Aggregation in Data Mining (original) (raw)
Last Updated : 29 Nov, 2025
Data Aggregation is used when raw datasets are too detailed for analysis. It summarizes data into meaningful metrics like sum, count, or average to improve insights and user experience. Aggregated data aids in understanding customer behavior, creating reports, and tracing data errors (data lineage). Aggregation can be applied to both numeric and non-numeric data but is always done on groups, not individual records.
Aggregation in Data Mining
Examples of aggregate data
- **Average Customer Age: Helps identify the target age group for a product by calculating the average age instead of analyzing individuals.
- **Consumers by Country: Counts buyers per country to boost sales where demand is high and improve marketing where it's low.
- **Online Buyer Behavior: Aggregated data reveals buying patterns and product success, aiding marketing and budgeting decisions.
- **Voter Turnout: Measures total votes per region, simplifying analysis without tracking individual voter data.
Data aggregators
Data Aggregators are systems in data mining that collects data from numerous sources, then processes the data and repackages them into useful data packages. They play a major role in improving the data of customer by acting as an agent. It helps in the query and delivery process where the customer requests data instances about a certain product. The aggregators provide the customer with matched records of the product. Thereby the customer can buy any instances of matched records.
Working of Data aggregators
The working of data aggregators takes place in three steps:

Working Of Data Aggregators
1. Data Collection
Data is gathered from various sources, including:
- **IoT Devices: Sensors and smart devices collect real-time information.
- **Social Media: Platforms provide insights into user interactions and trends.
- **Speech Recognition: Transcriptions from call centers and voice assistants.
- **News Headlines: Aggregated from multiple news outlets.
- **Browsing History: Tracks user behavior online.
- **Personal Device Data: Information from smartphones, wearables, etc.
2. Data Processing
Once collected, data undergoes processing to extract meaningful insights:
- **Aggregation: Combining data from different sources.
- **Artificial Intelligence & Machine Learning: Algorithms identify patterns and make predictions.
- **Statistical Methods: Techniques like predictive analysis forecast future trends.
3. Data Presentation
Processed data is then presented in an understandable format:
- **Summarization: Condensing data into key points.
- **Visualization: Charts, graphs, and dashboards for easy interpretation.
- **Reporting: Detailed reports highlighting significant findings.
Working Of Data Aggregators
Choice of manual or automated data aggregators
- Data aggregation can also be done by manual method. When one starts a new company, one can opt manual aggregator by using excel sheets and by creating charts to manage performance, budget, marketing etc.
- Data aggregation in a well-established company calls the need for middleware, a third party software to implement the data automatically using tools of marketing.
- But when large datasets are encountered, a Data Aggregator system is a need to provide accurate results.
Types of Data Aggregation
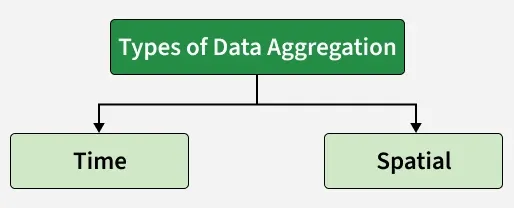
- **Time aggregation: It provides the data point for single resources for a defined time period.
- **Spatial aggregation: It provided the data point for a group of resources for a defined time period.
Time intervals for data aggregation process
- **Reporting Period: The time span over which data is collected and presented (e.g., daily reports from a network device).
- **Granularity: The interval used to aggregate data (e.g., data summed every 10 minutes). It can range from minutes to months.
- **Polling Period: How often data is sampled from a resource (e.g., every 7 minutes). Both polling and granularity relate to spatial aggregation.
Applications of Data Aggregation
- **Business Intelligence: Combines data from multiple sources for better reporting and decision-making.
- **Customer 360 View: Merges customer data from different systems to provide a complete profile.
- **Healthcare: Integrates patient records from various departments for accurate diagnosis and treatment.
- **E-commerce: Syncs inventory, sales, and customer data across platforms for smoother operations.
- **Financial Services: Consolidates transaction data to detect fraud and ensure compliance.