Google File System (original) (raw)
Last Updated : 13 Mar, 2026
The Google File System (GFS) is a scalable, fault tolerant distributed file system developed by Google. It is designed to store and process massive datasets for applications like web search and data analytics. GFS prioritizes reliability and scalability over specialized hardware by using software based fault tolerance.
- Built to handle large-scale data storage and processing efficiently
- Runs on low cost commodity servers instead of specialized hardware
- Manages frequent hardware failures using replication and software-level fault tolerance
Architecture of the Google File System (GFS)
The architecture of the Google File System (GFS) is designed to support massive scale data storage across thousands of commodity machines while maintaining high availability and fault tolerance. GFS follows a master worker model with centralized metadata management and distributed data storage.
At its core, GFS separates:
- Metadata management (control plane)
- Data storage and transfer (data plane)
This separation allows GFS to scale efficiently while minimizing bottlenecks.
A GFS cluster consists of three primary components, GFS Master, GFS Chunk Servers and GFS Clients. All components run on commodity Linux machines connected through a high-speed network.
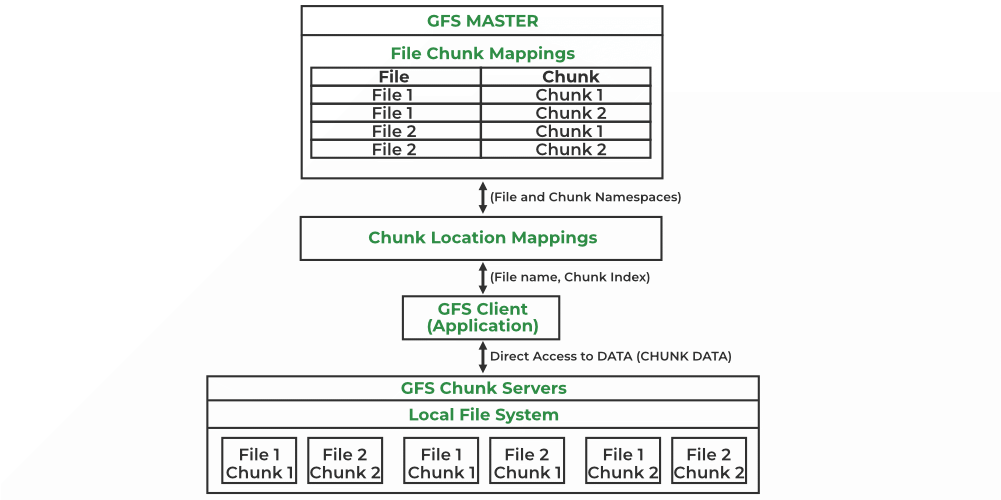
1. Master Server Architecture
The GFS Master is the central coordinator of the file system. There is typically one active master per cluster.
Responsibilities of the Master
The master manages all metadata, including:
- File namespace (directory structure).
- Access control information.
- Mapping of files to chunks.
- Chunk to replica locations.
- Chunk version numbers.
- Lease management for write coordination.
- Garbage collection of unused chunks.
To achieve high performance:
- Metadata is stored in memory for fast access.
- Changes are persisted in an operation log.
- The operation log is replicated to remote machines for durability.
- Periodic checkpoints reduce recovery time.
This design ensures:
- Fast metadata lookups
- Quick recovery after crashes
- Strong consistency for metadata operations
Master Communication
The master communicates with chunk servers using:
- Heartbeat messages (periodic status checks)
- Instructions for replication or rebalancing
- Lease grants for write operations
The master does not handle actual file data, preventing it from becoming a throughput bottleneck.
2. Chunk Servers Architecture
Chunk servers are the data storage nodes in GFS.
Storage Model
- Files are divided into fixed-size 64 MB chunks.
- Each chunk has a globally unique identifier (chunk handle).
- Chunks are stored as **Linux files on local disks.
Replication Strategy
Each chunk is replicated (default: **3 replicas):
- Stored on different chunk servers
- Often placed on different racks for fault tolerance
- Managed by the master
If a replica is lost due to server failure, the master automatically schedules re-replication.
Data Integrity
Chunk servers maintain:
- Checksums for each chunk block
- Validation during read operations
- Automatic corruption detection and reporting
If corruption is detected:
- The chunk server informs the master
- A healthy replica is used to restore the data
3. Client Architecture
Clients are applications or processes that interact with GFS.
Client Interaction Flow
Clients communicate:
- With the master for metadata
- Directly with chunk servers for data transfer
This design reduces load on the master and increases throughput.
Clients cache metadata to:
- Minimize repeated master requests
- Improve performance
Fault Tolerance Mechanisms
GFS assumes failures are common and handles them automatically.
1. Master Failure
- Metadata logs allow recovery.
- Shadow masters may exist for read-only access.
- The system can restart the master using persisted logs.
2. Chunk Server Failure
- Detected via missed heartbeats.
- Lost replicas are recreated.
- Client requests are redirected to healthy replicas.
3. Data Corruption
- Detected using checksums.
- Corrupted chunks are replaced automatically.
Namespace and Locking
The master manages:
- Hierarchical directories, File creation and deletion and Namespace locking.
Locks are:
- Fine grained.
- Designed to support high concurrency.
Scalability Characteristics
GFS scales by:
- Adding more chunk servers
- Distributing chunks across nodes
- Leveraging large chunk size (64 MB)
Large chunk size reduces:
- Metadata size
- Network overhead
- Frequency of master interaction
Clusters may include:
- 1,000+ nodes
- Hundreds of terabytes of storage
- Hundreds of concurrent clients
Why 64 MB Chunk Size?
The large chunk size:
- Reduces metadata overhead
- Allows efficient sequential reads
- Minimizes client-master communication
- Improves throughput for large workloads
However, this makes GFS less suitable for small files.
Rack Awareness and Network Efficiency
GFS considers network topology:
- Replicas are distributed across racks
- Cross-rack traffic is minimized
- Failure of an entire rack does not cause data loss
This improves both reliability and bandwidth efficiency.
Architectural Limitations
Despite its strengths:
- Single master may become a scalability constraint
- Not optimized for small files
- Poor support for random writes
- for data transfer
This design reduces load on the master and increases throughput.
Clients cache metadata to:
- Minimize repeated master requests
- Improve performance
Data Flow in GFS
1. Read Operation
- Client sends file request to master.
- Master responds with Chunk handle and Locations of chunk replicas.
- Client selects the closest chunk server.
- Client reads data directly from the chunk server.
The master is not involved in the actual data transfer.
2. Write Operation
Write operations use a primary-replica model:
- Client asks master for chunk metadata.
- Master designates one replica as the primary.
- Client pushes data to all replicas.
- Primary replica determines write order and coordinates with secondary replicas
- All replicas apply the write.
- Client receives acknowledgment.
This ensures:
- Consistency across replicas
- Ordered mutation application
Lease Mechanism for Consistency
To coordinate writes:
- The master grants a lease to one replica (primary).
- The lease is time bound.
- Only the primary decides the mutation order.
This prevents conflicting writes and ensures consistency across replicas.
Key Features of Google File System
- Centralized namespace management.
- Efficient locking mechanisms.
- Automatic data replication.
- High availability and reliability.
- Fault-tolerant design.
- Automatic data recovery.
- Optimized for append-heavy workloads.