Trie Data Structure Commonly Asked Questions (original) (raw)
Last Updated : 1 Sep, 2025
The trie data structure, also known as a prefix tree, is a tree-like data structure used for efficient retrieval of key-value pairs. It is commonly used for implementing dictionaries and autocomplete features, making it a fundamental component in many search algorithms.
What are the Properties of a Trie Data Structure?
Below are some important properties of the Trie data structure:
- Each Trie has an empty root node, with links (or references) to other nodes
- Each node of a Trie represents a string and each edge represents a character.
- Every node consists of a hashmapor an array of pointers, with each index representing a character and a flag to indicate if any string ends at the current node.
- Each path from the root to any node represents a word or string.
Below is a simple example of Trie data structure.
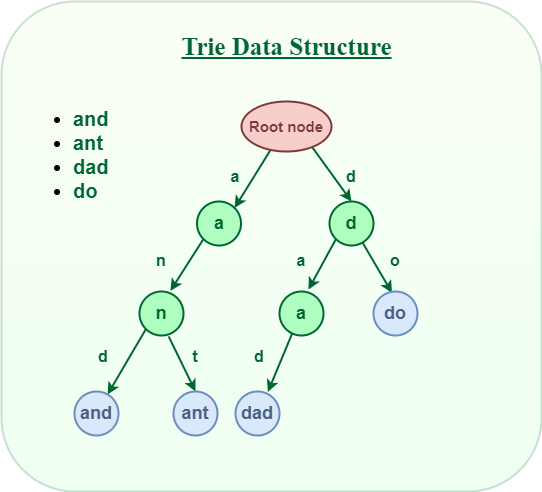
Trie Data Structure
Compare Trie and Hash Table
A **Trie data structure is used for **storing and **retrieval of data and the same operations could be done using another data structure which is **Hash Table but Trie data structure can perform these operations more efficiently. Moreover, a Trie data structure can be used for **prefix-based searching and a sorted traversal of all words. So a Trie has advantages of both hash table and self balancing binary search trees.
- We can efficiently do **prefix search (or auto-complete) with Trie.
- We can easily print all words in alphabetical order which is not easily possible with hashing.
- There is no overhead of Hash functions in a Trie data structure.
- Searching for a String even in the large collection of strings in a Trie data structure can be done in **O(L) where L is input key length. Time complexity,
- The main issue with Trie is extra memory space required to store words and the space may become huge for long list of words and/or for long words.
How does Trie Data Structure work?
**Trie data structure can contain any number of characters including **alphabets, **numbers, and **special characters. But for this article, we will discuss strings with characters **a-z. Therefore, only 26 pointers need for every node, where the 0th index represents 'a' and the **25th index represents 'z' characters.
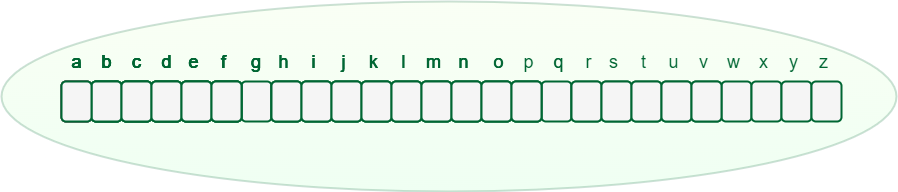
An array of pointers inside every Trie node
Let's see how a word "**and" and "**ant" is stored in the Trie data structure:
After storing the word "and" and "ant" the Trie will look like this:
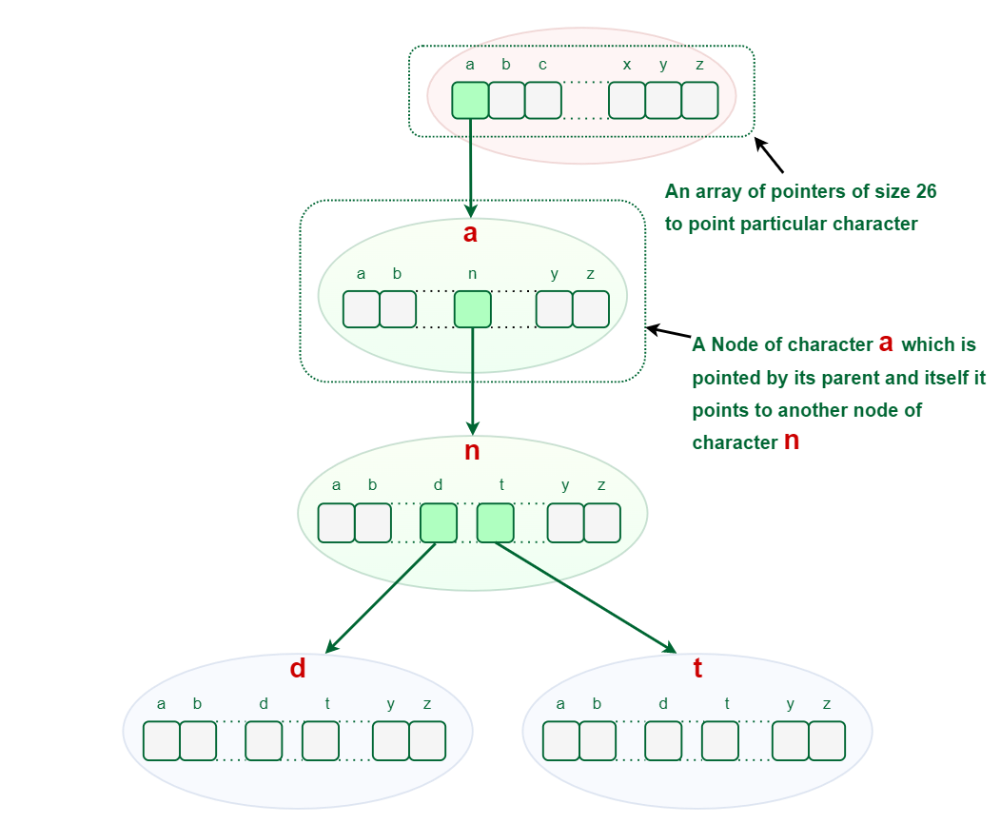
Explain Search, Insertion, and Prefix Search Operations in Trie
Please refer Trie Data Structure article for details.
Explain Deletion Operation on Trie
This operation is used to delete strings from the Trie data structure. There are three cases when deleting a word from Trie.
- The deleted word is a prefix of other words in Trie.
- The deleted word shares a common prefix with other words in Trie.
- The deleted word does not share any common prefix with other words in Trie.
**3.1 The deleted word is a prefix of other words in Trie.
As shown in the following figure, the deleted word "**an" share a complete prefix with another word "**and" and "**ant".
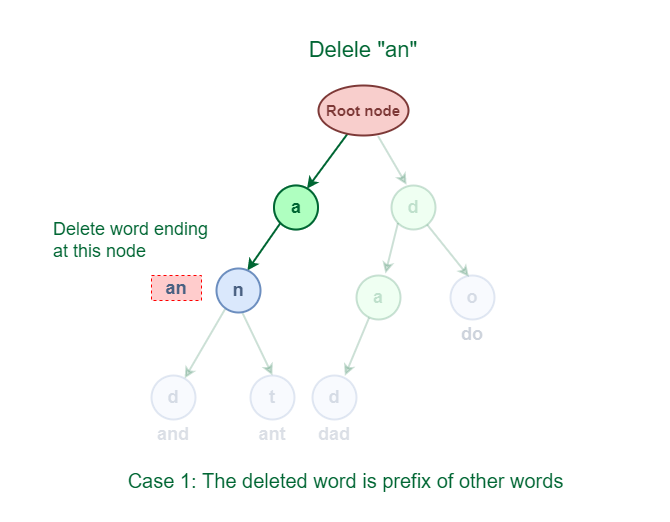
Deletion of word which is a prefix of other words in Trie
An easy solution to perform a delete operation for this case is to just decrement the **wordCount by 1at the ending node of the word.
**3.2 The deleted word shares a common prefix with other words in Trie.
As shown in the following figure, the deleted word "and" has some common prefixes with other words ‘ant’. They share the prefix ‘**an’.
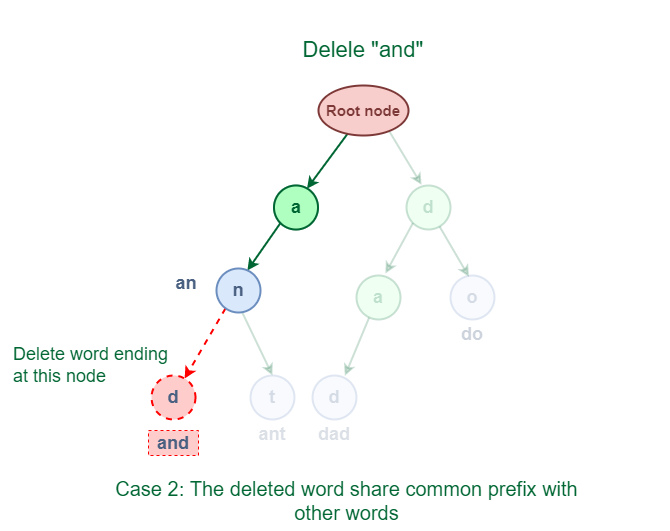
Deletion of word which shares a common prefix with other words in Trie
The solution for this case is to delete all the nodes starting from the end of the prefix to the last character of the given word.
As shown in the following figure, the word "**geek" does not share any common prefix with any other words.
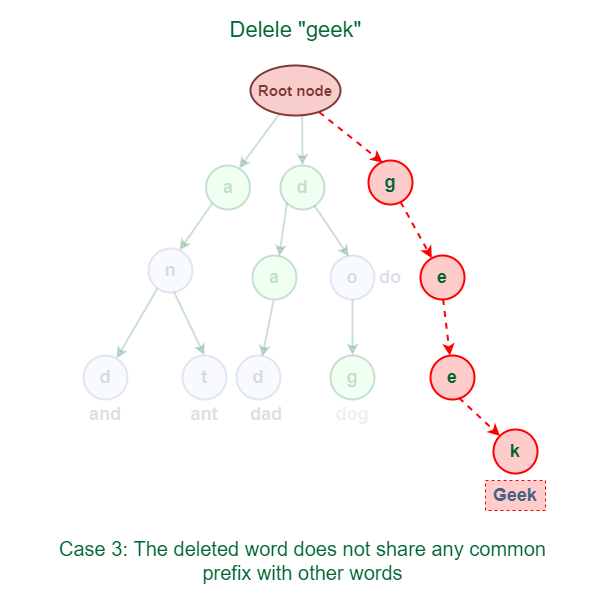
The solution for this case is just to delete all the nodes.
Please refer Trie Delete Operation for implementation details.
What are the time complexities of different operations?
| Operation | Time Complexity |
|---|---|
| Insertion | O(n) Here n is the length of string to be searched |
| Searching | O(n) |
| Deletion | O(n) |
**Note: In the above complexity table '**n', '**m' represents the size of the string and the number of strings that are stored in the trie.
What are the applications of Trie data structure:
**1. Autocomplete Feature: Autocomplete provides suggestions based on what you type in the search box. Trie data structure is used to implement autocomplete functionality.
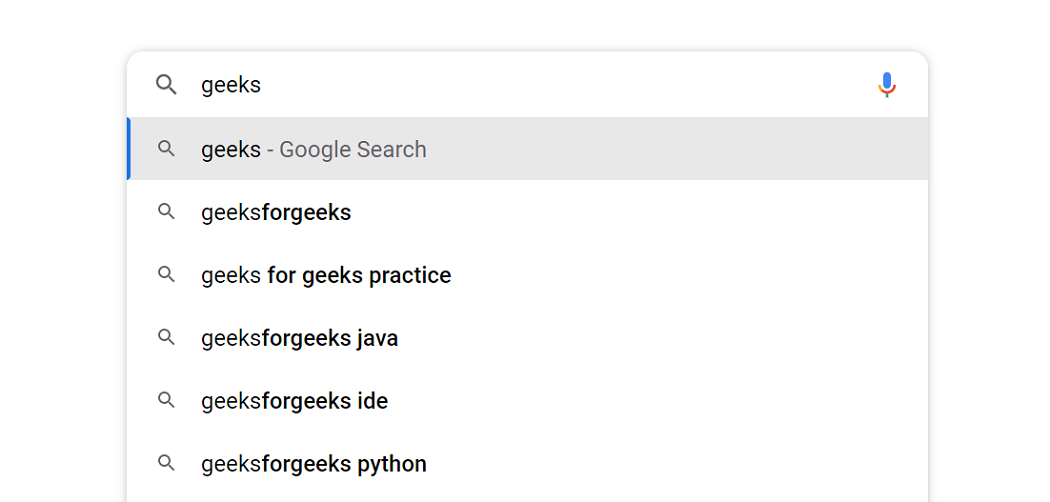
Autocomplete feature of Trie Data Structure
**2. Spell Checkers: If the word typed does not appear in the dictionary, then it shows suggestions based on what you typed.
**It is a 3-step process that includes :
- Checking for the word in the data dictionary.
- Generating potential suggestions.
- Sorting the suggestions with higher priority on top.
Trie stores the data dictionary and makes it easier to build an algorithm for searching the word from the dictionary and provides the list of valid words for the suggestion.
**3. Longest Prefix Matching Algorithm(Maximum Prefix Length Match): This algorithm is used in networking by the routing devices in IP networking. Optimization of network routes requires contiguous masking that bound the complexity of lookup a time to O(n), where n is the length of the URL address in bits.
To speed up the lookup process, Multiple Bit trie schemes were developed that perform the lookups of multiple bits faster.
What are the limitations of Trie Data Structure?
- The main disadvantage of the trie is that it takes a lot of memory to store all the strings. For each node, we have too many node pointers which are equal to the no of characters in the worst case.
- An efficiently constructed hash table(i.e. a good hash function and a reasonable load factor) has O(1) as lookup time which is way faster than O(l) in the case of a trie, where l is the length of the string.