Apache HBase (original) (raw)
Last Updated : 24 Apr, 2026
Apache HBase is a distributed, scalable, NoSQL database built on top of the Hadoop Distributed File System (HDFS). It is modeled after Google's Bigtable and is designed for storing large volumes of sparse, unstructured, or semi-structured data across clusters. HBase is column-oriented, supports horizontal scaling, and allows for real-time read/write access, making it an essential component of the Hadoop ecosystem.
**Example: Facebook migrated from Cassandra to HBase in 2010 to power its messaging infrastructure, needing a scalable, real-time system to unify chat, email, and SMS conversations.
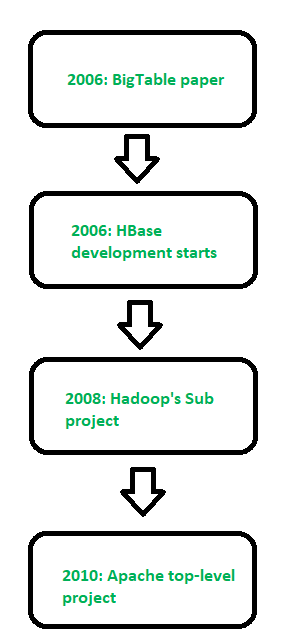
**HBase evolution flowchart:
Key Features of Apache HBase
- **Column-Oriented Storage: Efficient for queries on large datasets with flexible schemas.
- **Horizontal Scalability: Easily scales across multiple nodes by adding more servers.
- **Strong Consistency: Provides consistent reads and writes (no eventual consistency).
- **Atomic Operations: Ensures atomicity at the row level.
- **Rich APIs: Offers Java APIs and supports Thrift & REST APIs for integration with non-Java platforms.
- **Built-in Fault Tolerance: System automatically recovers from node failures using HDFS data replication and dynamic reassignment of regions.
- **Caching Support: Includes Block Cache and Bloom Filters for faster data retrieval.
- **Metric Export: Supports exporting performance metrics through Hadoop's metrics subsystem.
Architecture of Apache HBase
Apache HBase follows a master-slave architecture and is built on top of Hadoop HDFS. Here's how its major components work together:
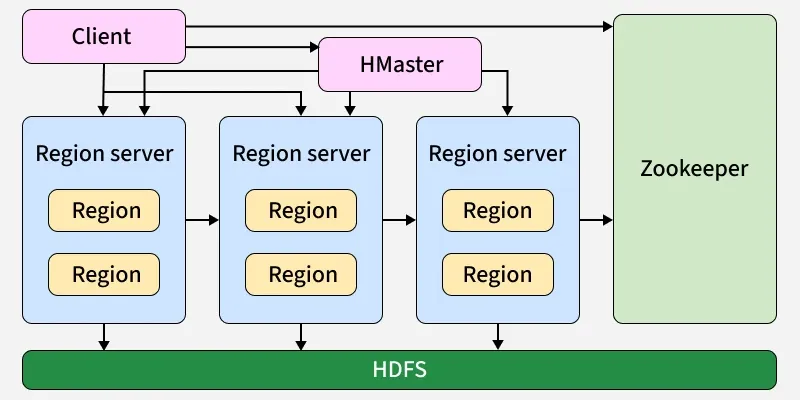
Apache HBase architecture
**Here’s how each part of the Apache HBase architecture works in detail:
1. HMaster
Acts as the master node of the HBase cluster. Its main responsibilities include:
- Coordinating RegionServers
- Assigning regions to RegionServers
- Monitoring RegionServer health
- Handling schema changes, like creating or deleting tables
- Performing load balancing so no RegionServer is overloaded
If the HMaster fails, a backup HMaster can take over to ensure high availability.
2. RegionServer
A worker node in HBase, serving client requests. Each RegionServer manages multiple regions, meaning chunks of tables. Internally, RegionServers have:
- **MemStore: stores data in memory for fast writes before persisting to disk
- **HFile: permanent storage format in HDFS
- **BlockCache: caches frequently read data to improve read performance
RegionServers also manage WAL (Write Ahead Log) for crash recovery. If a RegionServer fails, the HMaster reassigns its regions to other RegionServers.
3. Region
- A region is a horizontal partition of an HBase table (like a subset of rows).
- Each region contains data for a continuous range of row keys.
- When a region grows too large (default around 10GB), it automatically splits into smaller regions.
- Only one RegionServer handles a given region at a time to avoid conflicts.
4. ZooKeeper
It's an external, reliable coordination service. HBase uses ZooKeeper to:
- Track available RegionServers
- Help clients locate regions quickly
- Manage master election in case of failure
- Provide distributed configuration and synchronization
Without ZooKeeper, the cluster cannot coordinate properly.
5. HDFS (Hadoop Distributed File System)
HBase uses HDFS to store actual data on disk. It stores HFiles which are compressed files with the actual data and also WAL (Write Ahead Logs) files for durability. It Provides fault-tolerant, distributed storage so data is protected even if hardware fails.
- **Massive Scalability – It Can handle extremely large datasets and seamlessly expand by adding more nodes without affecting performance.
- **High Throughput – Supports fast read/write operations, making it suitable for applications requiring quick processing of huge volumes of data.
- **Schema Flexibility – Allows storing data without a fixed schema, enabling easy handling of unstructured and semi-structured data.
- **Fault Tolerant – Ensures data reliability and system availability by automatically replicating data across multiple nodes.
- **Flexible Distributed Setup – Designed for large scale systems, offering high control for experts in Hadoop and distributed architectures.
- **Efficient Query Processing for Big Data – Optimized for large datasets using non-SQL approaches suited for scalable applications.
- **High Performance Without Heavy Transaction Overhead – Ideal for scenarios where speed is prioritized over strict transactional consistency.
- **Optimized for Simple, High-Speed Operations – Best suited for workloads that do not require complex joins or real-time streaming.
Read related article Difference Between Hive and HBase