Ziyi Wang (original) (raw)
| Ziyi Wang I am a fifth year PhD student in the Department of Automation at Tsinghua University, advised by Prof. Jiwen Lu . In 2020, I obtained my B.Eng. in the Department of Electronic Engineering, Tsinghua University. I also obtained B.Admin. as dual degree in the School of Ecnomics and Management, Tsinghua University. I am broadly interested in computer vision and deep learning. My current research focuses on 3D vision, 3D generation and 4D world model. Email / Google Scholar / Github |  |
|---|
News
- 2025-06: 1 survey paper on vision generalist model is accepted to IJCV.
- 2025-02: 1 paper on unified 3D point cloud pre-training is accepted to CVPR 2025.
- 2024-09: 1 paper on 3D open vocabulary semantic segmentation is accepted to NeurIPS 2024.
- 2024-01: The journal paper of P2P is accepted to TPAMI.
- 2023-07: 1 paper on 3D generative pre-training is accepted to ICCV 2023.
- 2023-07: The journal paper of PV-RAFT is accepted to TPAMI.
- 2022-09: 1 paper (spotlight) on 3D prompt learning is accepted to NeurIPS 2022.
- 2022-03: 1 paper on 3D semantic segmentation is accepted to CVPR 2022.
- 2021-07: 2 papers (including 1 oral) are accepted to ICCV 2021.
- 2021-03: 1 paper on 3D scene flow estimation is accepted to CVPR 2021.
Publications
* indicates equal contribution
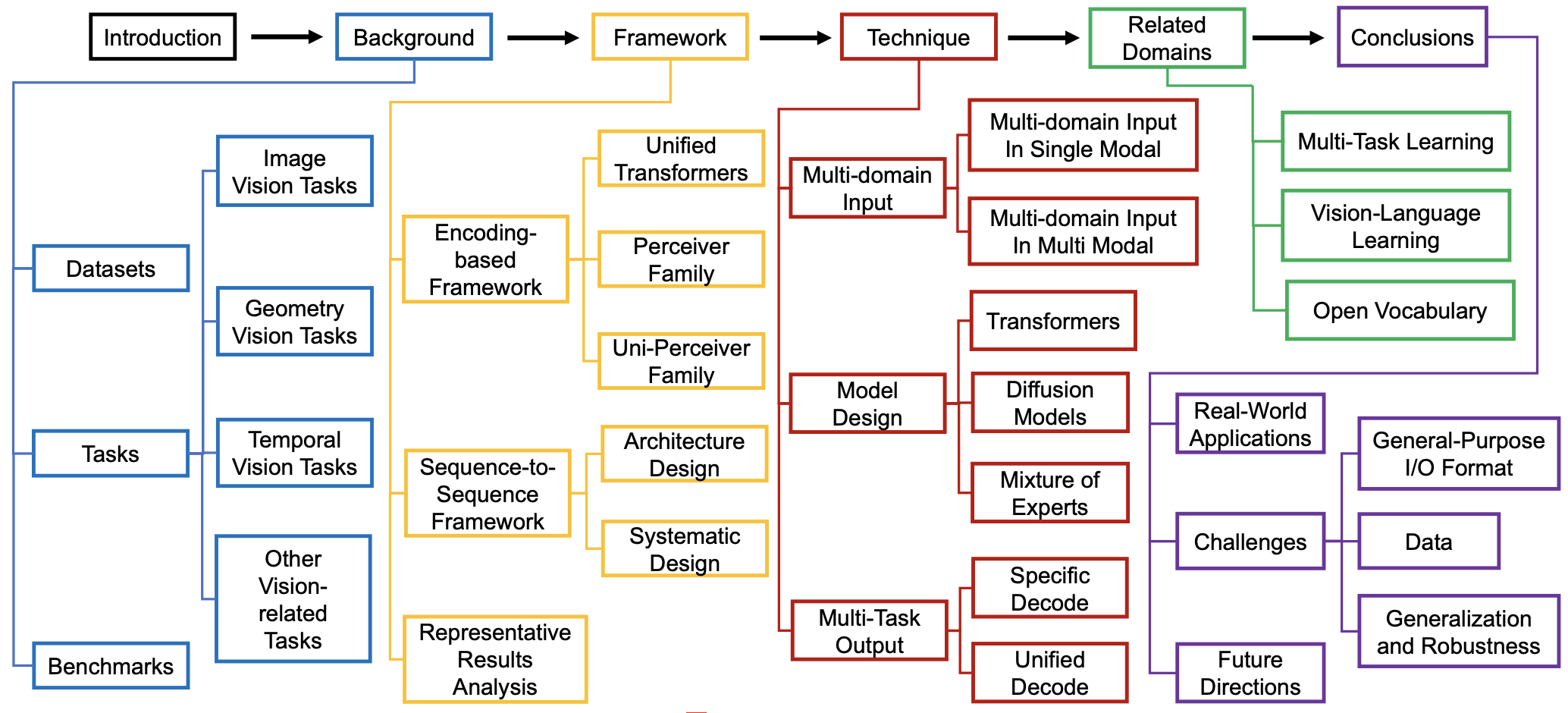 |
Vision Generalist Model: A Survey Ziyi Wang,Yongming Rao, Shuofeng Sun, Xinrun Liu,Yi Wei,Xumin Yu,Zuyan Liu,Yanbo Wang, Hongmin Liu, Jie Zhou , Jiwen Lu International Journal of Computer Vision (IJCV), 2025 [arXiv] We conduct a comprehensive survey on vision generalist models that support multimodal inputs and can handle various downstream tasks. |
|---|---|
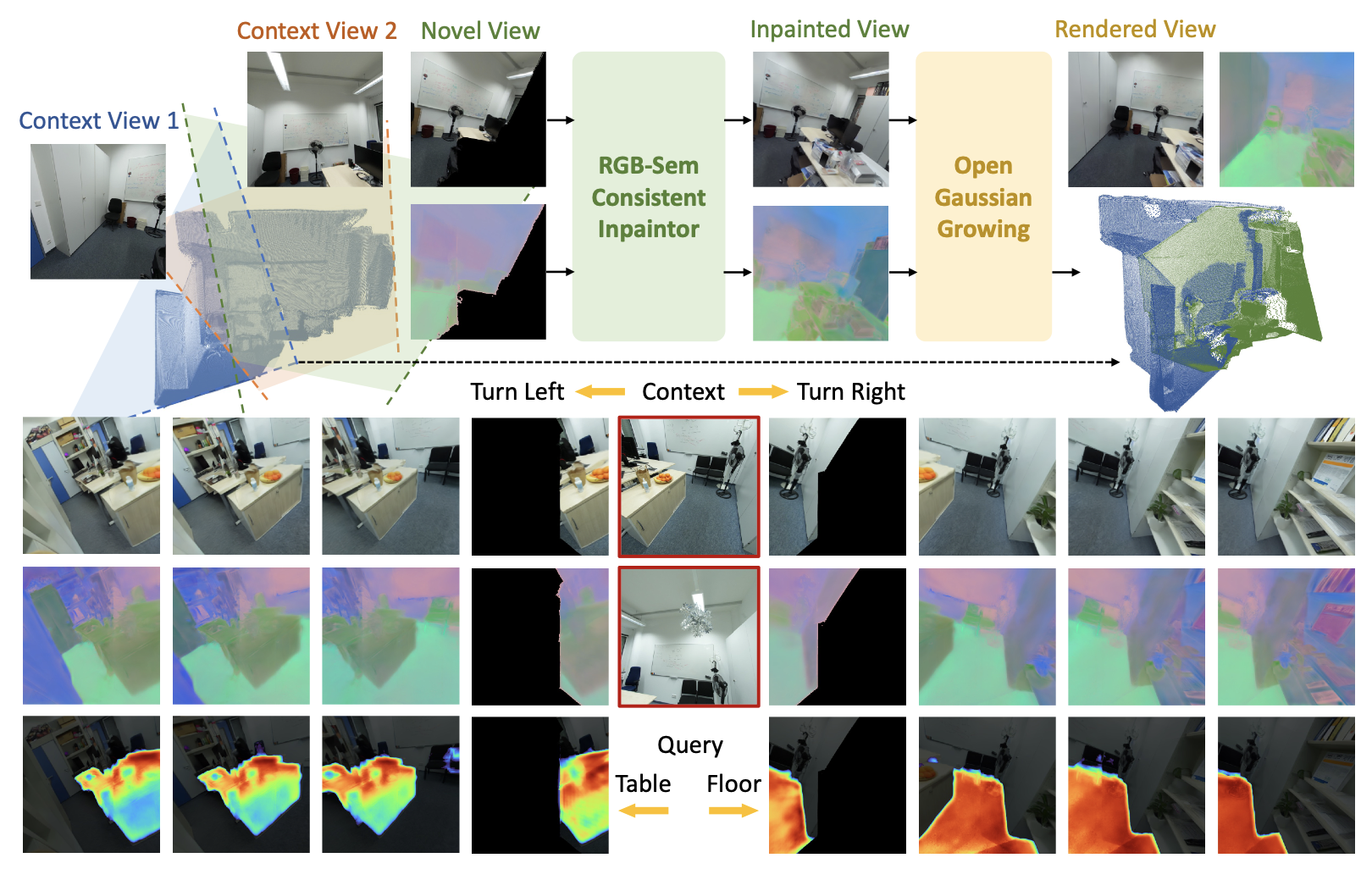 |
OGGSplat: Open Gaussian Growing for Generalizable Reconstruction with Expanded Field-of-View Yanbo Wang*,Ziyi Wang*,Wenzhao Zheng, Jie Zhou , Jiwen Lu Preprint. [arXiv] [Code] [Project Page] OGGSplat is designed to expand the field-of-view of the Gaussian-based 3D scene reconstructed from sparse views and feedforward / generalizable models. |
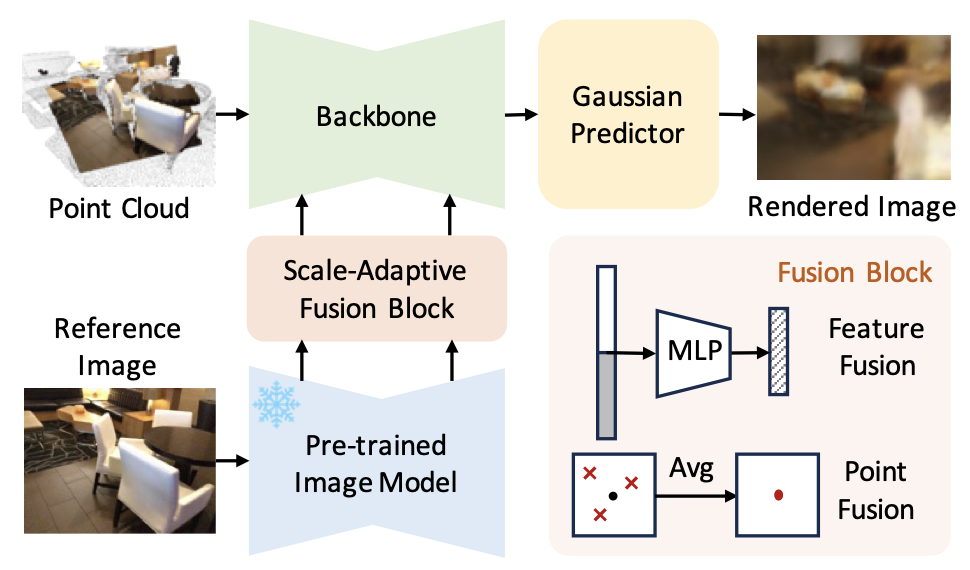 |
UniPre3D: Unified Pre-training of 3D Point Cloud Models with Cross-Modal Gaussian Splatting Ziyi Wang*,Yanran Zhang*, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [Code] UniPre3D is a unified pre-training method that can be applied to both object-level and scene-level point clouds. It is supported by cross-modal Gaussian splatting technique. |
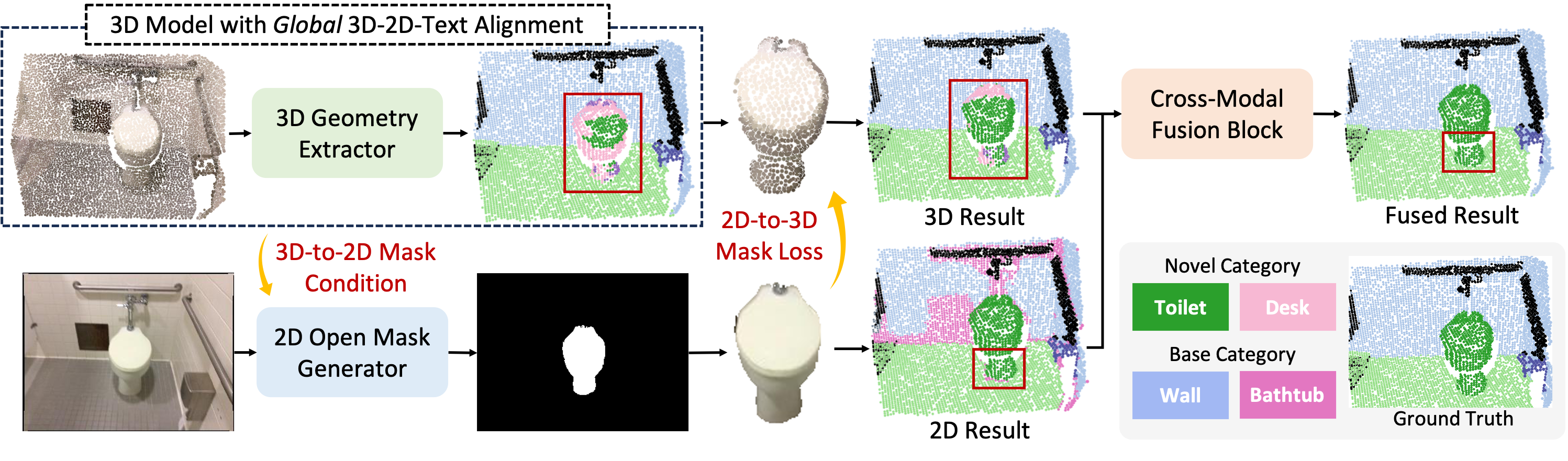 |
XMask3D: Cross-modal Mask Reasoning for Open Vocabulary 3D Semantic Segmentation Ziyi Wang*,Yanbo Wang*,Xumin Yu, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] XMask3D is a framework that propose mask-level reasoning techniques to empower 3D segmentation model with open vocabulary capacity under the assistance of the pre-trained 2D mask generator. |
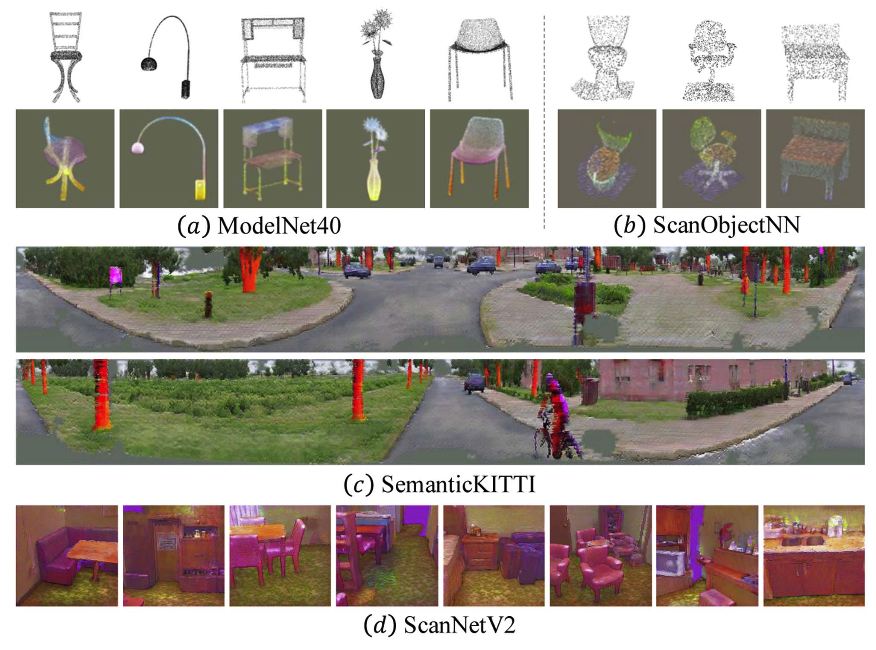 |
Point-to-Pixel Prompting for Point Cloud Analysis With Pre-Trained Image Models Ziyi Wang,Yongming Rao,Xumin Yu, Jie Zhou , Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 [IEEE] [Code] [Project Page] P2P++ is the extended journal version of P2P. We further propose Pixel-to-Point Distillation to make P2P applicable in scene-level perception tasks. |
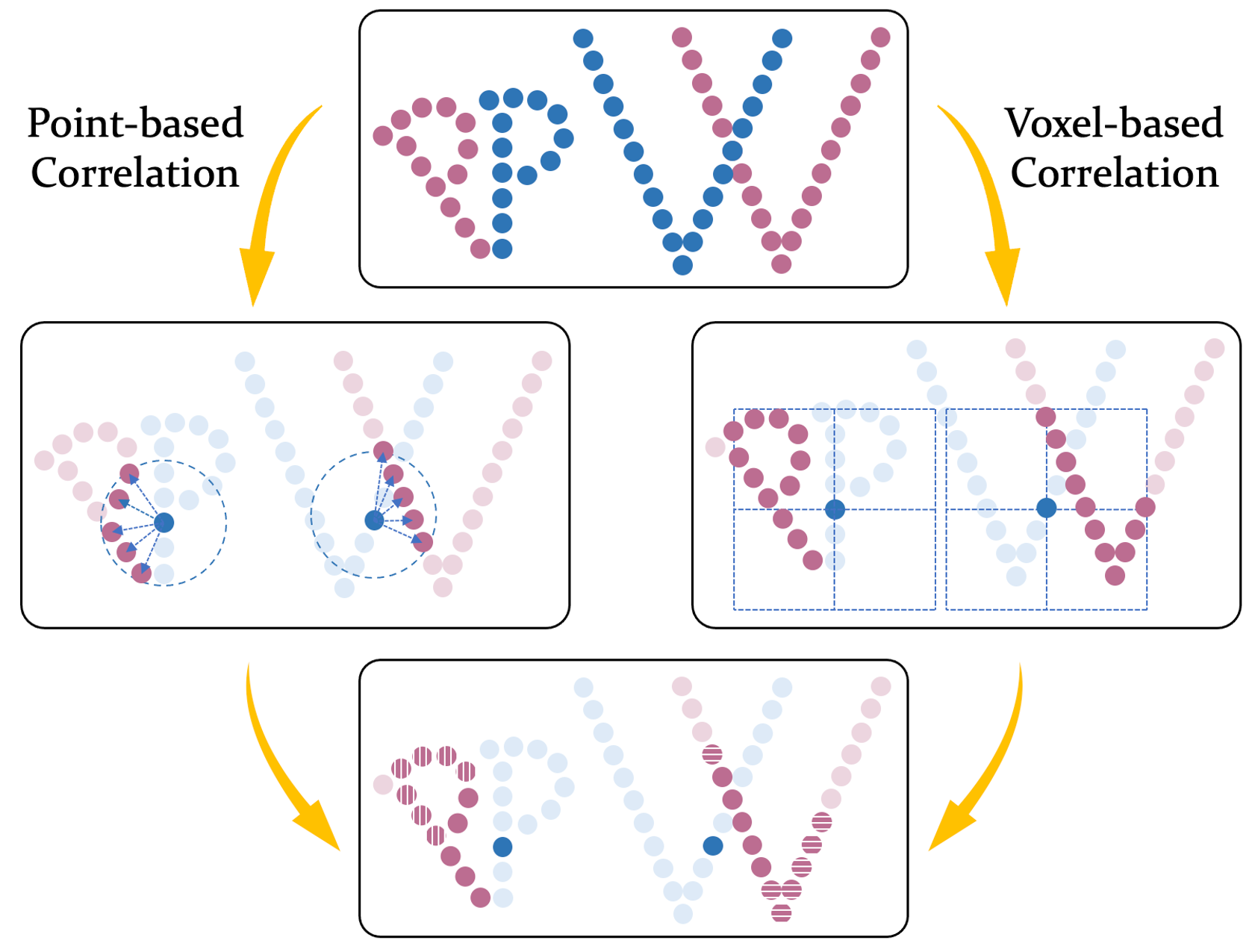 |
3D Point-Voxel Correlation Fields for Scene Flow Estimation Ziyi Wang*,Yi Wei*,Yongming Rao, Jie Zhou , Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023 [IEEE] [Code] [Project Page] DPV-RAFT is the extended journal version of PV-RAFT. We further propose Spatial Deformation and Temporal Deformation to enhance PV-RAFT. |
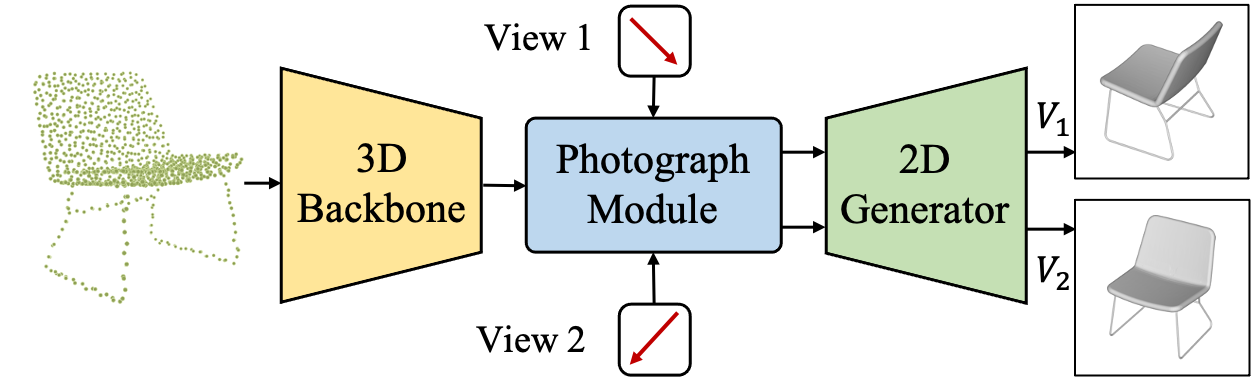 |
Take-A-Photo: 3D-to-2D Generative Pre-training of Point Cloud Models Ziyi Wang*,Xumin Yu*,Yongming Rao, Jie Zhou , Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023 [arXiv] [Code] [Project Page] TAP is a 3D-to-2D generative pre-training method that generate projected images of point clouds from instructed perspectives. |
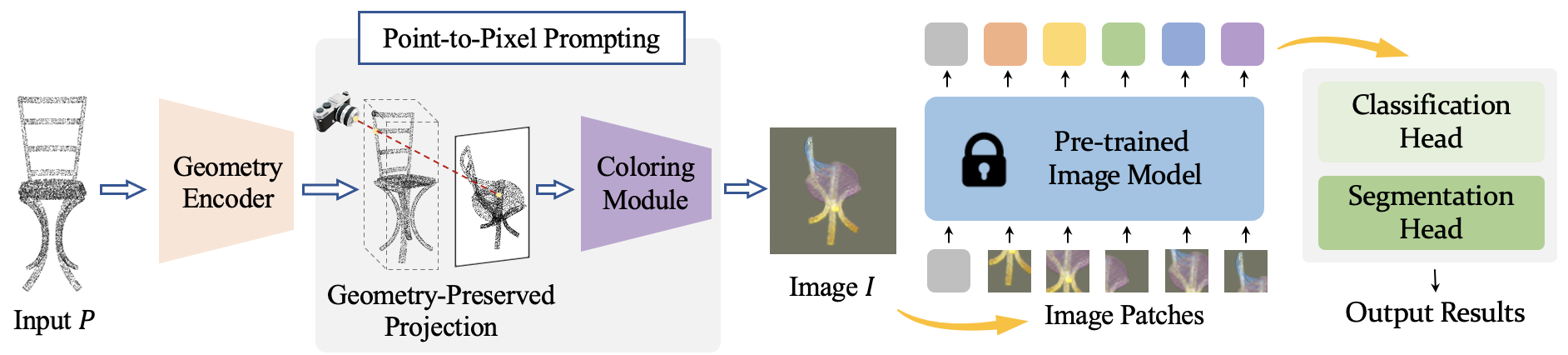 |
P2P: Tuning Pre-trained Image Models for Point Cloud Analysis with Point-to-Pixel Prompting Ziyi Wang*,Xumin Yu*,Yongming Rao*, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 Spotlight [arXiv] [Code] [Project Page] [中文解读] P2P is a framework to leverage large-scale pre-trained image models for 3D point cloud analysis. |
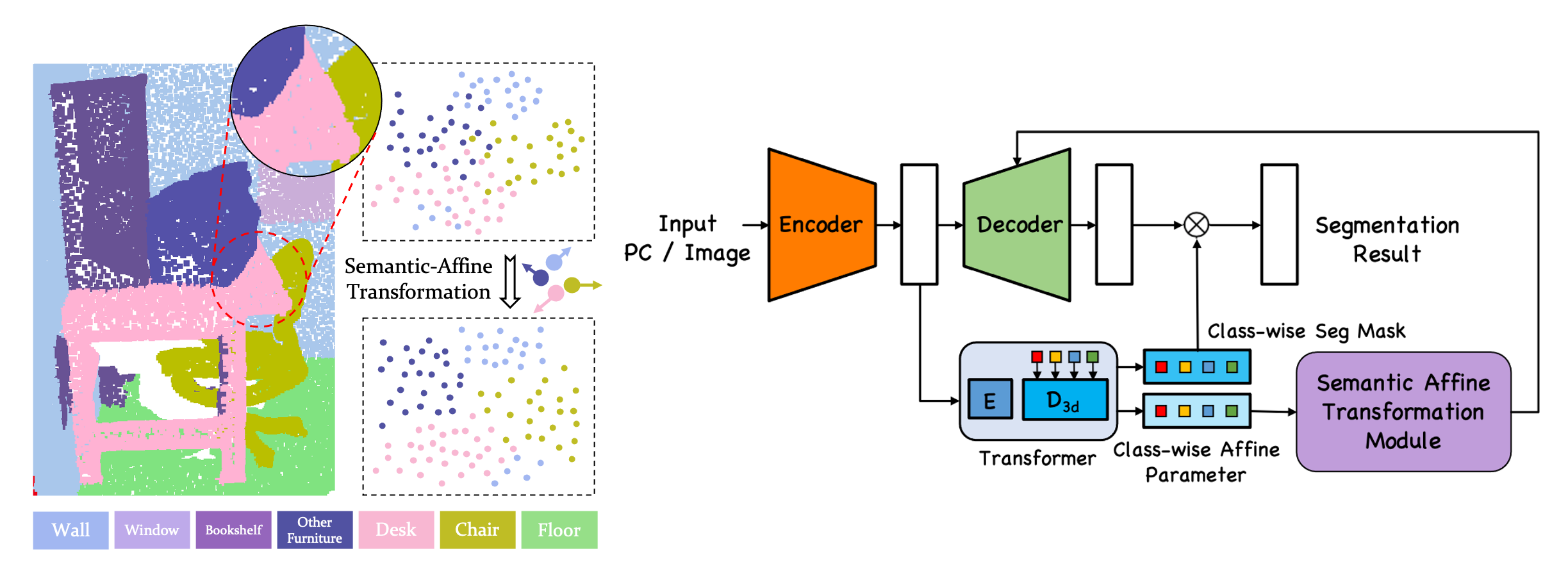 |
SemAffiNet: Semantic-Affine Transformation for Point Cloud Segmentation Ziyi Wang,Yongming Rao,Xumin Yu, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] We present Semantic-Affine Transformation that transforms decoder mid-level features of the encoder-decoder segmentation network with class-specific affine parameters. |
 |
PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers Xumin Yu*, Yongming Rao*,Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [Code] [中文解读] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |
 |
Towards Interpretable Deep Metric Learning with Structural Matching Wenliang Zhao*, Yongming Rao*,Zyi Wang, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We present a deep interpretable metric learning (DIML) that adopts a structural matching strategy to explicitly aligns the spatial embeddings by computing an optimal matching flow between feature maps of the two images. |
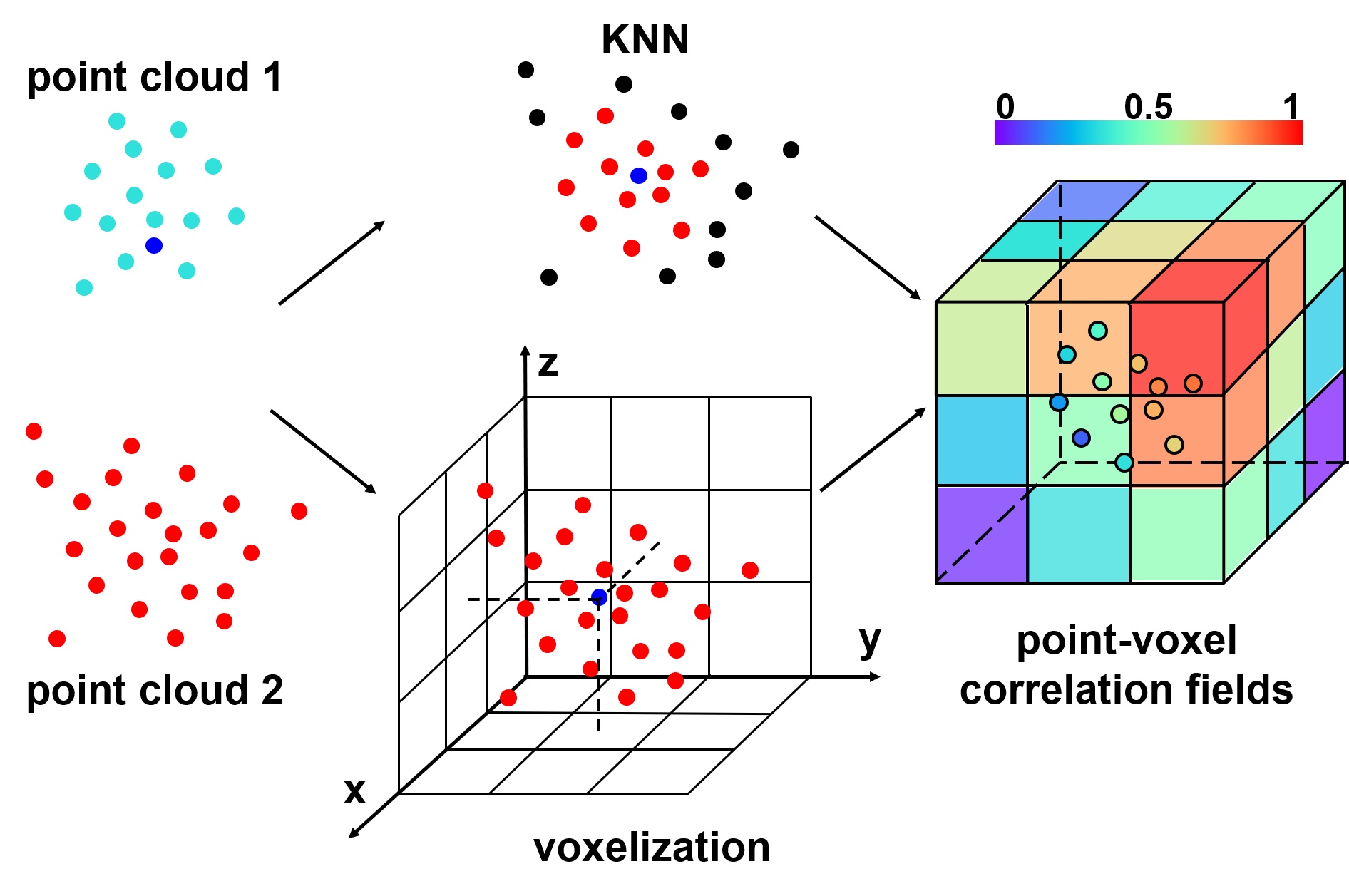 |
PV-RAFT: Point-Voxel Correlation Fields for Scene Flow Estimation of Point Clouds Yi Wei *, Ziyi Wang*, Yongming Rao*, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [arXiv] [Code] We present point-voxel correlation fields for 3D scene flow estimation which migrates the high performance of RAFT and provides a solution to build structured all-pairs correlation fields for unstructured point clouds. |
Teaching
- Teaching Assistant, Computer Vision, 2024 Spring Semester
- Teaching Assistant, Pattern Recognition and Machine Learning, 2022 Fall Semester
Honors and Awards
- 2024 National Scholarship, Tsinghua University
- 2023 ChangXin Memory Scholarship, Tsinghua University
- 2023 CVPR Outstanding Reviewer
- 2021 Haining Talent Scholarship, Tsinghua University
- 2020 Excellent graduation thesis, Tsinghua University
- 2018 Zheng Geru Scholarship, Tsinghua University
- 2017 Hongqian Electronics Scholarship, Tsinghua University