SMS Spam Detection using TensorFlow in Python (original) (raw)
Last Updated : 11 Dec, 2025
SMS spam detection is automatically classifying incoming text messages as either ham (legitimate) or spam using machine learning and deep learning models, so that harmful, fraudulent or unwanted messages can be filtered before reaching the user. In this project, we will:
- Load and clean an SMS spam dataset and encode labels into numeric form.
- Prepare text statistics and a text vectorisation pipeline for deep learning models.
- Build three TensorFlow models, i.e a dense embedding model, a Bi-LSTM model and a transfer-learning model using the Universal Sentence Encoder (USE).
- Train all models with a shared helper pipeline and evaluate them on accuracy, precision, recall and F1-score.
- Visualise model performance using bar and line plots to compare metrics.
Implementation
Step 1: Import Libraries
We will import all the required libraries like numpy, pandas, matplotlib, seaborn, scikit-learn and TensorFlow.
Python `
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score import tensorflow_hub as hub
`
Step 2: Load the Dataset
We will load the dataset.
The used dataset can be downloaded from here.
Python `
df = pd.read_csv("/content/spam.csv", encoding='latin-1') df.head()
`
**Output:
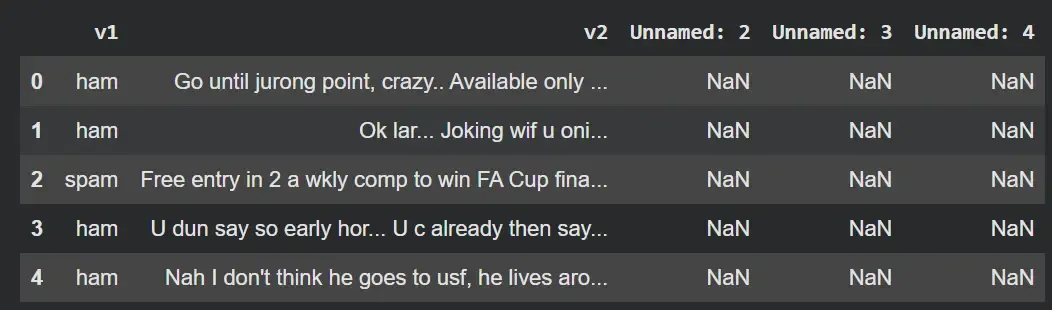
Result
Step 3: Clean the dataset and encode labels
We will clean the dataset:
- Drops unused columns that contain only null or irrelevant values.
- Renames columns to more meaningful names i.e label (target) and Text (message).
- Encodes text labels into numeric form i.e ham is 0 and spam is 1.
- Shows the cleaned DataFrame with the new encoded label column. Python `
df = df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1) df = df.rename(columns={'v1': 'label', 'v2': 'Text'}) df['label_enc'] = df['label'].map({'ham': 0, 'spam': 1}) df.head()
`
**Output:
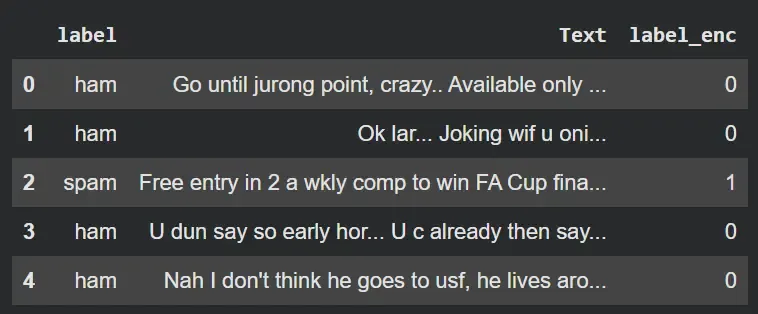
Result
Step 4: Split Data and convert to NumPy arrays
Here,
- Splits the dataset into training (80%) and testing (20%) sets.
- Uses a fixed random_state for reproducibility.
- Converts pandas Series to NumPy arrays. Python `
X_train, X_test, y_train, y_test = train_test_split( df['Text'], df['label_enc'], test_size=0.2, random_state=42 )
X_train_np = X_train.to_numpy() X_test_np = X_test.to_numpy() y_train_np = y_train.to_numpy() y_test_np = y_test.to_numpy()
`
Step 5: Compute text Statistics for Vectorization
- Computes the average number of words per SMS, used as sequence length for padding.
- Estimates vocabulary size by counting unique tokens across all messages.
- Prints basic dataset statistics for reference. Python `
avg_words_len = round(sum([len(i.split()) for i in df['Text']]) / len(df['Text'])) total_words_length = len(set(" ".join(df['Text']).split()))
print(f"Data Loaded. Training samples: {len(X_train_np)}") print(f"Average words per message: {avg_words_len}") print(f"Approximate vocabulary size: {total_words_length}")
`
**Output:

Result
Step 6: Helper functions for training and evaluation
- compile_and_fit centralizes the compile + train logic for all models.
- Uses binary_crossentropy and accuracy for binary classification.
- Trains on training data and validates on the test data, returning training history.
- get_metrics predicts labels, rounds probabilities to 0 or 1 and computes accuracy, precision, recall and F1-score. Python `
def compile_and_fit(model, epochs=5): model.compile( optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'] ) history = model.fit( X_train_np, y_train_np, epochs=epochs, validation_data=(X_test_np, y_test_np) ) return history
def get_metrics(model, X, y): y_preds = np.round(model.predict(X)) return { 'accuracy': accuracy_score(y, y_preds), 'precision': precision_score(y, y_preds), 'recall': recall_score(y, y_preds), 'f1-score': f1_score(y, y_preds) }
`
Step 7: Create the TextVectorization layer
- Creates a TextVectorization layer to convert raw text into integer sequences.
- Limits the vocabulary size to total_words_length unique words.
- Standardizes text by lowercasing and stripping punctuation.
- Pads or truncates each sequence to avg_words_len tokens.
- Adapts the layer on training data to learn the vocabulary distribution. Python `
from tensorflow.keras.layers import TextVectorization text_vec = TextVectorization( max_tokens=total_words_length, standardize='lower_and_strip_punctuation', output_mode='int', output_sequence_length=avg_words_len ) text_vec.adapt(X_train_np)
`
Step 8: Model 1 – Dense embedding model (build and train)
- Defines an input layer that expects string tensors.
- Applies the TextVectorization layer to convert text into token IDs.
- Uses an Embedding layer to learn dense vector representations for each word.
- Applies GlobalAveragePooling1D to compress each sequence into a single vector.
- Adds a dense hidden layer with ReLU activation for non-linearity.
- Outputs a single sigmoid unit for binary spam/ham prediction.
- Compiles and trains the model using the shared compile_and_fit function. Python `
input_layer = layers.Input(shape=(1,), dtype=tf.string) x = text_vec(input_layer) x = layers.Embedding(input_dim=total_words_length, output_dim=128)(x) x = layers.GlobalAveragePooling1D()(x) x = layers.Dense(32, activation='relu')(x) output_layer = layers.Dense(1, activation='sigmoid')(x)
model_1 = keras.Model(input_layer, output_layer, name="Dense_Model") history_1 = compile_and_fit(model_1)
`
**Output:
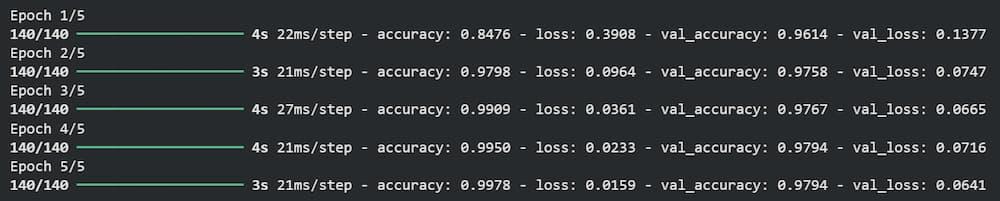
Result
Step 9: Model 2 – Bidirectional LSTM model (build and train)
- Uses the same input and text vectorization setup as Model 1.
- Adds an embedding layer to convert token IDs into dense vectors.
- Stacks two Bidirectional LSTM layers to capture context from both past and future tokens.
- Flattens the final sequence output before feeding into dense layers.
- Adds dropout to reduce overfitting.
- Uses a dense hidden layer with ReLU and a sigmoid output layer for classification.
- Compiles and trains this Bi-LSTM model with the helper function. Python `
input_layer = layers.Input(shape=(1,), dtype=tf.string) x = text_vec(input_layer) x = layers.Embedding(input_dim=total_words_length, output_dim=128)(x) x = layers.Bidirectional(layers.LSTM(64, return_sequences=True))(x) x = layers.Bidirectional(layers.LSTM(64))(x) x = layers.Flatten()(x) x = layers.Dropout(0.1)(x) x = layers.Dense(32, activation='relu')(x) output_layer = layers.Dense(1, activation='sigmoid')(x)
model_2 = keras.Model(input_layer, output_layer, name="BiLSTM_Model") history_2 = compile_and_fit(model_2)
`
**Output:

Result
Step 10: Model 3 – Transfer learning with Universal Sentence Encoder (build and train)
- Loads the pre-trained Universal Sentence Encoder from TensorFlow Hub.
- Freezes the USE layer (trainable=False) to use it purely as a feature extractor.
- Defines an input layer with scalar string input (shape=[]) as expected by USE.
- Uses a Lambda layer to call USE and produce a fixed 512-dimensional sentence embedding.
- Adds a dense hidden layer with 64 units and ReLU activation.
- Uses dropout for regularization.
- Outputs a single sigmoid unit for spam vs ham prediction.
- Compiles and trains the USE-based transfer learning model with the same pipeline. Python `
use_layer = hub.KerasLayer( "https://tfhub.dev/google/universal-sentence-encoder/4", trainable=False, input_shape=[], dtype=tf.string, name='USE' ) input_layer = layers.Input(shape=[], dtype=tf.string) embedding = layers.Lambda(lambda x: use_layer( x), output_shape=(512,))(input_layer) x = layers.Dense(64, activation='relu')(embedding) x = layers.Dropout(0.2)(x) output_layer = layers.Dense(1, activation='sigmoid')(x) model_3 = keras.Model(input_layer, output_layer, name="USE_Model") history_3 = compile_and_fit(model_3)
`
**Output:
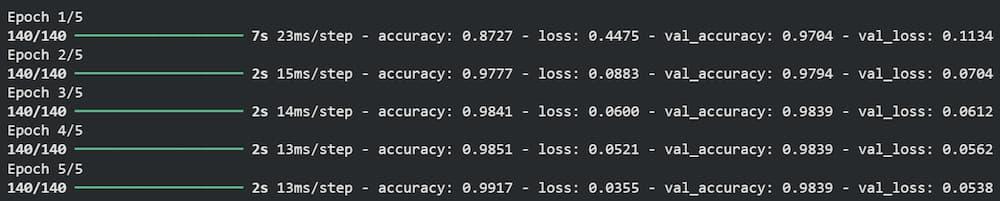
Result
Step 11: Collect performance metrics for all models
- Evaluates each model on the same test set using the get_metrics helper.
- Builds a DataFrame summarizing accuracy, precision, recall and F1-score for all models.
- Prints a performance table for quick numeric comparison. Python `
results = { 'Dense Embedding': get_metrics(model_1, X_test_np, y_test_np), 'Bi-LSTM': get_metrics(model_2, X_test_np, y_test_np), 'Transfer Learning (USE)': get_metrics(model_3, X_test_np, y_test_np) }
results_df = pd.DataFrame(results).transpose() print("Performance Table:") print(results_df)
`
**Output:
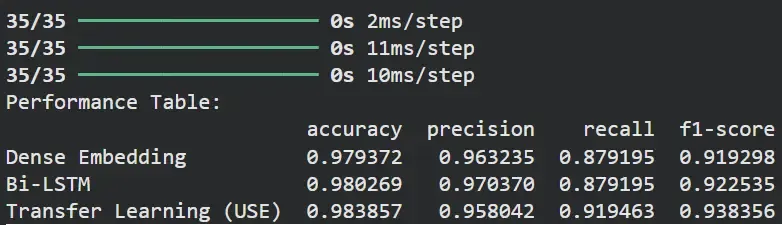
Result
The table compares the performance of all three models on the same dataset:
- Transfer Learning (USE) gives the highest overall score, especially in recall and F1-score, showing it captures patterns more effectively.
- Bi-LSTM also performs slightly better than Dense Embedding because it understands sequence information.
Step 12: Visualize
We will visualize the results,
**a. Bar Chart
Python `
results_df.plot(kind='bar', figsize=(10, 6)) plt.title("Model Performance Metrics (Bar Chart)") plt.ylabel("Score") plt.ylim(0.8, 1.0) plt.xticks(rotation=0) plt.legend(loc='lower right') plt.grid(axis='y', linestyle='--', alpha=0.7) plt.show()
`
**Output:
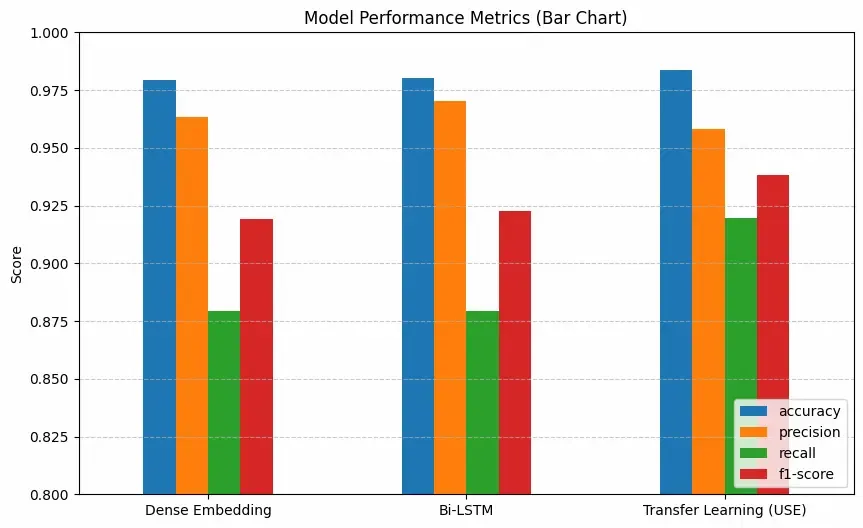
Result
**b. Line Graph
Python `
plt.figure(figsize=(10, 6))
for model_name in results_df.index: plt.plot( results_df.columns, results_df.loc[model_name], marker='o', label=model_name, linewidth=2 ) plt.title("Model Performance Trends (Line Graph)") plt.ylabel("Score") plt.xlabel("Metric") plt.ylim(0.8, 1.0) plt.grid(True, linestyle='--', alpha=0.6) plt.legend() plt.show()
`
**Output:
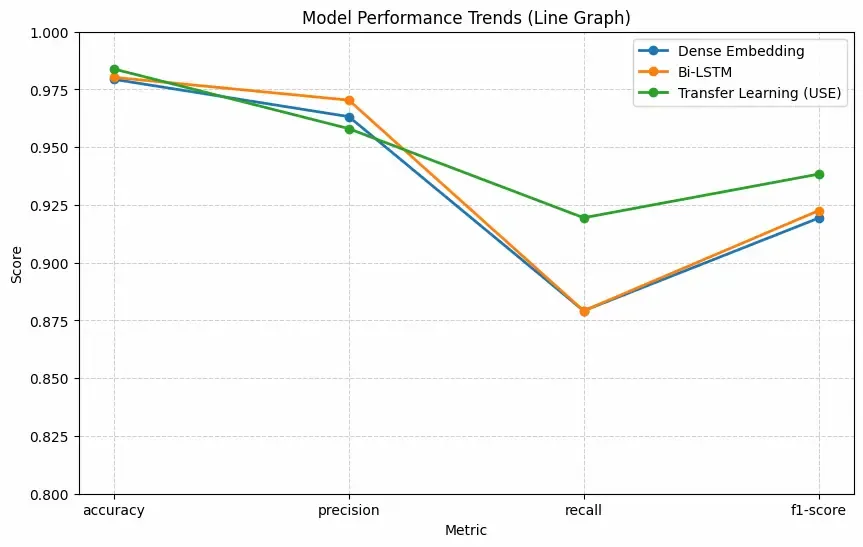
Result
You can download source code from here.