Data Preprocessing in Data Mining (original) (raw)
Last Updated : 7 Feb, 2026
Real-world data is often incomplete, noisy, and inconsistent, which can lead to incorrect results if used directly. Data preprocessing in data mining is the process of cleaning and preparing raw data so it can be used effectively for analysis and model building.
- Real data contains missing and incorrect values
- Data may come from multiple sources
- Large datasets often have irrelevant information
- Clean data gives better mining results
Steps in Data Preprocessing
Some key steps in data preprocessing are:
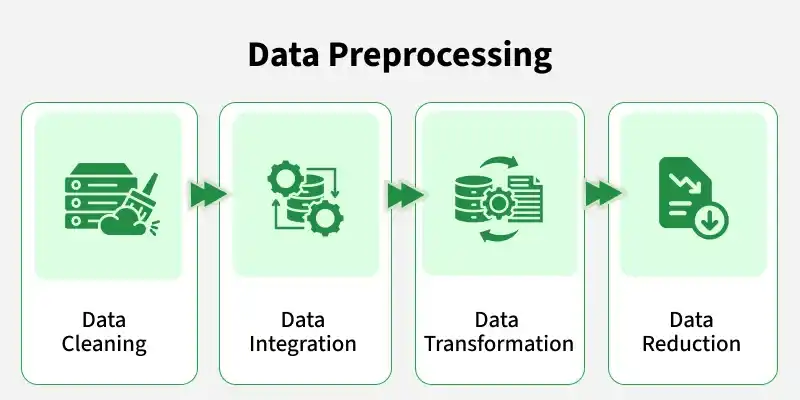
Steps in Data Preprocessing
**1. Data Cleaning
It is the process of identifying and correcting errors or inconsistencies in the dataset. Its common tasks include:
- Handling missing values
- Removing duplicate records
- Correcting wrong or inconsistent data
- Handling Outliers
**Techniques used:
- **Mean Imputation: Replaces missing values with the average of the attribute.
- **Median Imputation: Replaces missing values with the middle value, useful when outliers exist.
- **Mode Imputation: Replaces missing values with the most frequent value.
- **Deletion Method: Removes records that contain missing values.
- **Interquartile Range (IQR): Detects outliers using the range between Q1 and Q3.
- **Z-Score Method: Identifies outliers based on standard deviation from the mean.
- **Binning: Smooths noisy data by grouping values into bins.
- **Regression Smoothing: Uses regression to predict and smooth noisy values.
- **Duplicate Detection: Identifies and removes repeated records.
**Example:
- Replacing missing age values with the average age
- Removing repeated rows in a dataset
**2. Data Integration
It involves merging data from various sources into a single, unified dataset. It can be challenging due to differences in data formats, structures, and meanings.
- Used when data comes from databases, files, or APIs
- Removes redundancy between datasets
- Resolves conflicts in data values
**Techniques used:
- **Schema Matching: Aligns attributes from different data sources.
- **Entity Resolution: Identifies records that refer to the same real-world entity.
- **Correlation Analysis: Finds and removes redundant attributes.
- **Data Conflict Resolution: Resolves inconsistencies in units or data values.
- **Duplicate Elimination: Removes overlapping records after integration.
**Example: Merging customer data from sales and marketing databases
**3. Data Transformation
Data transformation converts data into a suitable form so that data mining algorithms can work effectively.
- Bring data into a common format
- Improve mining efficiency
- Make data suitable for modeling
**Techniques used:
- **Min-Max Normalization: Scales data into a fixed range, usually 0 to 1.
- **Z-Score Normalization: Transforms data using mean and standard deviation.
- **Decimal Scaling: Normalizes data by moving the decimal point.
- **Log Transformation: Reduces data skewness using logarithmic scaling.
- **One-Hot Encoding: Converts categories into binary columns.
- **Label Encoding: Assigns numeric labels to categorical values.
- **Aggregation: Combines detailed data into summarized form.
**Example:
- Converting salary values into a fixed range (0–1)
- Changing text labels like _Male/Female into numeric values
**4. Data Reduction
It reduces the dataset's size while maintaining key information. This can be done through feature selection which chooses the most relevant features and feature extraction which transforms the data into a lower-dimensional space while preserving important details.
- Improves processing speed
- Saves storage space
- Makes analysis easier
**Techniques used:
- **Principal Component Analysis (PCA): Reduces dimensions by projecting data onto principal components.
- **Linear Discriminant Analysis (LDA): Reduces dimensions while maximizing class separation.
- **Filter Methods: Select features based on statistical measures.
- **Wrapper Methods: Select features using model performance.
- **Embedded Methods: Perform feature selection during model training.
- **Simple Random Sampling: Selects data points randomly from the dataset.
- **Stratified Sampling: Samples data proportionally from each class.
**Benefits of Data Preprocessing
- Improves data quality
- Increases accuracy of mining results
- Reduces errors in models
- Makes data easier to understand
Advantages
- **Improved Data Quality: Ensures data is clean, consistent, and reliable for analysis.
- **Better Model Performance: Reduces noise and irrelevant data, leading to more accurate predictions and insights.
- **Efficient Data Analysis: Streamlines data for faster and easier processing.
- **Enhanced Decision-Making: Provides clear and well-organized data for better business decisions.