VisIT-Bench (original) (raw)
VisIT-Bench: A Benchmark for Vision-Language Instruction Following Inspired by Real-World Use
1 The Hebrew University of Jerusalem, 2 Google Research, 3 University of California Los Angeles, 4 Allen Institute for AI, 5 University of Washington, 6 University of California, Santa Barbara, 7 Stanford University 8 LAION
*Equal Contribution
NeurIPS 2023, Datasets and Benchmarks
VisIT-Bench is a new vision-language instruction following benchmark inspired by real-world use cases. Testing 70 diverse “wish-list” skills with an automated ranking system, it advances the ongoing assessment of multimodal chatbot performance.
Why VisIT-Bench 🤔?
Though recent VLMs have shown promise in following instructions, their evaluation for real-world human-chatbot instructions is often limited. Typically, VLMs are evaluated through qualitative comparison of outputs, which makes it challenging to quantify progress and potential shortcomings. VisIT-Bench helps address this problem by offering a comprehensive testbed for measuring model performance across a diverse set of instruction-following tasks, inspired by real world scenarios.🌍
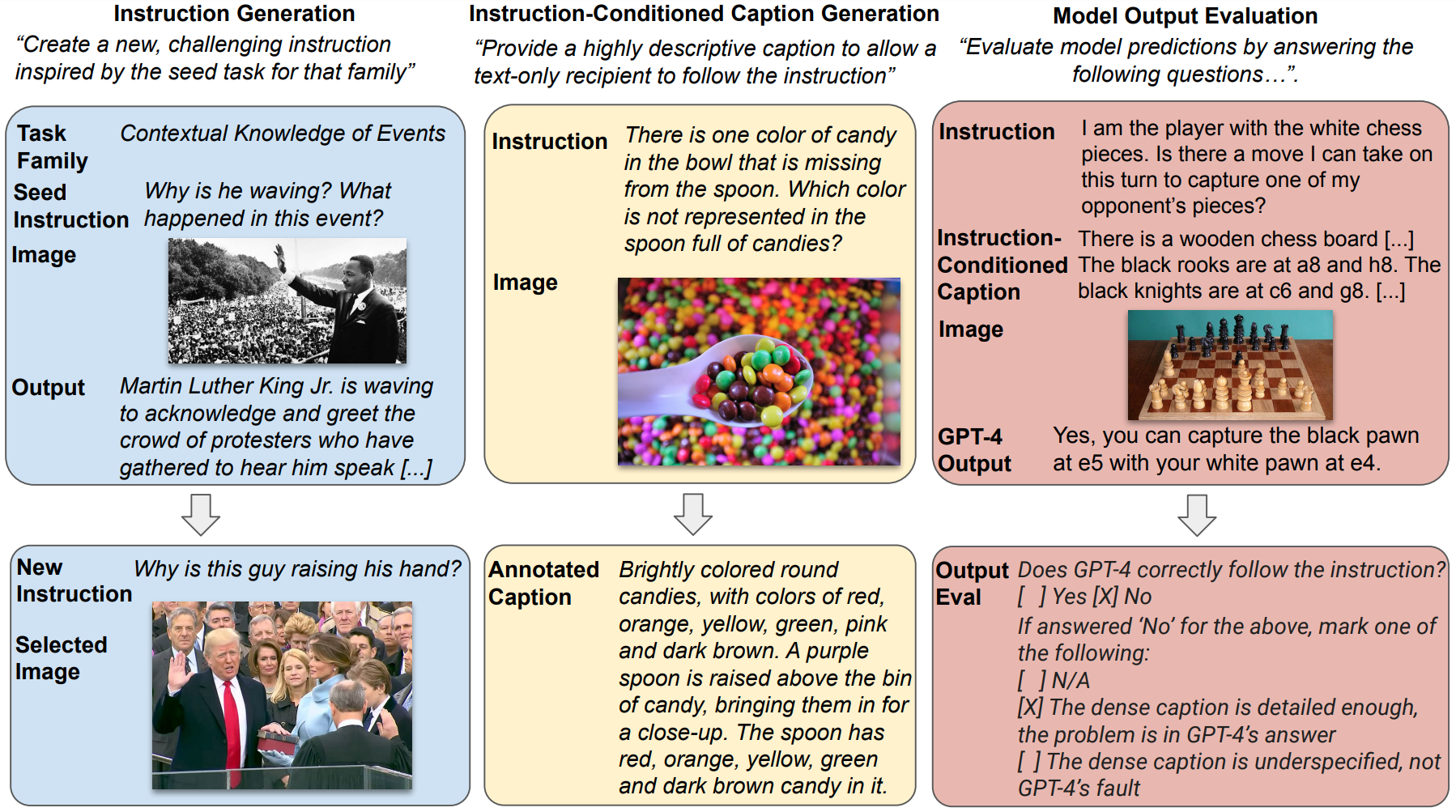
VisIT-Bench Instance
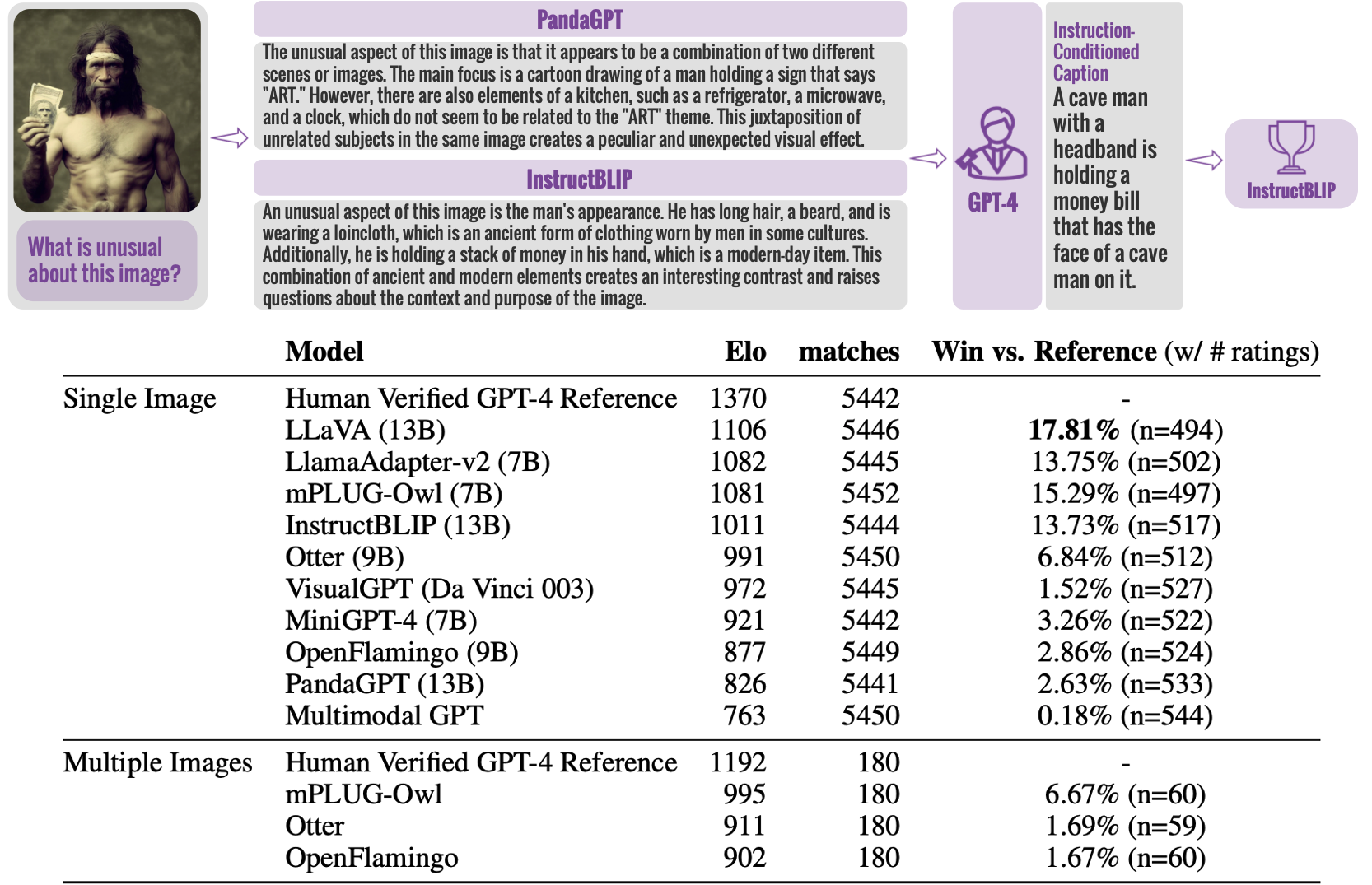
An example from VisIT-Bench, featuring an image, an instruction, an “instruction-conditioned caption”, a detailed description allowing a model to follow the instruction using just the text, and a human-verified response from GPT-4. These elements are used for evaluating multimodal chatbots and updating a leaderboard.📊

Data Collection Framework
1. Creating “wish-list” instructions for desired V&L chatbot capabilities
2. Using these as inspiration for instructions annotation
3. Collecting instruction-conditioned dense captions
4. Generating human-verified chatbot responses from GPT-4 outputs
Repurposing Existing Datasets
VisIT-Bench repurposes 25 datasets to a chatbot-style, including 10 multi-image datasets.
Here, we add an instruction prompt and a chatbot response to an NLVR2 instance.
This methodology leverages previous studies, tailoring them to current chatbot requirements.

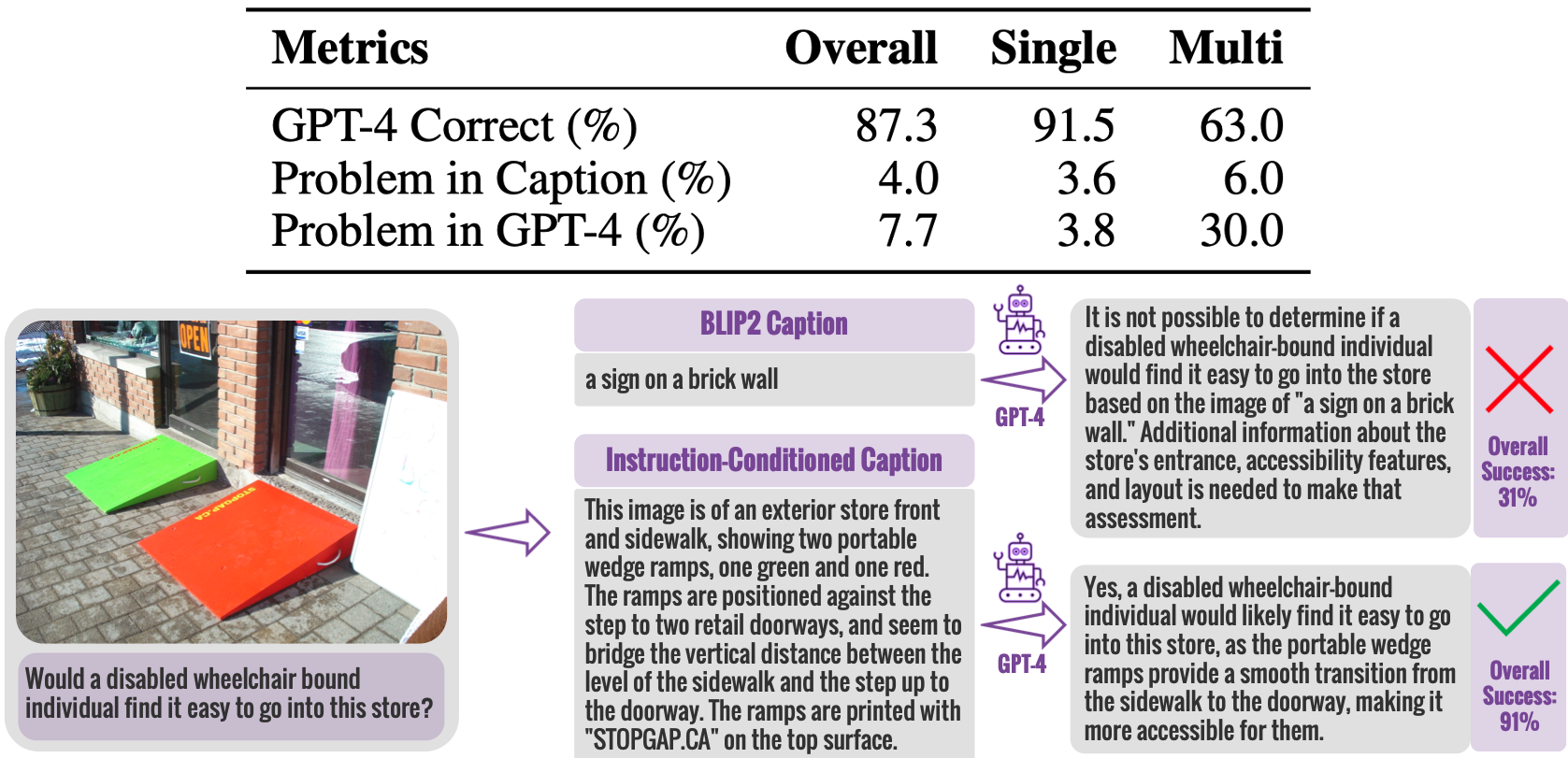
Instruction-Conditioned Dense Captions and Data Collection Results
With a 91.5% success rate in single-image scenarios, our data collection demonstrates the effectiveness of instruction-conditioned dense captions.
It also showcases the necessity of our dense captions over generated captions from a SoTA BLIP2 captioning model. 📈
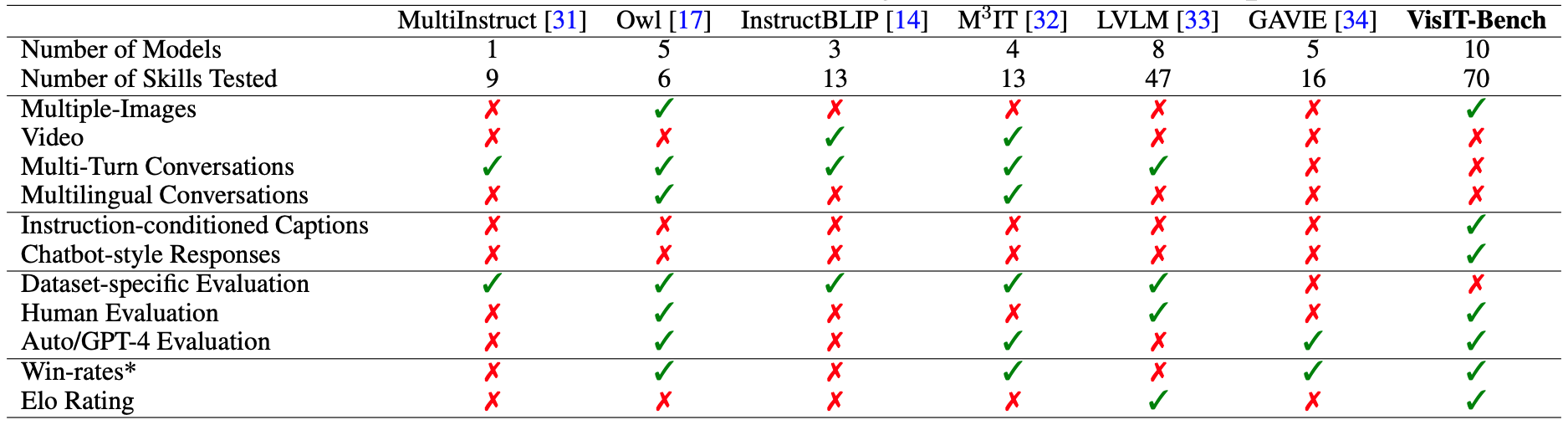
Features of the Dataset
VisIT-Bench emphasizes diverse tasks and human-chatbot interactions.
We stand apart with our 'wish-list' instructions, 70 tested skills, and the repurposing of existing datasets, including multi-image tasks, thereby reflecting the dynamic demands of modern chatbots.🎯.
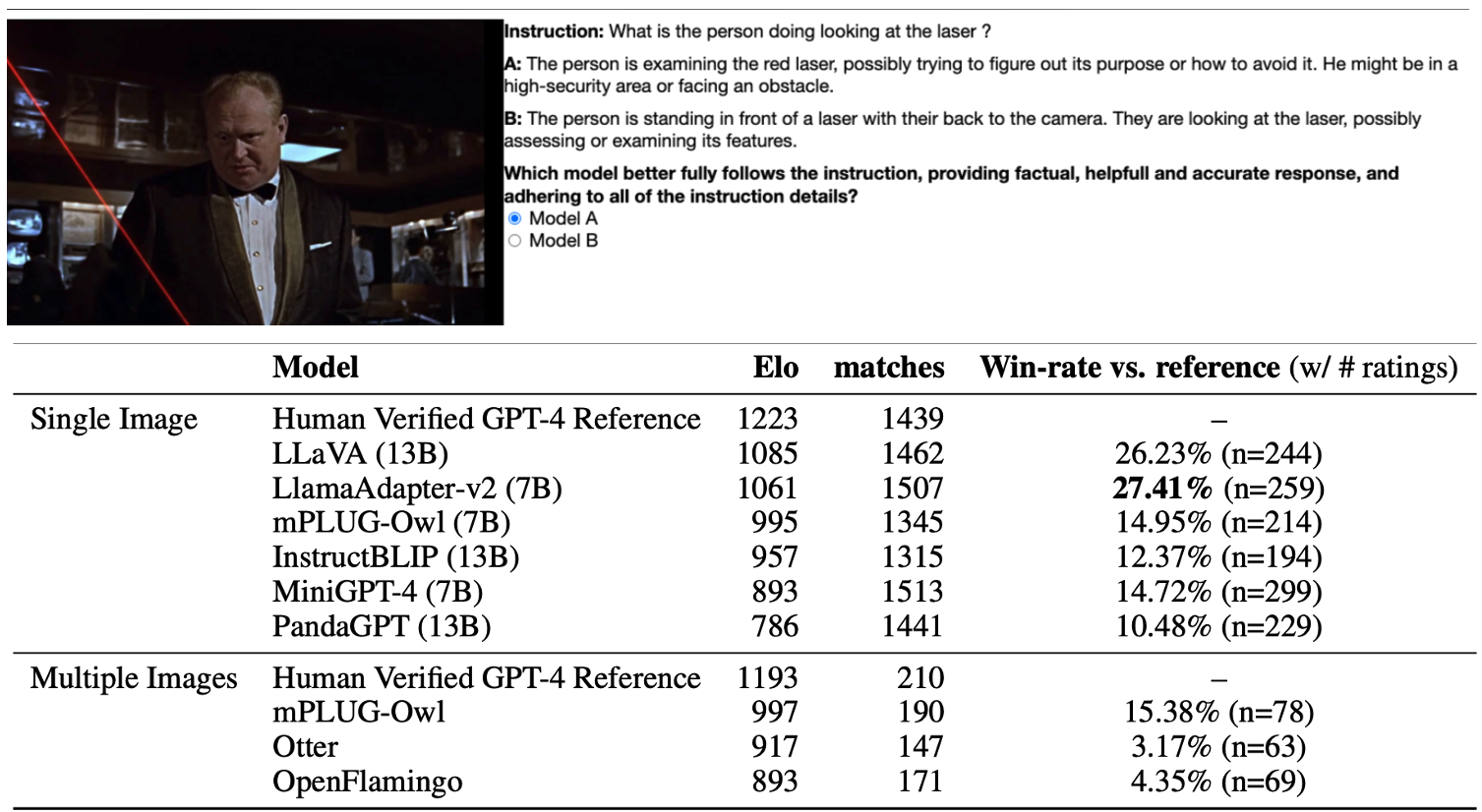
Human-Guided Rankings
VisIT-Bench facilitates the comparison of different V&L models.
By using human preference annotations, we form a leaderboard, providing insights into the strengths and weaknesses of each model in various tasks.
Automatic Evaluation and Dynamic Leaderboard
Using GPT-4 as a judge, we host head-to-head battles among top vision-and-language models 🥊.
Our leaderboard reflects human preferences with high agreement, making it a scalable and reliable assessment tool.⚖️
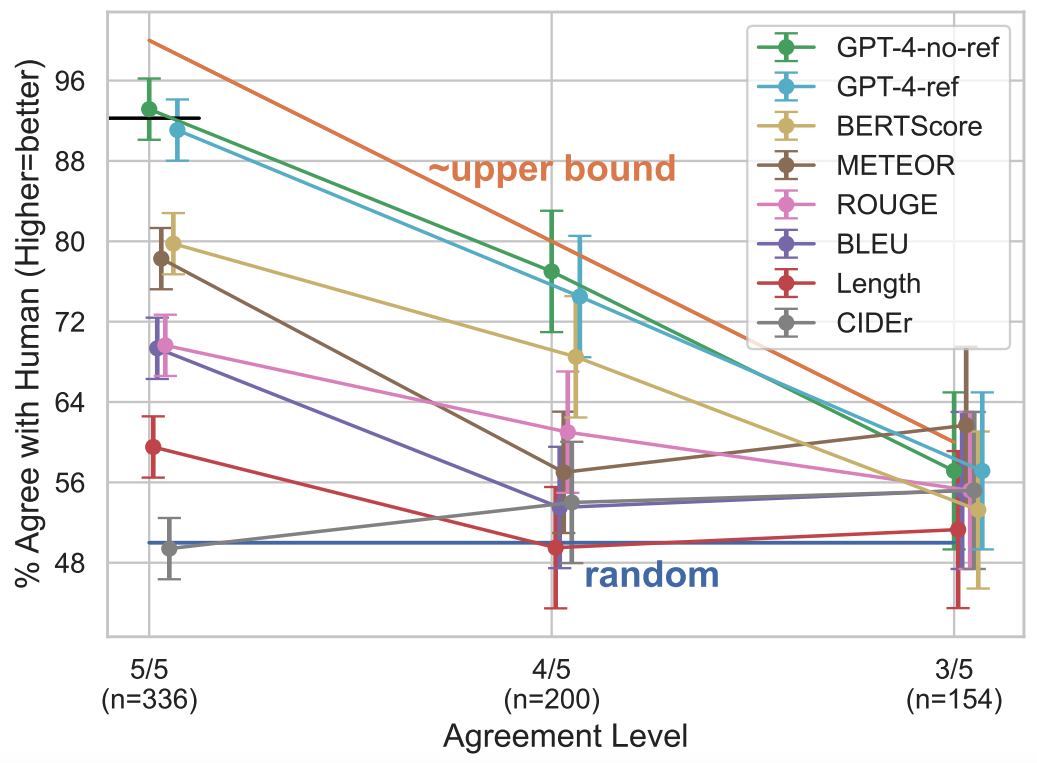
Evaluating Evaluation Metrics
How good is our automatic metric? We measure correlations of several automatic metrics vs. human preferences, with our reference free evaluation (GPT-4-no-ref) showing the strongest alignment (top orange line - upper bound, bottom blue line - random chance (50%).📏
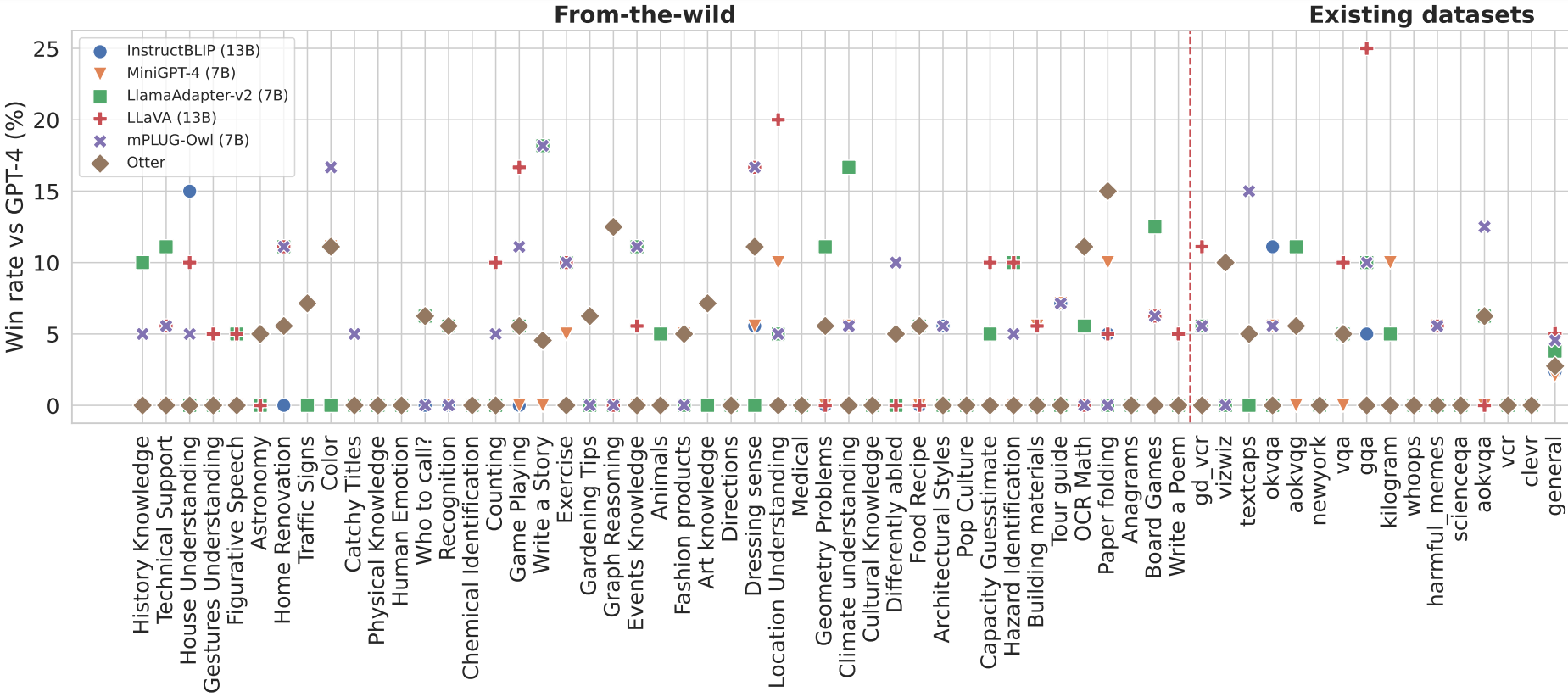
Results by Different Models on Different Instruction Families
VisIT-Bench offers detailed insight into the performance of V&L models.
Through our diverse instruction families, you can assess how different models perform on various tasks, providing a thorough understanding of their capabilities.🔍
Dataset Viewer
Leaderboard
To submit your results to the leaderboard, you can run our auto-evaluation code, following the instructions here. Once you are happy with the results, you can send to this mail. Please include in your email 1) a name for your model, 2) your team name (including your affiliation), and optionally, 3) a GitHub repo or paper link. Please also attach your predictions: you can add a "predictions" column to this csv.
BibTeX
@misc{bitton2023visitbench, title={VisIT-Bench: A Benchmark for Vision-Language Instruction Following Inspired by Real-World Use}, author={Yonatan Bitton and Hritik Bansal and Jack Hessel and Rulin Shao and Wanrong Zhu and Anas Awadalla and Josh Gardner and Rohan Taori and Ludwig Schmidt}, year={2023}, eprint={2308.06595}, archivePrefix={arXiv}, primaryClass={cs.CL} }