TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos (original) (raw)
1Peking University, 2South China University of Technology,
3The University of Hong Kong, 4Kuaishou Technology
*Equal contribution
Demo Video
Demonstration of TimeChat-Online's real-time streaming video understanding capabilities.
This paper presents TimeChat-Online, a novel online VideoLLM for efficient Streaming Video Understanding.
At its core is the innovative Differential Token Dropping (DTD) module that selectively preserves only significant temporal changes across continuous video streams.

The yellow-highlighted frames with few tokens dropped indicate significant video scene transitions.
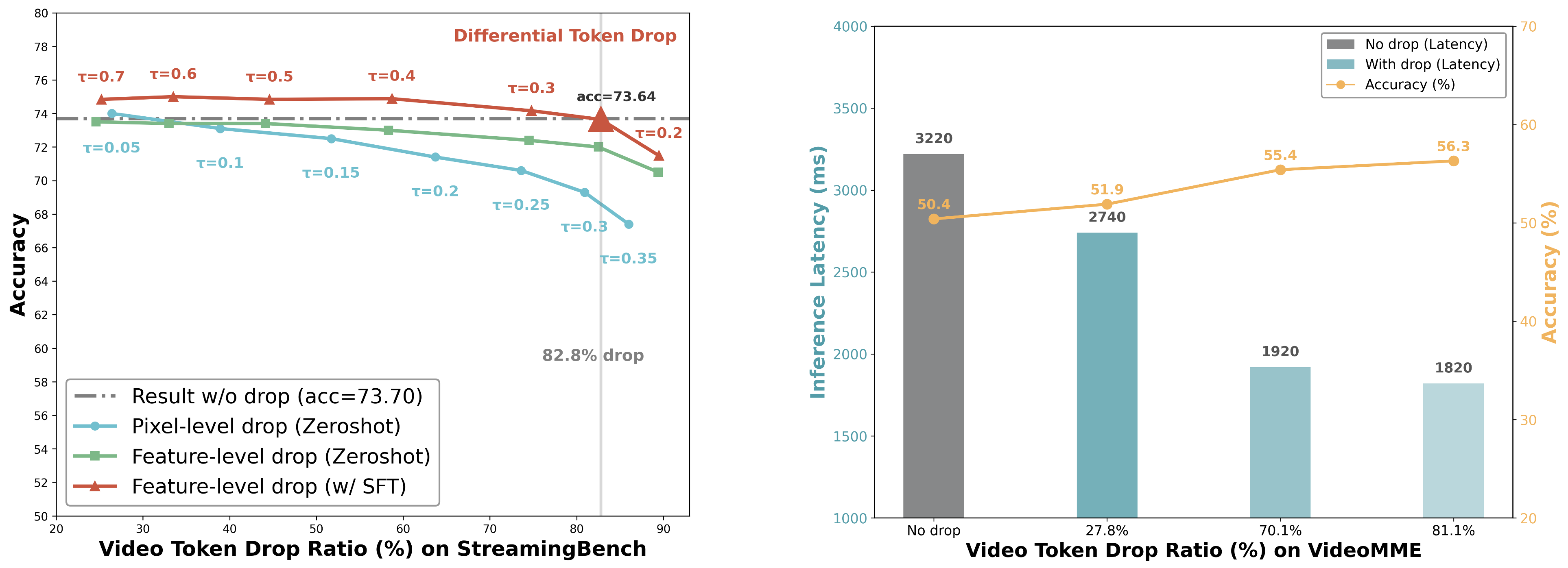
The DTD module eliminates 82.8% of redundant video tokens, while achieving a 1.76x speedup in response latency and maintaining over 98% of original accuracy, revealing that over 80% of streaming video content is naturally redundant without any user-query guidance. Furthermore, it naturally monitors video scene transitions, facilitating online Proactive Responding.
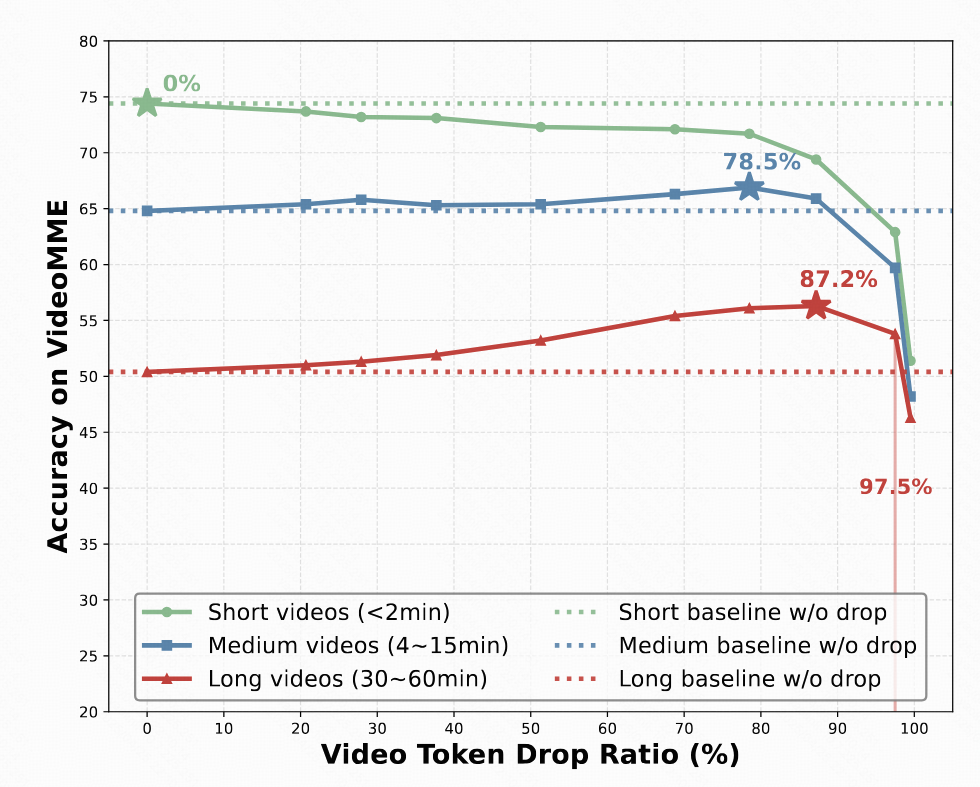
When directly integrated with Qwen2.5VL-7B without additional training, DTD achieves a 5.7-point accuracy improvement while reducing video tokens by 84.6% on the challenging VideoMME long subset containing videos of 30-60 minutes. Furthermore, longer videos permit higher rates of redundant visual token dropping without performance degradation (up to 97.5% for the long subset).
Abstract
The rapid growth of online video platforms, particularly live streaming services, has created an urgent need for real-time video understanding systems. These systems must process continuous video streams and respond to user queries instantaneously, presenting unique challenges for current Video Large Language Models (VideoLLMs). While existing VideoLLMs excel at processing complete videos, they face significant limitations in streaming scenarios due to their inability to handle dense, redundant frames efficiently. We present TimeChat-Online, a novel online VideoLLM for real-time video interaction. Its core innovation, the Differential Token Drop (DTD) module, tackles visual redundancy by preserving meaningful temporal changes while eliminating static content between frames. Our experiments show DTD reduces video tokens by 82.8% while maintaining 98% performance on StreamingBench, revealing that over 80% of streaming video content is naturally redundant without requiring user-query guidance. For seamless real-time interaction, we introduce TimeChat-Online-139K, a comprehensive streaming video dataset with diverse interaction patterns spanning backward-tracing, current-perception, and future-responding scenarios. TimeChat-Online's unique Proactive Response capability—naturally achieved through continuous monitoring of video scene transitions via DTD—sets it apart from conventional approaches. Our evaluation confirms TimeChat-Online's superior performance on streaming benchmarks (StreamingBench and OvOBench) while maintaining competitive results on long-form video tasks (Video-MME, LongVideoBench, and MLVU). This work establishes a new paradigm for efficient streaming video understanding and demonstrates the potential of leveraging natural video redundancy in future VideoLLM development.
Differential Token Dropping Design
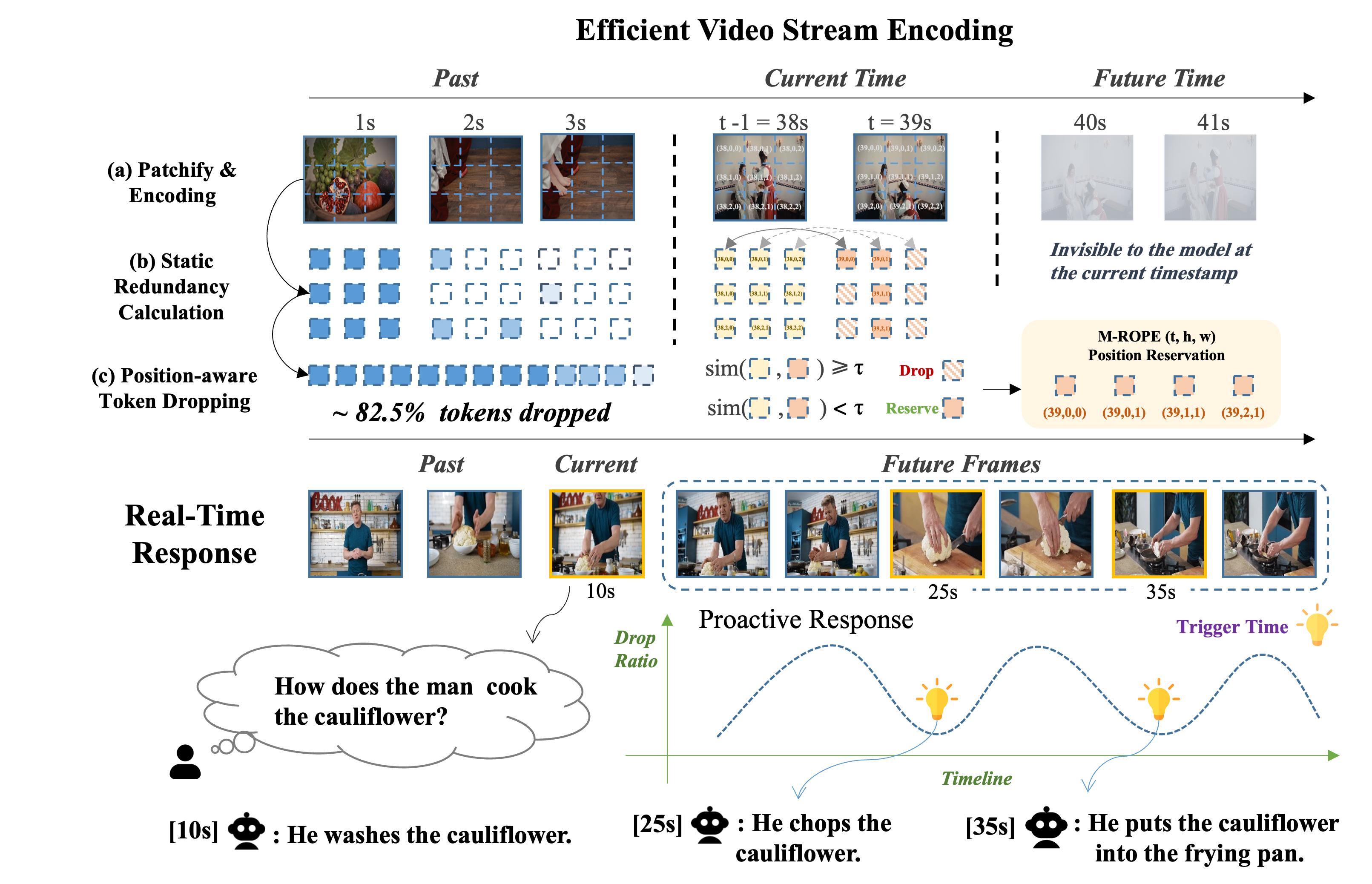
The core of TimeChat-Online lies in its Differential Token Drop (DTD) module, designed to efficiently eliminate visual redundancy in streaming videos by only preserving significant temporal changes.
How DTD Works
- Patchify and Encoding: Each video frame is split into a sequence of visual patches and then encoded into visual tokens using a vision encoder (i.e., ViT).
- Static Redundancy Calculation: DTD quantifies redundancy between temporally consecutive frames at either the pixel level or feature level. This process involves comparing spatially-aligned tokens from consecutive frames and measuring their similarity to determine whether the newly-arriving frame is redundant.
- Pixel-level redundancy: calculates L1 distance between two pixel patches (before ViT).
- Feature-level redundancy: uses cosine similarity between two visual tokens (after ViT).
- Position-aware Token Dropping: Based on static redundancy, DTD creates a binary mask to identify which tokens to keep and which to discard. Importantly, it preserves the original Multimodal-ROPE (t, h, w) position ids of the retained tokens to maintain the fine-grained spatial-temporal structure of the video.
Facilitating Proactive Response
The drop ratio curve across the timeline naturally reveals video scene transitions, as frames with significant changes from previous frames have fewer dropped tokens, visualized as valleys (low drop ratio) in the curve. These transition points serve as natural "trigger times" for proactive responses, enabling the model to detect when meaningful new visual information becomes available without requiring additional perception modules.
This mechanism allows TimeChat-Online to achieve Proactive Response by autonomously identifying critical moments in streaming content and responding accordingly.
Key Technical Innovations of DTD
- ✨ Video-aware Dynamic Pruning:
DTD adaptively reduces video tokens from a holistic video perspective, well-suited for both high-speed and slow-motion videos. - 📝 Positional Reservation:
DTD maintains the fine-grained spatial-temporal positions of retained tokens, ensuring precise spatial localization and temporal understanding capabilities. - ⚡ Streaming-friendly Design:
DTD efficiently processes video streams by calculating redundancy only for newly-arriving frames with faster speed, without re-processing historical video content.
TimeChat-Online-139K Dataset
To enable more flexible real-time interactions, we present TimeChat-Online-139K, a comprehensive streaming video dataset that encompasses backward-tracing, current-perception, and future-responding tasks across diverse online video scenarios.
Our dataset creation involved four key steps: (1) Collecting visually informative videos with diverse scene changes, (2) Generating scene-oriented dense captions using GPT-4o, (3) Creating streaming VideoQA samples based on these captions, and (4) Constructing negative samples for future-response training.
Data Statistics:
- Videos: 11,043 visually informative videos
- Average Duration: 11.1 minutes per video
- Scene-oriented Key Frames: Average of 87.8 key frames per video
- Key Frame Interval: ~7.14 seconds between consecutive frames
- Caption Length: ~176 words per key frame description
- QA Pairs: 139K question-answer pairs
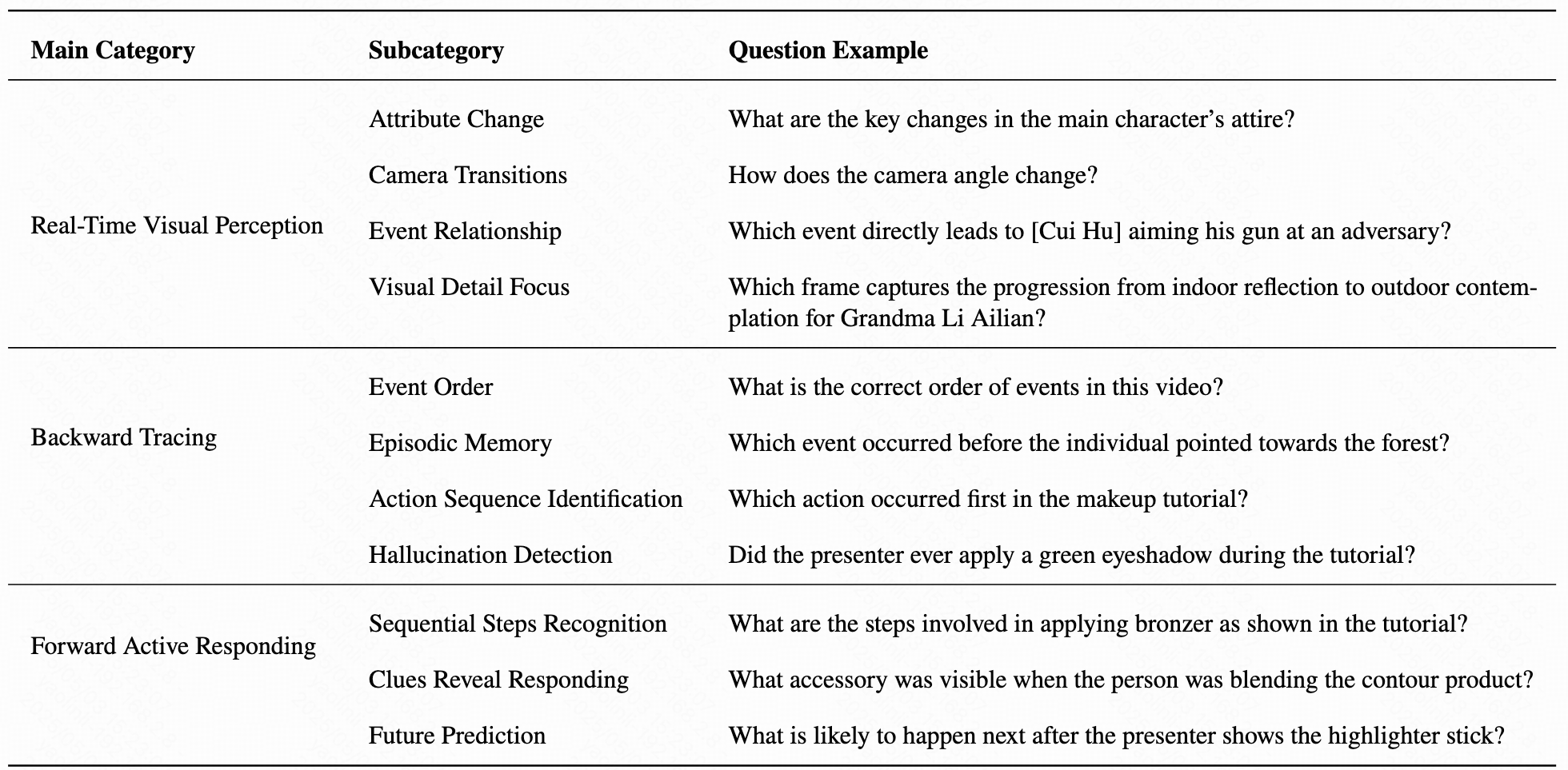
- Task Types: Backward Tracing, Real-Time Visual Perception, and Forward Active Responding
Experiments
We conduct comprehensive experiments on both streaming video benchmarks (StreamingBench and OVO-Bench) and offline long-form video benchmarks (MLVU, LongVideoBench, VideoMME) to validate the effectiveness of TimeChat-Online.
Performance on StreamingBench
On StreamingBench, TimeChat-Online achieves 56.56% accuracy with 82.6% token reduction, demonstrating state-of-the-art performance among online and offlineVideoLLMs. This significant token reduction of over 80% while maintaining high accuracy confirms that streaming videos contain substantial natural redundancy that can be effectively filtered.
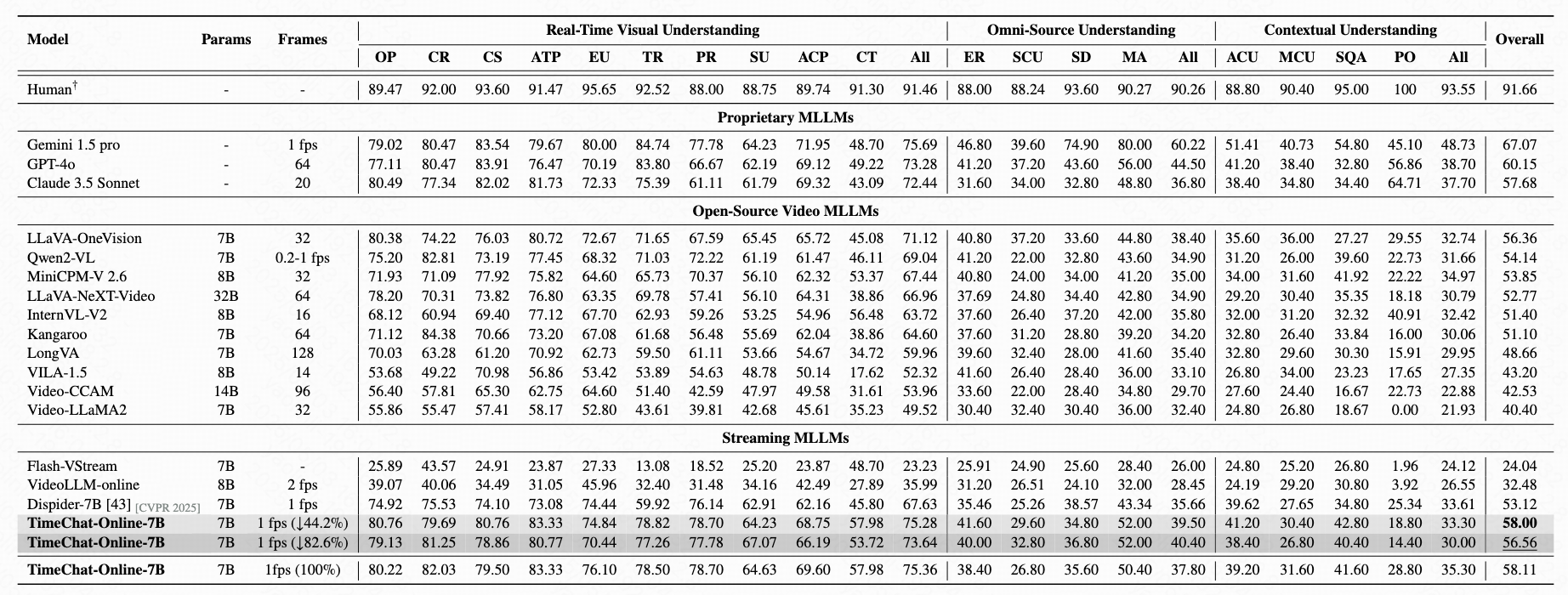
Table 1: Performance comparison on StreamingBench full set including three categories: Real-Time Visual Understanding, Omni- Source Understanding and Contextual Understanding.
Evaluation on OVO-Bench
TimeChat-Online significantly outperforms existing online VideoLLMs across real-time perception, backward tracing, and forward responding tasks on OVO-Bench.
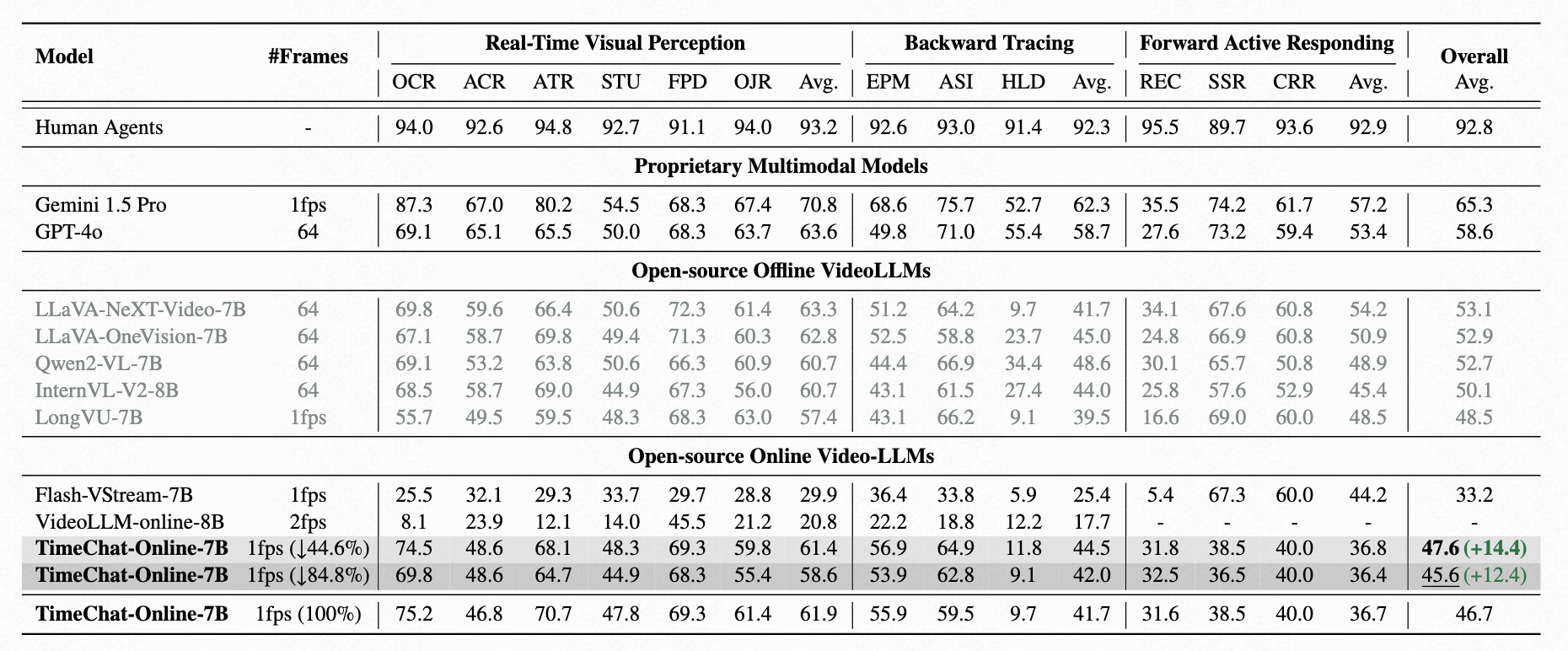
Table 2: Evaluation results on OVO-Bench comprising three categories: i) Real-Time Visual Perception (OCR: Optical Character Recognition, ACR: Action Recognition, ATR: Attribute Recognition, STU: Spatial Understanding, FPD: Future Prediction, OJR: Object Recognition), ii) Backward Tracing (EPM: Episodic Memory, ASI: Action Sequence Identification, HLD: Hallucination Detection), and iii) Forward Active Responding (REC: Repetition Event Count, SSR: Sequential Steps Recognition, CRR: Clues Reveal Responding).
Results on Offline Long Video Benchmarks
Compared with existing online VideoLLMs, TimeChat-Online achieves superior performance on all long video benchmarks. It achieves up to 85.0% reduction in video tokens while maintaining or even improving performance across long-form video benchmarks. This demonstrates the effectiveness of our DTD approach for both streaming and offline video tasks.
When integrated with Qwen2.5-VL-7B without training, our DTD module improves VideoMME (long subset) accuracy by 5.7 points while reducing 84.6% of video tokens. Notably, higher token drop ratios consistently enhance performance, indicating that substantial vision redundancy in long videos can be eliminated to improve efficiency and understanding capabilities.
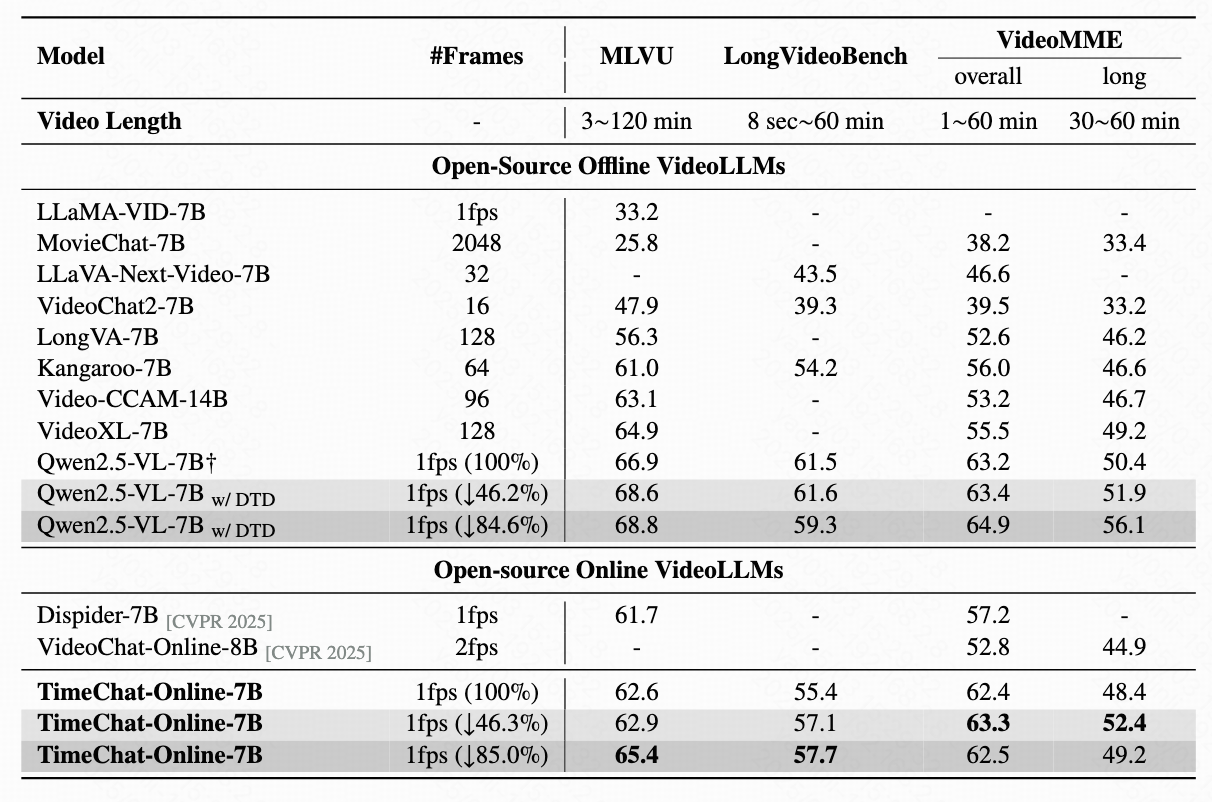
Table 3: Results on offline long video benchmarks. We report the accuracy on the MLVU, LongVideoBench and VideoMME(w/o subtitles). † indicates the reproduced results.
Visualized Cases
We present visualized examples demonstrating how TimeChat-Online processes streaming video content in real-time, highlighting the effectiveness of our Differential Token Dropping module and Proactive Response capability.
Case Study 1: Proactive Response with Scene Change Detection

TimeChat-Online autonomously identifies significant scene transitions in streaming videos and generates proactive responses without requiring explicit user queries. The model precisely detects when meaningful new visual information becomes available, as illustrated by the drop ratio timeline, where valleys (aligned frames with yellow lightbulb icons) indicate substantial visual changes that trigger intelligent autonomous responses.
Case Study 2: Feature-level vs. Pixel-level Token Dropping

Comparison between feature-level (left) and pixel-level (right) token dropping. Feature-level approach with τfeat = 0.4 achieves a 58.3% drop ratio while effectively preserving visually important elements.
Case Study 3: Highly Redundant Video Content

DTD dynamically adapts to different video content types. This example demonstrates that with the same threshold τfeat = 0.4, DTD achieves an impressive 89.5% drop ratio (compared to 58.3% in Case 2) for highly redundant drawing scenarios, highlighting its efficiency in content-adaptive token preservation.
Case Study 4: Visualizing Scene Transitions Through Drop Ratio Analysis
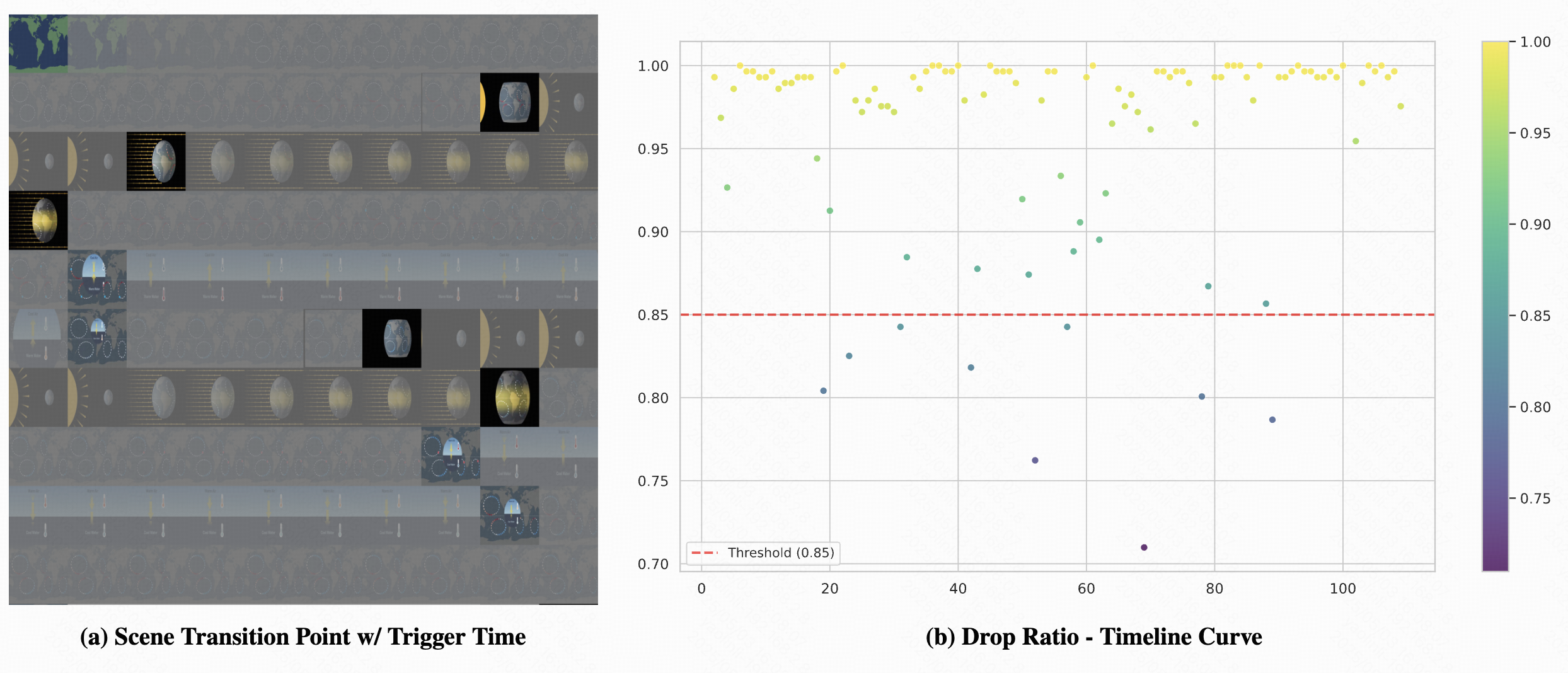
Drop ratio timeline acts as a natural scene transition detector. Significant visual changes create valleys in the curve, identifying key video moments. Left: Scene transition with trigger time. Right: Drop ratio curve showing valleys at scene changes, with 0.85 threshold for increased token retention.
BibTeX
@misc{timechatonline,
title={TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos},
author={Linli Yao and Yicheng Li and Yuancheng Wei and Lei Li and Shuhuai Ren and Yuanxin Liu and Kun Ouyang and Lean Wang and Shicheng Li and Sida Li and Lingpeng Kong and Qi Liu and Yuanxing Zhang and Xu Sun},
year={2025},
eprint={2504.17343},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.17343},
}Acknowledgement
Usage and License Notices: The data, code and checkpoints are intended and licensed for research use only. They are also restricted to uses that follow the license agreements of the respective datasets and models used in this work.
Related Projects: TimeChat, Qwen2.5VL, RLT, VideoLLM-online, OVOBench,StreamingBench