Iterating over rows and columns in Pandas DataFrame (original) (raw)
Last Updated : 13 Sep, 2025
Iteration simply means going through elements one by one. In a Pandas DataFrame you commonly need to inspect rows (records) or columns (fields) to analyze, clean or transform data. This article shows practical ways to iterate with real dataset to understand how each method behaves on real data.
Iterate Over Rows
Iterating over rows is useful when you want to process each record individually. Pandas provides multiple methods for row iteration, each with its own benefits.
1. Using iterrows()
**iterrows() returns each row as a (index, Series) pair. This means you get the row’s index and a Pandas Series object containing column names and their values. It is easy to use since you can access fields by column name, but it can be slower on very large DataFrames.
We are working with nba.csv dataset in these examples. Download CSV file here.
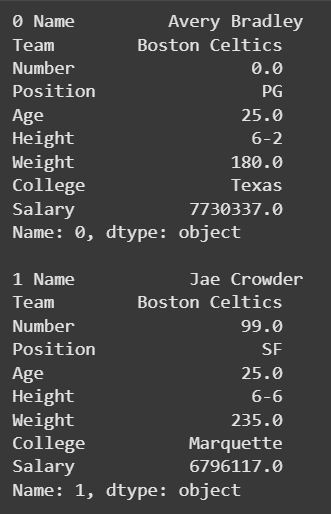
**Example 1: This code demonstrates how to loop through a small subset of rows and view all column values in each row.
- data.head(2)selects first 2 rows of the DataFrame.
- for i, row in .. iterrows() gives i as the row index and row as a Series with column-value pairs. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
iterate over rows
for i, row in data.head(2).iterrows(): print(i, row) print()
`
**Output
Output
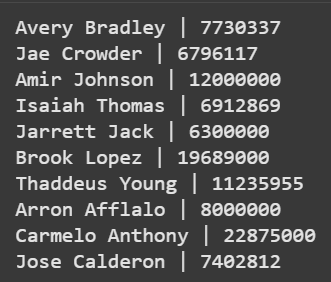
**Example 2: This code applies a row-wise condition to filter high-salary players.
- loop iterates over every row using iterrows().
- pd.notnull(s) ensures missing values (NaN) are skipped.
- list of (Name, Salary) is created for players earning above 5M. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
high_salary = [] for i, row in data.iterrows(): s = row['Salary'] if pd.notnull(s) and s > 5_000_000: high_salary.append((row['Name'], int(s)))
for name, sal in high_salary[:10]: print(f"{name} | {sal}")
`
**Output
Output
2. Using itertuples()
itertuples() returns each row as a named tuple. It is faster than iterrows() because it avoids creating Series objects and you can access row values as attributes (e.g., row.Name, row.Salary). This makes it ideal for performance-heavy tasks.
**Example 1: This code shows how each row is returned in tuple format.
- Each row is returned as a Pandas namedtuple.
- You can access fields directly using attribute syntax (e.g., row.Name).
- Much faster than iterrows() for larger datasets. Python `
import pandas as pd data = pd.read_csv("nba.csv")
for row in data.head(3).itertuples(): print(row)
`
**Output

Output
**Example 2: This code demonstrates how to extract values from a specific column using list comprehension.
- List comprehension iterates through itertuples().
- row.Name extracts the Name field directly.
- [:6] limits the result to the first 6 names. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
names = [row.Name for row in data.itertuples()][:6] print("First 6 names:", names)
`
**Output

Output
Iterate Over Columns
Iterating columns is useful for column-wise checks or operations (e.g., computing stats, converting dtypes or applying functions). You can iterate columns by using items() or by creating a column-name list.
1. Using items()
items() iterates over DataFrame columns, returning each as a (label, Series) pair. The label is column name and Series contains values for that column. This is helpful when you want to check column-level details such as data distribution, types or missing values.
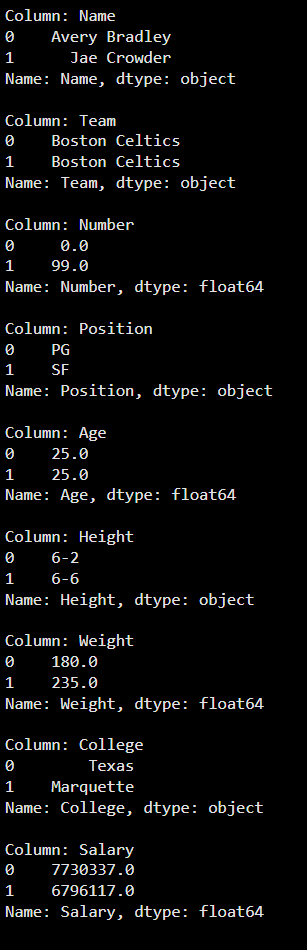
**Example 1: This code prints a few values from every column for a quick inspection.
- data.head(2).items() loops through each column of the first 2 rows.
- label gives the column name, while values is a Series of that column’s data. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
for label, values in data.head(2).items(): print(f"Column: {label}") print(values) print()
`
**Output
Output
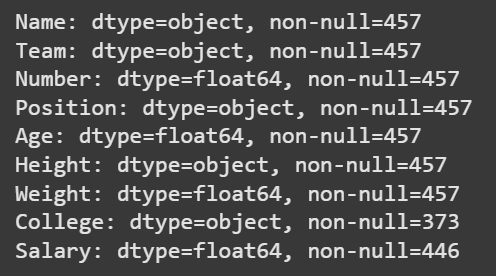
**Example 2: This example helps detect data quality issues across columns.
- values.dtype shows the data type of each column.
- values.notnull().sum() counts how many values are non-missing. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
for label, values in data.items(): print(f"{label}: dtype={values.dtype}, non-null={values.notnull().sum()}")
`
**Output
Output
2. Using direct column iteration
In Pandas, one can also iterate through columns directly without using methods. This is done by looping over list of column names and then accessing their values from DataFrame.
**Example 1: This example prints 3rd row’s value for each column, one column at a time.
- list(data.columns) gives all column names.
- data[col][2] accesses the 3rd row (index 2) value for that column. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
cols = list(data.columns)
for col in cols: print(f"{col}: {data[col][2]}")
`
**Output

Output
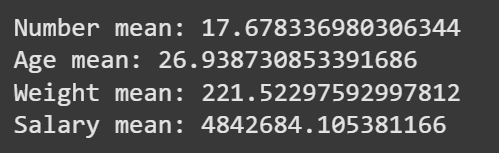
**Example 2: This code summarizes numeric columns by calculating their mean values.
- select_dtypes(include='number') selects numeric columns.
- The loop calculates and prints the mean of each numeric column. Python `
import pandas as pd
data = pd.read_csv("nba.csv")
num = data.select_dtypes(include='number') for col in num.columns: print(f"{col} mean: {num[col].mean()}")
`
**Output
Output