Clustering Indexing in Databases (original) (raw)
Last Updated : 7 Jan, 2026
Databases are a crucial component of modern computing, providing a structured way to store, manage, and retrieve vast amounts of data. As the size of databases increases, it becomes increasingly important to have an efficient indexing mechanism that can quickly search and retrieve data. Clustering indexing is one such mechanism that has been designed to meet this need.
Clustering Indexing
Clustering indexing is a database indexing technique that is used to physically arrange the data in a table based on the values of the clustered index key. This means that the rows in the table are stored on disk in the same order as the clustered index key. With a clustered index, the database can more efficiently retrieve data because it doesn't have to scan the entire table to find the data it needs. Instead, it can use the clustered index to quickly locate the data, resulting in faster query execution times and improved overall performance.
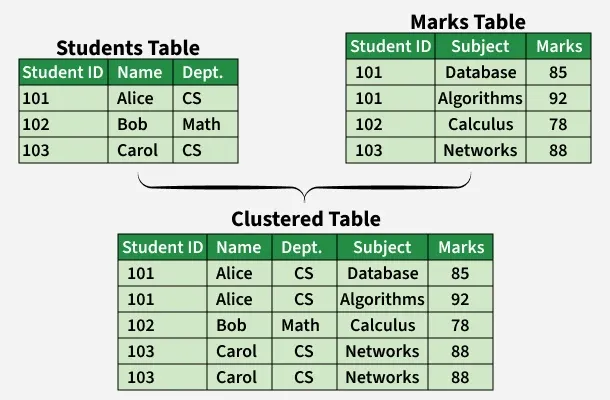
Example of Clustering
Advantages
- **Improved Query Performance: Clustering indexing results in faster query performance, as the data is stored in a way that makes it easier to retrieve the desired information. This is because the index is built based on the clustered data, reducing the number of disk I/Os required to retrieve the data.
- **Reduced Disk Space Usage: Clustering indexing reduces the amount of disk space required to store the index. This is because the index contains only the information necessary to retrieve the data, rather than storing a copy of the data itself.
- **Better Handling of Complex Queries: Clustering indexing provides better performance for complex queries that involve multiple columns. This is because the data is stored in a way that makes it easier to retrieve the relevant information.
- **Improved Insert Performance: Clustering indexing can result in improved insert performance, as the database does not have to update the index every time a new record is inserted.
- **Improved Data Retrieval: Clustering indexing can also improve the efficiency of data retrieval operations. In a clustered index, the data is stored in a logical order, which makes it easier to locate and retrieve the data. This can result in faster data retrieval times, particularly for large databases.
Disadvantages
- **Increased Complexity: Clustering indexing is a more complex technology compared to other indexing mechanisms, such as B-Tree indexing.
- **Reduced Update Performance: Clustering indexing can result in reduced update performance, as the database must reorganize the data to reflect the changes.
- **Limited to One Clustered Index: A table can have only one clustered index, as having multiple clustered indexes would result in conflicting physical orderings of the data.
Pre-requisites: Primary Indexing in Databases, indexing
When to Use Clustering Indexing
Clustering indexing is a useful technique for improving the performance of database queries and data storage.
- **When Data is Often Retrieved in a Specific Order: If your queries often retrieve data in a specific order, clustering indexing can be a great choice. By physically arranging the data in the table according to the clustered index key, the database can quickly locate and retrieve the data it needs.
- **When Query Performance is a Concern: If query performance is a concern, clustering indexing can be a great option. By using the clustered index to quickly locate the data, the database can execute queries faster, particularly for queries that return large amounts of data.
- **When Disk Space Utilization is a Concern: Clustering indexing can also help to improve disk space utilization. By storing the data in a compact form, the database can reduce the amount of disk space required to store the data. This can result in significant savings in terms of disk space, particularly for large databases.
**Note: Clustering indexing may not always be the best choice for every situation. For **example, if your data is constantly changing and new data is frequently added to the table, clustering indexing may not be the best choice. This is because the database has to physically rearrange the data every time new data is added to the table, which can be time-consuming and negatively impacts performance.
Aplications of Clustering Indexing
- **Faster retrieval of related records: Records with similar clustering key values are stored adjacently on disk, enabling fast sequential access .
- **Efficient range queries: Ideal for BETWEEN, <, > queries since ordered records lie in contiguous disk blocks, reducing page accesses.
- **Improved performance for grouped data: Tuples sharing the same clustering key (e.g., department or category) are stored together, speeding up group and equality scans.
- **Optimized sequential access: Supports efficient bulk reading of large related record sets with minimal disk head movement.
- **Better performance in data warehousing: Accelerates OLAP queries by clustering frequently queried dimensions like date, region, or product.
- **Used in file organization: Determines the physical order of records in clustered files, unlike secondary indexes which only store pointers.
- **Reduces disk seeks: Spatial locality places related rows in fewer disk pages, significantly reducing random disk seeks.