Primary Instruction Cycles (original) (raw)
Last Updated : 29 Nov, 2025
The Instruction Cycle is the basic operational process of a computer’s CPU, referring to the sequence of steps it follows to fetch, decode, and execute each machine-level instruction. This cycle happens millions or even billions of times per second, ensuring proper execution and smooth system operation.
- Ensures instructions are processed in a clear, orderly manner.
- The CPU continuously fetches, decodes, and executes instructions to perform tasks.
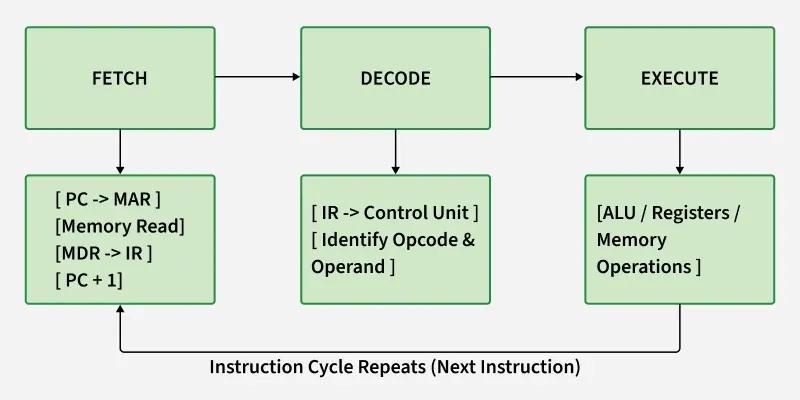
Primary Instruction Cycle
Key Registers Used in the Instruction Cycle
Several registers inside the CPU are actively involved in carrying out the instruction cycle:
- **Program Counter (PC): Holds the address of the next instruction to be executed. Automatically increments after fetching an instruction.
- **Instruction Register (IR): Holds the instruction currently being executed.
- **Memory Address Register (MAR) _(optional): Holds the address of the memory location being accessed.
- **Memory Data Register (MDR) _(optional): Holds the data read from or written to memory.
Fetch Cycle
The Fetch Cycle is the first step in the instruction cycle. Here, the CPU retrieves the instruction from memory using the Program Counter (PC).
**Steps in Fetch Cycle:
- The address in PC is transferred to MAR.
- Control Unit sends a read signal to memory.
- The instruction at that memory address is placed into MDR.
- MDR contents are transferred to IR.
- PC is incremented to point to the next instruction.
Example:
Instruction: LOAD 500
PC = 100
IR ← Memory[100]
PC ← PC + 1
After this cycle, IR contains the instruction LOAD 500. PC now points to the next instruction.
Decode Cycle
In the Decode Cycle, the Control Unit interprets the fetched instruction stored in the IR.
**Steps in Decode Cycle:
- Control Unit checks the opcode part of the instruction.
- Determines what operation to perform.
- Identifies the operand(s) or registers involved.
Example:
IR = LOAD 500
Control Unit:
Opcode = LOAD
Operand = 500
Here, LOAD indicates the operation. 500 is the address of the data to be loaded.
Execute Cycle
Finally, the Execute Cycle performs the actual operation determined during the decode stage.
**Steps in Execute Cycle:
- Depending on the opcode, the CPU perform operations.
- Perform arithmetic or logical operations via the ALU.
- Transfer data between memory and registers.
- Change the sequence of execution (e.g., jump instructions).
Example:
LOAD 500
Accumulator ← Memory[500]
After execution, the cycle can begin again with the next instruction.
**Challenges in Modern CPU Instruction Execution
While the Fetch–Decode–Execute cycle forms the foundation of CPU operation, modern processors face several challenges when executing multiple instructions efficiently. These issues can impact performance, throughput, and overall system efficiency.
1. **Pipeline Hazards
Pipelining is a technique used to improve instruction throughput by overlapping the execution of multiple instructions.
However, pipeline hazards occur when:
- One instruction depends on the result of a previous instruction.
- There are control flow changes (e.g., branches).
- Hardware resources are not available for all pipeline stages.
This leads to stalls or bubbles in the pipeline, ultimately reducing performance.
2. **Branch Prediction Errors
Branch prediction helps the CPU guess the outcome of conditional branch instructions to keep the pipeline running smoothly.
But if the prediction is incorrect, the processor must:
- Flush the incorrect instructions from the pipeline.
- Fetch the correct instruction path.
This results in wasted cycles and lower execution efficiency.
3. **Instruction Cache Misses
The instruction cache is a small, high-speed memory used to store frequently accessed instructions.
When a required instruction is not found in the cache:
- It must be fetched from main memory, which is slower.
- This leads to delays and pipeline stalls.
High cache miss rates can significantly degrade CPU performance.
4. **Instruction-Level Parallelism (ILP) Limitations
Instruction-Level Parallelism allows a CPU to execute multiple instructions simultaneously.
However:
- Not all instructions are independent or parallelizable.
- Data dependencies and control flow often limit parallel execution.
As a result, ILP has practical limits, beyond which adding more hardware doesn’t yield significant speedups.
5. **Resource Contention
When multiple instructions **compete for the same CPU resource (e.g., registers, memory ports, ALU units):
- Execution must wait until the resource is available.
- This creates bottlenecks and slows down the pipeline.
Efficient resource scheduling and hardware design help minimize this issue.