Hadoop Different Modes of Operation (original) (raw)
Last Updated : 12 Aug, 2025
Hadoop is an open-source framework widely used for storing, processing, and analyzing large-scale datasets on clusters of commodity hardware. It provides a scale-out storage and processing architecture, meaning we can easily add or remove nodes as per requirements. This makes Hadoop highly suitable for Big Data applications across industries. Hadoop operates in three different modes, each designed for a specific use case:
- Standalone Mode
- Pseudo-Distributed Mode (Single Node Cluster)
- Fully Distributed Mode (Multi-Node Cluster / Production Mode)
**1. Standalone Mode (Local Mode)
Hadoop Standalone Mode is the simplest mode in which Hadoop runs on a single JVM (Java Virtual Machine). In this mode, no Hadoop daemons (like NameNode, DataNode, ResourceManager, or NodeManager) are started. By default, Hadoop works in this mode after installation.
Instead of using HDFS, it relies on the local file system (e.g., NTFS/FAT32 in Windows or EXT4 in Linux). No extra configuration is required in core-site.xml, hdfs-site.xml, or mapred-site.xml. Because there is no cluster setup or communication overhead, this mode is also the fastest among all.
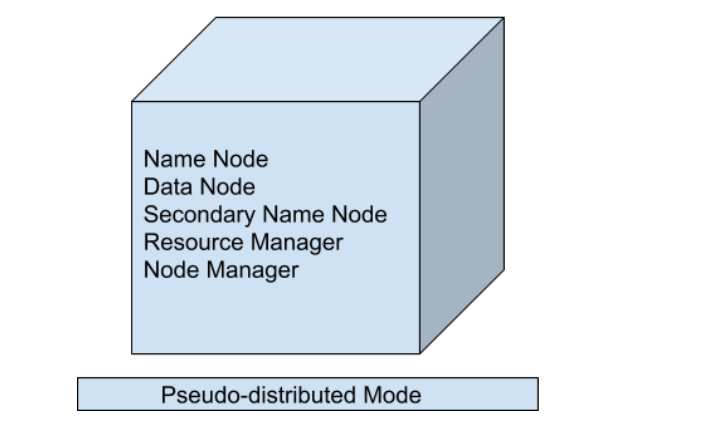
2. Pseudo-Distributed Mode (Single Node Cluster)
In Pseudo-Distributed Mode, Hadoop still runs on a single physical machine, but all Hadoop daemons run as separate processes on independent JVMs. This setup simulates a real cluster environment.
Here, master daemons (NameNode, ResourceManager, SecondaryNameNode) and slave daemons (DataNode, NodeManager) all run on the same system. Unlike Standalone Mode, HDFS is fully functional and data is stored in blocks like in a real cluster.
This mode requires configuration changes in core-site.xml, hdfs-site.xml, mapred-site.xml.
3. Fully Distributed Mode (Multi-Node Cluster)
The Fully Distributed Mode is Hadoop’s production-grade mode, where Hadoop runs on a cluster of multiple machines (nodes).
- Master Nodes run the NameNode (manages metadata) and ResourceManager (manages cluster resources).
- Slave Nodes run the DataNode (stores actual data blocks) and NodeManager (executes tasks).
Data is stored in HDFS and replicated across nodes, ensuring fault tolerance and high availability. This setup is highly scalable, ranging from a few nodes to thousands of nodes.
Comparison of Hadoop Modes
| Feature | Standalone Mode | Pseudo-Distributed Mode | Fully Distributed Mode |
|---|---|---|---|
| Nodes | Single JVM | Single machine (all daemons as separate processes) | Multiple machines (cluster) |
| HDFS | Not used (local FS) | Fully functional | Fully functional |
| Daemons | None | All run on one system | Distributed across nodes |
| Configuration | Not required | Required | Required |
| Performance | Fastest | Moderate | Depends on cluster size |
| Use Case | Learning, debugging small jobs | Development & testing | Production & real-world |