How to Parallelize Deep Learning on GPUs Part 2/2: Model Parallelism — Tim Dettmers (original) (raw)
In my last blog post I explained what model and data parallelism is and analysed how to use data parallelism effectively in deep learning. In this blog post I will focus on model parallelism.
To recap, model parallelism is, when you split the model among GPUs and use the same data for each model; so each GPU works on a part of the model rather than a part of the data. In deep learning, one approach is to do this by splitting the weights, e.g. a 1000×1000 weight matrix would be split into a 1000×250 matrix if you use four GPUs.

Model parallelism diagram. Synchronizing communication is needed after each dot product with the weight matrix for both forward and backward pass.
One advantage of this approach is immediately apparent: If we split the weights among the GPUs we can have very large neural networks which weights would not fit into the memory of a single GPU. In part I mentioned this in an earlier blog post, where I also said that such large neural networks are largely unnecessary. However, for very big unsupervised learning tasks – which will become quite important in the near future – such large networks will be needed in order to learn fine grained features that could learn “intelligent” behavior.
How does a forward and backward pass work with such split matrices? This is most obvious when we do the matrix algebra step by step:
We start looking at 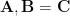
Standard: 128×1000 dot 1000×500 = 128×500
Split by weight matrix first dimension: 128×500 dot 500×500 = 128×500 -> add matrices
Split by weight matrix second dimension: 128×1000 dot 1000×250 = 128×250 -> stack matrices
To calculate the errors in the layer below we need to pass the current error through to the next layer, or more mathematically, we calculate the deltas by taking the dot product of the error of the previous layer 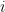
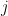
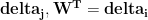
Standard: 128×500 dot 500×1000 = 128×1000
Split by weight matrix first dimension: 128×500 dot 500×500 = 128×500 -> stack matrices
Split by weight matrix second dimension: 128×250 dot 250×1000 = 128×1000 -> add matrices
We see here, we need to synchronize (adding or stacking weights) after each dot product and you may think that this is slow when compared to data parallelism, where we synchronize only once. But one can quickly see that this is not so for most cases if we do the math: In data parallelism a 1000×500 gradient needs to be transferred once for the 1000×500 layer – that’s 500000 elements; for model parallelism we just need to transfer a small matrix for each forward and backward pass with a total of 128000 or 160000 elements – that’s nearly 4 times less data! So the network card bandwidth is still the main bottleneck in the whole application, but much less so than in the data parallelism case.
This is of course all relative and depends on the network architecture. Data parallelism will be quite fast for small networks and very slow for large networks, the opposite is true for model parallelism. The more parameters we have, the more beneficial is model parallelism. Its true strength comes to play if you have neural networks where the weights do not fit into a single GPU memory. Here model parallelism might achieve that for which one would need thousands of CPUs.
However, if you run small networks where the GPUs are not saturated and have some free capacity (not all cores are running), then model parallelism will be slow. Unlike data parallelism, there are no tricks you can use to hide the communication needed for synchronization, this is because we have only partial information for the whole batch. With this partial information we cannot compute the activities in the next layer and thus have to wait for the completion of the synchronization to move forward.
How the advantages and disadvantages can be combined is best shown by Alex Krizhevsky who demonstrates the efficiency of using data parallelism in the convolutional layers and model parallelism in the dense layers of a convolutional neural network.