The CAP Theorem in DBMS (original) (raw)
Last Updated : 6 Dec, 2025
The CAP Theorem is a key idea in distributed systems that explains why building a perfectly reliable, networked data system is impossible. Proposed by Eric Brewer and proven later by Seth Gilbert and Nancy Lynch, it states that a distributed system cannot guarantee Consistency, Availability, and Partition Tolerance all at the same time—at most, it can fully achieve any two. This means designers must make conscious trade-offs based on what their application needs most: strict accuracy of data, continuous system responsiveness, or the ability to function even when parts of the network fail. Understanding this balance helps developers choose the right priorities to create systems that perform reliably in real-world distributed environments.
CAP Theorem Properties
**1. Consistency
Consistency means that all the nodes (databases) inside a network will have the same copies of a replicated data item visible for various transactions. It guarantees that every node in a distributed cluster returns the same, most recent, and successful write. It refers to every client having the same view of the data. There are various types of consistency models. Consistency in CAP refers to sequential consistency, a very strong form of consistency.
Note that the concept of Consistency in ACID and CAP are slightly different since in CAP, it refers to the consistency of the values in different copies of the same data item in a replicated distributed system. In ACID, it refers to the fact that a transaction will not violate the integrity constraints specified on the database schema.
For example, a user checks his account balance and knows that he has 500 rupees. He spends 200 rupees on some products. Hence the amount of 200 must be deducted changing his account balance to 300 rupees. This change must be committed and communicated with all other databases that hold this user's details. Otherwise, there will be inconsistency, and the other database might show his account balance as 500 rupees which is not true.
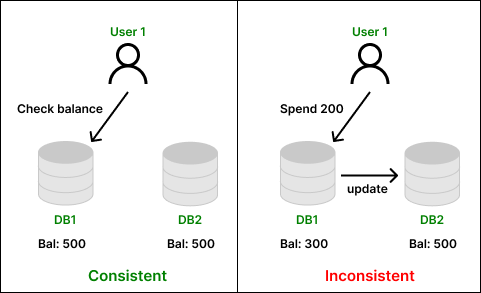
Consistency problem
2. Availability
Availability means that each read or write request for a data item will either be processed successfully or will receive a message that the operation cannot be completed. Every non-failing node returns a response for all the read and write requests in a reasonable amount of time. The key word here is "every". In simple terms, every node (on either side of a network partition) must be able to respond in a reasonable amount of time.
For example, user A is a content creator having 1000 other users subscribed to his channel. Another user B who is far away from user A tries to subscribe to user A's channel. Since the distance between both users are huge, they are connected to different database node of the social media network. If the distributed system follows the principle of availability, user B must be able to subscribe to user A's channel.

Availability problem
**3. Partition Tolerance
Partition tolerance means that the system can continue operating even if the network connecting the nodes has a fault that results in two or more partitions, where the nodes in each partition can only communicate among each other. That means, the system continues to function and upholds its consistency guarantees in spite of network partitions. Network partitions are a fact of life. Distributed systems guaranteeing partition tolerance can gracefully recover from partitions once the partition heals.
For example, take the example of the same social media network where two users are trying to find the subscriber count of a particular channel. Due to some technical fault, there occurs a network outage, the second database connected by user B losses its connection with first database. Hence the subscriber count is shown to the user B with the help of replica of data which was previously stored in database 1 backed up prior to network outage. Hence the distributed system is partition tolerant.

Partition Tolerance
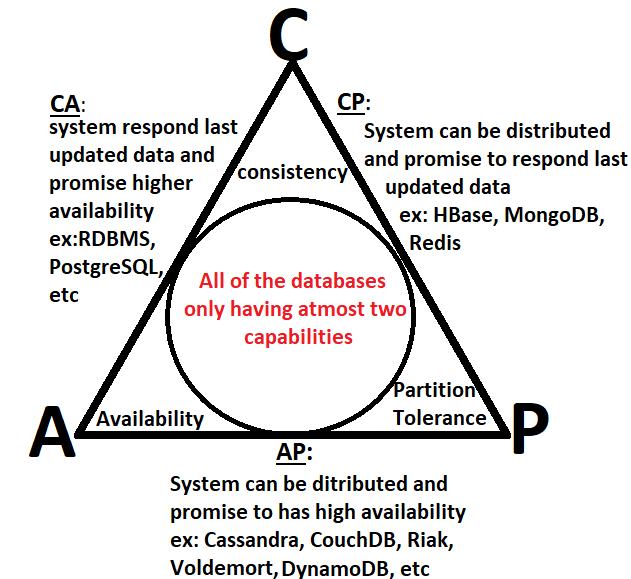
**The CAP theorem states that distributed databases can have at most two of the three properties: consistency, availability, and partition tolerance. As a result, database systems prioritize only two properties at a time.

Venn diagram of CAP theorem
The Trade-Offs in the CAP Theorem
The CAP theorem implies that a distributed system can only provide two out of three properties:
1. CA (Consistency and Availability)
**These types of system always accept the request to view or modify the data sent by the user and they are always responded with data which is consistent among all the database nodes of a big, distributed network.
However, such type of distributed systems is not realizable in real world because when network failure occurs, there are two options: Either send old data which was replicated moments ago before network failure or do not allow user to access the already moments old data. If we choose first option, our system will become Available and if we choose second option our system will become Consistent.
The combination of consistency and availability is not possible in distributed systems and for achieving CA, the system has to be monolithic such that when a user updates the state of the system, all other users accessing it are also notified about the new changes which means that the consistency is maintained. And since it follows monolithic architecture, all users are connected to single system which means it is also available. These types of systems are generally not preferred due to a requirement of distributed computing which can be only done when consistency or availability is sacrificed for partition tolerance.
Example databases: MySQL, PostgreSQL
CAP diagram
**2. AP (Availability and Partition Tolerance)
**These types of system are distributed in nature, ensuring that the request sent by the user to view or modify the data present in the database nodes are not dropped and are processed in presence of a network partition.
The system prioritizes availability over consistency and can respond with possibly stale data which was replicated from other nodes before the partition was created due to some technical failure. Such design choices are generally used while building social media websites such as Facebook, Instagram, Reddit, etc. and online content websites like YouTube, blog, news, etc. where consistency is usually not required, and a bigger problem arises if the service is unavailable causing corporations to lose money since the users may shift to new platform. The system can be distributed across multiple nodes and is designed to operate reliably even in the face of network partitions.
Example databases: Amazon DynamoDB, Google Cloud Spanner.
**3. CP (Consistency and Partition Tolerance)
**These types of system are distributed in nature, ensuring that the request sent by the user to view or modify the data present in the **database nodes are dropped instead of responding with inconsistent data in presence of a network partition.
The system prioritizes consistency over availability and does not allow users to read crucial data from the stored replica which was backed up prior to the occurrence of network partition. Consistency is chosen over availability for critical applications where latest data plays an important role such as stock market application, ticket booking application, banking, etc. where problem will arise due to old data present to users of application.
For example, in a train ticket booking application, there is one seat which can be booked. A replica of the database is created, and it is sent to other nodes of the distributed system. A network outage occurs which causes the user connected to the partitioned node to fetch details from this replica. Some user connected to the unpartitioned part of distributed network and already booked the last remaining seat. However, the user connected to partitioned node will still one seat which makes the available data inconsistent. It would have been better if the user was shown error and make the system unavailable for the user and maintain consistency. Hence consistency is chosen in such scenarios.
Example databases: Apache HBase, MongoDB, Redis.