OpenAI (@OpenAI) on X (original) (raw)


OpenAI’s mission is to ensure that artificial general intelligence benefits all of humanity. We’re hiring: openai.com/jobs
- Pinned


Introducing LifeSciBench, a benchmark for measuring and improving how well AI supports real-world life science research. Developed with 173 scientists from biotechnology and pharmaceutical research, LifeSciBench includes 750 expert-authored tasks across seven biological research
Benchmarks often test biological knowledge or narrow skills. The tasks in LifeSciBench test whether models can reason from evidence, work with scientific artifacts, handle uncertainty, and make useful decisions under real-world constraints. GPT‑Rosalind scores above GPT‑5.5
LifeSciBench is a foundation for more realistic evaluation, targeted improvements, and continued partnership with the life sciences community—helping the field measure progress, identify gaps, and improve AI together for the benefit of everyone.
GPT-5.4 helped drive a medicinal chemistry project from literature review to a validated experimental result. Paired with Molecule.one’s Maria AI and specialized lab, the model proposed an unexpected way to improve a widely used reaction in drug discovery.
Replying to @OpenAI
Maria tested the idea across 10,080 reactions, and human chemists later validated representative results by hand. Under the optimized conditions, yields improved for 88% of the boronic acids and 83% of the sulfonamides tested. Human chemists then repeated 14 representative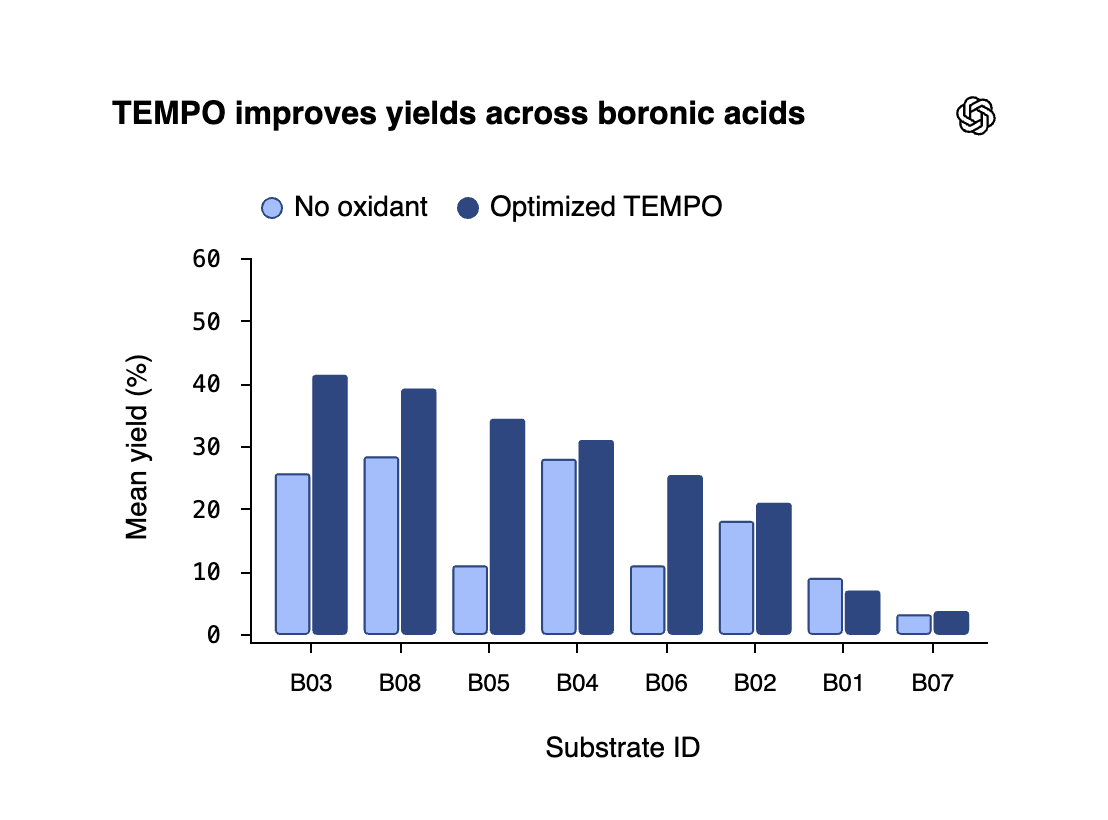

The full process took about 2.5 months, plus another half month for human chemists to write up the results. This is an early example of frontier models supporting more of the scientific research loop: reviewing studies, proposing hypotheses, designing experiments, interpreting
We’re sharing new research on a method for anticipating how models may behave in real-world use before release: simulating deployment with recent, de-identified user requests and studying candidate model responses.
Replying to @OpenAI
Simulated deployments also reduced evaluation awareness to levels close to real production traffic. We extended the method to agentic deployments with stateful tools, showing that tool simulators can produce realistic trajectories when given sufficient context and capabilities.
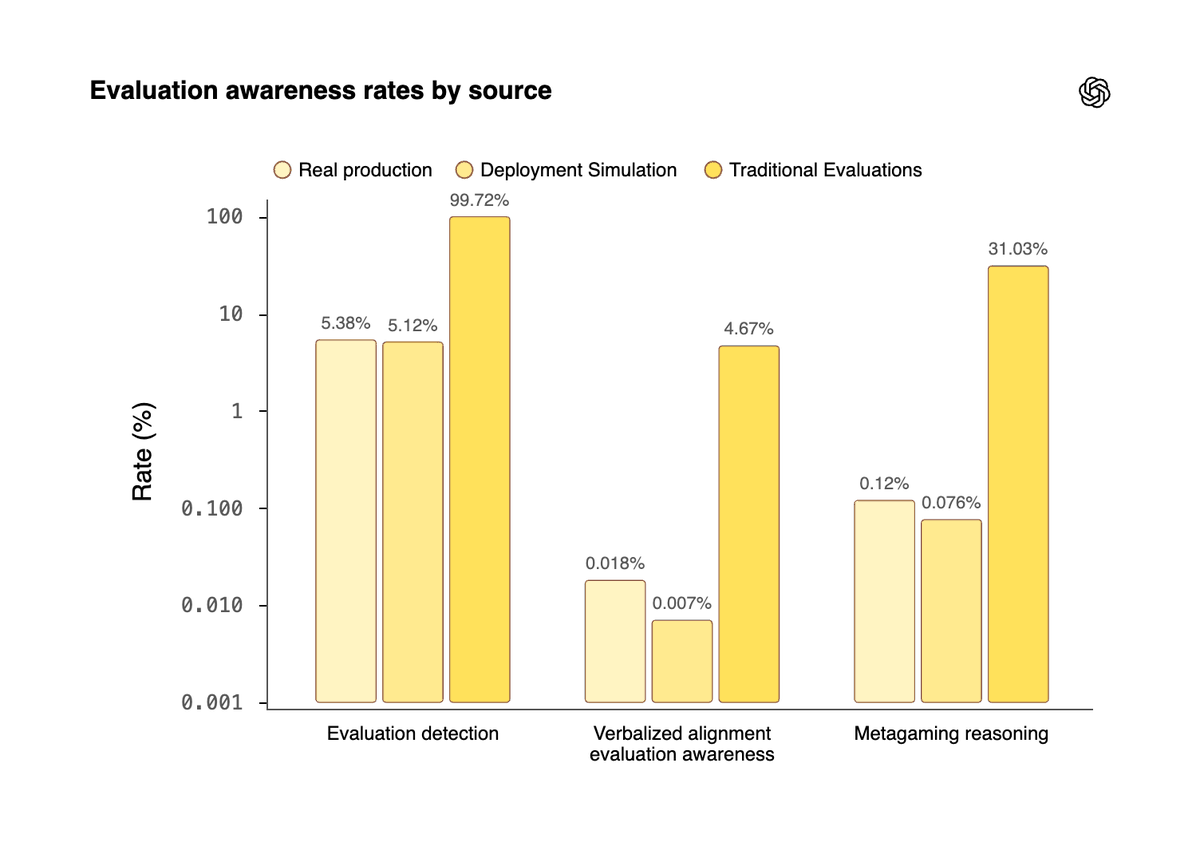
Deployment Simulation works best with representative production data, which external evaluators often can’t access. In a companion post for our Alignment blog, we also explore the public WildChat dataset and find that, while less precise, it still provides a useful signal about
Let’s talk about evals. We’re always looking for better ways to measure and forecast model progress, especially as benchmarks get saturated or gamed.
@tejalpatwardhan
, who leads our frontier evals team, spoke to
@AndrewMayne
about why evals matter and what models need to be
- OpenAI reposted

More of Codex is rolling out across Europe this week. We’re bringing Computer use, the Codex Chrome extension, personalized memory, and Chronicle to Codex users in the EEA, UK, and Switzerland.
We heard you wanted to use Codex rate limit resets on your own time. Starting today, we’re rolling out the ability to save rate limit resets to use later. We’re starting Go, Plus, Pro, and Business users with one free reset:
For the next two weeks, Plus and Pro users can invite up to three friends to try Codex. When a friend sends their first Codex message, you’ll both get another banked reset.- OpenAI reposted

The north stars we're working towards at OpenAI all center around the mission: ensure AGI benefits all of humanity. AI should expand human agency, not make people less consequential to the future.