What is ViLT (VisionandLanguage Transformer) (original) (raw)
What is ViLT (Vision-and-Language Transformer)
Last Updated : 23 Aug, 2025
ViLT is a deep learning model that understands both images and text together using a single transformer. Unlike other models that need complex vision systems like CNNs, ViLT works by breaking images into patches and combining them with text tokens. It then processes everything using just one transformer, making it simpler, faster and more efficient for tasks like image captioning, visual question answering and image text matching.
Key Features
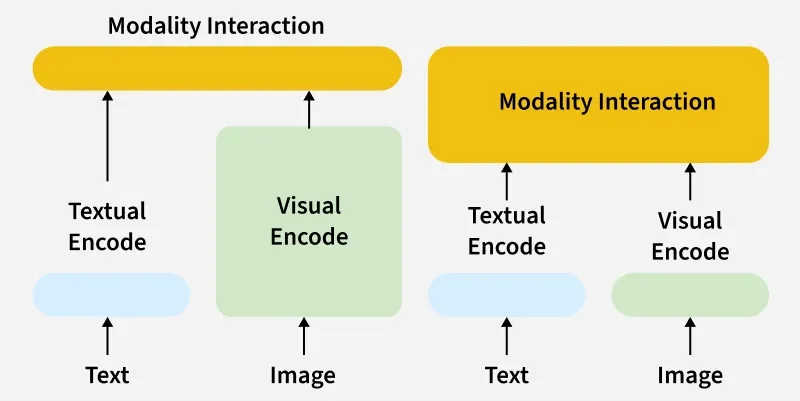
- **Unified Transformer Architecture: ViLT uses a single transformer to process both images and text together, unlike traditional models that use separate modules for vision and language. This makes the architecture simpler and more efficient.
- **No Visual Backbone: It doesn't need a pre trained CNN or object detector to extract image features. Instead it directly takes image patches as input, reducing complexity and computation time.
- **Fast and Lightweight: It skips the heavy visual encoder, ViLT is faster than other multi modal models at training and inference while still achieving competitive accuracy.
- **Cross Modal Learning from the Start: It allows early fusion of image and text by mixing them at input level. This lets the model learn interactions between visual and textual elements throughout all transformer layers.
- **Strong Performance on Vision Language Tasks: ViLT performs well on tasks like Visual Question Answering (VQA), Image Text Retrieval and Visual Reasoning showing that its minimalist design doesn’t compromise performance.
Architecture
Lets see architecture of ViLT (Vision-and-Language Transformer):
ViLT
1. Image Patch Embedding
- The input image is resized and split into non overlapping fixed size patches.
- Each patch is flattened and projected linearly into a vector like a word embedding.
- This forms a sequence of image embeddings analogous to word tokens in NLP.
2. Text Embedding
- The text like caption, question or description is tokenized using a BERT tokenizer.
- Each token is converted into an embedding using a standard embedding layer.
3. Modality Type Embedding
- To tell the model whether a token came from text or image a modality embedding is added to each token.
- **For Example: modality = 0 for text, modality = 1 for image patch.
4. Positional Embedding
- Transformers don’t understand the order of tokens on their own so positional embeddings are added to each image patch and text token to preserve their position in the sequence.
- This helps the model understand the spatial layout of images and the word order in sentences which is useful for tasks that rely on structure and context.
5. [CLS] Token
- A special [CLS] token is prepended to the combined sequence of image and text tokens.
- Its final output representation is used for classification tasks such as image text matching or VQA.
6. Single Transformer Encoder
- The combined sequence of text tokens, image patches and [CLS] token is passed through a single stack of transformer layers.
- This allows cross modal interactions to happen within each layer unlike two stream models.
7. Task Specific Head
- A classification head or similarity score layer is placed on top of the [CLS] token.
- This final layer varies depending on the downstream task.
Implementation
Step 1: Install Necessary Libraries
Import ViltProcessor and ViltForQuestionAnswering from Hugging Face Transformers, PyTorch and Python Imaging Library (PIL) to handle model loading, tensor operations and image processing respectively.
Python `
pip install transformers torch torchvision from transformers import ViltProcessor, ViltForQuestionAnswering import torch from PIL import Image
`
Step 2: Load the Processor and Model
Use ViltProcessor.from_pretrained and ViltForQuestionAnswering.from_pretrained to load the pretrained ViLT processor and the model fine tuned on the Visual Question Answering (VQA) task.
Python `
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa") model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
`
Step 3: Load Image and Prepare Example Text
Open your input image file using PIL’s Image.open. This prepares the image for processing by the model. Create a text string containing the question you want the model to answer about the image and pass the image and text to the processor which tokenizes the text and converts the image into patches returning PyTorch tensors ready for the model.

Image Used
Step 4: Forward Pass
Feed the processed inputs into the model to get raw output logits representing scores for possible answers.
Python `
outputs = model(**inputs) logits = outputs.logits
`
Step 5: Predictions
Find the index of the highest scoring answer from logits using argmax then map it to the corresponding text label from the model’s vocabulary. Output the predicted answer string to the console.
Python `
predicted_answer_id = logits.argmax(-1).item() answer = model.config.id2label[predicted_answer_id]
print("Answer:", answer)
`
**Output:
Answer: elephant
You can download the source code from - here.
Advantages
- **Simplified Architecture: ViLT combines image and text processing into a single transformer model eliminating the need for complex visual feature extractors like CNNs or Faster R CNN. This makes the model easier to train and deploy.
- **Faster Training and Inference: By directly using image patches instead of precomputed region features ViLT achieves faster training and inference speeds compared to traditional vision and language models.
- **End to End Learning: It can be trained end to end allowing the model to learn joint representations of images and text simultaneously which improves overall performance and adaptability to different tasks.
- **Various use case: Despite its simpler design ViLT delivers strong results on various vision and language benchmarks like Visual Question Answering (VQA), Image Text Retrieval and Visual Reasoning.
Disadvantages
- **Less Detailed Visual Understanding: Since it uses raw image patches without sophisticated CNN based feature extraction it can struggle with fine grained spatial details and object level reasoning compared to models that use region based detectors.
- **Requires Large Scale Training Data: ViLT’s end to end training approach demands massive amounts of paired image text data and computational resources to achieve top performance which can be a barrier for some users.
- **Limited Performance on Complex Tasks: For tasks requiring detailed object detection or localization such as detailed image captioning or dense visual reasoning ViLT may underperform relative to models that incorporate explicit object detectors.
- **Patch Based Image Representation Limits Resolution: Dividing images into fixed size patches means spatial resolution is limited by patch size which can cause loss of subtle visual cues critical for some applications.