IT Ticket Classification: The Simpler, the Better (original) (raw)
Abstract
Recently, automatic classification of IT tickets has gained notable attention due to the increasing complexity of IT services deployed in enterprises. There are multiple discussions and no general opinion in the research and practitioners' community on the design of IT ticket classification tasks, specifically the choice of ticket text representation techniques and classification algorithms. Our study aims to investigate the core design elements of a typical IT ticket text classification pipeline. In particular, we compare the performance of TF-IDF and linguistic features-based text representations designed for ticket complexity prediction. We apply various classifiers, including kNN, its enhanced versions, decision trees, naïve Bayes, logistic regression, support vector machines, as well as semi-supervised techniques to predict the ticket class label of low, medium, or high complexity. Finally, we discuss the evaluation results and their practical implications. As our study shows, linguistic representation not only proves to be highly explainable but also demonstrates a substantial prediction quality increase over TF-IDF. Furthermore, our experiments evidence the importance of feature selection. We indicate that even simple algorithms can deliver highquality prediction when using appropriate linguistic features.
Figures (13)

Table | summarizes the strengths and weaknesses of the discussed techniques. TABLE 1. Text representation techniques.

TABLE 2. Text classification techniques.

Ticket example: "Refresh service registry on the XYZ-ZZ YYY server. See attachment for details." 1) OBJECTIVE KNOWLEDGE ASPECT

FIGURE 1. When sampling the data, the size r of the sample should be chosen carefully so that the sampled data is representative. Each U“) is a random subset of U containing r instances (\U| =r). For simplicity, each instance has the same prob- ability of being selected. To train the j-th classifier, we use all the labeled instances in L together with U. When sampling the data, the size r of the sample should be chosen carefully so that the sampled data is representative in the sense that the structure of the classes can be learned. This is illustrated in Figure 1.

TABLE 4. Datasets. The data was pre-processed (step 2) by removing stop words, punctuation, turning to lowercase, stemming and converted into a CSV-formatted corpus of ticket texts. The tickets texts contained prevailingly English texts (more than 80% of English words, a small portion of German words was present). The second dataset (Data2) comprised 4,684 entries in prevailingly English language from the period January — May 2019. The length of IT ticket texts varies from 5-10 words to 120-150.


TABLE 5. Execution time (in seconds) and accuracy of SUCCESS and QuickSUCCESS. D. RESULTS

TABLE 6. Evaluation results using linguistic features and TF-IDF.
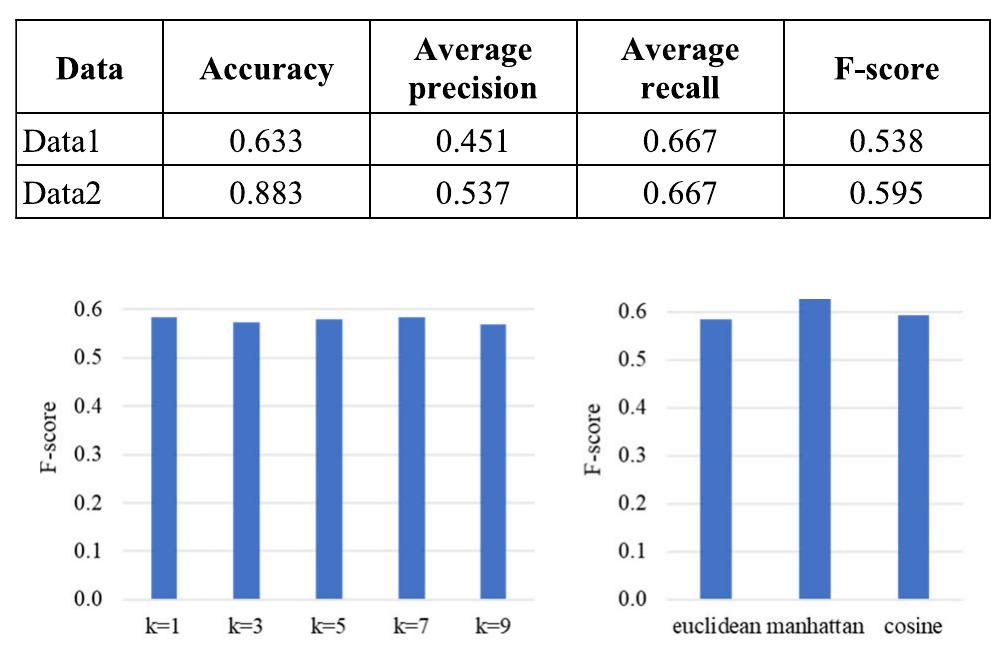
FIGURE 3. KNN performance with various k values (in the left, using Euclidean distance) and distance functions (in the right, k=1) on Data2. TABLE 9. Evaluation results using expert decision rule. with recent classifiers that have not been used for ticket classification before, and (ii) limitations of our rule-based approach.

TABLE 7. Evaluation results using the five best performing linguistic features.
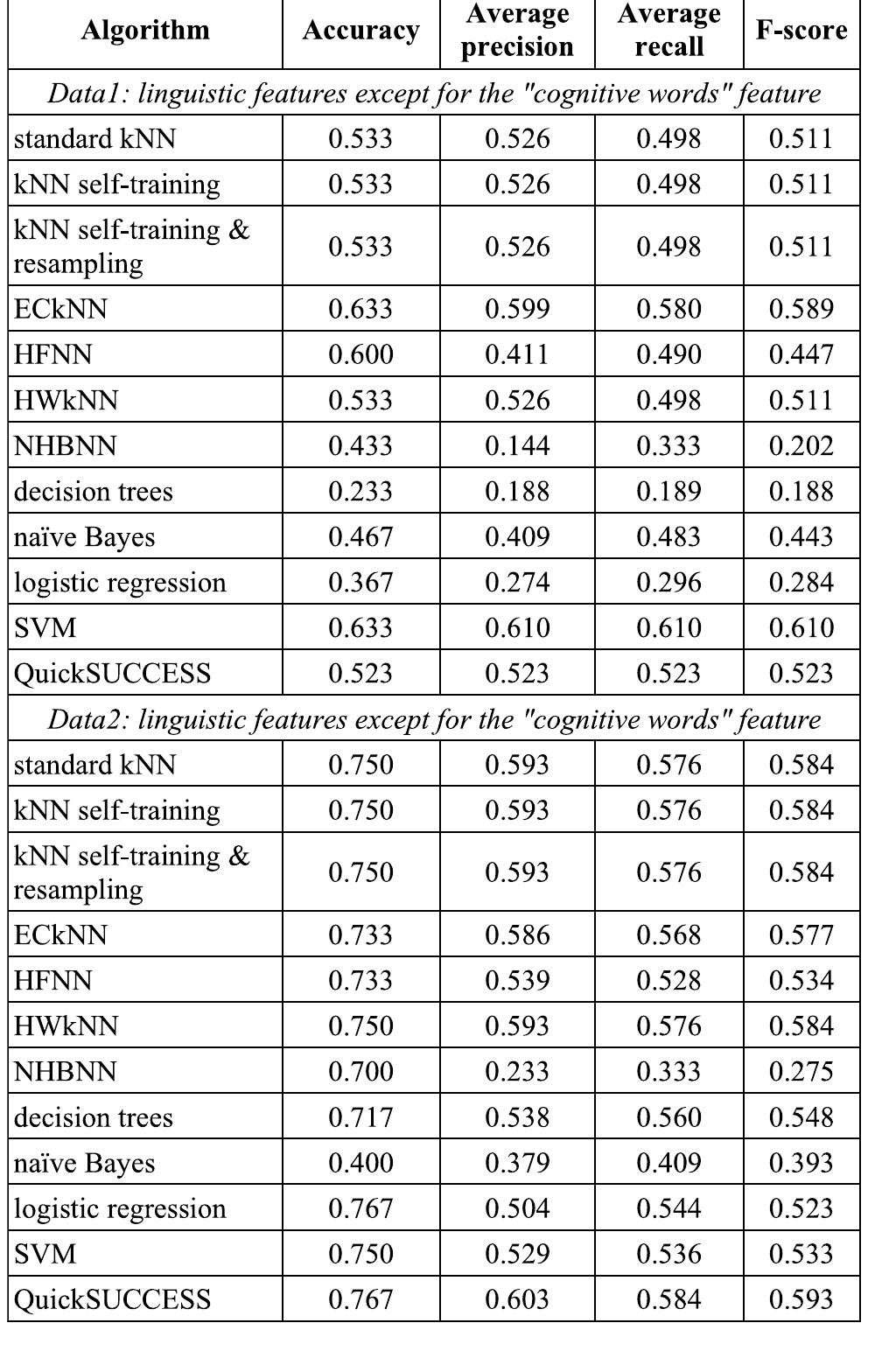
TABLE 8. Evaluation results using linguistic features without “cognitive words” feature.



Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.