Introduction to Hadoop (original) (raw)
Last Updated : 24 Jun, 2025
Hadoop is an open-source software framework that is used for storing and processing large amounts of data in a distributed computing environment. It is designed to handle big data and is based on the MapReduce programming model, which allows for the parallel processing of large datasets. Its framework is based on Java programming with some native code in C and shell scripts.
Hadoop is designed to process large volumes of data (Big Data) across many machines without relying on a single machine. It is built to be scalable, fault-tolerant and cost-effective. Instead of relying on expensive high-end hardware, Hadoop works by connecting many inexpensive computers (called nodes) in a cluster.
Hadoop Architecture
Hadoop has two main components:
- **Hadoop Distributed File System (HDFS): HDFS breaks big files into blocks and spreads them across a cluster of machines. This ensures data is replicated, fault-tolerant and easily accessible even if some machines fail.
- **MapReduce: MapReduce is the computing engine that processes data in a distributed manner. It splits large tasks into smaller chunks (map) and then merges the results (reduce), allowing Hadoop to quickly process massive datasets.
Apart from the above-mentioned two core components, Hadoop framework also includes the following two modules **Hadoop Common which are Java libraries and utilities required by other Hadoop modules and **Hadoop YARN which is a framework for job scheduling and cluster resource management.
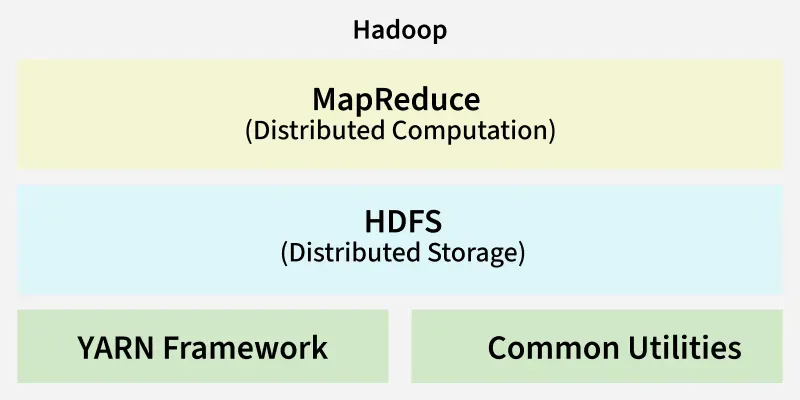
Hadoop Architecture
Hadoop Distributed File System (HDFS)
HDFS is the storage layer of Hadoop. It breaks large files into smaller blocks (usually 128 MB or 256 MB) and stores them across multiple DataNodes. Each block is replicated (usually 3 times) to ensure fault tolerance so even if a node fails, the data remains available.
**Key features of HDFS:
- **Scalability: Easily add more nodes as data grows.
- **Reliability: Data is replicated to avoid loss.
- **High Throughput: Designed for fast data access and transfer.
MapReduce
MapReduce is the computation layer in Hadoop. It works in two main phases:
- **Map Phase: Input data is divided into chunks and processed in parallel. Each mapper processes a chunk and produces key-value pairs.
- **Reduce Phase: These key-value pairs are then grouped and combined to generate final results.
This model is simple yet powerful, enabling massive parallelism and efficiency.
How Does Hadoop Work?
Here’s a overview of how Hadoop operates:
- Data is loaded into HDFS, where it's split into blocks and distributed across DataNodes.
- MapReduce jobs are submitted to the ResourceManager.
- The job is divided into map tasks, each working on a block of data.
- Map tasks produce intermediate results, which are shuffled and sorted.
- Reduce tasks aggregate results and generate final output.
- The results are stored back in HDFS or passed to other applications.
Thanks to this distributed architecture, Hadoop can process petabytes of data efficiently.
**Advantages and Disadvantages of Hadoop
**Advantages:
- **Scalability: Easily scale to thousands of machines.
- **Cost-effective: Uses low-cost hardware to process big data.
- **Fault Tolerance: Automatic recovery from node failures.
- **High Availability: Data replication ensures no loss even if nodes fail.
- **Flexibility: Can handle structured, semi-structured and unstructured data.
- **Open-source and Community-driven: Constant updates and wide support.
**Disadvantages:
- Not ideal for real-time processing (better suited for batch processing).
- Complexity in programming with MapReduce.
- High latency for certain types of queries.
- Requires skilled professionals to manage and develop.
Applications
Hadoop is used across a variety of industries:
- **Banking: Fraud detection, risk modeling.
- **Retail: Customer behavior analysis, inventory management.
- **Healthcare: Disease prediction, patient record analysis.
- **Telecom: Network performance monitoring.
- **Social Media: Trend analysis, user recommendation engines.