Working of Bottom up parser (original) (raw)
Last Updated : 15 Jul, 2025
Parsing, also known as syntactic analysis, is the process of analyzing a sequence of tokens to determine the grammatical structure of a program. It takes the stream of tokens, which are generated by a lexical analyzer or tokenizer, and organizes them into a parse tree or syntax tree.
Bottom Up Parsing
As the name suggests, bottom-up parsing works in the opposite way of top-down parsing. While a top-down parser starts from the start symbol and moves down to the input string, a bottom-up parser starts from the input string (terminals) and works its way up to the start symbol.
It does this by looking for parts of the input that match the right-hand side of grammar rules, then replaces them with the left-hand side (the non-terminal), building the parse tree from the bottom to the top.
**Note :
In bottom-up parser, no variable that's why not have any derivation from the bottom but in reverse order it is looking like top-down, when you have rightmost derivation.
**Working of Bottom-up parser
**1. Start with tokens: The parser begins with the terminal symbols (the input tokens), which are the leaves of the parse tree.
**2. Shift and reduce: The parser repeatedly applies two actions:
- **Shift: The next token is pushed onto a stack.
- **Reduce: A sequence of symbols on the stack is replaced by a non-terminal according to the production rules of the grammar. This step is called “reduction,” where the parser replaces the right-hand side of a production with the left-hand side non-terminal.
**3. Repeat until root: The process of shifting and reducing continues until the entire input is reduced to the start symbol, indicating the sentence has been successfully parsed.
Let's consider an example where grammar is given and you need to construct a parse tree by using bottom-up parser technique.
**Example 1:
- E → T
- T → T * F
- T → id
- F → T
- F → id
input string: “id * id”
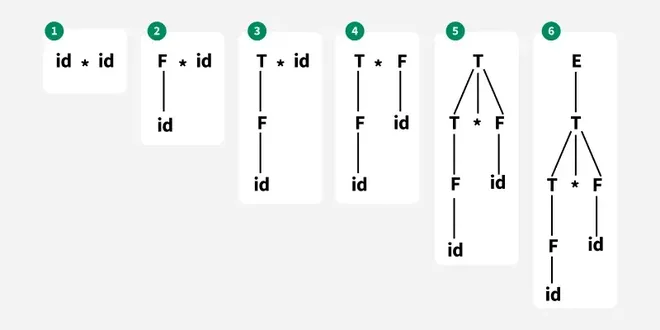
STEPS INVOLVE IN PARSING
**Example 2:
- S→A+B
- A→3
- B→5
Now, let’s parse the string “3 + 5”:
- First, we start with the input string: “3 + 5”.
- We look for parts of the string that match a production rule.
- We see that “3” matches A, so we replace it with A (so now we have A+5).
- Next, “5” matches B, so we replace it with B (now we have A+B).
- Finally, A+B matches the production S→A+B, so we replace A+B with S.
Now, we’ve reduced the entire input to the start symbol S, meaning the input has been successfully parsed.
**Classification of Bottom-up Parsers
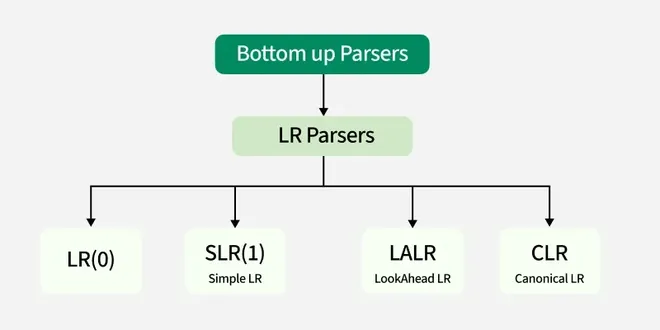
Classification Of Bottom up Parsers
**LR(0) Parser :
- Simplest form and no lookahead.
- LR(0) parser parses the input by examining the current symbol and using predefined rules based on the grammar.
- Rarely used due to limitations in grammar coverage.
**SLR(1) Parser (Simple LR)
- **SLR(1) Parser uses First and Follow sets to resolve parsing conflicts, which helps in determining whether to reduce or shift.
- Easier to implement compared to the canonical LR parsers.
- Less powerful, meaning it may fail on certain complex grammars that would be solvable by more powerful parsers.
**LALR(1) Parser (Look-Ahead LR)
- LALR(1) Parser are most commonly used in practical compilers.
- It combines similar LR(1) states to reduce the size of the parsing table, making it more efficient.
- Strikes a balance between parsing power and table size, and is used in many production compilers like Yacc and Bison.
**Canonical LR(1) Parser
- Canonical LR(1) Parser are most powerful LR parser, as it uses full lookahead (1 token) to make parsing decisions.
- Can handle the widest range of grammars, including those that would challenge other LR parsers.
- However, it results in very large parsing tables, making it less practical for real-world usage, as the table size grows exponentially.