Deep Learning Interview Questions (original) (raw)
Last Updated : 4 Oct, 2025
Deep Learning is a field of AI that trains multi-layered neural networks to learn from data. It is widely used in applications like vision, speech and NLP. This article shows all key Deep Learning interview questions to help you revise core concepts and advanced topics.
1. What is the difference between Deep Learning and Machine Learning?
| Aspect | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Definition | Algorithms that learn from data and make predictions | Subset of ML using multi-layered neural networks |
| Feature Engineering | Requires manual feature extraction | Learns features automatically from raw data |
| Data Requirement | Works well with smaller datasets | Needs large amounts of data for training |
| Training Time | Relatively faster | Computationally expensive and slower |
| Interpretability | Easier to interpret and explain | Harder to interpret (acts like a “black box”) |
| Applications | Fraud detection, recommendations | Image recognition, NLP, self-driving cars |
2. What are the different types of Neural Networks?
There are different types of neural networks used in deep learning. Some of the most important neural network architectures are as follows:
- Feedforward Neural Networks (FFNNs)
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory Networks (LSTMs)
- Gated Recurrent Units (GRU)
- Autoencoder Neural Networks
- Generative Adversarial Networks (GANs)
- Transformers
- Deep Belief Networks (DBNs)
3. **What is a Neural Network and Artificial Neural Network (ANN)?
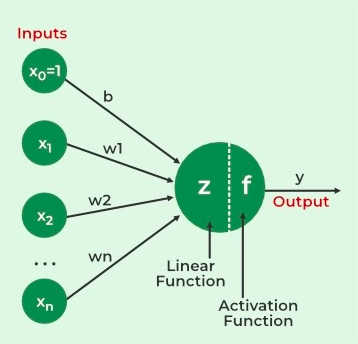
A Neural Network is a computational model inspired by the human brain where nodes (neurons) are connected to process and transfer information. An Artificial Neural Network (ANN) is the basic implementation of this concept in machines. It consists of:
- **Input Layer: takes raw data.
- **Hidden Layers: process data using weights, biases and activation functions.
- **Output Layer: gives the final prediction or classification.
ANNs are widely used in deep learning for applications like image recognition, speech analysis and natural language processing.
artificial neural network
4. How Biological neurons are similar to the Artificial neural network.
Artificial Neural Networks (ANNs) are inspired by how biological neurons work in the human brain.
- In the human brain, a neuron receives signals through dendrites, processes them in the cell body and passes the signal through the axon to other neurons.
- In an ANN, an artificial neuron receives inputs, multiplies them by weights, adds a bias, applies an activation function and passes the output to the next layer.
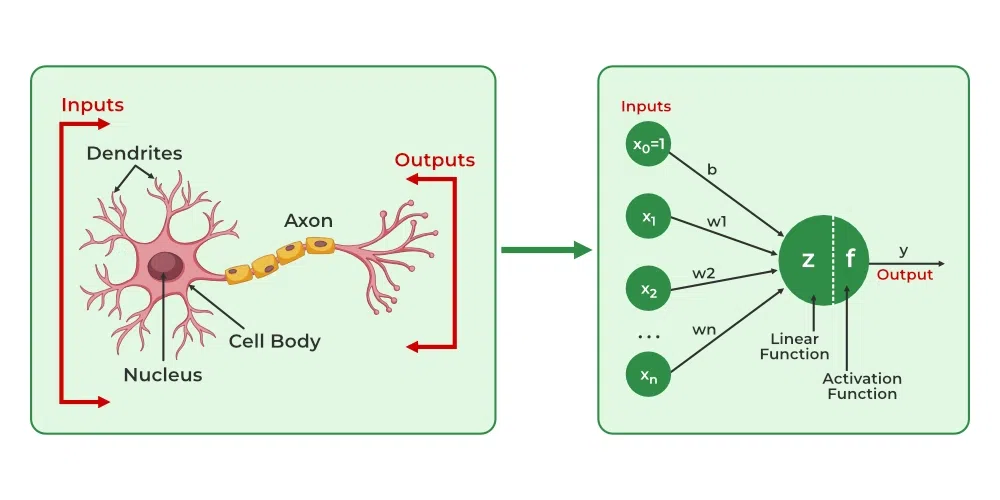
Biological neurons to Artificial neurons
**5. What are Weights and Biases in Neural Networks?
- **Weights: These are numerical values assigned to the connections between neurons. They determine the importance of each input. If an input has a higher weight, it influences the output more strongly.
- **Bias: This is an extra parameter added to the weighted sum of inputs before applying the activation function. It helps the model shift the activation curve so that the network can learn patterns more flexibly.
**Example: For a neuron with inputs x_1, x_2 weights w_1, w_2 and bias b, the output before activation is:
z = (w_1 \cdot x_1) + (w_2 \cdot x_2) + b
Then an activation function like sigmoid or ReLU is applied on z to get the final output.
6. How weights are initialized in Neural Networks?
Weight initialization is a crucial step in training neural networks. The goal is to set the initial weights in a way that allows the network to learn efficiently and converge to a good solution. Several methods are commonly used:
- **Zero Initialization: All weights are set to zero. This causes every neuron to learn the same features (symmetry problem) making training ineffective or extremely slow.
- **Random Initialization: Weights are assigned small random values from a uniform or normal distribution. This breaks symmetry, but poorly chosen ranges can lead to issues like vanishing or exploding gradients.
- **Xavier (Glorot) Initialization: Weights are drawn from a distribution with variance. Designed for sigmoid, softmax and tanh activations, it helps maintain balanced activations across layers.
- **He Initialization: A variant of Xavier where variance is scaled. It is well-suited for ReLU and its variants, preventing the dying ReLU problem.
- **Orthogonal Initialization: Weights are set as a random orthogonal matrix, ensuring columns are orthonormal. This method has shown strong performance in recurrent neural networks (RNNs).
- **Pretrained Initialization: Weights are initialized from a model trained on a related task (e.g., using ImageNet-pretrained CNN weights). This speeds up training and often improves performance on smaller datasets.
**7. What is an Activation Function and how does it work in Neural Networks?
An Activation Function is a mathematical function applied to the output of a neuron. It decides whether the neuron should be activated (pass information) or not.
**How it works:
- Each neuron calculates a weighted sum of its inputs plus a bias.
- The activation function is applied to this value.
- It introduces non-linearity, which allows the network to learn complex patterns instead of just simple linear relationships.
**Common Activation Functions:
- **Sigmoid: Outputs values between 0 and 1 (useful for probabilities).
- **ReLU (Rectified Linear Unit): Outputs 0 for negative values and the input itself for positive values.
- **Tanh: Outputs values between -1 and 1.
Without activation functions, a neural network would act like a simple linear regression model and fail to learn complex tasks like image recognition or NLP.
**8. What are the different types of Activation Functions used in Deep Learning?
- **Sigmoid function: It maps any value between 0 and 1. It is mainly used in binary classification problems where it converts the output of the preceding hidden layer into a probability value.
- **Softmax function: It is the extension of the sigmoid function used for multi-class classification problems in the output layer of the neural network. It maps the output of the previous layer into a probability distribution across classes, giving each class a probability value between 0 and 1, with the sum of probabilities equal to 1. The class with the highest probability is considered the predicted class.
- **ReLU (Rectified Linear Unit) function: It is a non-linear function that returns the input value for positive inputs and 0 for negative inputs. Deep neural networks frequently employ this function since it is both straightforward and effective.
- **Leaky ReLU function: It is similar to the ReLU function, but it adds a small slope for negative input values to prevent dead neurons.
- **Tanh (Hyperbolic Tangent) function: It is a non-linear activation function that maps the input value between -1 and 1. It is similar to the sigmoid function but provides both positive and negative results. It is mainly used for regression tasks where the output will be continuous values.
9. What are the different layers in a Neural Network?
A neural network is made up of multiple layers, each having a specific role in processing data:
**1. Input Layer:
- First layer that receives raw data (images, text, numbers).
- **Example: In image recognition, pixel values act as inputs.
**2. Hidden Layers:
- Intermediate layers between input and output.
- Perform most of the computation.
- Each hidden layer applies weights, biases and activation functions to extract features step by step.
- More hidden layers = deeper learning (Deep Neural Networks).
**3. Output Layer:
- Produces the final result (class label, probability, numeric value).
- **Example: For classification, it may output probabilities for different classes.
- Activation function depends on the task like Softmax for classification (multi-class), Sigmoid for binary classification and Linear for regression.
10. What is a Perceptron or a Single Layer Neural Network?
A Perceptron is the simplest type of artificial neural network model, introduced by Frank Rosenblatt in 1958. It is a single-layer neural network used for binary classification problems.
- It takes multiple inputs, multiplies each with a weight, adds a bias and passes the result through an activation function.
- If the output crosses a certain threshold, the perceptron outputs one class or otherwise, it outputs the other class.
**Formula:
y = f\Big(\sum (w_i \cdot x_i) + b\Big)
where f is the activation function, x_i are inputs, w_i are weights and b is bias.
**Example: Used for simple problems like checking whether a number is greater than a threshold (yes/no type outputs).
11. What is Multilayer Perceptron and How it is different from a Single-Layer Perceptron?
A Multilayer Perceptron (MLP) is an extension of the simple perceptron that contains one or more hidden layers between the input and output layers. It is a type of feedforward neural network and is widely used in deep learning.
- Each neuron in one layer is connected to every neuron in the next layer (fully connected).
- The network uses weights, biases and activation functions to transform inputs step by step.
- The hidden layers allow the model to learn non-linear and complex patterns, unlike a single perceptron.
**Structure:
- **Input Layer: accepts raw data.
- **Hidden Layers: process data using weighted connections and activation functions.
- **Output Layer: produces the final prediction (e.g., classification or regression output).
**Example: Handwriting recognition, image classification and speech recognition.
**12. How are the number of hidden layers and neurons per hidden layer selected?
There is no fixed rule for selecting hidden layers and neurons and they are chosen based on the complexity of the problem and are often tuned experimentally.
**Number of Hidden Layers
- For shallow problems or simple patterns we can use 1–2 hidden layers.
- For complex problems like images, speech or NLP we can use deeper networks with many layers.
- Universal Approximation Theorem says even a single hidden layer with enough neurons can approximate any function, but deeper networks often train more efficiently.
**Number of Neurons per Layer
- Too few neurons can lead to underfitting (model can’t capture the patterns).
- Too many neurons can lead to overfitting (model memorizes training data).
- A common practice is to start with a number between the size of the input layer and output layer, then adjust based on validation performance.
- Some heuristics methods like powers of 2 (e.g., 64, 128, 256) are commonly tried in practice.
In real projects, hidden layers and neurons are usually chosen by trial and error, cross-validation or automated methods like hyperparameter tuning.
**13. What is the difference between Shallow Networks and Deep Networks?
**1. Shallow Networks
- Have only one or two hidden layers.
- Suitable for simple tasks where patterns are not very complex.
- Easier to train, require fewer computations, but may struggle with high-dimensional data like images or speech.
**2. Deep Networks
- Have many hidden layers (sometimes dozens or hundreds).
- Capable of learning complex, hierarchical features automatically.
- Used for tasks like image recognition, natural language processing and speech recognition.
- Require more data, higher computation power and techniques to avoid problems like vanishing gradients.
**14. Why are Neural Networks Called Black Boxes?
Neural networks are often referred to as black boxes because their internal workings are not easily interpretable. While they can learn complex patterns and make highly accurate predictions, it is usually difficult to understand how inputs are transformed into outputs.
15. What are Feedforward Neural Networks?
Feedforward Neural Network is the simplest type of artificial neural network where the data flows only in one direction i.e from the input layer to hidden layers and then to the output layer.
- There are no cycles or loops in the connections.
- Each layer passes information forward and neurons are fully connected to the next layer.
- Training is usually done using backpropagation with gradient descent to adjust weights and biases.
- Easy to design and train for smaller tasks.
- Works well for problems like image recognition, speech recognition and regression tasks.
- Unlike recurrent networks, FNNs do not have memory of past inputs.
16. Are ANN, Single Layer Perceptron and Feedforward Neural Network the same?
They are related concepts but not exactly the same:
- **Artificial Neural Network (ANN): A broad term for any computational model inspired by the brain’s neurons. It can include single-layer, multilayer, feedforward or recurrent networks.
- **Single Layer Perceptron: The simplest type of ANN with only one layer of weights (no hidden layer). It can solve only linearly separable problems.
- **Feedforward Neural Network (FNN): A type of ANN where data flows in one direction (input → hidden → output). Both single-layer perceptron and multilayer perceptron are examples of FNNs.
In short we can say that:
- Every Perceptron is an ANN and also a Feedforward Network,
- But not every ANN or Feedforward Network is just a Perceptron (they can be deeper or recurrent).
17. What is forward and backward propagation?
**Forward Propagation:
- Input data is passed through the network layer by layer.
- Each neuron calculates a weighted sum of inputs, adds bias, applies an activation function and passes the output forward.
- The final output is compared with the actual target to calculate the error (loss).
- Example flow: Input→HiddenLayer(s)→Output
- Forward Propagation → computes the output.
**Backward Propagation (Backpropagation):
- Used to minimize the error by adjusting weights and biases.
- The error from the output layer is propagated backward through the network.
- Gradients are calculated using the chain rule of calculus and weights are updated using an optimization algorithm like Gradient Descent.
- Example update rule: w = w - \eta \cdot \frac{\partial L}{\partial w}
- Backward Propagation → updates the parameters to reduce error.
18. What is the cost function in deep learning?
A Cost Function in deep learning measures the difference between the predicted output of the model and the actual target values. It helps the network learn by guiding weight and bias updates during backpropagation. The aim is to minimize the cost so that predictions get closer to the actual results.
**Commonly used cost functions:
- **Binary Cross-Entropy: Used for binary classification tasks. It measures the difference between the predicted probability of the positive outcome and the actual outcome.
- **Categorical Cross-Entropy: Used for multi-class classification problems. It measures the difference between the predicted probability distribution and the actual probability distribution.
- **Sparse Categorical Cross-Entropy: Also for multi-class classification, but used when the actual label is represented as an integer instead of a one-hot encoded vector.
- **Kullback-Leibler Divergence (KL Divergence): Used in generative learning models like GANs and VAEs. It measures the difference between two probability distributions.
- **Mean Squared Error (MSE): Used for regression tasks. It measures the average squared difference between actual values and predicted values.
**19. What is Binary Cross-Entropy, Categorical Cross-Entropy and Sparse Categorical Cross-Entropy?
**1. Binary Cross-Entropy (BCE)
- Used for binary classification (two classes: 0 or 1).
- Measures the difference between the predicted probability of the positive class and the actual label.
- Formula: L = - \big[y \log(p) + (1-y)\log(1-p)\big]
- where y is the true label (0 or 1) and p is the predicted probability of class 1.
**2. Categorical Cross-Entropy (CCE)
- Used for multi-class classification when labels are one-hot encoded.
- Compares the predicted probability distribution across all classes with the one-hot encoded true distribution.
- Formula: L = - \sum_{i=1}^{C} y_i \log(p_i)
- where C is number of classes, y_i is 1 for the correct class and 0 otherwise, p_i is predicted probability for class i.
**3. Sparse Categorical Cross-Entropy (SCCE)
- Same as Categorical Cross-Entropy but used when labels are not one-hot encoded (just integer class indices).
- Saves memory and is easier to work with for large datasets.
- Example: Instead of [0,0,1,0][0,0,1,0][0,0,1,0] for class 2, you directly use y=2.
20. How do neural networks learn from the data?
Neural networks learn from data through an iterative process of forward propagation, error calculation and backpropagation.
- **Forward Propagation: Input data passes through the network and each neuron applies weights, biases and activation functions to produce an output.
- **Error Calculation: The network compares its output with the actual target values using a cost function to measure the difference (error).
- **Backpropagation: The error is propagated backward through the network. Gradients of the cost function with respect to weights and biases are calculated using the chain rule.
- **Weight and Bias Update: Optimization algorithms like Gradient Descent update the weights and biases to reduce the error.
- **Iteration: Steps 1–4 are repeated over multiple epochs until the network achieves minimal error and can generalize well on new data.
Neural networks learn by adjusting their parameters (weights and biases) to minimize the error between predicted and actual outputs.
21. What is Gradient Descent and its Variants?
Gradient Descent is an optimization algorithm used in neural networks to minimize the cost function by iteratively updating the weights and biases in the opposite direction of the gradient. The gradient indicates the slope of the error surface and a parameter called the learning rate (lr) controls the size of each step taken. A large Learning Rate can overshoot the minimum while a very small Learning Rate can make training extremely slow. By moving against the gradient with an appropriate Learning Rate, the error is gradually reduced until it reaches a minimum.
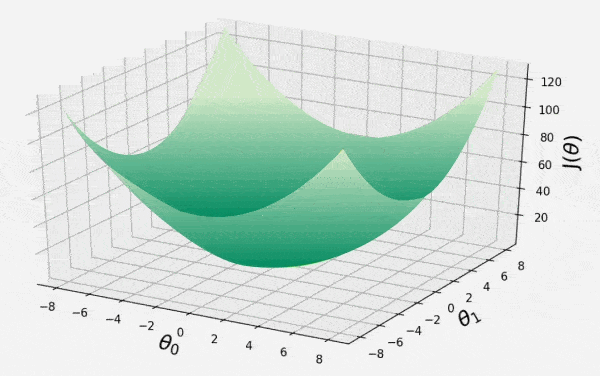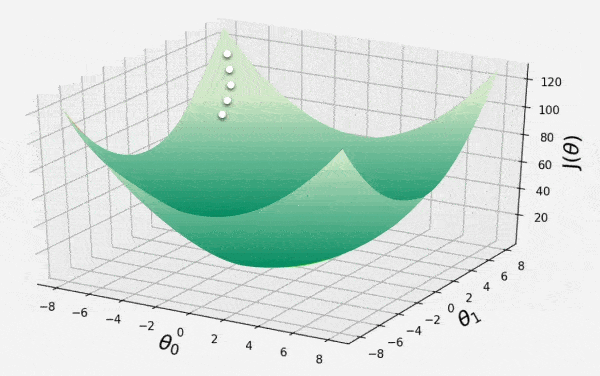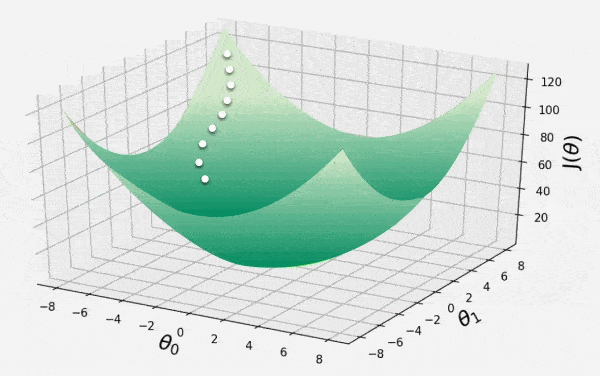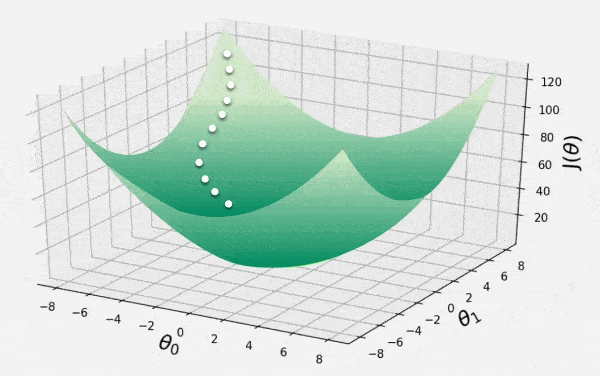
Gradient Descent
The gradient of the cost function with respect to each parameter is calculated and the parameters are updated using the formula:
\theta = \theta - \eta \cdot \frac{\partial L}{\partial \theta}
where
- \theta = parameter (weight or bias)
- \eta = learning rate
- L = cost function.
**Variants of Gradient Descent:
**1. Batch Gradient Descent:
- Uses the entire training dataset to compute the gradient in each iteration.
- Accurate but slow for large datasets.
**2. Stochastic Gradient Descent (SGD):
- Uses only one training example to compute the gradient per iteration.
- Faster but introduces more noise in updates.
**3. Mini-Batch Gradient Descent:
- A compromise between batch and stochastic.
- Uses a small batch of training examples per iteration.
- Widely used in practice due to efficiency and stability.
**4. Gradient Descent with Momentum:
- Accelerates convergence by adding a fraction of the previous update to the current update.
**5. Adaptive Methods:
- **Adagrad: Adapts learning rates based on past gradients.
- **RMSProp: Modifies Adagrad to perform better on non-stationary objectives.
- **Adam: Combines momentum and RMSProp for faster and reliable convergence.
- **In short: Gradient Descent and its variants help neural networks learn by gradually
22. Define the learning rate in Deep Learning.
The learning rate (lr) is a hyperparameter in deep learning that controls how much the model’s weights are adjusted during each update step in training. It determines the size of the step taken in the direction opposite to the gradient of the loss function.
- A high learning rate can make the training unstable or skip the minimum.
- A low learning rate makes learning stable but very slow.
General weight update rule:
w=w−η∇L(w)
Where:
- w: weight
- η: learning rate
- ∇L(w): gradient of the loss function w.r.t. weight
23. Difference between Batch Gradient Descent, Stochastic Gradient Descent and Mini-Batch Gradient Descent?
| Aspect | Batch Gradient Descent | Stochastic Gradient Descent (SGD) | Mini-Batch Gradient Descent |
|---|---|---|---|
| Data Used per Update | Entire training dataset | One training example | Small subset (batch) of training data |
| Speed | Very slow for large datasets | Very fast per update | Faster than batch, slower than SGD |
| Convergence | Stable and accurate | Noisy, may fluctuate | More stable than SGD and less costly than batch |
| Memory Requirement | Very high (needs whole dataset in memory) | Very low (one sample at a time) | Moderate (depends on batch size) |
| Practical Usage | Rarely used for large-scale tasks | Rarely used alone in deep learning | Most widely used in practice |
24. Explain Adagrad, RMSProp and Adam Optimizer.
**1. Adagrad (Adaptive Gradient Algorithm)
**It adjusts the learning rate for each parameter based on how frequently it is updated. It works well with sparse data like in NLP or recommendation systems.
**Working:
- Parameters that get frequent updates receive smaller learning rates.
- Rarely updated parameters get larger learning rates.
- Uses a running sum of squared gradients.
The learning rate keeps decreasing and eventually becomes very small and hence training may stop too early.
**2. RMSProp (Root Mean Square Propagation)
It Fixes Adagrad’s problem by using a moving average of squared gradients instead of the sum. It works well for non-stationary data like RNNs in sequence tasks.
**Working:
- Keeps track of recent squared gradients (not the entire history).
- This prevents the learning rate from shrinking too much.
We need to carefully tune hyperparameters like learning rate and decay factor.
**3. Adam (Adaptive Moment Estimation)
It combines the benefits of Momentum and RMSProp. It is the default optimizer in deep learning, offering fast convergence and working well for large datasets and parameters.
**Working:
- Keeps track of exponentially decaying average of past gradients (momentum).
- Also tracks the average of squared gradients (like RMSProp).
- Corrects bias in the estimates.
Sometimes it can lead to overfitting or poor generalization if not tuned.
25. What is Momentum-based Gradient Descent?
Momentum-based Gradient Descent is an optimization method that accelerates learning by adding a fraction of the previous update (velocity) to the current gradient. This reduces oscillations and helps the model converge faster.
Formula is:
v=βv−η∇L(w)
w=w+v
Where:
- v: velocity (accumulated gradient)
- β: momentum term (typically 0.9)
- η: learning rate
- ∇L(w): gradient of loss w.r.t. weights
This allows faster convergence, especially in ravines or areas with steep slopes in one direction and flat in another.
**26. What is the Vanishing and Exploding Gradient Problem?
In deep neural networks, during backpropagation, gradients are propagated backward through many layers. Depending on how the weights and activations behave, gradients can either become extremely small (vanish) or extremely large (explode).
**Vanishing Gradient:
- Gradients shrink as they move backward through layers.
- Earlier layers learn very slowly or stop learning.
- Common in deep networks with activation functions like sigmoid or tanh.
**Exploding Gradient:
- Gradients grow exponentially as they move backward.
- Causes unstable updates where weights become very large.
- Training may diverge instead of converging.
**Solutions:
- Use activation functions like ReLU instead of sigmoid/tanh.
- Apply weight initialization techniques.
- Use gradient clipping to prevent exploding gradients.
- Use optimizers like RMSProp or Adam that adapt the learning rate.
**27. What is Gradient Clipping?
Gradient Clipping is a technique used to prevent the exploding gradient problem during training of deep neural networks. When gradients become too large, weight updates can be unstable, causing the model to diverge. With gradient clipping, we set a threshold value and if the gradient exceeds this value, it is scaled down to stay within the limit.
Two common approaches:
- **Norm Clipping: Scale the entire gradient vector if its norm is larger than the threshold.
- **Value Clipping: Clip individual gradient values to lie within a fixed range.
28. Define Epoch, Iterations and Batches.
**1. Batch:
- A batch is a subset of the training dataset used for one forward and backward pass through the network.
- Example: If you have 10,000 samples and a batch size of 100, then each batch contains 100 samples.
**2. Iteration:
- One iteration is a single update of the model’s parameters using one batch.
- Example: With 10,000 samples and batch size of 100, you’ll have \frac{10,000}{100} = 100 iterations in one epoch.
**3. Epoch:
- One epoch means the model has seen the entire dataset once, i.e., all batches have been processed.
- Example: With 10,000 samples and batch size of 100, one epoch = 100 iterations.
**29. How to Avoid Overfitting in Neural Networks?
Overfitting happens when a neural network memorizes the training data instead of learning general patterns. Some common techniques to reduce overfitting are:
- **Use More Training Data: Larger datasets help the model generalize better.
- **Regularization (L1/L2): Adds a penalty to large weights, preventing the model from becoming too complex.
- **Dropout: Randomly disables a fraction of neurons during training, forcing the network to learn robust features.
- **Early Stopping: Stop training when validation loss stops improving.
- **Data Augmentation: Generate new training samples by transforming existing data (e.g., image rotation, flipping).
- **Batch Normalization: Normalizes activations to reduce internal covariate shift and improve generalization.
- **Reduce Model Complexity: Use fewer layers/neurons if the dataset is small.
- **Cross-Validation: Monitor validation performance to tune hyperparameters properly.
**30. What is Dropout and Early Stopping in Neural Networks?
**1. Dropout
- Dropout is a regularization technique where, during training, a random fraction of neurons is temporarily "dropped" (ignored).
- This prevents the network from relying too heavily on specific neurons and forces it to learn more robust, generalized patterns.
- At test time, all neurons are used, but their outputs are scaled to match training conditions.
**2. Early Stopping
- Early Stopping is a method where training is stopped once the model’s performance on a validation set stops improving.
- This prevents overfitting because continuing to train after that point usually makes the model memorize the training data instead of generalizing.
- Commonly implemented by monitoring validation loss or accuracy.
**31. What is Data Augmentation and Its Techniques?
Data Augmentation is a technique used to artificially increase the size and diversity of a training dataset by applying various transformations to existing data. It helps neural networks generalize better and reduces overfitting.
**Common Techniques in Image Data Augmentation:
- **Rotation: Rotating images by a few degrees.
- **Flipping: Horizontal or vertical flips.
- **Scaling/Zooming: Changing the size or zoom of the image.
- **Translation/Shifting: Moving the image along X or Y axis.
- **Shearing: Slanting the shape of objects.
- **Brightness/Contrast Adjustment: Changing image brightness or contrast.
- **Adding Noise: Introducing random noise to make the model robust.
**For Text or NLP:
- Synonym replacement
- Random insertion or deletion of words
- Back translation (translating text to another language and back)
**For Time-Series Data:
- Jittering (adding noise)
- Scaling, shifting or window slicing
**32. What is Batch Normalization?
Batch Normalization (BN) is a technique used in neural networks to normalize the inputs of each layer so that they have a consistent distribution during training. This reduces the problem of internal covariate shift, where the input distribution to a layer keeps changing as previous layers update, which can slow down training.
**How it works:
- For each mini-batch, calculate the mean (\mu_B) and variance (\sigma_B^2) of the inputs.
- Normalize the inputs: \hat{x} = \frac{x - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}
- Apply learnable scale and shift parameters (\gamma and \beta) so the network can adjust the normalized values if needed: y = \gamma \hat{x} + \beta
33. **What is CNN (Convolutional Neural Network)?
A Convolutional Neural Network (CNN) is a type of deep learning model mainly used for image recognition, computer vision and pattern detection. Unlike traditional neural networks, CNNs automatically detect important features (edges, textures, shapes) from raw data without manual feature engineering.
**Key parts of CNN:
- **Convolution Layer: extracts features from input.
- **Pooling Layer: reduces dimensions (downsampling).
- **Fully Connected Layer: performs final classification or prediction.
**Applications: Image classification, face recognition, self-driving cars, medical imaging, NLP (with 1D convolutions), etc.
**34. What do you mean by Convolution?
- **Convolution is a mathematical operation used in CNNs to extract features from data like images.
- It works by sliding a small matrix called a kernel or filter over the input image and performing element-wise multiplication + summation.
- The result is a feature map that highlights important patterns (edges, corners, textures).
**Example:
- Suppose you have a 5×5 image and a 3×3 filter.
- The filter slides over the image, multiplies numbers element-wise, sums them up and creates a smaller output matrix.
- Different filters detect different patterns (horizontal edges, vertical edges, etc.).
35. What is a kernel?
A **kernel also called a **filter in deep learning is a small matrix of numbers used in the convolution operation of a CNN. It is a weight matrix (for example 3×3 or 5×5) that slides over the input (like an image) to extract features. During convolution, the kernel performs element-wise multiplication with the part of the input it overlaps and the results are summed to form a feature map.
- Kernels are learned automatically during training.
- Size is usually small (3×3, 5×5) compared to the input image.
- Multiple kernels are used in a CNN where each learns to detect different features.
Suppose you have a 3×3 kernel:
K = \begin{bmatrix} 1 & 0 & -1 \\ 1 & 0 & -1 \\ 1 & 0 & -1 \end{bmatrix}
- If this kernel slides over an image, it highlights vertical edges.
- Different kernels detect different features: edges, corners, textures, patterns.
36. Define stride.
Stride is the number of steps the kernel (filter) moves across the input matrix during convolution. It is the is the step size of the filter movement, deciding how much the filter shifts across the input. By default, stride = 1, meaning the kernel shifts one cell at a time (both horizontally and vertically).
- Controls the spatial size of the feature map.
- Larger stride means smaller output and faster computation but may lose detail.
- Smaller stride means bigger output and more detail but more computation.
Suppose you have a 5×5 image and a 3×3 kernel:
- With stride = 1 → kernel moves 1 step at a time hence larger output feature map.
- With stride = 2 → kernel moves 2 steps at a time hence smaller output feature map.
37. What is Pooling Layer and its different types?
The Pooling Layer is used in Convolutional Neural Networks (CNNs) to reduce the size of feature maps while keeping the important information. It makes the network faster, prevents overfitting and helps capture dominant features. Pooling works by sliding a small window (like 2×2) over the feature map and summarizing the values inside it.
**Types of Pooling:
**1. Max Pooling
- Takes the maximum value from the window.
- Helps capture the most important features (like strong edges).
- Example (2×2 window): \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} \rightarrow 4
**2. Min Pooling
- Selects the minimum value from each window.
- Rarely used, but sometimes applied in special cases where detecting the least intense features is required.
- Example (2×2 window): \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} \rightarrow 1
**3. Average Pooling
- Takes the average value from the window.
- Keeps overall information but less effective at feature detection compared to max pooling.
- Example (2×2 window): \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} \rightarrow (1+3+2+4)/4 = 2.5
**4. Global Pooling
- Instead of a small window, the pooling is applied across the entire feature map.
- Reduces each feature map to a single value.
- Commonly used before the fully connected layers in CNNs.
38. **What is Padding in CNN?
In CNNs, Padding means adding extra rows and columns (usually zeros) around the input matrix before applying convolution. It is used:
- To control the spatial size and use same size for all input images.
- To avoid losing information at the image borders.
- To allow filters to cover edges and corners properly.
**Types of Padding:
**1. Valid Padding (No Padding)
- No extra rows/columns are added.
- Output feature map is smaller than input because the kernel cannot slide outside the input.
- Formula for output size: O = \frac{(I - K)}{S} + 1 where I = input size, K = kernel size, S = stride.
**2. Same Padding (Zero Padding)
- Zeros are added around the input so that the output size = input size.
- Useful when we want to preserve spatial dimensions.
- Example: A 5×5 input with a 3×3 kernel remains 5×5 after convolution.
**3. Full Padding
- Adds enough padding so that the kernel can slide over every element of the input, even corners.
- Output size is larger than the input size.
**4. Reflective / Replication Padding (less common)
- Instead of zeros, the border values of the input are reflected or repeated.
- Used in some computer vision tasks to avoid introducing artificial black borders (from zero-padding).
39. What is the difference between object detection and image segmentation?
| Feature | Object Detection | Image Segmentation |
|---|---|---|
| **Definition | Identifies objects and their locations in an image. | Assigns a class label to each pixel in the image. |
| **Output | Bounding boxes with class labels. | Pixel-wise classification mask (colored regions). |
| **Granularity | Object-level understanding. | Pixel-level understanding (detailed boundaries). |
| **Use Cases | Face detection, pedestrian detection, vehicle detection. | Medical imaging, self-driving cars, satellite image analysis. |
| **Algorithms | YOLO, SSD, Faster R-CNN, R-CNN. | U-Net, Mask R-CNN, DeepLab, FCN. |
40. What are Recurrent Neural Networks (RNNs) and How it works?
A Recurrent Neural Network (RNN) is a type of neural network designed to work with sequential data like text, speech, time series or video frames. Unlike traditional neural networks, RNNs have a memory of previous inputs, which helps them capture context and dependencies in sequences.
h_t = f(Uh_{t-1} + Wx_t + b)
Where:
- h_t = Current state at time t
- x_t = Input vector at time t
- h_{t-1} = Previous state at time t-1
- U = Weight matrix of recurrent neuron for the previous state
- W = Weight matrix of input neuron
- b = Bias added to the input vector and previous hidden state
- f = Activation functions
And the output of the RNN at each time step will be:
y_t = g(Vh_t + c)
Where:
- y = Output at time t
- V = Weight matrix for the current state in the output layer
- C = Bias for the output transformations.
- g = activation function
Here, W, U, V, b and c are the learnable parameters and it is optimized during the backpropagation.
**RNN Working
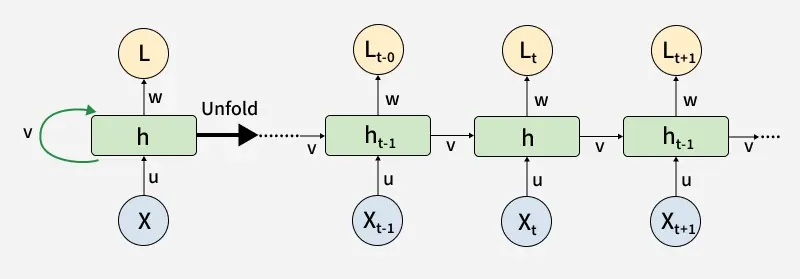
RNN
**1. Sequential Processing:
- RNNs take input one step at a time (e.g., one word in a sentence).
- At each step, the network processes the input and updates its hidden state (memory).
**2. Hidden State (Memory):
- The hidden state carries information from previous steps and passes it forward in the sequence.
- This allows the RNN to "remember" past inputs while processing the current one.
**3. Weights Sharing:
- The same set of weights is applied at each step, which makes RNNs efficient for variable-length sequences.
**4. Output:
- Depending on the task, RNNs can work as One-to-One, One-to-Many, Many-to-One or Many-to-Many models.
41. How does the Backpropagation through time work in RNN?
Backpropagation Through Time (BPTT) is the method used to train Recurrent Neural Networks (RNNs) by applying the backpropagation algorithm across time steps. It allows the network to learn temporal dependencies in sequential data.
**BPTT working:
**1. Forward Pass:
- The input sequence is fed into the RNN one element at a time.
- At each step, the hidden state is updated using the recurrent connections, carrying information from previous steps.
- The RNN produces outputs for each time step.
**2. Unrolling the RNN:
- The RNN is conceptually unrolled into a feedforward network, with one layer per time step.
- This helps visualize the flow of information and errors across the sequence.
**3. Error Calculation:
- The network computes the difference between the predicted outputs and actual outputs at each time step.
- These errors are summed (or averaged) across all time steps to calculate the total loss.
**4. Backward Pass (Through Time):
- Using the chain rule, gradients of the loss with respect to weights are computed from the last time step to the first.
- Errors are propagated backward through both the hidden states and the recurrent weights.
**5. Weight Update:
- Gradients are used to update the network’s weights via an optimization algorithm like Gradient Descent or its variants (Adam, RMSProp).
**6. Iteration:
- The process is repeated over multiple epochs until the network converges.
- By accumulating gradients over time, the RNN learns patterns and dependencies in sequential data.
BPTT enables the RNN to remember past information and adjust its weights to better predict future elements in a sequence, making it ideal for tasks like language modeling, time-series forecasting and speech recognition.
42. What is Vanishing and Exploding gradient problems in traditional RNNs?
**Vanishing Gradient Problem
- Occurs when gradients shrink exponentially as they are backpropagated through time.
- Makes it difficult for RNNs to learn long-term dependencies.
- Early time-step information has very little effect on weight updates.
- Typically caused by sigmoid or tanh activations, which squash values between 0–1 or -1–1.
Network forgets earlier inputs hence leading to poor performance on long sequences.
**Exploding Gradient Problem
- Occurs when gradients grow exponentially as they are backpropagated.
- Can cause unstable training and very large weight updates.
- Usually happens when weights are large or sequences are long.
Loss function may diverge and the network fails to learn.
**Solutions:
- **Vanishing gradients: Use LSTM or GRU cells, which have gating mechanisms to retain long-term information.
- **Exploding gradients: Apply gradient clipping to limit the gradient values.
43. What is LSTM and How it works?
LSTM (Long Short-Term Memory) is a type of Recurrent Neural Network (RNN) designed to overcome the vanishing and exploding gradient problems in traditional RNNs. It is especially good at learning long-term dependencies in sequential data.
Unlike RNNs, which have a single hidden state, LSTMs have a memory cell that can retain information over long sequences. This memory is controlled by gates that regulate the flow of information.
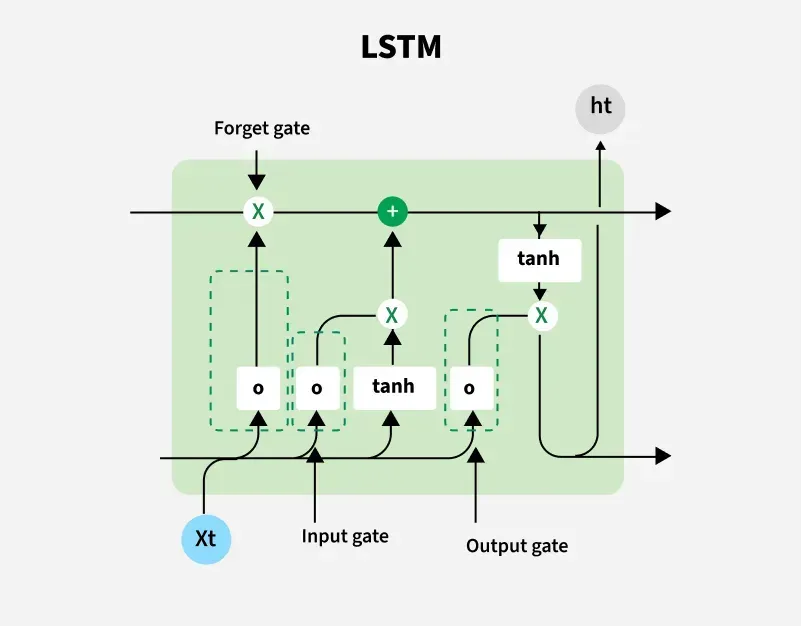
LSTM Model architecture
**Key Components of an LSTM Cell:
**1. Cell State (C):
- The “memory” of the cell that carries relevant information across time steps.
- Modified selectively via the gates to remember or forget data.
**2. Hidden State (h):
- The output of the LSTM at each time step.
- Used for predictions or passed to the next LSTM cell.
**3. Forget Gate (f):
- Decides which information from the previous cell state should be discarded.
- Takes current input x_t and previous hidden state h_{t-1}, multiplies with weights, adds bias and passes through a sigmoid activation.
- Output is between 0 and 1 (0 = forget, 1 = keep).
**4. Input Gate (i):
- Determines which new information should be added to the cell state.
- Combines current input x_t and previous hidden state h_{t-1} through a sigmoid function.
- Multiplies this with a tanh-transformed candidate vector to update the cell state.
**5. Output Gate (o):
- Selects the relevant information from the current cell state to output.
- Uses tanh on the cell state and a sigmoid gate to regulate what gets passed as the hidden state h_t.
**LSTM Working:
- **Forget step: Decide what to remove from the previous cell state.
- **Input step: Decide what new information to add to the cell state.
- **Update cell state: Combine the forget and input steps to update the memory.
- **Output step: Decide what information to output to the next cell or layer.
44. What is BiRNN and BiLSTM?
**1. BiRNN (Bidirectional RNN)
- Processes sequential data in both directions i.e forward (past → future) and backward (future → past).
- Has two hidden layers per time step i.e one for forward pass and one for backward pass.
- Captures context from both past and future for better predictions.
- Useful in tasks like text classification, sentiment analysis, speech recognition.
**BiLSTM (Bidirectional LSTM)
- Extension of BiRNN using LSTM cells instead of standard RNN cells.
- Processes sequence forward and backward while handling long-term dependencies.
- Benefits from LSTM’s gates (input, forget, output) and avoids vanishing gradient problem.
- Widely used in NLP, machine translation, named entity recognition.
45. What is GRU and How it works?
GRU (Gated Recurrent Unit) is a type of Recurrent Neural Network (RNN) similar to LSTM but with a simpler architecture. It is designed to capture long-term dependencies in sequential data while being computationally more efficient than LSTM.
Unlike LSTM, which has three gates (input, forget, output), a GRU has two gates and no separate cell state. The hidden state serves as both memory and output.
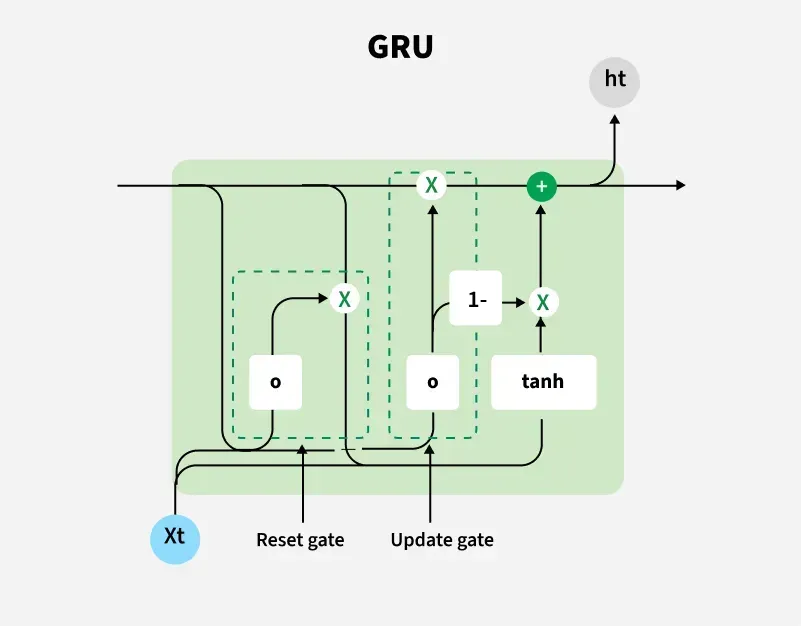
GRU Model architecture
**Key Components of a GRU Cell:
**1. Update Gate (z):
- Determines how much of the previous hidden state should be kept and how much of the new candidate hidden state should be added.
- Controls the balance between remembering past information and updating with new information.
**2. Reset Gate (r):
- Controls how much of the previous hidden state to forget when calculating the new candidate hidden state.
- Helps the network focus on relevant recent information.
**3. Candidate Hidden State (ht~\tilde{h_t}ht~):
- Computed using the current input and the previous hidden state (modified by the reset gate).
- Represents the new information to be added to the hidden state.
**4. Final Hidden State (h):
- Computed as a weighted combination of the previous hidden state and the candidate hidden state, controlled by the update gate.
**GRU Working:
- **Reset Gate: Decide which past information to forget.
- **Candidate Hidden State: Compute new information based on the reset-modified previous hidden state and current input.
- **Update Gate: Decide how much of the candidate hidden state to keep and how much of the previous hidden state to retain.
- **Hidden State Update: Combine previous hidden state and candidate to produce the current hidden state.
How GRU is better than LSTM
- GRU has only 2 gates (update and reset) compared to LSTM’s 3 gates, making it simpler.
- GRU has no separate cell state amd hidden state acts as memory and output.
- Fewer parameters means faster training and lower computational cost.
- Works well on smaller datasets where LSTM may overfit or train slowly.
- Achieves comparable performance to LSTM on most sequence tasks.
- Easier to implement and tune due to simpler architecture.
46. Difference between RNN, LSTM and GRU
| Feature | RNN | LSTM | GRU |
|---|---|---|---|
| **Architecture | Single hidden state | Hidden state + cell state | Single hidden state with gating |
| **Gates | None | 3 gates: input, forget, output | 2 gates: update, reset |
| **Memory | Limited memory, struggles with long-term dependencies | Can retain long-term dependencies | Can retain long-term dependencies |
| **Gradient Problem | Introduces to vanishing/exploding gradients | Mitigates vanishing/exploding gradients | Mitigates vanishing/exploding gradients |
| **Computational Complexity | Low | Higher due to more gates | Lower than LSTM |
| **Performance on Long Sequences | Poor | Good | Comparable to LSTM, often faster |
| **Use Cases | Short sequences, simple tasks | Long sequences, NLP, time-series | Long sequences, NLP, time-series, faster training |
47. What is the Transformer model?
The Transformer is a neural network architecture that relies on the attention mechanism to efficiently capture long-range dependencies in sequences. Unlike traditional RNNs, it processes sequences in parallel which makes it faster and more effective for tasks in NLP such as machine translation, text summarization, question answering and word embedding.
**Key Components of the Transformer:
**1.Self-Attention Mechanism:
- Allows each word in the input sequence to attend to all other words, assigning weights based on relevance.
- Captures both short-term and long-term dependencies, critical for understanding context in NLP tasks.
**2. Encoder-Decoder Architecture:
- **Encoder: Processes the input sequence and generates a context vector representing the entire sequence.
- **Decoder: Uses the context vector to construct the output sequence step by step.
**3. Multi-Head Attention:
- Uses multiple attention heads in parallel to learn different types of correlations and patterns.
- Each head focuses on different parts of the input, allowing the model to capture a wide range of dependencies.
**4. Positional Encoding:
- Adds information about the order of words in the sequence.
- Can use sine/cosine functions or learned embeddings.
- Ensures the model understands relative and absolute positions in the sequence.
**5. Feed-Forward Neural Networks:
- Applied independently to each position after the attention layers.
- Helps the model learn complex non-linear correlations in the data.
**6. Layer Normalization and Residual Connections:
- **Layer normalization: Stabilizes activations, helping the network converge faster.
- **Residual connections: Pass inputs directly to subsequent layers, mitigating vanishing gradient problems and improving gradient flow.
48. What is Attention Mechanism?
The Attention Mechanism is a technique in neural networks that allows the model to focus on the most relevant parts of the input sequence when making predictions. Instead of treating all inputs equally, attention assigns different weights to different parts of the input, helping the model capture important dependencies more effectively.
- Captures long-range dependencies without sequential processing like RNNs.
- Helps models focus on important parts of the input.
- Forms the core of Transformers, BERT, GPT and other state-of-the-art models
**How It Works:
**1. Assigning Weights:
- Each element in the input sequence is assigned a **score based on its relevance to the current output step.
- Higher scores mean more importance.
**2. Weighted Sum:
- The scores are normalized (usually with softmax) to form weights.
- A weighted sum of input vectors is computed to create a context vector.
**3. Context Vector:
- The context vector represents the relevant information from the input sequence for the current output step.
- This vector is then used to make predictions.
49. What are different types of attention mechanisms?
**1. Global (Soft) Attention:
- Considers all positions in the input sequence when computing attention for the current output.
- Computes a weighted sum over all encoder outputs.
- Useful for capturing long-range dependencies.
**2. Local (Hard or Windowed) Attention:
- Only a subset of input positions (a window around a specific position) is considered.
- Reduces computation compared to global attention.
- Useful when relevant context is nearby in the sequence.
**3. Self-Attention:
- Each element in the sequence attends to all other elements in the same sequence.
- Captures relationships within the same sequence.
- Core component of Transformers.
**4. Scaled Dot-Product Attention:
- Computes attention using dot product of query and key vectors.
- Scales the result by the square root of the key dimension for stability.
- Followed by softmax to get attention weights.
**5. Multi-Head Attention:
- Uses multiple attention heads in parallel.
- Each head learns different types of relationships in the sequence.
- Combines outputs of all heads for richer representation.
**50. What is Positional Encoding?
Positional Encoding is a technique used in Transformer models to provide information about the order of tokens in a sequence. Since Transformers process all input tokens in parallel (unlike RNNs), they have no inherent sense of sequence order. Positional encoding solves this by adding position-specific information to the token embeddings.
**51. What are Layer Normalization and Residual Connections?
**1. Layer Normalization (LayerNorm):
- A technique to normalize the activations of a neural network layer across the features for each training example.
- Ensures that the outputs have mean ≈ 0 and variance ≈ 1, which stabilizes and speeds up training.
- Commonly used in Transformers instead of batch normalization because it works well with sequential data and variable batch sizes.
- It reduces internal covariate shift, helping deeper networks converge faster.
**2. Residual Connections (Skip Connections):
- Shortcut connections that add the input of a layer directly to its output.
- Helps preserve information from earlier layers and mitigate vanishing gradient problems.
- It makes training of very deep networks feasible and improves gradient flow.
52. What are Tokens and Embeddings?
**1. Tokens
- Tokens are the basic units of text that a model processes.
- Text is split into smaller pieces (tokenized) before being fed to a neural network.
- Can be words, subwords or characters depending on the tokenizer.
Example:
- Sentence: "I love AI"
- Word-level tokens: ["I", "love", "AI"]
- Subword tokens (BPE): ["I", "lo", "ve", "AI"]
**2. Embeddings
- Embeddings are vector representations of tokens in a continuous, high-dimensional space.
- Capture semantic meaning of words so that similar words have similar vectors.
- Allow neural networks to process text numerically.
Example:
- "king" → [0.25, 0.1, ..., 0.72]
- "queen" → [0.27, 0.12, ..., 0.70]
- Vectors for "king" and "queen" are close in the embedding space.
53. What is an Encoder-Decoder network in Deep Learning?
An Encoder-Decoder network is a neural network architecture that learns to map an input sequence to an output sequence, which may have a different length and structure. It is used in Machine Translation, Text Summarization, Chatbots and Image Captioning. It consists of two main components: encoder and decoder.
**1. Encoder
- Takes a variable-length input sequence (e.g., a sentence, image or video).
- Processes the sequence step by step to create a fixed-length context vector (encoded representation).
- The context vector captures the important information from the entire input sequence, condensing it into a single representation.
**2. Decoder
- Takes the encoded context vector as input.
- Generates the output sequence step by step (e.g., translated sentence, image caption or video prediction).
- Updates its hidden state at each step based on the context vector and previously generated outputs.
**Training
- The network is trained on pairs of input and target sequences.
- The goal is to minimize the difference between the predicted output sequence and the true target sequence using a suitable loss function.
54. What is an Autoencoder?
An Autoencoder is a type of neural network designed to learn efficient representations of data (encoding) by training the network to reconstruct its input at the output. It is commonly used for dimensionality reduction, feature learning, Anomaly Detection and data denoising.
- Autoencoders are unsupervised learning models because they don’t require labeled data.
- The network is trained to reproduce the input at the output as accurately as possible.
- Variants include Denoising Autoencoders, Sparse Autoencoders and Variational Autoencoders (VAE)..
**Key Components:
**1. Encoder:
- Compresses the input data into a lower-dimensional latent representation (also called a bottleneck).
- Captures the most important features of the input while reducing redundancy.
**2. Latent Space:
- The compressed representation produced by the encoder.
- Holds the essential information needed to reconstruct the input.
**3. Decoder:
- Reconstructs the original input from the latent representation.
- Tries to minimize the difference between the input and output using a loss function like Mean Squared Error (MSE).
55. What are dfferent types of Autoencoder?
**1. Vanilla (Basic) Autoencoder:
- Standard autoencoder with an encoder and decoder.
- Learns to reconstruct the input from a compressed latent representation.
- Mainly used for dimensionality reduction and feature learning.
**2. Denoising Autoencoder (DAE):
- Trained to reconstruct the original input from a corrupted/noisy version.
- Helps the network learn robust features that are insensitive to noise.
- Useful for image and signal denoising.
**3. Sparse Autoencoder:
- Adds a sparsity constraint to the latent representation.
- Encourages most neurons to be inactive, forcing the network to learn efficient and meaningful features.
- Used for feature extraction and anomaly detection.
**4. Variational Autoencoder (VAE):
- A probabilistic autoencoder that models the latent space as a probability distribution.
- Generates new data samples by sampling from the latent distribution.
- Widely used in generative tasks like image generation.
**5. Convolutional Autoencoder (CAE):
- Uses convolutional layers instead of fully connected layers.
- Better suited for image and spatial data, preserving spatial hierarchies.
- Often used for image compression, denoising and feature extraction.
**6. Contractive Autoencoder (CAE):
- Adds a regularization term to make the latent representation robust to small input changes.
- Useful for learning invariant features.
**56. What is a Variational Autoencoder (VAE)?
A Variational Autoencoder (VAE) is a type of probabilistic autoencoder that learns to model the underlying probability distribution of the input data. Unlike a standard autoencoder that maps inputs to a fixed latent vector, a VAE maps inputs to a distribution in the latent space, allowing it to generate new, realistic data samples by sampling from this distribution.
**57. What is a Seq2Seq Model?
A Sequence-to-Sequence (Seq2Seq) model is a type of neural network architecture designed to map an input sequence to an output sequence, where the lengths of the input and output may differ. It is widely used in natural language processing (NLP) tasks such as machine translation, text summarization, Speech Recognition and chatbots.
**Key Components:
**1. Encoder:
- Processes the input sequence and compresses it into a context vector (or hidden representation).
- Captures the essential information from the entire input.
**2. Decoder:
- Generates the output sequence step by step using the context vector.
- Updates its hidden state at each step based on previous outputs and the context vector.
**3. Attention Mechanism (Optional but Common):
- Allows the decoder to focus on relevant parts of the input sequence at each step instead of relying solely on the fixed context vector.
- Improves performance, especially for long sequences.
58. What is a Generative Adversarial Network (GAN)?
A Generative Adversarial Network (GAN) is a type of neural network architecture used to generate realistic data that resembles a given dataset. It consists of two neural networks i.e a Generator and a Discriminator. They compete with each other in a game-like setup, which helps the generator produce increasingly realistic outputs.
**1. Generator:
- Takes a random noise vector as input and generates synthetic data (e.g., images, text, audio).
- Goal: Fool the discriminator into thinking the generated data is real.
**2. Discriminator:
- Takes real or generated data as input and predicts whether it is real or fake.
- Goal: Correctly distinguish between real data from the training set and fake data from the generator.
**How It Works:
The generator and discriminator are trained simultaneously:
- The generator creates fake samples.
- The discriminator evaluates them against real data.
- Both networks update their weights based on their performance.
This adversarial training continues until the generator produces data that the discriminator cannot reliably distinguish from real data. It is used in image generation, data augmentation, etc.
59. Different types of Generative Adversarial Networks (GANs)?
**1. Vanilla GAN (Basic GAN):
- The original GAN with a simple generator and discriminator.
- Trains on adversarial loss to generate realistic data from random noise.
**2. Conditional GAN (cGAN):
- Generates data conditioned on additional information like class labels.
- Example: Generate images of a specific digit or object category.
**3. Deep Convolutional GAN (DCGAN):
- Uses convolutional layers in both generator and discriminator.
- Better suited for image generation, capturing spatial hierarchies effectively.
**4. Wasserstein GAN (WGAN):
- Uses the Wasserstein distance instead of standard GAN loss.
- Stabilizes training and reduces mode collapse (generator producing limited variety of samples).
**5. Least Squares GAN (LSGAN):
- Uses least squares loss for the discriminator instead of cross-entropy.
- Produces higher quality images and reduces vanishing gradient problems.
**6. CycleGAN:
- Enables image-to-image translation without paired datasets.
- Example: Convert horses → zebras or summer → winter scenes.
**7. Progressive GAN (PGGAN):
- Trains GANs progressively from low-resolution to high-resolution images.
- Produces high-quality and high-resolution outputs.
**8. StyleGAN:
- Introduces style-based generator architecture.
- Allows control over specific features in generated images (e.g., hair style, facial expression).
**60. What is StyleGAN?
StyleGAN is a type of Generative Adversarial Network (GAN) designed for high-quality image generation with fine-grained control over features of the generated images. It was developed by NVIDIA and is widely known for producing photorealistic human faces and other high-resolution images.
**1. Style-Based Generator:
- Instead of feeding the latent vector directly to the generator, StyleGAN transforms it into “styles” at each layer.
- Allows control over different levels of detail: coarse features (pose, shape), middle features (facial features), fine features (hair, skin texture).
**2. Adaptive Instance Normalization (AdaIN):
- Combines the latent styles with feature maps at each layer of the generator.
- Enables the network to control specific attributes of the output image independently.
**3. Separation of Features:
- The architecture allows coarse, middle and fine features to be manipulated separately, giving better control over the generated images.
**4. High-Resolution Image Generation:
- Produces very realistic and detailed images compared to traditional GANs.
- Avoids typical GAN artifacts due to improved architecture and progressive training.
**61. What is Transfefine Learning and Fine-Tuning?
**1. Transfer Learning:
- Transfer Learning is a technique in deep learning where a pre-trained model on a large dataset is reused for a new, related task.
- Instead of training a model from scratch, it uses the knowledge (features) learned from the original task.
- Example: Using a model trained on ImageNet to classify medical images.
**2. Fine-Tuning:
- Fine-tuning is the process of adapting a pre-trained model to a new task.
- Typically, some initial layers are frozen (retain learned features) and later layers are retrained on the new dataset.
- Allows the model to learn task-specific features while retaining general knowledge.
**Example:
- Take a CNN pre-trained on ImageNet.
- Freeze the first few convolutional layers.
- Retrain the last few layers on a dataset of dog breeds.
62. What is the Difference Between Transfer Learning and Fine-Tuning?
| Aspect | **Transfer Learning | **Fine-Tuning |
|---|---|---|
| **Definition | Using a pre-trained model on a new, related task without modifying its internal weights much. | Adapting a pre-trained model to a new task by retraining some or all layers on the new dataset. |
| **Training | Usually, only the final layer(s) are trained for the new task. | Some layers are frozen and others are retrained to learn task-specific features. |
| **Purpose | Leverage existing general features learned from a large dataset. | Adjust the model to better fit the specifics of the new dataset. |
| **When Used | When the new dataset is small or similar to the original dataset. | When the new task is related but slightly different and requires more adaptation. |
| **Example | Using ImageNet-pretrained CNN to classify cats vs dogs by just replacing the final layer. | Using ImageNet-pretrained CNN, freezing early layers and retraining later layers on a small dog breed dataset. |