Apache Spark (original) (raw)
Last Updated : 27 Feb, 2026
Apache Spark is an open-source distributed computing framework built for large-scale data processing and analytics.
It processes massive datasets across clusters of machines with high speed and reliability.
- It is designed for large-scale distributed data processing.
- Handles massive datasets (terabytes to petabytes).
- Uses in-memory computation for high performance.
- Provides fault tolerance and horizontal scalability.
Core Architecture
Spark uses a **master-worker (driver-executor) model, with modern enhancements like Spark Connect.
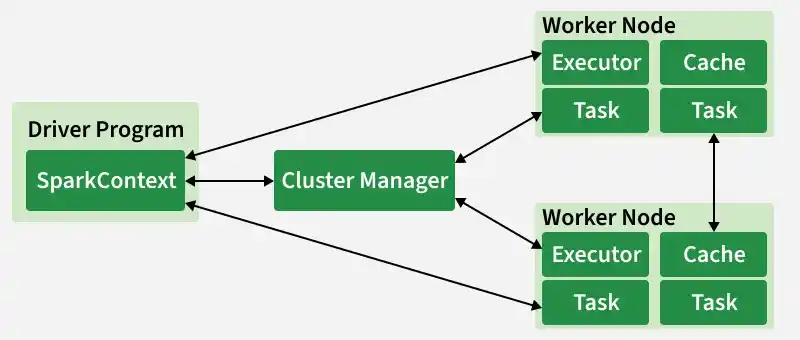
Architecture Of Apache Spark
- **Driver Program — The "brain": Runs the main() function, creates SparkSession/SparkContext, translates code into a logical plan, optimizes it (via Catalyst), creates a physical plan, and coordinates execution.
- **Cluster Manager — Allocates resources (YARN, Kubernetes, Mesos, standalone, or cloud-native like Databricks/EMR).
- **Executors — Worker processes on cluster nodes. Each runs tasks, stores data in memory/disk, and reports back to the driver.
- **SparkSession — Unified entry point (replaces older SparkContext + SQLContext).
- **Spark Connect (major in 4.x) — Decouples client from cluster: Thin client (Python/Scala/Go/R) talks to server-side Spark via gRPC. Enables remote development, better security, and consistency between local and cluster execution.
Key abstractions:
- **Resilient Distributed Datasets (RDDs) — Low-level, immutable, partitioned collections with lineage for fault recovery (still foundational but less used directly now).
- **DataFrames / Datasets — Higher-level, structured (with schema), optimized via Catalyst optimizer and Tungsten execution engine (columnar, codegen).
- **Directed Acyclic Graph (DAG) — Execution plan: Spark builds a DAG of stages (shuffle boundaries separate them).
Built-in libraries (unified engine):
- **Spark SQL — Structured data, ANSI SQL, DataFrames.
- **Spark Streaming / Structured Streaming — Real-time (micro-batch or continuous/real-time mode in 4.x for ms latency).
- **MLlib — Scalable machine learning.
- **GraphX — Graph computation
Working of Apche Spark
1. Application Submission & Driver Initialization
A Spark application begins when the user submits code written in PySpark, Scala, Java, or SQL. This code creates a SparkSession, which internally initializes the SparkContext.
The Driver Program is the central coordinator of the application and runs the user’s main function. It is responsible for:
- Creating the SparkContext
- Converting user code into execution plans
- Coordinating execution across the cluster
- Collecting or persisting final results
The Driver contains critical internal components:
- DAG Scheduler
- Task Scheduler
- Backend Scheduler
- Block Manager
Together, the Driver and SparkContext oversee the entire job execution lifecycle.
2. Logical Plan Creation (Lazy Evaluation)
Spark follows a lazy evaluation model. When transformations such as filter, map, or groupBy are defined, Spark does not execute them immediately.
Instead:
- User code is converted into an unresolved logical plan.
- Spark records what needs to be done, not how to do it yet.
Execution only begins when an action (e.g., show(), count(), write()) is called.
3. Query Optimization Using Catalyst Optimizer
Once an action is triggered, Spark hands the logical plan to the Catalyst Optimizer, which performs multiple optimization steps:
- **Analysis – Resolves column names, data types, and references.
- **Logical Optimization – Applies rule-based optimizations (predicate pushdown, projection pruning).
- **Cost-Based Optimization (CBO) – Chooses optimal join strategies using statistics.
- **Physical Planning – Converts optimized logic into executable physical operators.
Spark may also apply whole-stage code generation and columnar execution to further improve performance.
4. DAG Creation and Stage Breakdown
The optimized physical plan is translated into a Directed Acyclic Graph (DAG) of operations.
The DAG Scheduler:
- Breaks the DAG into stages
- Identifies shuffle boundaries (e.g., joins, aggregations)
- Determines task dependencies
Each stage consists of multiple tasks that can be executed in parallel.
5. Cluster Manager & Resource Allocation
The Cluster Manager (Standalone, YARN, Kubernetes, or Mesos) is responsible for:
- Allocating CPU cores and memory
- Launching executor processes on worker nodes
The Spark Driver communicates with the Cluster Manager to request resources and schedule work.
6. Task Scheduling & Execution
The Task Scheduler assigns tasks to executors, which are long-lived processes running on worker nodes.
Executors:
- Execute tasks in parallel
- Cache data in memory or disk
- Perform shuffles when required
- Communicate with other executors during data exchange
7. Data Storage, Caching, and Memory Management
Spark supports in-memory computation, which is key to its performance advantage.
- Data can be cached using cache() or persist().
- Memory is divided into execution memory and storage memory.
- Cached data accelerates iterative workloads such as machine learning and graph processing.
8. Fault Tolerance & Reliability
Spark ensures fault tolerance through:
- **Lineage based recomputation – lost partitions are recomputed automatically.
- **Speculative execution – slow running tasks are re executed on other executors.
- **Task retries – failed tasks are retried without restarting the job.
This approach avoids costly data replication while maintaining reliability.
9. Result Handling & Output
After task execution:
- Results may be returned to the Driver (for actions like collect)
- Or written to external storage (HDFS, S3, databases, data warehouses)
Once execution completes, executors are released and the Spark application terminates
Key Use Cases (Real-World in 2026)
Spark powers critical systems across industries:
- **ETL / Data Pipelines - Ingest, clean, transform, load massive data (bronze → silver → gold layers).
- **Real-Time Analytics & Streaming - Fraud detection (banks flag suspicious transactions in <200 ms), live dashboards, IoT sensor processing.
- **Machine Learning & AI - Train models on petabyte-scale data (recommendations, predictive maintenance).
- **Recommendation Engines - Netflix/Amazon personalize content/products using collaborative filtering.
- **Log & Event Processing - Analyze application logs for monitoring/anomalies.
- **Fraud & Risk Detection - Finance/security combine transaction data with external signals.
- **Healthcare - Real-time patient monitoring, population health analytics.
Companies like Netflix (recommendations + log analytics), Amazon (order fulfillment), banks (fraud), and OTT platforms rely on Spark at massive scale.
End-to-End Production Workflow Example
A typical production ETL + ML pipeline (e.g., customer churn prediction or daily reporting):
- **Sources: Kafka (streaming), S3/ADLS (batch files), databases (JDBC).
- Use Spark Structured Streaming for continuous or Spark batch jobs scheduled via Airflow Workflows.
**2. Processing (Transform)
- Read → clean (handle nulls/duplicates) → enrich (joins with reference data) → aggregate/window functions → feature engineering.
- Use Delta Lake for ACID transactions, time travel, schema evolution.
- Optimize: Partitioning, Z-ordering, caching, broadcast joins.
- Example: PySpark code with Spark Connect enabled for remote cluster.
**3. Storage (Load)
- Write to Delta Lake.
- Formats: Parquet/Delta for efficiency.
**4. Orchestration & Scheduling
- Airflow/Databricks Jobs → trigger daily/hourly.
- Use dynamic allocation, spot instances for cost savings.
**5. Monitoring & Governance
- Spark UI or Prometheus for metrics.
- Delta Lake for auditing.
- Unity Catalog (Databricks) or open equivalents for governance.
**6. Consumption
Serve gold tables to BI (Power BI/Tableau), ML models (MLflow), or downstream apps via APIs.