Bottomup Parsers (original) (raw)
Bottom-up Parsers
Last Updated : 6 Mar, 2026
Bottom-up parsing is a syntax analysis method in which the parser starts from the input symbols (tokens) and attempts to reduce them to the start symbol (S). It builds the parse tree from the leaves (input symbols) to the root by applying production rules in reverse.
- Construct parse trees efficiently
- Detect syntax errors early
- Handle complex context-free grammars
- Suitable for programming language compilers
Steps in Bottom-Up Parsing
**Start with tokens
- The parser begins with the terminal symbols (the input tokens), which are the leaves of the parse tree.
**Shift and reduce
The parser repeatedly applies two actions:
- **Shift : The next token is pushed onto a stack.
- **Reduce : A sequence of symbols on the stack is replaced by a non-terminal according to the production rules of the grammar.
**Repeat until root
The process of shifting and reducing continues until the entire input is reduced to the start symbol, indicating the sentence has been successfully parsed.
**Example
Using following production rule construct a parse tree which takes the **input "id * id".
- E → T
- T → T * F
- T → id
- F → T
- F → id
**Solution:
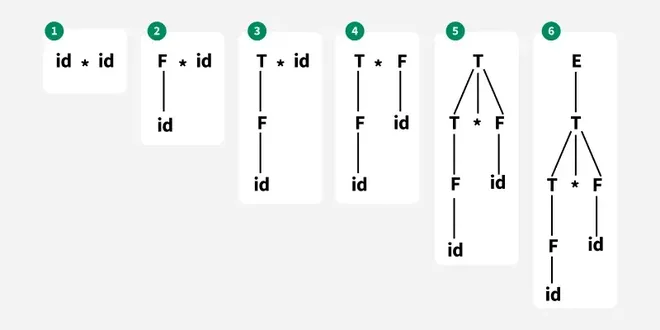
Example of Bottom Up Parsing
Shift and Reduce Operation
In bottom-up parsing, the parser reduces the input string to the start symbol using two operations.
Shift Operation
The next input symbol is pushed onto the stack. This is usually the first action taken by the parser.
How it works:
- The parser reads the input string one symbol (token) at a time.
- It maintains a stack that stores processed symbols.
- The stack is initially empty.
- The next input symbol is pushed onto the stack.
Example
**Parsing the expression "a + b"
Initial Input: a + b
Stack: empty
Step 1:
Read "a" → Shift
Stack: [a]
Remaining Input: + b
Step 2:
Read "+" → Shift
Stack: [a, +]
Remaining Input: b
Step 3:
Read "b" → Shift
Stack: [a, +, b]
Remaining Input: empty
At this stage, the entire input is on the stack, and the parser checks whether a reduction is possible.
Reduce Operation
Reduction is when a specific part of the input (called a substring or handle) is replaced by a non-terminal symbol according to the production rules of the grammar. A handle is a substring in the stack that matches a grammar rule's RHS and must be reduced next to progress toward the start symbol.
**Production Rule: How a non-terminal symbol can be replaced by other symbols (either terminals or non-terminals). For example, you might have seen a production like this:
Expression → Term + Term
This rule says that an Expression can be made by combining two Terms with a '+' in between.
**Matching the Substring: During parsing, we look at the input string and try to match parts of it to the right-hand side of a production rule. For instance, if the input is "3 + 5", we might find that this substring matches the Term + Term part of the production.
**Replacement Step (Reduction): Once a match is found, we "reduce" that matched part. This means we replace it with the non-terminal on the left side of the production rule. So, from the example above:
- We recognize the substring "3 + 5" as matching
Term + Term. - We then replace this substring with the non-terminal
Expression.
**Continue Reducing: The parser keeps reducing parts of the input string in this way, until all parts are reduced to the start symbol (like S in many grammars). This indicates that the entire input has been successfully parsed according to the grammar.
Example of Reduce Operation
Consider the following simple grammar:
- S→A+B
- A→3
- B→5
Now, let's parse the string "3 + 5":
- First, we start with the input string: "3 + 5".
- We look for parts of the string that match a production rule.
- We see that "3" matches A, so we replace it with A (so now we have A+5).
- Next, "5" matches B, so we replace it with B (now we have A+B).
- Finally, A+B matches the production S→A+B, so we replace A+B with S.
Now, we've reduced the entire input to the start symbol S, meaning the input has been successfully parsed.
**Classification of Bottom-up Parsers
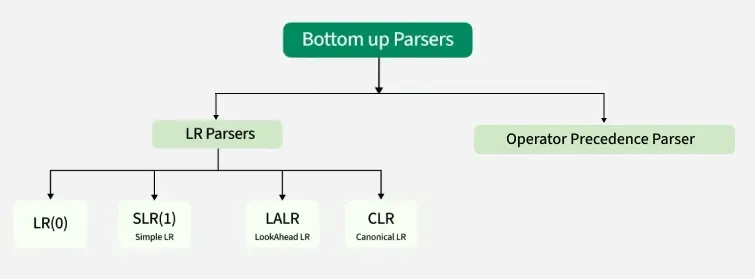
Classification of Bottom Up Parsers
A bottom-up parser is often referred to as a shift-reduce parser. A shift-reduce parser has just four canonical actions:
- **Shift: next input symbol is shifted onto the top of the stack.
- **Reduce: pop the rule's RHS from the stack, push its LHS
- **Accept: terminate parsing and signal success.
- **Error: call an error recovery routine.
LR parsers are a type of bottom-up parsers that are used to handle large and complex grammars. They are commonly used in compilers for programming languages. The name "LR" comes from two parts:
- The "L" stands for left-to-right scanning of the input. This means the parser reads the input string one symbol at a time, from left to right.
- The "R" stands for rightmost derivation in reverse. This refers to the way the parser constructs the parse tree.
Instead of building the tree from the top down (like in top-down parsers), LR parsers work from the leaves (the input symbols) and gradually reduces them back to the start symbol, following a rightmost derivation in reverse.
The "K" part, which you may see in some variants like LALR or SLR, refers to the lookahead symbols the parser uses. A "lookahead" is the number of input symbols the parser looks at in advance to decide what action to take.
For example, if the parser uses 1 lookahead, it looks at just the next symbol to decide what to do, while a parser using 2 lookahead looks ahead by two symbols.
Algorithm
push s₀ # Start with initial state
token ← next_token() # Load first tokenwhile True:
s ← stack.top() # Current statematch action[s, token]:
case "shift sᵢ":
push sᵢ # Shift to new state
token ← next_token() # Consume tokencase "reduce A → β":
pop |β| states # Remove RHS symbols
s' ← stack.top() # State after pop
push goto[s', A] # Push GOTO for LHScase "accept" if token == $:
return SUCCESS # Input fully parsedcase _:
raise ERROR # Invalid parse
The common algorithms to build tables for an “LR” parser:
LR(0) Parser
An LR(0) parser is a particular kind of bottom-up parser employed in compiler construction. The "LR" refers to Left-to-right scanning of the input and Rightmost derivation in reverse. The "(0)" means that the parser has no lookahead i.e., it makes parsing choices based solely on the current symbol on the input and the stack, without having to look ahead at subsequent symbols.
**Working of LR(0) Parser:
The LR(0) parser analyzes the input symbol by symbol from left to right. It creates the parse tree using a shift-reduce process. This continues on until the whole input string has been processed and the stack only has the start symbol of the grammar.
**SLR(1) Parser
An SLR(1) parser is an extended version of the LR(0) parser. The "SLR" refers to Simple LR, and the "(1)" indicates that it has 1 symbol of lookahead to decide what action to take. That is, the parser will have a look at the next symbol in the input to aid in deciding what action to perform, hence more powerful than an LR(0) parser.
**Working of SLR(1) Parser:
Similar to the LR(0) parser, an SLR(1) parser employs a shift-reduce strategy. The main distinction here is that the SLR(1) parser also takes into account the next input symbol (the lookahead) to determine whether to shift or reduce. This additional lookahead enables it to resolve certain kinds of conflicts not resolvable by LR(0) parsers.
**LR(1)
- full set of LR(1) grammars
- largest tables (number of states)
- slow, large construction
- intermediate sized set of grammars
- same number of states as SLR(1)
- canonical construction is slow and large
- better construction techniques exist
**Benefits of LR parsing
- Many programming languages using some variations of an LR parser. It should be noted that C++ and Perl are exceptions to it.
- LR Parser can be implemented very efficiently.
- Of all the Parsers that scan their symbols from left to right, LR Parsers detect syntactic errors, as soon as possible.
**LR(k) Items
When building parsing tables for LR parsers, we use LR(k) items to track what the parser is expecting next.
An LR(k) item is a pair [α, β], where:
- α is a grammar rule with a dot (
•) in it. The dot shows how much of the rule has been processed. - β is a string of up to k lookahead symbols (tokens) that help decide the next action.
The k in LR(k) means how many lookahead symbols the parser considers when making decisions.
**Examples of LR(k) Items
**LR(0) Items (No Lookahead) : These only track progress in a grammar rule.
Example for a rule S → A B:
[S → • A B](nothing processed yet)[S → A • B](A is processed, B is next)[S → A B •](complete rule)
**LR(1) Items (One Lookahead Symbol) : These also consider one lookahead token (β).
Example: If we have the rule S → A B, with b as lookahead:
[S → • A B, b](predicting this rule when next token isb)[S → A • B, b][S → A B •, b]
**Note: LR(0) items are used in **SLR(1) parsers (simpler) and **LR(1) items are used in **LR(1) and LALR(1) parsers (more powerful).
**CLOSURE
Function helps a parser figure out all possible rules that might be needed in a particular situation.
If we have a rule like A → α • B β, it means:
- We have processed α so far.
- B is the next thing we need to expand.
The CLOSURE function finds all rules that start with B and adds them to the set.
**Example
**Grammar Rules
S → A BA → aB → b CC → c**Closure for [S → A • B]:
- Start with the item **[S → A • B].
The dot is before **B, so we look for production rules of **B.
- We find the rule **B → b C.
- Add the item **[B → • b C] to the closure.
Since the dot is now before terminal **b, no further expansion is required.
Therefore, the closure process stops here.
**Closure Algorithm
function CLOSURE(I):repeat:for each [A → α • B β] in I:for each rule [B → γ] in grammar:add [B → • γ] to Iuntil no new items can be addedreturn I
**GOTO
The GOTO function helps a parser move from one state to another after recognizing a symbol (**X).
- Suppose we are in a state I and expecting X next.
- GOTO(I, X) finds all rules where X was the next expected symbol.
- It moves the dot (
•) past X and then applies CLOSURE to find any new possibilities.
**Example
**Grammar Rules
S → A BA → aB → b CC → c**GOTO for (I, B)
- Suppose the set III contains the item **[S → A • B].
- Since the dot is before **B, move the dot past **B to obtain **[S → A B •].
- Then apply the CLOSURE function to this item.
- If there are production rules for **B, add those rules with the dot at the beginning.
**GOTO Algorithm
function GOTO(I, X):J = set of items [A → α X • β]where [A → α • X β] is in Ireturn CLOSURE(J)
**Construction of GOTO graph
- State I0 - closure of augmented LR(0) item
- Using I0 find all collection of sets of LR(0) items with the help of DFA
- Convert DFA to LR(0) parsing table
Examples of CLOSURE and GOTO
| CLOSURE | GOTO |
|---|---|
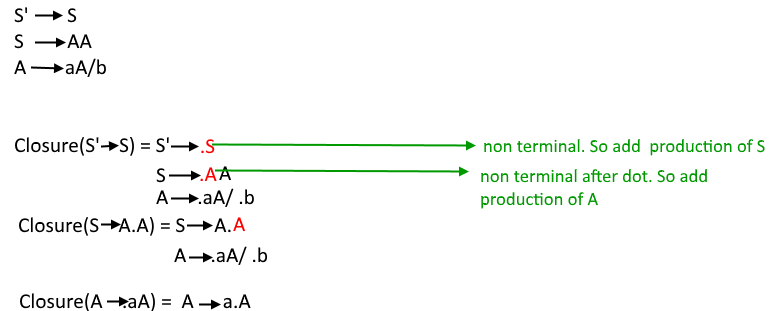 |
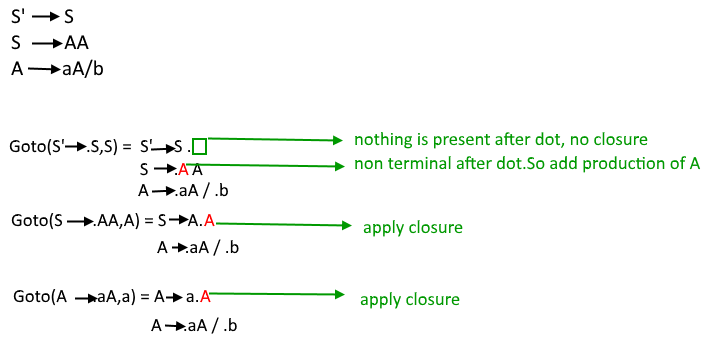 |
**Augmented Grammar
An augmented grammar is a modified version of a grammar where we add a new start symbol and rule to help with parsing.
- It ensures that the parser knows when to accept the input.
- It helps in building LR parsing tables (used in compilers).
**How Do We Create an Augmented Grammar?
- **Add a new start symbol (
S') - **Create a new rule (
S' → S), whereSis the original start symbol. - **Keep all other rules the same.
**Example
**Original Grammar:
S → A BA → aB → b**Augmented Grammar:
S' → S (New Start Rule)S → A BA → aB → bNow, S' → S helps the parser recognize when it has reached the end of the input.Operator Precedence Parsing
Operator precedence parsing is a type of bottom-up parsing used to parse expressions based on operator precedence relations. It is suitable for grammars where operators have clear precedence and associativity, such as arithmetic expressions.
**Operator Precedence Relations
Operator precedence parsers rely on three relations between terminal symbols (operators) to determine the parsing action:
- **Less than (
<·) → Operator has lower precedence than the next. - **Greater than (
·>) → Operator has higher precedence than the next. - **Equal to (
=) → Operators have the same precedence (e.g., parentheses matching).
These relations help in deciding when to shift or reduce during parsing.
**Operator Precedence Table
A table defining precedence relationships among operators is required for the parser to function. Example:
| Operator | + | * | ( | ) | $ |
|---|---|---|---|---|---|
| ****+** | ·> | <· | <· | ·> | ·> |
| *** | ·> | ·> | <· | ·> | ·> |
| ****(** | <· | <· | <· | = | error |
| ****)** | ·> | ·> | error | ·> | ·> |
| ****$** | <· | <· | <· | error | accept |
$represents the end of input.- **Shift occurs when the relation is
<·(lower precedence). - **Reduce occurs when the relation is
·>(higher precedence).
**Parsing Algorithm
**Initialize Stack: Push
$onto the stack.**Read Token: Get the next input symbol.
**Compare Precedence: Check precedence between the top of the stack and input token:
- If **stack_top
<·input_token → **Shift (push the token onto the stack).- If **stack_top
·>input_token → **Reduce (apply reduction to the handle).- If **stack_top
=input_token → **Match and proceed (for parentheses).- If no valid relation exists → **Error.
**Repeat Until Accept: Continue until the parser reaches the
$symbol andacceptcondition.
**Advantages
- Efficient for handling operator-precedence grammars.
- Simple Implementation using precedence relations.
- No Need for Left Recursion Removal in certain cases.