * SAT *)
になります。Lを単体で指定した場合、SATを指定したのと同じ動作になります。
この動作を初めて見つけたとき、だいぶ変わった仕様だと思っていたのですがQuartzのドキュメントにはまさにその仕様が書かれていました。
If used in the day-of-week field by itself, it simply means “7” or “SAT”.https://www.quartz-scheduler.org/documentation/quartz-2.3.0/tutorials/crontrigger.html
それ以外にもいくつかのエッジケース、たとえば「Day-of-monthに31を指定したときに31日がない月はどうなるのか?」とか「Day-of-weekに6#5を指定したときに第五週目の金曜日がない月はどうなるのか?」などの動作が一致しているように見えたので、準拠している可能性は高そうなのですが公式の情報は見つけられていないので、気になっているところではあります…
cronplanに関してはAWSのEventBridgeコンソールのプレビューを見つつできるだけ動作を合わせているつもりですが、さすがに数日・数年かけたテストはできていないので、もし実際の動作と異なる仕様がありましたらIssueを起票していただけましたら対応しますので、ぜひぜひご利用ください。
SREの菅原です。
カンムのサービスはWebサービス・バッチ処理なども含めて基本的にはECS上で動かしているのですが、簡単なバッチ処理はLambda+EventBridge Schedulerの組み合わせで動かすこともあります。
LambdaはECSに比べてDockerイメージのビルドやECRの準備が不要で作成の手間が少ないのですが、terraformでデプロイまで含めて管理しようとすると少し問題がありました。
terraformでのLambdaのデプロイの問題点
例えば以下のような構成のNode.jsのLambdaをデプロイする場合
/ ├── lambda.tf └── lambda ├── app.js ├── package-lock.json └── package.json
const util = require("util"); const gis = util.promisify(require("g-i-s"));
exports.handler = async (event) => { const rs = await gis("nyan"); console.log(JSON.stringify(rs, null, 2)); };
null_resource(またはterraform-data)とarchive_fileを使って、terraformでLambdaの作成とデプロイを行えます。
resource "null_resource" "npm_install" { triggers = { package_json = filebase64sha256("lambda/package.json") package_lock_json = filebase64sha256("lambda/package-lock.json") }
provisioner "local-exec" { working_dir = "lambda" command = "npm install" } }
data "archive_file" "nyan" { type = "zip" output_path = "app.zip" source_dir = "lambda" depends_on = [null_resource.npm_install] }
resource "aws_lambda_function" "nyan" { function_name = "nyan" runtime = "nodejs20.x" role = "..." handler = "app.handler" filename = data.archive_file.nyan.output_path source_code_hash = data.archive_file.nyan.output_base64sha256 }
しかしこの方法だと
- archive_fileがデータソースであるため、terraformを実行するたびにzipファイルが作成される *1
- 特にCIやAtlantis*2でterraformを実行する場合、意図しないタイミングでLambdaの更新が実行される
- npm installやpip installなどzipファイル作成前の処理の定義が複雑になる
という問題があります。
terraform-provider-lambdazip
そこで、これらの問題を解決しterraformだけでLambdaの管理を行えるようにするため、terraformプロバイダーを自作しました。
- データソースではなくリソースなのでtriggersの変更がなければzipファイル作成処理が走らない
- before_createでzipファイル作成前の処理を指定できる
lambdazipプロバイダーを使って先ほどのlambda.tfを書き直すと次のようになります。
data "lambdazip_files_sha256" "triggers" { files = [ "lambda/app.js", "lambda/package.json", "lambda/package-lock.json", ] }
resource "lambdazip_file" "nyan" { base_dir = "lambda" sources = ["**"] output = "lambda.zip" before_create = "npm i" triggers = data.lambdazip_files_sha256.triggers.map }
resource "aws_lambda_function" "nyan" { function_name = "nyan" runtime = "nodejs20.x" role = "..." handler = "app.handler" filename = lambdazip_file.nyan.output source_code_hash = lambdazip_file.nyan.base64sha256 }
Go Lambda
社内のLambdaにはPythonやJavaScriptが使われることもありますが、私がLambdaを作成する場合は慣れているGoで実装することが多いです。
- npmやpipなどライブラリの同梱について考える必要がない
- 手元の環境でもCI/Atlantis環境でもデプロイ用のバイナリのクロスコンパイルができる
- Go 1.21以降で再現可能なビルドができるようになったのでソースコードの変更だけをトリガにデプロイできる
- 共有ライブラリへの依存を避けやすい
などがGo Lambdaの良い点です。
terraformでの定義は
/ ├── lambda.tf └── lambda ├── main.go ├── go.mod └── go.sum
data "lambdazip_files_sha256" "triggers" { files = ["lambda/*.go", "lambda/go.mod", "lambda/go.sum"] }
resource "lambdazip_file" "app" { base_dir = "lambda" sources = ["bootstrap"] output = "lambda.zip" before_create = "GOOS=linux GOARCH=amd64 go build -o bootstrap main.go" triggers = data.lambdazip_files_sha256.triggers.map }
resource "aws_lambda_function" "app" { filename = lambdazip_file.app.output function_name = "my_func" role = aws_iam_role.lambda_app_role.arn handler = "my-handler" source_code_hash = lambdazip_file.app.base64sha256 runtime = "provided.al2023" }
のようになります。
以下、業務で使用しているGo Lambdaの一例です。
例: リザーブドインスタンスの期限のメトリクス化
インフラコスト削減ためAWS RDSやOpenSearchのリザーブドインスタンスを利用しているのですが、AWS Cost Explorerが提供している期限切れアラートはEメールへの通知のみで、また7日前・30日前・60日前と決められたタイミングにしか通知を送ることができません。
カンムのインフラのアラートはほとんどがDatadogで管理されておりリザーブドインスタンスの期限切れアラートもなるべくDatadogに集約したい、また通知のタイミング以外にも複数のアカウントのリザーブドインスタンスの期限がどの程度迫っているのか簡単に把握したい、といったモチベーションがありGo Lambdaを使ってリザーブドインスタンスの期限をDatadogのメトリクスにしてみました。
main.go
Goの実装はGetReservationUtilization APIを呼び出して、Datadogにメトリクスを送るだけの単純なものです。AWS Organizationsの親アカウントでGetReservationUtilizationを呼び出すと、子アカウントのRIの情報を取得することができます。
package main
import ( "context" "fmt" "log" "os" "time"
"github.com/DataDog/datadog-api-client-go/v2/api/datadog"
"github.com/DataDog/datadog-api-client-go/v2/api/datadogV2"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/costexplorer"
"github.com/aws/aws-sdk-go-v2/service/costexplorer/types"
"github.com/aws/aws-sdk-go-v2/service/secretsmanager")
var ( TARGET_SERVICES = []string{ "Amazon Relational Database Service", "Amazon OpenSearch Service", } DD_API_KEY_FROM = os.Getenv("DD_API_KEY_FROM") DD_APP_KEY_FROM = os.Getenv("DD_APP_KEY_FROM") )
const ( METRIC_NAME = "costexplor.reservation.days_to_expiry" )
func main() { lambda.Start(HandleRequest) }
func HandleRequest(ctx context.Context, event any) error { now := time.Now() output, err := getReservationUtilization(ctx, now)
if err != nil {
return fmt.Errorf("failed to getReservationUtilization: %w", err)
}
if len(output.UtilizationsByTime) == 0 {
log.Println("No data")
return nil
}
utilizations := output.UtilizationsByTime[0]
for _, g := range utilizations.Groups {
endDateTime, err := time.Parse("2006-01-02T15:04:05.000Z", g.Attributes["endDateTime"])
if err != nil {
return fmt.Errorf("failed to parse endDateTime: %w", err)
}
daysToExpiry := endDateTime.Sub(now).Hours() / 24
if daysToExpiry < -10 {
continue
}
tags := []string{
"account_name:" + g.Attributes["accountName"],
"service:" + g.Attributes["service"],
"lease_id:" + g.Attributes["leaseId"],
}
submitMetrics(ctx, now.Unix(), daysToExpiry, tags)
}
return nil}
func getReservationUtilization(ctx context.Context, now time.Time) (*costexplorer.GetReservationUtilizationOutput, error) { cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
return nil, err
}
client := costexplorer.NewFromConfig(cfg)
input := &costexplorer.GetReservationUtilizationInput{
TimePeriod: &types.DateInterval{
Start: aws.String(now.AddDate(0, 0, -90).Format("2006-01-02")),
End: aws.String(now.Format("2006-01-02")),
},
Filter: &types.Expression{
Dimensions: &types.DimensionValues{
Key: "SERVICE",
Values: TARGET_SERVICES,
},
},
GroupBy: []types.GroupDefinition{
{
Type: "DIMENSION",
Key: aws.String("SUBSCRIPTION_ID"),
},
},
}
return client.GetReservationUtilization(ctx, input)}
func submitMetrics(ctx context.Context, ts int64, daysToExpiry float64, tags []string) error { ddApiKey, err := getSecretValue(ctx, DD_API_KEY_FROM)
if err != nil {
return err
}
ddAppKey, err := getSecretValue(ctx, DD_APP_KEY_FROM)
if err != nil {
return err
}
body := datadogV2.MetricPayload{
Series: []datadogV2.MetricSeries{
{
Metric: METRIC_NAME,
Type: datadogV2.METRICINTAKETYPE_GAUGE.Ptr(),
Unit: datadog.PtrString("day"),
Points: []datadogV2.MetricPoint{
{
Timestamp: datadog.PtrInt64(ts),
Value: datadog.PtrFloat64(daysToExpiry),
},
},
Tags: tags,
},
},
}
configuration := datadog.NewConfiguration()
apiClient := datadog.NewAPIClient(configuration)
api := datadogV2.NewMetricsApi(apiClient)
ctx = context.WithValue(ctx, datadog.ContextAPIKeys, map[string]datadog.APIKey{
"apiKeyAuth": {Key: ddApiKey},
"appKeyAuth": {Key: ddAppKey},
})
_, _, err = api.SubmitMetrics(ctx, body, *datadogV2.NewSubmitMetricsOptionalParameters())
if err != nil {
return fmt.Errorf("Error when calling `MetricsApi.SubmitMetrics`: %w\n", err)
}
log.Printf("Put metric value=%.2f tags=%v ", daysToExpiry, tags)
return nil}
func getSecretValue(ctx context.Context, secretId string) (string, error) { cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
return "", err
}
input := &secretsmanager.GetSecretValueInput{
SecretId: aws.String(secretId),
}
client := secretsmanager.NewFromConfig(cfg)
output, err := client.GetSecretValue(ctx, input)
if err != nil {
return "", err
}
return aws.ToString(output.SecretString), nil}
tfファイル
前述の通りterraformでLambdaを定義し、EventBridge Schedulerで一時間ごとにメトリクスを送信します。
data "lambdazip_files_sha256" "dd_ce_reservation_days_to_expiry" { files = [ "./lambda/dd-ce-reservation-days-to-expiry/main.go", "./lambda/dd-ce-reservation-days-to-expiry/go.mod", "./lambda/dd-ce-reservation-days-to-expiry/go.sum", ] }
resource "lambdazip_file" "dd_ce_reservation_days_to_expiry" { base_dir = "./lambda/dd-ce-reservation-days-to-expiry" sources = ["bootstrap"] output = "lambda.zip" before_create = "GOOS=linux GOARCH=amd64 go build -o bootstrap main.go" triggers = data.lambdazip_files_sha256.dd_ce_reservation_days_to_expiry.map }
resource "aws_lambda_function" "dd_ce_reservation_days_to_expiry" { function_name = "dd-ce-reservation-days-to-expiry" runtime = "provided.al2023" role = aws_iam_role.lambda_dd_ce_reservation_days_to_expiry.arn handler = "bootstrap" filename = lambdazip_file.dd_ce_reservation_days_to_expiry.output source_code_hash = lambdazip_file.dd_ce_reservation_days_to_expiry.base64sha256 timeout = 300
environment { variables = { DD_API_KEY_FROM = aws_secretsmanager_secret.datadog_DD_API_KEY.name DD_APP_KEY_FROM = aws_secretsmanager_secret.datadog_DD_APP_KEY.name } }
depends_on = [ aws_cloudwatch_log_group.lambda_dd_ce_reservation_days_to_expiry, ] }
(略)
resource "aws_scheduler_schedule" "dd_ce_reservation_days_to_expiry" { name = "dd-ce-reservation-days-to-expiry" schedule_expression = "rate(1 hour)" schedule_expression_timezone = "Asia/Tokyo" state = "ENABLED"
flexible_time_window { mode = "OFF" }
target { arn = aws_lambda_function.dd_ce_reservation_days_to_expiry.arn role_arn = aws_iam_role.dd_ce_reservation_days_to_expiry_schedule.arn } }
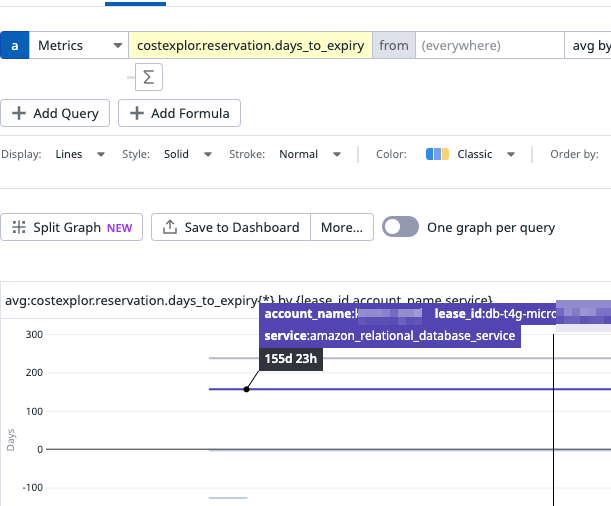
表示例
Datadogでメトリクスを表示すると、どのアカウントのどのRIがどの程度残っているのかが一目でわかります。
まとめ
terraformでGo Lambdaをデプロイできると、ちょっとした処理をバッチ化するのがとても楽になり、インフラ環境の改善が進みます。 さらにAtlantisとの組み合わせで、PR上でLambdaのデプロイが可能になり、開発体験も非常に良いです。
今後も引き続き環境の改善に務めていきたいところです。
エンジニアの佐野です。バンドルカードではポチっとチャージという後払いの機能を利用する際に年齢確認が必須となりました。通信キャリアや銀行との連携等によって年齢確認ができるようになっています*1。今回はこの機能の開発を題材に普段開発でどのようなことを考えて開発し、本機能の開発ではどのようなフローを構築して進めていったかを書きます。
少し概要を書くと、本件についてはウォーターフォールモデル "のような" 開発フローで行いました。事業上の理由でビッグバンリリースが必要でした。要件をしっかり決めてステップバイステップで開発を行いすべての機能を同時にリリースする...案件の性質を考えるとウォーターフォールが開発フローの候補の1つだと思っていたためです。ただそのまま一般的に思われているウォーターフォールを導入するのではなく、その欠点や面倒な点を解消しつつ、認識齟齬なしに設計と実装を行い、納期を死守しつつ、バグを最小限に抑えて一撃で出すにはどうするのが最適かを考える必要がありました。本記事ではその開発の計画、DB設計やシーケンス図のような各フェーズの成果物、実装方法、テスト、リリースについて書ける範囲で書きます。本件のバックエンド側はやることは比較的単純(後述しますが、簡単に言うと連携先から生年月日を取得して突合する)なのですが、リリースが遅れたりリリース後にバグると収益にかなりのダメージがある案件でした。
自分がエンジニアということもありPdM、デザイナー、エンジニアといった製作サイドの話、特に開発計画とバックエンドの話がメインになりますが、製作サイド以外の部署 (事業開発、法務、セキュリティ、CS、データ分析チーム...etc)ももちろん存在しており、リーガルチェックや連携先を含む関連各社との交渉、LP 作成やオペレーション体制の構築などに尽力してくれました。書きっぷりから私が PJ を主導して成功に導いた...ことを大々的に書いているかのように見えるかもしれませんが、自分の視点から見た PJ の進め方と要所要所で考えていたことや実際に起きたことの記録だと思ってもらえるとよいです。
- 年齢確認についての前提知識
- ウォーターフォールを考える
- 開発フロー
- 各フェーズの説明
- まとめ
1. 年齢確認についての前提知識
バンドルカードはユーザ新規登録時に生年月日を入力することになっています。この時点では自己申告の生年月日です。ポチっとチャージを利用する際はその生年月日の正当性チェックを必須とするのが今回の案件です。正当性が認められたユーザは「年齢確認済」となります。ポチっとチャージを利用する際、そのユーザが年齢確認済かどうかをチェックします。年齢確認済でなければ通信キャリアや銀行との連携等による年齢確認を促します。通信キャリアや銀行と連携する際の模式図を描くと次のような形となります。

通信キャリアおよび銀行は一般的な OIDC もしくは独自の認証・認可の仕組みを持っています。年齢確認を実施する際、バンドルカードはユーザをそれらのサイトにリダイレクトさせ、個人情報の連携に同意していただきます。それによって各社に格納されているユーザの個人情報を取得し、新規ユーザ登録時に入力された生年月日と突合することで年齢確認を行います。冒頭にも書きましたが要件としてすべての連携先を同日にリリースし、アプリの強制アップデートで全ユーザに年齢確認を提供します。いろいろな事情がありカナリアリリースや連携先を1つずつ解放することはできない案件でした。
2. ウォーターフォールを考える
話がだいぶ逸れてしまうのですが、ウォーターフォールと呼ばれている開発モデルの歴史や誤解について語っておきます。記事の頭で「ただそのまま一般的に思われているウォーターフォールを導入するのではなく、その欠点や面倒な点を解消しつつ...」と書いたように、自分の経験上、ウォーターフォールで失敗した過去や、もちろん成功した過去もあるため、これを機にウォーターフォール含め開発フローを再考して今回の PJ に活かします。
ウォーターフォールやらアジャイルやら開発フローについては「どうやってもうまくいくときはうまくいくし、ダメなときはダメ」と冷めた目で見ていた節もあるのですが...ちょっと真面目に考えてみようと思いました。
2.1 多くの人がウォーターフォールと呼んでいるもの
ウォーターフォールというのはなんなのか、ですが、多くの人は以下の様な図をイメージするかもしれません。使っている言葉に揺れはありますが概ねこのような流れで行われます。谷底に開発(コーディング) を挟んで V 字で図示して V モデルと呼ぶこともあります。双方向矢印は左側の設計フェーズと対応するテストフェーズを紐付けています。

特徴としては以下の通り、あえて悪評のようなものをここでは羅列しておきます(後で回収します)。
- 前のフェーズへの手戻りは行わない (が、往々にして要件定義の変更が後から行われてしまい大規模な巻き戻りが発生することがある)
- 各フェーズで膨大な成果物が必要
- 多くの人が嫌っている (玄人感を出したいからかとりあえず否定するワナビーもいる)
私は SI に従事していたときは疲弊した記憶はあります。ただまったくダメというイメージはありません。
ここでウォーターフォールという言葉がこの世に登場したとき、それはこのようなものを指していません。
2.2 元祖ウォーターフォール
ウォーターフォールモデルの歴史を掘っていくと次の様な文献が見つかります。
- Production of Large Computer Programs HERBERT D. BENINGTON 1956
- MANAGING THE DEVELOPMENT OF LARGE SOFTWARE SYSTEMS Dr. Winston W. Royce 1970
- SOFTWARE REQUIREMENTS: ARE THEY REALLY A PROBLEM? T. E. Bell and T. A. Thayer TRW Defense and Space Systems Group Redondo Beach, California 1976
- SOFTWARE PROCESS MANAGEMENT: LESSONS LEARNED FROM HISTORY Barry W. Boehm 1987
時系列に並べています。1が1956年の論文で SAGE*2 を開発する際の技術について述べられています。そこで次のような図が出てきます。
 Production of Large Computer Programs HERBERT D. BENINGTON 1956
Production of Large Computer Programs HERBERT D. BENINGTON 1956
計画 -> 仕様策定 -> コーディング ... -> システム評価 の順に進む。V 型のウォーターフォールの図のように、コーディング (実装)を谷底として各フェーズのテストが行われています。見たことある図に近いですね...。
With SAGE, we were faced with programs that were too large for one person to grasp entirely and also with the need to hire and train large numbers of people to become programmers.
一人では把握できない巨大なプログラムに直面したこと、そして大量のプログラマーを採用してトレーニングする必要があった、と書かれており、これがこの開発手法の背景にあったと思われます。
続いて1970年にロイス博士の論文 MANAGING THE DEVELOPMENT OF LARGE SOFTWARE SYSTEMS が登場します。この論文では次の様なことが述べられています。
- すべてのプログラムには解析・分析(要求分析のようなことを表しているのだと思う)とコーディングという2ステップが存在する。複雑さやサイズにかかわらずそれが基本である。
- 小規模プログラムではそれで十分だが大規模開発では追加のステップが必要である。(要件定義、設計、テスト...)
- テストフェーズが最後の方にあるのでそこで問題が発見されると大幅な設計変更、つまり巻き戻りが発生することがある。
- ↑を軽減するために予備プログラム (A preliminary program design phase プロトタイプのことかな...)を作る、ドキュメントをがっつり書く、2回作れ (Do It Twice)、テストの計画と管理をする、顧客を関与させる
みなさんが知っているウォーターフォールについて1956年の論文のような図を引き合いに出し、その問題点と解決策を提唱しています。この時点でプロトタイピングや反復開発の概念について言及しています。それを図にしたものが次です。かなり複雑に見えます。
 MANAGING THE DEVELOPMENT OF LARGE SOFTWARE SYSTEMS Dr. Winston W. Royce 1970
MANAGING THE DEVELOPMENT OF LARGE SOFTWARE SYSTEMS Dr. Winston W. Royce 1970
そして3の1976年の論文 SOFTWARE REQUIREMENTS: ARE THEY REALLY A PROBLEM? で次の一節、
The same top-down approach to a series of requirements statements is explained, without the specialized military jargon, in an excellent paper by Royce [5]; he introduced the concept of the "waterfall" of development activities.
ここで初めてウォーターフォールという文字が登場します。引用の [5] はロイスの2の論文を指し示しています。ウォーターフォールという言葉が出現したとき、それはプロトタイピングや反復開発の概念があるスタイルのものを指しています。みなさんが思っているものと違うものが「ウォーターフォール」と呼ばれています。
ではなぜこんにちの Vモデルのようなものであったり、巻き戻りはしない、という考えのものがウォーターフォールと呼ばれるようになったのかですが正直わかりません (掘れていません)。1987年の4の論文では「3の論文では2の論文がウォーターフォールであると言っているが、実際は1なんじゃないの?」と書かれていて、たしかに実際にみなさんが思うウォーターフォールはこちらの方が近いと思います。しかし1の論文はウォーターフォールとは呼ばれていません。
とりあえずですが、ウォーターフォールについては歴史的観点から細かいことを言うと現代のウォーターフォールはウォーターフォールではないと言えるかもしれません。
2.3 元祖ウォーターフォールから得るヒント
物事を真似する、参考にするにはその背景や再現性を考慮する必要があります。「一人では把握できない巨大なプログラムに直面したこと、そして大量のプログラマーを採用してトレーニングする必要があった」ようなことが書かれていたとおり、ウォーターフォールは超大規模向けに考案されたというのが背景にあります。今回の案件はそのような規模ではありません。しかしいくつか取り入れるべきヒントがあります。
- 2回やれ
元祖では全フローをもう一回繰り返せ...ということを言っています。我々は全フローではなく、巻き戻るとダメージの大きい要件定義と一部の設計を2回やることにします。軌道修正するフェーズを最初から設けておきます。
- テスト計画と管理を行う
テスト計画を要件定義の次くらい、設計の前段くらいに作り上げ、それをもとにテスト時の人員と資材を計画しておきます。テスト項目表 (=期待動作一覧表) も並行して先に作っておきます。すべてのケースの期待動作を洗い出し、それを設計、実装、そしてもちろん QA テストの前段の成果物にするという思惑です。これはテストフェーズが最後の方にあるのが問題点である、というものを解消するためです。なるべく早い段階からバグの芽を摘み取れるようにテスト項目を早い段階から作り、それを正解の仕様としてテスト駆動で開発を進められるようにします。
これは当たり前...だと私は思っていますが、ちゃんとドキュメントを書きます。エンジニア向け、エンジニア以外のチーム向けを意識したものを成果物として出します。
ちなみにこのドキュメント業なのですが...たまにドキュメントや資料の類いは無駄、不要と言う人々が存在しており、私とは全く考えが合わないのですが、少なくとも顧客に提供して長く運用を回す前提の業務アプリケーションはドキュメンテーション必須だと思っています。エンジニアチームとしては設計レビュー、コードレビューで必要になります。例えばコードレビューですが、ドキュメント不要と言っている人はコードの何を見ているのか...というのは非常に気になります。ソースコードのみてくれを確認しているとは思いますが、コードが仕様通りに書かれているかどうかを確認するのはレビューのはずで、例えばある条件のときに true を返すテストコードとその関数の実装のセットがあったとして、それ自体が正しいのか?は前段の design doc がないと判断ができないはずです。これがそのままスルーされて外部結合テストのような後続のフェーズで見つかると面倒な巻き戻りが発生し、またドキュメントがないことでバグなのか仕様なのかがわからずドツボにハマります。
昔の同僚にも不要派がいて、彼らの話を聞くとドキュメントを永遠に更新し続けるのは無理だしソースコードとドキュメントに齟齬が出る、と言うのですが、それに対しては私は対策をしています。それは設計ドキュメントと運用ドキュメントは別にすること、ドキュメントに寿命を設けること、です。設計用ドキュメントですが、必要になるのはエンジニア以外が含まれるチームでの仕様の確認時、そしてエンジニアチームで行う設計レビューとコードレビュー時です。その寿命は最初のリリースが終わるまで、とします。つまり最初のリリースが終わるまでは仕様変更や巻き戻りによってドキュメントの更新はしますが、リリースが済んだらもうそれはお役御免とします。資料として残しはしますが、有効期限は最終更新日としてそれ以降の変更についてはシステムの方が正しい、とします。設計用ドキュメントは1stリリースまでの仕様確認用であり設計レビュー用であると割り切ります。
運用ドキュメントはいわゆる Runbook のようなものであったり、CS チーム用に作る問い合わせ指南書のようなものです。こちらは運用とともに育てていく前提で永遠に更新します。Runbook を更新したり書くのが面倒であればそれこそ Runbook が不要となるようにシステムを改善すれば良いです。コードを書いて直しましょう。そうすればいくらかの運用ドキュメントは消滅させることができます。
寿命についてはドキュメントを書くのがしんどいというのであればそのハードルを下げればよいという考え方です。受託開発であれば話は別ですが、納品が発生しない前提であれば軽い口調の書き方や多少の表記揺れやミスがあっても気にしなくてもよいはずです。
ミドルウェアの開発やライブラリの開発であったり、エンジニア同志の口頭の意思伝達で済ませているチームの場合は本当に自然言語のドキュメントが必要かどうかはわかりません。私は逆にそのような組織に属したことがないので...。
この節では私の主張が少し(だいぶ?)入りました...。
3. 開発フロー
さて、長ったらしいウォーターフォールの話から元に戻りまして...開発の条件は次の通りです。
- 製作サイドのメンバー数人 (元祖ウォーターフォールの想定のような人数規模ではない)
- ビッグバンリリースが必要
- リリースでバグがあったら会社として結構マズい
以下がその際に実際に行われたフローです。上述のヒントや先人達の与えてくれた教訓を盛り込み次のようになりました。ちなみに図自体は今作った後付けです。PJ発足時に「俺はこう考えている」というのをちゃんと示しておいた方がよかったかもしれない...。
3.1 考案した開発フロー
時系列は概ね左から右です。双方向矢印は工数として考慮済の手戻りを表しています。実装と設計を行き来しないわけがない、テストでバグが見つかって実装に手戻りが発生しないわけがない、というような...。

3.2 現実の開発フロー
ここで現実を書いておきます。計画通りにいったら苦労はしない。

赤入れした部分が計画崩れした部分や想定と変わってしまった部分です。
- 連携先との疎通テスト: 連携先との疎通確認は早々に終わらせてしまい、インフラ面でのハマりは早々に解消したかったのですが...。TCP/IPレベルでの疎通はある程度はできたもののアプリケーションレイヤでの疎通は QA テストのときにいきなり結合する形となってしまった。そしてそこで早めに疎通試験できていれば見つかったであろうバグを見つけるなど...。
- ER図とアプリ/サーバ間のAPI: これは元から手戻りはあるだろうと思っていたが本当にちょっとしたミスで手戻りがあった。APIが1本足りなかった、連携先から取得した生年月日は保存しない算段だったが保存が必要だった、etc...。図を見てわかるとおりシーケンス図は2回やったこともあり手戻りはほとんどなく、ここで「2回やれ」の効果が奇しくも出ることになった(2回やったから大丈夫だったと言い切ることはできないが)。
- 一部仕様変更: とある連携先だけ年齢確認時の挙動を変えることになった。こちらも幸いダメージは少なかったが...。
- リリース: ビッグバンリリースはいうことになっていたがとある連携先だけ先出しする形になった。ちなみにこれはいくつかの連携先の開発が遅れているので先に出せるところだけ...といったネガティブな理由ではなく、むしろ先に一部の連携先を開放してユーザにインセンティブを付与する+ユーザの反応や動きを先に分析したいという戦略上の要因です。
- 俺の離脱: そう俺が PJ から外れる。他案件の兼ね合いで。QAテストの前あたり。各社との連携の実装までは完了したが、後から追加で出現した年齢確認手段の要件定義〜設計〜実装、QAテスト以降のフェーズを残して俺がこの案件からいなくなった...。フェーズが巻き戻ることや想定外の要件が後から出てくるといったようなものは気にしていたのですが、メンバーチェンジ...まあそれもあるっちゃあるか、と思ってはいたがそしてそれが割とメインの自分...うーむ、これはさすがに考えていなかった...。自分が離れたあとのバグの発生がチャットに流れてくるとすまねえなあ...と、なんとも言えない気持ちになるなど...入れ替わったメンバーが完遂してくれました。
4. 各フェーズの説明
以下、それぞれのフェーズで何を行い、どのようなことを考えていたかを書きます。ここから先は多少はテクニックの話も出てきます。
4.1 要件定義 (1回目)
まずはやりたいことを PdM にまとめてもらいます。こちらについては PJ キックオフ前から経営層と PdM が水面下で進めていました。自分の進言としては、上のフロー図のとおり、連携先の仕様確認と画面設計のあとにこれをやり直す (再精査する)べきであると告げました。この時点ではどのような開発フローで進めるかはふわふわしていました。
4.2 画面設計 (1回目)
チーム内では仮UIと呼んでいました。こちらも後続のフェーズからフィードバックする前提のアイテムです。まずは素直に我々が実現したいこと (≠できること)を図にします。
4.3 連携先仕様調査
1回目の要件定義と仮UIこと画面設計をやりつつ連携先の仕様書を精読します。最初に仕様書読めば?という人がいるかもしれませんが先方の仕様書も膨大です。やりたいことを決める -> やりたいことに関連した箇所を読んで実際にできるかどうかを調べる、といった流れで要件定義と仮UIにフィードバックします。この仕様書からインフラ設計に必要な情報や非機能要件も読み取っておきます。また先方に質問を投げるなどして仕様の確認をする、結合テストする際の制約事項*3のスケジュールについても洗い出しておきます。
4.4 シーケンス図 (1回目)
仕様書の情報から1回目のシーケンス図を書きます。ここでは要件定義と画面設計にフィードバックするという目的があるのでそれを意識した書きっぷりにします。粒度としても細かいパラメータの表記は最低限として、PdM などエンジニア以外の職種にも理解してもらえる表記にします。以下のような成果物です。図そのものも重要ですが「※」マークで書いた箇所、「これを決める必要がある」「この画面が追加で必要である」「こういう遷移を考慮する必要がある」といった情報を洗い出します。


4.5 要件定義 (2回目)とスケジュール決め
仕様調査と仮UI、先ほどの1回目のシーケンス図をもとに再度要件定義を行います。ここでスケジュール線表も引きます。線を引くのが私、バックエンドの人間ということもあり、バックエンド観点のものになってしまうため、他メンバーともすり合わせをします。またここで引いたスケジュールは我々製作サイドの考えたスケジュールでもあるのでこれを PdM から経営層にぶつけてもらい、そちらともすり合わせを行います。
ところでものの本によると一流は納期を決めないらしいですが私は三流なので納期は決めます...。と、まあ人様の本を揶揄するつもりはなく、カンムのこの PJ では会社としてリリース日に大きな意味がありました。ということでこちらの案件については納期を決めて守る必要がありました。納期に大きな意味がなければ自分も、完成したら出します、くらいにするかもしれません。
4.6 画面設計 (2回目)
必要になった画面をデザイナーおよびフロント担当にフィードバックして画面遷移図を再描画します。
4.7 期待動作洗い出し
これがコアです*4。仕様書の読み込みからシーケンス図(1回目)を描き、要件定義、画面設計の精度が高まったらここで正常系、準正常系、異常系すべての期待動作を洗い出します。ある状態のユーザがある端末である操作を行ったときの、画面遷移、DBの状態変化まで洗い出しておきます。DB 設計はこの後段のフェーズで行うのでここでは「年齢確認済となる」というような表現になっています。

これは設計のインプットであり実装のインプットであり QA テストのテスト項目であり...すべての動作を網羅した仕様書になります。CS チームにも共有することで何が仕様で何がバグかを明らかにすることもできます。今確認すると150パターンほどありました。大変ではありますが事前に苦労しておくには十分価値のある大変さではあります。複雑な案件ではさらにパターンが増えるでしょう。
4.8 連携先 API クライアント&モック開発
こちらについては連携先の仕様書が手に入り次第単独で取りかかれるアイテムです。1回目の要件定義が完了すればやろうとしていることの概略はわかるので、それを実現するためのクライアントを早々に書き始めます。Testability を上げるため、またサーバ本体に組み込んだときに実際に連携先と接続しなくても動かせるようにモックできるようにしておきます。これはあたりありふれた手法でありここで改めて言うほどのことではないとは思いますが...。
type TokenRequester interface { Request(ctx context.Context, tokenEndpoint, code string) (*TokenResponse, error) }
type TokenClient struct { ... }
func NewTokenClient(config *TokenConfig) TokenRequester { return &TokenClient{ ... } }
func (c *TokenClient) Request(ctx context.Context, tokenEndpoint, code string) (*TokenResponse, error) { ... }
4.9 インフラ設計
連携先の仕様書をインプットとしてインフラ設計を行います。先方から配られるクレデンシャルであったり、セキュリティ面などの非機能要件や接続要件をインフラに落とし込みます。また本 PJ ではこちらのシステムの情報を先方に出す必要もあったためそれもこのフェーズでまとめておきます。
4.10 インフラ構築
実際の構築です。今回はそれほど土台の工事は必要ではありませんでした。概ね以下のような作業でした。
4.11 連携先との疎通テスト
先にやってしまおうと思っていた疎通テストです。上の方にも書きましたが当初の計画よりかなり後ろのフェーズでの確認になってしまいました。QA テストのタイミングで以下のようなバグが見つかるなど...。
- 連携先の仕様書に変更があり通信時に応答が返らない (変更に気づかず...)
- 単純に自分の書いた API クライアントにミスがあった
4.12 シーケンス図 (2回目)
今度のシーケンス図の粒度は自分以外のエンジニアとセキュリティエンジニアが理解できるように書きます。レビュー待ちが開発のボトルネックにならないようにするため、本PJに参画していなくてもコードレビュー可能なよう、この設計図自体もレビューにかけつつ、PJ外メンバーには内容を理解してもらいます。
「おおまかなシーケンス図」がシーケンス図(1回目)のことで「期待動作」がその名の通り期待動作洗い出しの成果物です。これらをインプットとして数々のパターンを網羅する形でシーケンス図を書きます。

4.13 ER図
期待動作洗い出しで DB の状態が定まったらデータチームからの要件も盛り込んで DB 設計を行います。ポイントとなるテーブルだけ抜き出すと次の様な設計としました。

- ユーザ: 既存テーブル。このテーブルには変更なし。
- 年齢確認リクエスト: 新規作成。どのような年齢確認手段(銀行、通信キャリア)においても必ず作られる。年齢確認の起点となるテーブル。ユーザは何回も年齢確認を行う可能性があるため、ユーザ:年齢確認リクエスト = 1:N となる。
- 年齢確認リクエスト_手段A_固有情報: 新規作成。それぞれの年齢確認手段を行う際の固有のデータを格納するテーブル。年齢確認リクエストは各手段で0回(途中でアプリを落とすなど)または1回行われるため年齢確認リクエストと1:0..1。
- 年齢確認リクエスト_手段A_実施: 新規作成。実際に年齢確認処理を行った際に記録されるテーブルで、
年齢確認リクエスト_手段A_固有情報と JOIN することでリプレイアタックが行われたかのチェックにも使う。年齢確認リクエストと1:0..1。 - 年齢確認リクエスト_手段A_取得した生年月日: 新規作成。連携先から取得した生年月日を格納するテーブル。年齢確認リクエストと1:0..1。
- 年齢確認_生年月日差異: 新規作成。連携先から取得した生年月日とカンム側に格納されているユーザの生年月日が異なっていた場合に作られる。年齢確認リクエストと1:0..1。
- 年齢確認_完了:新規作成。連携先から取得した生年月日とカンム側に格納されているユーザの生年月日が一致していた場合に記録される。年齢確認リクエストと1:0..1。
ポイントは以下の通り。
- 積み上げ式とする: 自分がこのような設計を好んでいるというのもありますが delete と update はしない方針とします。insert で状態を表現していきます。これはデータは存在していることに価値があるためです。ユーザ分析の要件としてもユーザがどの手段でどこまで年齢確認を進めたか?(ex: ある通信キャリアで途中まで進めたが離脱、後に銀行で年齢確認を試みて成功、など...)を知る必要があるためユーザの行動をトレースできるような設計としておきます。
- 年齢確認手段が増えた際に対応できるようにする: 拡張性です。実は本人確認書類のアップロードによる年齢確認も可能なのですが、 PJ 発足当時はやるかやらないかが揺れていて、後続のフェーズになってようやく「やるかも?」くらいの状態になっていました。ここで本人確認書類のアップロードを含め、新しい年齢確認手段が増えたら手段Bのような形で年齢確認リクエストテーブルを起点にリレーションを生やす戦略としました。
投げる SQL とインデックスもここで示しておきます。テーブル設計は済んだが SQL が無茶になりすぎたら厳しい気持ちになるのでここで面妖な SQL にならないかの確認もしておきます。
4.14 アプリ/サーバ間の API 設計
バンドルカードのアプリとサーバの間の API 設計を行います。期待動作洗い出しとシーケンス図 (2回目) をインプットに API スキーマを考えます。上の図で「アプリ/サーバ間の API 設計」が ER 図とシーケンス図と同列になっているのは間違いですね...。
4.15 セキュリティレビュー (設計編)
1回目のセキュリティレビューを行います。シーケンス図、ER図、API設計をセキュリティエンジニアに見てもらいます。連携先の仕様書にセキュリティガイドラインも書かれているケースもあるので、それをクリアできているかどうかもチェックしてもらいます。

設計のタイミングでセキュリティエンジニアに入ってもらうのはとてもよいです。セキュリティエンジニアに最初からこのタイミングでレビューをしてほしいので工数もらっていいですか?と声をかけておいてよかった。
4.16 実装
セキュリティレビューのフィードバックを設計に盛り込むと、期待動作、各種設計、連携先のAPIクライアントが出揃います。ここでようやく本体の実装が可能になります。例えば年齢確認を実行する API エンドポイントについて、あらかじめまとめた期待動作を網羅する形でテストを書いていきます。期待動作をまとめてあるため比較的容易に TDD を行うことができます。このテストをパスするように本体の実装を書くことで、PdM やデザイナーやフロント担当などチーム内で決めた期待動作を実装の時点で結構な割合で保証することができます。
t.Run("誕生日一致", func(t *testing.T) {
...
res, err := executeAgeVerificationRequestDocomo(ctx, app, queryParams)
assert.NoError(t, err)
assert.Equal(t, constant.AgeVerificationSuccessURL, res)
status, err := service.GetAgeVerificationRequestStatusByRequestIDAndUserID(ctx, tx, avr.ID, avr.UserID)
assert.NoError(t, err)
assert.Equal(t, constant.AgeVerificationRequestStatusCompleted, status)
avred, err := model.GetAgeVerificationExecDocomoByPkContext(ctx, tx, avr.ID)
assert.NoError(t, err)
assert.NotNil(t, avred)
t.Logf("age_verification_exec_docomo: %+v\n", avred)
diff, err := model.GetAgeVerificationBirthdayDiffDetectionByPkContext(ctx, tx, avr.ID)
assert.Error(t, err)
assert.Nil(t, diff)
t.Logf("age_verification_birthday_diff_detection: %+v\n", diff)
completion, err := model.GetAgeVerificationCompletionByPkContext(ctx, tx, avr.ID)
assert.NoError(t, err)
assert.NotNil(t, completion)
t.Logf("age_verification_completion: %+v\n", completion)
userInfo, err := model.GetAgeVerificationIdentificationDocomoByPkContext(ctx, tx, avr.ID)
assert.NoError(t, err)
assert.NotNil(t, userInfo)
t.Logf("age_verification_identification_docomo: %+v\n", string(userInfo.UserIdentificationData))
bd, _, err := service.GetAgeVerificationBirthdayDocomoByRequestID(ctx, tx, avr.ID)
assert.NoError(t, err)
assert.Equal(t, time.Date(2001, 4, 1, 0, 0, 0, 0, time.UTC), bd)
}
t.Run("誕生日不一致", func(t *testing.T) {
...
}
t.Run("認証セッションがタイムアウトした", func(t *testing.T) {
...
}
t.Run("ユーザが同意しなかった", func(t *testing.T) {
...
}
t.Run("情報が存在しなかった", func(t *testing.T) {
...
}
t.Run("法人契約端末が使われた", func(t *testing.T) {
...
}
t.Run("レスポンスが返ってこなかった", func(t *testing.T) {
...
}
t.Run("メンテナンス中", func(t *testing.T) {
...
}4.17 セキュリティレビュー (実装編)
セキュリティのプロに実装の方も目を通してもらいます。セキュリティホール、ログに出したらいけないものを出そうとしていないか、セキュリティレビュー (設計編) で指摘された事柄がクリアされているかを確認してもらいます。
4.18 QA テスト
度々登場する期待動作一覧の表をもとにひたすらテスト -> 修正を繰り返します。このフェーズの前あたりに自分は離脱...。横目でバグの発生を見ながら申し訳ない気持ちになるなど...。
4.19 リリース
もはや私はいないのですが PdM がリリース体制を構築してくれました。対ユーザ向けにはバグなしで機能を提供できたはずです。 最終的なリリース日時について「その日・時間帯は避けろ」と横から口出しをしたくらいです。
5. まとめ
開発フローに以下のようなことを導入して一定の効果が得られました。
- ウォーターフォールを見直して先人のヒントを盛り込むことである程度円滑に PJ を進めることができた。
- 「2回やる」を局所的に導入した。局所的な導入でも今回については効果があり、要件定義の考慮漏れが回収された。
- 早い段階からテスト計画を練り、期待動作の一覧を網羅したものを作った。その期待動作一覧を正解の仕様として設計、実装、リリース後の仕様/バグ確認として活かすことができた。
- 上記により TDD が容易になった。
- セキュリティレビューを早い段階から2回行い、セキュリティの観点からの修正を早期に行うことができた。
カンムのチーム環境としては以下の通りです。PJ運営をする際に製作サイドから見てしがらみが少なかったのは開発フローの柔軟性に大きく寄与されていると思われます。
- 職種間のパワーバランスがそこまで大きくなく要件を決めたりスケジュールを引く権限が現場にあった
- 開発スタイルは担当者に委ねられている
- 必要に応じて各職種を巻き込むことができる
開発フローの策定においては開発するものの特性、難易度、規模、チームの状況、会社の事情、自社内と他社を含んだステークホルダーのパワーバランス、個々のスキル...といったパラメータが複雑に絡み合っています。これらを考慮して最適なフローを構築することが必要です。世の中によく知られた既存の開発フロー、例えば本記事でも挙げたウォーターフォールですが、半世紀以上前に考案されたものをそのまま適用するのは無理があります*5。当時の状況を鑑みて再現性を考慮する必要があります。今回の我々の PJ もたまたまうまく適合したのかどうかは振り返りを行い、成功に再現性のある事柄は他チームに展開するなどして自チームにあったスキームを育てていく必要があります。
おわり
先日、React Native Japanと一緒に開催した「React Native Meetup #17」のイベントレポートをお届けします!前回に引き続き、今回もたくさんの方にご参加いただき、賑やかな会になりました。

皆さんのご参加、本当にありがとうございました。それぞれの発表者が共有してくれた経験や知見のおかげで、懇親会までとても充実した時間を過ごすことができました。

発表内容のご紹介
@mtry さんの「EAS Custom Buildを使ってビルドの開始/完了をSlackに通知する方法」
@mtry さんは、EAS Custom Buildを使ってビルドの進捗をSlackに通知する仕組みを発表してくれました。弊社ではExpoは使用しておらず、EAS Build自体の知見が少ないので、非常に興味深く聞かせていただきました。ぜひチェックしてみてください。詳しくはこちらからどうぞ!
@katayama8000 さんの「Rustで作ったExpo Push Notification Clientが公式ドキュメントに掲載された話」
@katayama8000 さんは、Rustで作ったExpo Push Notification Clientが公式ドキュメントに掲載されるまでのプロセスを発表してくれました。Discordでの地道な活動を重ね、少しずつコミュニュケーションを取っていく過程に苦労が垣間見え、とても引き込まれる内容でした。
@kondo_script さんの「React Nativeで防衛戦をする方法」
@kondo_script さんは、React Nativeを使ってプロジェクトの品質を守るための具体的な方法について発表してくれました。ビジネスとの合意形成や、内部品質を泥臭く保守する様子など、非常に共感できる実践的なアプローチが紹介されました。詳しくはこちらもご覧ください。
@hiraikyo さんの「React Native + Cloudflare Workerで個人開発アプリを作る話」
@hiraikyo さんは、React NativeとCloudflare Workerを使って個人開発アプリを作り上げた一連の流れを紹介してくれました。企画から設計、実装までのプロセスを通じて、個人開発ならではの面白さが詰まった内容でした。詳しくはこちらをご覧ください!
余談
今回のイベントにあたり、前回の開催後に課題の洗い出しを行い、少し設備やフローを整えました。その結果もあって、メンバーが前回の経験を活かし準備がすごいスピードで進んでいたり、設営と同時にドキュメントが出来上がっていたりしました!

まだまだ不便をかけてしまった部分や課題はありますが、今後も様々な社内イベントが円滑にできるように改善を繰り返していこうと思います。
最後に
今回も無事にイベントを進行でき、スポンサーとして参加できたことに大変感謝しております!ご参加いただいた皆さん、スピーカーの皆さん、そしてサポートしてくれたReact Nativeコミュニティやスタッフの皆さん、本当にありがとうございました!
カンムではフロントエンドエンジニアを募集中!
カンムでは現在、フロントエンドエンジニアを募集しています。「お金の新しい選択肢をつくる」というミッションに共感していただける方、ぜひ一緒に働きませんか?興味のある方はお気軽にご連絡ください!
バンドルカードのバックエンドエンジニアをしているshibaです。生粋のiPhoneユーザです。
昨年の10月頃にバンドルカードは Google Pay に対応しました。少し遅くなってしまいましたが、 Google Pay 対応について簡単に紹介したいと思います。なお、 Google Pay というアプリ名は2023年3月頃からGoogle ウォレット に変更され、 Google Pay はGoogle ウォレット 内の1機能という扱いになっています。
Google Pay について
まず、 Google Pay や、 Google Pay を使った決済の仕組みについて簡単に紹介します。
まずバンドルカードの説明になりますが、バンドルカードのアプリをインストールし、電話番号を使ってアカウント登録することで、バーチャルカード(オンラインのみで利用できるプリペイドカード)を即時発行することができます。 Google Pay 対応以前は、バンドルカードを実店舗で利用するにはリアルカードもしくはリアル+カードと呼ばれる物理カードの発行が必要でした。物理カードを発行するには発行費用や諸手続きが求められ、加えて、カードが家に届くまで待つ必要がありました。しかし、今回 Google Pay に対応したことによって、バンドルカードのアプリをインストールしてアカウント登録後、 Android 端末に搭載されている Google Pay にカードを登録することで、物理カードを発行する必要なく、すぐに実店舗で Google Pay を通したVisaのタッチ決済ができるようになりました。アプリをインストール後すぐに実店舗で決済できるというところは、バンドルカードと Google Pay の素晴らしい体験だと感じています。
続いて、 Google Pay を使った決済の仕組みについて紹介します。Google Pay を利用しない従来の決済であれば、PAN(カード番号)を含んだ決済データが加盟店様からVisa様のネットワークを通して弊社のようなカード発行会社に連携されます。一方、 Google Pay を使った決済では、PANではなく、トークンと呼ばれる、カードに紐づく一意なIDを含む決済データが連携されるようになります。トークンは、 Google Pay にバンドルカードを登録する際にVisa様を介して発行され、 Google Pay にはPANではなくこのトークンが格納されています。Google Pay を使った決済では、PANの代わりにトークンが加盟店様からVisa様に連携され、弊社のケースではそこから、Visa様がトークンをPANに変換した上で決済データが弊社に連携される仕組みになっています。Google Pay を使ったフローの全体像としては次のようになります。

PANの代わりにトークンを使うメリットですが、最も大きいのは漏洩時のリスクを抑えられることだと考えています。Google Pay に格納されるトークンは、カードを登録した特定の Android 端末および特定のGoogleアカウントに紐づいているため、 Google Pay に格納されているトークンの番号が仮に漏洩したとしても他の端末では決済ができないはずです。(実際に試したわけではないため、この情報の信憑性は担保できていません。)Visa様のネットワークまでの経路においてPANではなくトークンでやりとりされることは、カード所有者にとって非常に安全で良い体験だと感じています。
Google Pay 対応について
Google Pay に対応するにあたって、弊社が対応した内容を簡単に紹介します。バンドルカードを Google Pay で利用できるようするためには、大きく次の2つの要件を満たす必要がありました。
- カードに紐づくトークンの発行を可能にすること
- Visaのタッチ決済を処理できるようにすること
まずトークンの発行を可能にするために行なった弊社の対応について説明します。先に説明しましたが、バンドルカードを Google Pay に登録する際に、カードに紐づくトークンをVisa様が発行しており、発行されたトークンが Google Pay に格納されています。トークンの発行及び管理はVisa様が行なっております。ただし、Visa様は弊社のカードやカード所有者についての詳細な情報を把握していないため、 Google Pay にカードを登録する際に「トークンの発行を承認しても良いカード及びカード所有者か」どうかを弊社が都度判断する必要があります。カードを Google Pay に登録するフローの裏側では、Visa様と弊社のサーバ間でAPI連携がされており、弊社はAPIを通じて、この、トークン発行を承認するかどうかという判断をしています。加えて、カードを Google Pay に登録するフローの一部ではOne Time Passwordが求められますが、その認証コードを弊社がユーザに連携したりもしています。なお、 Google Pay にカードを登録するフローは2つあります。まず Google Pay のアプリから直にカード情報を入力するフロー、そして、バンドルカードのアプリのトップ画面に表示されている「 Google Pay に追加」ボタンをタップして登録するフローの2つです。

Android 端末におけるバンドルカードのTOP画面
「 Google Pay に追加」ボタンをタップするフローにおいては、 Google Pay に用意されている Push Provisioning という仕組みを利用しています。いずれのフローを利用しても、裏側では先に説明したAPI連携がされています。このように、Visa様とのAPI連携及びPush Provisioningの対応をすることで、弊社はトークンの発行に対応し、 Google Pay にカードを登録できるようにしました。
次にVisaのタッチ決済を処理できるようにするために行なった弊社の対応について説明します。決済データはバイナリ形式でVisa様から弊社に連携され、弊社のProcessorと呼ばれるシステムがバイナリをパースして処理しています。Visaのタッチ決済では従来のバイナリデータに新しいフィールドが追加されて送られてくるため、既存のパース処理を拡張する必要がありました。そのため、Visa様が公開している決済データのドキュメントを確認し、タッチ決済時に追加されるフィールドの仕様を確認した上でパース処理を追加することで、Visaのタッチ決済を処理できるようにしました。余談ですが、弊社に入社した当時から、カンムのエンジニアはバイナリをパースする特殊な集団であるというイメージがありました。どこかのタイミングで自分もバイナリのパース処理を扱ってみたいと思っていたので良い機会になりました。なお、バイナリ処理については2022年度のGoConにて、関連したクイズを弊社が出題しているので参考にしてみてください。
プロジェクトを振り返って
プロジェクトを振り返ってみると、リリースまでに1年強の期間を要しましたが、グローバルにサービスを展開するVisa様とこのような長期プロジェクトを進められたことは、弊社ならではの貴重な経験だったと感じています。Visa様とのプロジェクトには特有の面白さがありました。例えば、プロジェクトの初期段階でVisa様のシンガポール支社にいるエンジニアから英語でプロジェクト概要の説明を受けたり、設計レビューでこちらから英語で質問をする機会があったりしたことは面白かったなと感じています。また、プロジェクトはウォーターフォール方式で進められました。プロジェクトを開始する前にVisa様からリリースまでのタスク一覧とスケジュールの目安が提示され、全体のスケジュールやタスクなどを詰めた上でプロジェクトが開始されました。ウォーターフォール方式で長期プロジェクトを進めた経験がなかったので良い経験になりました。
特有の面白さとして1つ関連したエピソードを紹介します。Google Pay に対応するにあたって、本番リリースする前に試験環境でタッチ決済の動作確認をする必要がありました。Visa様から提供される試験環境の決済用のソフトウェアはWindowsで実行する必要があるため、弊社では手元のMacからRDPでWindowsインスタンスに接続して決済を試すようになっています。従来の決済の動作確認は、このソフトウェアで完結しますが、タッチ決済の動作確認をする場合はカードリーダーをWindowsに接続し、カードリーダーに Android 端末をタッチして試す必要がありました。弊社ではuTrust 4701 F デュアルインターフェーススマートカードリーダーを購入し、Windowsに接続を試みましたが、Windowsインスタンス側でカードリーダーが認識されず、頭を抱えていたことがありました。動作確認の期日が迫っていたこともあり、先輩のsummerwind が「俺にやらせてみろ。とりあえずカードリーダーをスカイツリーに持ってきてくれ。」と伝えてくれたので、スカイツリーでカードリーダーを受け渡したのですが、その後、すぐに原因を特定して問題を解決してくれました。物理カードリーダーのドライバはMacにインストール済みであったもののNFCリーダーのドライバをMacに追加でインストールする必要があったようでした。力量の差に空いた口が塞がらなかったのは良い思い出です。
余談ですが、 Google Pay 対応のリリース後にTwitterで見かけたコメントが印象に残っています。Google Pay 対応のリリース後、何か問題が起きていないかを確認するために、Twitterでエゴサーチをちょくちょくしていたのですが、リリース直後に次のようなツイートを見かけて大変嬉しく感じたことを覚えています。良い声も悪い声もですが、こういったユーザの声をダイレクトに確認できるところは、toCサービスならではだと感じています。
バンドルカードがGooglepayに対応したからpixelwatchでもタッチ決済に使えるようになったんだが えっめちゃくちゃ楽じゃん 助かる…… どんどん使いやすくなる……https://x.com/Ruri_Midorimiya/status/1714272066302886004
最後に
私はiPhoneユーザなので、Apple Payの対応を心待ちにしていたりします。TwitterでもApple Pay非対応を嘆く声を度々見かけます。バンドルカードはApple Payにも対応する予定ではあるのですが、エンジニアの人数も少なく、手が回っていません。
ということで、バンドルカードではプロダクトを改善するバックエンドエンジニアを募集しています。ご応募お待ちしております。
※Android、Google Pay、Google Wallet は Google LLC の商標です。
こんにちは、カンムのエンジニアリングマネージャーの佐藤です。カンムでは5月30日(木)に、React Native Japanコミュニティと協賛してReact Native Meetup #16を開催しました。本記事では、その様子をレポートしました。
当日の様子
イベントは、弊社オフィスの会議室で行われました。当日は30人ほど集まり、とても活気のある勉強会となりました。発表の後には懇親会も設けられ、皆様の意見交換や情報共有が盛んに行われました。

発表内容の紹介
今回は、弊社の社員含め5名のスピーカーからLTが発表されました。
1. 「React Navigation v7で導入されるStatic APIについて」
弊社からは私が、React Navigation 7で新たに導入されるStatic APIについて発表させていただきました。 背景や変更点、それによって何が嬉しいのか?弊社はどのような課題を解決できたのか?などをお話しさせていただきました。 詳しくは資料をご覧ください。
2. @yukukotani様「Capacitor製のWebViewアプリからReact Native製のハイブリッドアプリへ」
Ubie 社の@yukukotani様は、Capacitor 製のWebViewアプリをReact Nativeに移行する際のお話をテーマに発表されました。 React Nativeへ移行されたモチベーションとして、Capacitorに比べエコシステムの維持が強固であること、Next.js & TypeScriptで作られたアプリケーションとの親和性などを挙げられていました。資料と合わせてご覧ください。
3. @mok_oshi様「React Nativeでスケジュール帳を作っている話」
@mok_oshi様の発表は、React Nativeを用いた美容サロンの予約システムKarutekunを作成する過程での経験を発表されていました。カレンダービューというとても複雑なUIを、FlatListとScrollViewを巧みに組み合わせて表現されているのがとても印象的でした。資料はこちらからご覧ください。
4. @kazutoyo様「React Native Skiaを使ってみよう!」
@kazutoyo様の発表は、ShopifyチームがメンテしているReact Native Skiaについてでした。Skiaは過去にFlutterが採用していた2Dグラフィックライブラリで、React Nativeでもリッチな体験を提供できます。 実際に動く多数のサンプルが掲載されている資料もぜひご覧ください。
5. shibafu-san様「WebViewを使って既存のウェブアプリをReact Nativeアプリに組み込む話」
shibafu-san様は、既存のウェブアプリとして展開しているL COLLECTIONなどのサービスをWebViewを用いてReact Nativeアプリに統合する方法について発表しました。
最後に
弊社では初となるエンジニア勉強会の開催でしたが、無事にイベントを進行できました。これもイベントへ参加してくださったゲストの皆様、スピーカーの皆様、そして準備にご協力いただいたReact Nativeコミュニティ及び当日スタッフの皆様のおかげです。心よりお礼申し上げます。
カンムではフロントエンドエンジニアを募集しています!
カンムでは現在、フロントエンドエンジニアを募集しています。私たちと一緒に「お金の新しい選択肢をつくる」ミッションを達成するを仲間を求めています。興味のある方は、ぜひご連絡ください!