Instruction Tuning for Large Language Models (original) (raw)
Last Updated : 8 May, 2026
Instruction tuning is a technique where a pre-trained language model is fine-tuned on instruction–response pairs to improve its ability to follow user directions. It focuses on making models more adaptable and usable in real-world applications.
- Helps the model understand and execute natural language instructions
- Improves generalization across diverse tasks
- Aligns responses better with user intent
**Why is Instruction Tuning Important?
**1. Enhanced Usability
Without instruction tuning, large language models (LLMs) may generate responses that are technically correct but fail to address the user's intent. For instance, a user asking for a concise summary might receive an overly verbose response. Instruction tuning ensures the model adheres to the user's expectations.
**2. Generalization Across Tasks
Modern LLMs are expected to handle a wide range of tasks—from answering questions to writing code, generating reports, or even providing emotional support. Instruction tuning equips the model with the flexibility to perform well across diverse scenarios.
**3. Reduced Hallucinations
One common challenge with LLMs is their tendency to "hallucinate"—generate plausible but incorrect information. By emphasizing alignment with instructions, instruction tuning reduces the likelihood of such errors.
**Working of Instruction Tuning
The process of instruction tuning typically involves the following steps:
**Step 1: Data Collection
A dataset of instruction-output pairs is curated. These pairs should cover a broad spectrum of tasks, including both simple and complex instructions.
Examples include:
- **Instruction: "Translate the following sentence into French."
- **Output: "La phrase traduite en français."
**Step 2: Model Fine-Tuning
The pre-trained LLM is fine-tuned on this dataset using supervised learning techniques. During training, the model learns to map instructions to appropriate outputs.
**Step 3: Evaluation and Iteration
After fine-tuning, the model is evaluated on a validation set to assess its ability to follow instructions accurately. If necessary, additional data or rounds of fine-tuning are performed to improve performance.
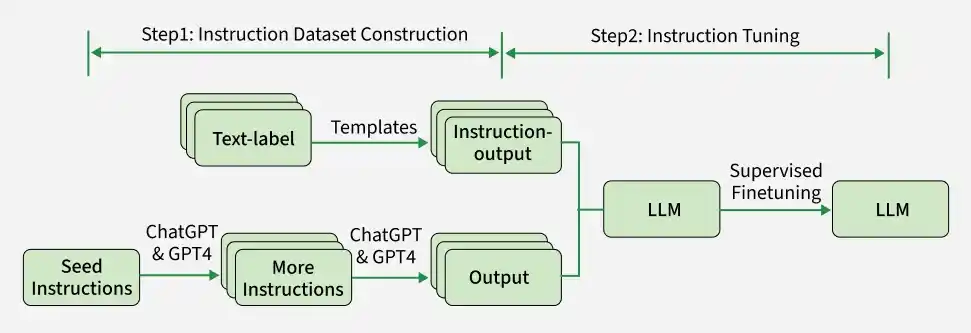
Working
**Instruction Tuning vs. Multi-Task Fine-Tuning
Multi-task fine tuning is a method to train the LLM on datasets associated with multiple predefined tasks. Both multi-task fine tuning and instruct tuning enhances the capabilities of large language models but, there are following differences:
| Instruction Tuning | Multi-task Fine-tuning |
|---|---|
| Teaches the model to follow explicit instructions and generalize across diverse tasks. | Optimize the model's performance on predefined, specific tasks. |
| Enhance adaptability and alignment with user intent for open-ended or novel instructions. | Improve accuracy and efficiency on a set of specialized, task-specific objectives. |
| Prioritize generalization, enabling the model to handle new or unseen instructions and tasks. | Focuses on specialization, limiting the model’s ability to generalize beyond its predefined tasks. |
| Datasets composed of instruction-output pairs covering a wide variety of tasks and instructions. | Task-specific datasets, where each dataset corresponds to a particular task (e.g., sentiment analysis). |
Characteristics of Instruction-Tuning Datasets
- **Instruction-Output Pairs: Each entry in an instruction-tuning dataset consists of an **instruction (a directive or question) and its corresponding **output (the desired response).
- **Natural Language Instructions: Instructions are written in natural language, making them accessible and interpretable by both humans and models. This ensures the model learns to understand human-like input formats.
- **High-Quality Outputs: The outputs in the dataset must be accurate, well-structured, and aligned with the instructions. Poor-quality outputs can lead to misaligned behavior in the fine-tuned model.
**Examples
**1. FLAN (Fine-tuned LAnguage Net) :
- A collection of datasets used to fine-tune language models on a wide range of tasks, including summarization, translation, and question-answering.
- FLAN includes over 1,800 tasks and is designed to improve generalization across unseen tasks.
- Introduced by Google Research in the paper _"Scaling Instruction-Finetuned Language Models" .
**2. Super-Natural Instructions
- A dataset containing 617 diverse tasks, each described in natural language instructions.
- Focuses on teaching models to follow complex instructions, such as generating recipes, solving puzzles, or rewriting text in a specific style.
- Developed by researchers at Microsoft and other institutions.
**3. Alpaca
- A dataset derived from OpenAI's GPT-3.5, containing 52,000 instruction-output pairs.
- Designed to make smaller models behave like larger ones by teaching them to follow instructions effectively.
- Created by Stanford University.
**4. OpenAssistant Dataset
- A crowdsourced dataset containing conversational instruction-response pairs.
- Emphasizes conversational AI and dynamic interactions, making it ideal for training chatbots and virtual assistants.
- Developed by the LAION community.
**5. Self-Instruct
- A method for generating synthetic instruction-tuning datasets using LLMs themselves.
- Enables the creation of large-scale datasets without extensive human annotation.
- Introduced by researchers at the University of Washington.
Challenges
While instruction tuning is powerful, there are some challenges:
- **Data Quality: Quality of the instructions and examples provided during fine-tuning is crucial. If the data is not diverse or clear enough, the model’s output can be inaccurate.
- **Overfitting: If the model is tuned too much for specific instructions, it may lose its generalization ability and fail at other tasks.
- **Model Bias: Model can inherit biases from the data it’s trained on. Ensuring fairness and diversity in the instructions is key to avoiding harmful biases.
- **Scalability: Instruction tuning may require large amounts of labeled data and computing power, which can be challenging and resource-intensive, especially for complex tasks.
- **Consistency: Ensuring that the model consistently follows instructions across various scenarios can be difficult. It might provide different responses to similar instructions, making it harder to maintain reliability.
Applications
Instruction tuning can be applied in various industries:
- **Customer Service: AI chatbots that understand user queries and provide relevant solutions based on specific instructions.
- **Education: AI tutors that can adapt to different learning styles and provide personalized guidance to students.
- **Content Creation: Models that generate tailored articles, reports or blog posts according to user preferences.
- **Healthcare: AI-powered virtual health assistants that offer personalized health advice based on user symptoms or medical history.
- **E-commerce: AI that recommends products based on customer preferences and browsing behavior.
- **Marketing & Advertising: AI that generates personalized ad content by following specific instructions related to tone, audience, and goals.
Instruction tuning holds the promise of making AI more adaptive and capable, offering personalized and accurate responses across various industries. As the technology continues to improve, it will play a crucial role in shaping smarter, more efficient AI systems capable of handling increasingly complex and diverse tasks.