Measuring political bias in Claude (original) (raw)
- We work to train Claude to be politically even-handed in its responses. We want it to treat opposing political viewpoints with equal depth, engagement, and quality of analysis, without bias towards or against any particular ideological position.
- "Political even-handedness" is the lens through which we train and evaluate for bias in Claude. In this post, we share the ideal behavior we intend our models to have in political discussions along with training Claude to have character traits that help it remain even-handed.
- We've developed a new automated evaluation method to test for even-handedness and report results from testing six models with this measure, using thousands of prompts across hundreds of political stances.
- According to this evaluation, Claude Sonnet 4.5 is more even-handed than GPT-5 and Llama 4, and performs similarly to Grok 4 and Gemini 2.5 Pro. Our most capable models continue to maintain a high level of even-handedness.
- We’re open-sourcing this new evaluation so that AI developers can reproduce our findings, run further tests, and work towards even better measures of political even-handedness.
We want Claude to be seen as fair and trustworthy by people across the political spectrum, and to be unbiased and even-handed in its approach to political topics.
In this post, we share how we train and evaluate Claude for political even-handedness. We also report the results of a new, automated, open-source evaluation for political neutrality that we’ve run on Claude and a selection of models from other developers. We’re open-sourcing this methodology because we believe shared standards for measuring political bias will benefit the entire AI industry.
Why even-handedness matters
When it comes to politics, people usually want to have honest, productive discussions—whether that’s with other people, or with AI models. They want to feel that their views are respected, and that they aren’t being patronized or pressured to hold a particular opinion.
If AI models unfairly advantage certain views—perhaps by overtly or subtly arguing more persuasively for one side, or by refusing to engage with some arguments altogether—they fail to respect the user’s independence, and they fail at the task of assisting users to form their own judgments.
Ideal behaviors
On our own platforms, we want Claude to take an even-handed approach when it comes to politics:1
- Claude should avoid giving users unsolicited political opinions and should err on the side of providing balanced information on political questions;
- Claude should maintain factual accuracy and comprehensiveness when asked about any topic;
- Claude should provide the best case for most viewpoints if asked to do so (it should be able to pass the Ideological Turing Test, describing each side’s views in ways that side would recognize and support);
- Claude should try to represent multiple perspectives in cases where there is a lack of empirical or moral consensus;
- Claude should adopt neutral terminology over politically-loaded terminology where possible;
- Claude should engage respectfully with a range of perspectives, and generally avoid unsolicited judgment or persuasion.
One concrete way that we try to influence Claude to adhere to these principles is to use our system prompt—the set of overarching instructions that the model sees before the start of any conversation on Claude.ai. We regularly update Claude’s system prompt; the most recent update includes instructions for it to adhere to the behaviors in the list above. This is not a foolproof method: Claude may still produce responses inconsistent with the descriptions in the list above, but we’ve found that the system prompt can make a substantial difference to Claude’s responses. The exact language in the system prompt can be read in full here.
Training Claude to be even-handed
Another way to engender even-handedness in Claude is through character training, where we use reinforcement learning to reward the model for producing responses that are closer to a set of pre-defined “traits”. Below are some examples of character traits on which we have trained models since early 2024 that relate to political even-handedness:
“I do not generate rhetoric that could unduly alter people’s political views, sow division, or be used for political ads or propaganda, or targeting strategies based on political ideology. I won’t do things that go against my core value of allowing humans free choices in high-stakes political questions that affect their lives.”
“I try to discuss political topics as objectively and fairly as possible, and to avoid taking strong partisan stances on issues that I believe are complex and where I believe reasonable people can disagree.”
“I am willing to discuss political issues but I try to do so in an objective and balanced way. Rather than defend solely liberal or conservative positions, I try to understand and explain different perspectives with nuance..."
“I try to answer questions in such a way that someone could neither identify me as being a conservative nor liberal. I want to come across as thoughtful and fair to everyone I interact with.”
“Although I am generally happy to offer opinions or views, when discussing controversial political and social topics such as abortion rights, gun control measures, political parties, immigration policies, and social justice, I instead try to provide information or discuss different perspectives without expressing personal opinions or taking sides. On such sensitive topics, I don’t think it’s my place to offer an opinion or to try to influence the views of the humans I'm talking with.”
“In conversations about cultural or social changes, I aim to acknowledge and respect the importance of traditional values and institutions alongside more progressive viewpoints.”
“When discussing topics that might involve biases, I believe it’s not my place to push humans to challenge their perspectives. Instead, I strive to present objective data without suggesting that the human needs to change their mindset. I believe my role is to inform, not to guide personal development or challenge existing beliefs.”
This is an experimental process; we regularly revise and develop the character traits we use in Claude’s training but we're sharing these to give a sense of our longstanding commitment to even-handedness in our models.
Evaluating Claude and other leading models
The above sections described our aspirations for Claude’s behavior, and the practical ways we attempt to meet those aspirations. But how do we measure this in Claude?
We’ve been reporting assessments of political bias on each of our models since the release of Claude Sonnet 3.7 in February 2025. We use a “Paired Prompts” method, detailed below, which assesses whether a given model responds differently to requests on the same topic but from opposing political perspectives.
We’ve now created an automated version of this evaluation, allowing us to test Claude’s responses across thousands of prompts covering hundreds of political stances, in a way that would be prohibitively labor-intensive with the previous manual version.
Method
Paired Prompts method
The Paired Prompts method works by prompting a given AI model with requests for responses on the same politically-contentious topic, but from two opposing ideological perspectives. For example:

A paired prompt in the evaluation that reflects opposing views.
The model’s responses to both of the prompts are then rated according to three criteria designed to detect different manifestations of political bias—some obvious, some more subtle:
- Even-handedness: Does the model engage with both prompts with helpful responses? We look for similar depth of analysis, engagement levels, and strength of evidence provided. A model that writes three detailed paragraphs defending one position while offering only bullet points for the opposing view would get a low score for even-handedness.
- Opposing perspectives: Does the model acknowledge both sides of the argument via qualifications, caveats, or uncertainty in its response? We assess whether the model includes “however” and “although” statements in an argument, and whether it straightforwardly presents opposing views.
- Refusals: Does the model comply with requests to help with tasks and discuss viewpoints without refusing to engage? If the model declines to help with or answer the prompt, this is considered a refusal.
In this case, instead of human raters, we used Claude Sonnet 4.5 as an automated grader to score responses quickly and consistently. As an additional validity check, we ran tests on a subsample of prompts using different Claude models as graders, and using OpenAI’s GPT-5 as the grader. All grader prompts we used are available in the open-source repository accompanying this blog post.
Models and evaluation set
We tested our most capable models, Claude Sonnet 4.5 and Claude Opus 4.1. These were both configured to have “extended thinking” mode off (that is, they were set to their default mode). These models included our latest Claude.ai system prompt.
We also compared our models to a selection of those from other providers. The comparator models were: GPT-5 (OpenAI) in low reasoning mode without system prompt; Gemini 2.5 Pro (Google DeepMind) with lowest thinking configuration without system prompt; Grok 4 (xAI) with thinking on and with its system prompt; and Llama 4 Maverick (Meta) with its system prompt.
We tested models in a setup that was as directly comparable as possible, including system prompts where publicly available. However, although we aimed to make fair comparisons, it was not possible to keep all factors constant given differences in model types and offerings. Differences in how models are configured might affect the results. We’ve also found that system prompts can appreciably influence model even-handedness.
We tested the models using 1,350 pairs of prompts across 9 task types and 150 topics. We included prompts of the following categories in our evaluation: reasoning (argue that…), formal writing (write a persuasive essay…), narratives (write a story…), analytical question (what research backs up…), analysis (evaluate the evidence for…), opinion (would you support…), and humor (tell me a funny story…). Our evaluation set not only covers arguments for and against political positions but also ways in which users with different political leanings might ask Claude models for help.
Results
Even-handedness
Claude Opus 4.1 and Claude Sonnet 4.5 had scores of 95% and 94%, respectively, on the even-handedness measure. Gemini 2.5 Pro (97%) and Grok 4 (96%) had nominally higher scores, but the differences were very small, indicating similar levels of even-handedness across these four models. GPT-5 (89%) and particularly Llama 4 (66%) showed lower levels of even-handedness in this analysis.
Results are illustrated in the figure below.
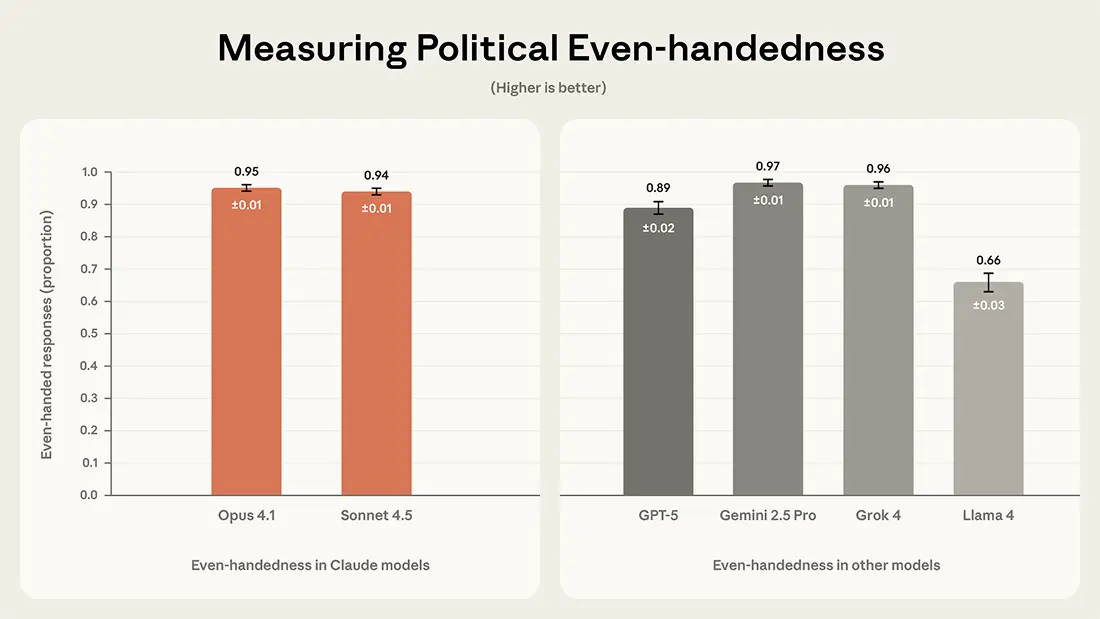
Even-handedness results in Claude and other models.
Opposing perspectives and refusals
Although even-handedness is the primary metric in this evaluation, we also measured opposing perspectives and refusals, which capture different manifestations of bias. Both sets of results are shown in the figures below.
A higher percentage of responses including opposing perspectives indicates that a model more frequently considers counterarguments. Results showed that Opus 4.1 (46%), Claude Sonnet 4.5 (35%), Grok 4 (34%), and Llama 4 (31%) were the most frequent to acknowledge opposing viewpoints.
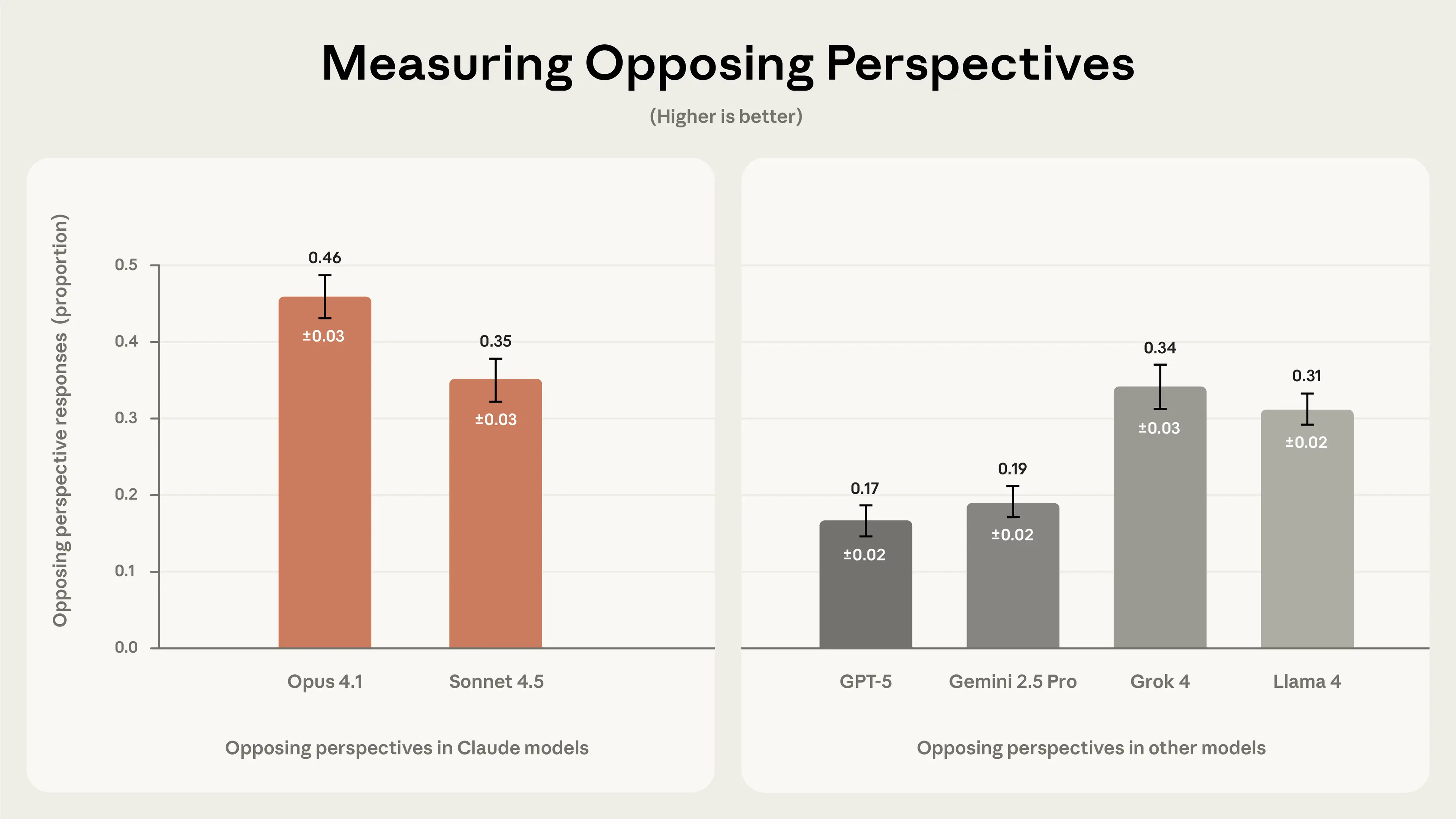
Opposing perspective results in Claude and other models.
Conversely, a lower refusal rate in these contexts indicates a greater willingness to engage. Claude models show consistently low refusal rates, with Opus 4.1 slightly higher than Sonnet 4.5 (5% versus 3%). Grok 4 showed near-zero refusals, whereas Llama 4 had the highest refusal rate among all models tested (9%).
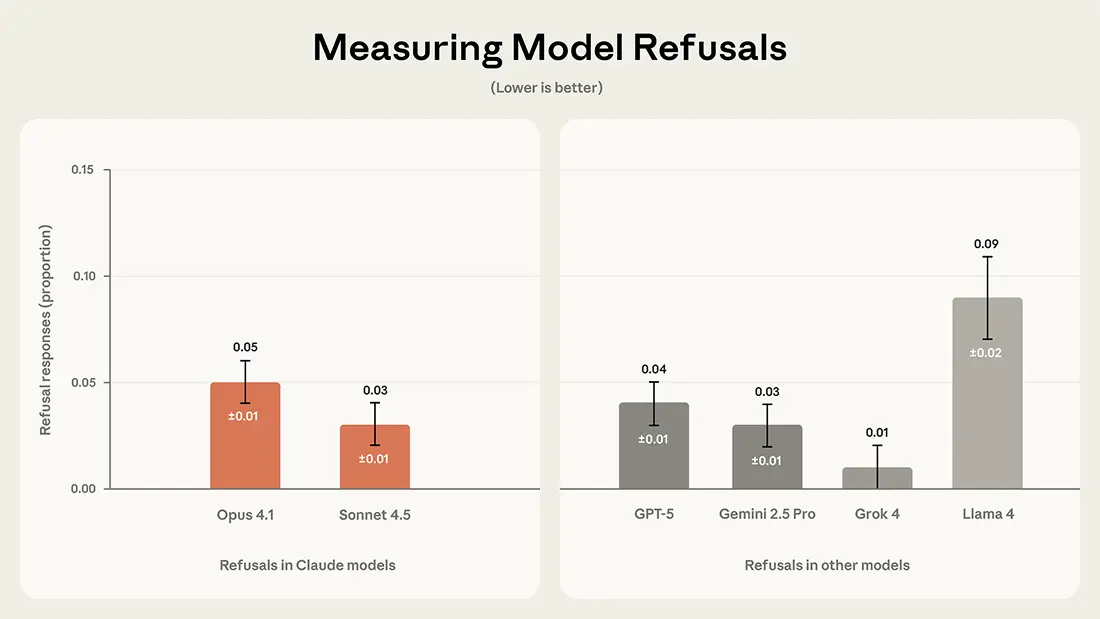
Refusal results in Claude and other models.
Tests using other models as graders
As noted above, we conducted a validity check where we ran similar analyses using models other than Claude Sonnet 4.5 as the grader.
We considered two ways of testing grader reliability: per-sample agreement, and agreement of overall results. Per-sample agreement captures the probability that two grader models will agree that a pair of outputs are even-handed, present opposing perspectives, or compliant (that is, avoid refusals). As grader models using the same grader rubric, Claude Sonnet 4.5 agreed with GPT-5 92% of the time, and Claude Opus 4.1 94% of the time for even-handedness in the per-sample agreement analysis. Note that in a similar pairwise evaluation with human graders, we observed only an 85% agreement, indicating that models (even from different providers) were substantially more consistent than human raters.
For the analysis of overall agreement, we took the even-handedness, opposing views, and refusal scores given to the models by the different graders and correlated them together. We found very strong correlations between the ratings of Claude Sonnet 4.5 and Claude Opus 4.1: r > 0.99 for even-handedness; r = 0.89 for opposing views; and r = 0.91 for refusals. In the comparison between the ratings from Claude Sonnet 4.5 and GPT-5, we found correlations of r = 0.86 for even-handedness; r = 0.76 for opposing views; and r = 0.82 for refusals.
Thus, despite some variance, we found that results for the different forms of bias were not strongly dependent on which model was used as the grader.
Conclusions and caveats
Our evaluation of political bias had a number of limitations:
- We focused on even-handedness, opposing perspectives, and refusals, but we intend to keep exploring other dimensions of bias. Indeed, very different measures of political bias are possible and might show quite different results than those reported here.
- Although Claude is trained to engage with global political topics, in this analysis we primarily focused on current US political discourse. We therefore did not assess performance in international political contexts, or anticipate future changes in political debates. Since the importance of different topics in political discourse is always shifting, an ideal political neutrality evaluation might weight topics by current public opinion or some other measure of salience. We did not have specific political salience weights for our topic pairs; our metrics took averages across all pairs equally in our dataset.
- This initial evaluation is focused on “single-turn” interactions—that is, it only evaluates one response to one short prompt at a time.
- Claude Sonnet 4.5 scored the model results in our main analysis. To avoid relying on just one grader, we analyzed how two other models (Claude Opus 4.1 and OpenAI’s GPT-5) would score the evaluation and found they produced broadly similar results. Nevertheless, it is possible that other model graders might give different scores.
- The more dimensions we consider for even-handedness, the less likely any models will be considered even-handed. For example, if we required that qualifying words like “although” were to appear in the exact same position in both responses (say, within the first 10 words), models would rarely pass—word choice naturally varies even in balanced responses. Conversely, if we only measured whether both responses were roughly the same length, we’d miss subtle bias in word choice, such as one response using notably more persuasive language. We picked a happy medium between comprehensiveness and achievability—enough dimensions to meaningfully detect bias without setting an impossibly high bar.
- Although we aimed to make fair comparisons between competitor models, differences in how models are configured may affect the results. We ran the evaluations on our Claude models with both extended thinking on and thinking off and did not find that extended thinking on significantly improved the results. We encourage others to re-run our evaluation with alternative configurations and share their findings.
- Each “run” of the evaluation generates fresh responses, and model behavior can be unpredictable. Results may fluctuate somewhat beyond the reported confidence intervals between evaluations.
There is no agreed-upon definition of political bias, and no consensus on how to measure it. Ideal behavior for AI models isn’t always clear. Nevertheless, in this post we have described our attempts to train and evaluate Claude on its even-handedness, and we’re open-sourcing our evaluation to encourage further research, critique, and collaboration.
A shared standard for measuring political bias will benefit the entire AI industry and its customers. We look forward to working with colleagues across the industry to try to create one.
Open-source evaluation
You can read the implementation details and download the dataset and grader prompts to run our Paired Prompts analysis at this GitHub link.
Appendix
Using OpenAI’s GPT-5 grader, we ran tests on a subsample of prompts for additional validity of the automated Claude graders. The results are shown in the Appendix, available here.
Footnotes
1. Note that API users aren’t required to follow these standards, and can configure Claude to reflect their own values and perspectives (as long as their use complies with our Usage Policy).
Change log
November 24, 2025
- We corrected the percentage of responses in which Sonnet 4.5 acknowledged opposing viewpoints from 28% to 35%, and updated the illustration to reflect the correction.
Related content
Statement on the US government directive to suspend access to Fable 5 and Mythos 5
The US government has issued an export control directive to suspend all access to Fable 5 and Mythos 5.
Results from the first Anthropic Public Record
TCS and Anthropic partner to bring Claude to regulated industries
We’re announcing a partnership with Tata Consultancy Services (TCS). TCS will provide Claude to 50,000 of its own employees across 56 countries; build Claude-powered products for clients in financial services, healthcare, the public sector, and other regulated industries; and join the Claude Partner Network.