Robin Hood Hashing (original) (raw)
Last Updated : 23 Jul, 2025
Hashing is a technique that maps data to a fixed-size table using a hash function. The hash function takes an input (or key) and returns an index in the hash table, where the corresponding value is stored. A hash table uses this index to store the data, making it very efficient for searching and accessing elements. **It is an advanced technique used in hash table implementation that builds upon **open addressing. The key idea is to minimize the variance in the distance between each key and its original "home" slot.
- **Collision Handling in Hashing: When multiple keys hash to the same index, a collision occurs.
- **Linear Probing: Searches for the next available spot but may place keys far from their ideal position, slowing down searches.
When a collision occurs and a new key is inserted, the algorithm shifts existing keys in such a way that the new key only displaces an old key if it ends up closer to its home slot.
**Key Properties of Robin Hood Hashing
- **Amortized Lookup Time: The average time for a lookup operation is O(1), meaning it's very fast. However, in the worst-case scenario (such as when many collisions occur), the lookup time can be O(ln n).
- **Efficient for Missing Keys: It performs well even when searching for keys that don't exist in the hash table, making it fast to detect absent keys.
- **Minimal Variance in Distances: The algorithm minimizes the distance between each key and its original position, which results in a more balanced and efficient hash table.
- **Cache-Friendly and Memory Efficient: Robin Hood Hashing does not require linked lists or extra pointers, making it efficient in terms of memory and cache usage.
- **Good Performance Under High Load: It maintains good performance even when the hash table’s load factor is high (up to about 0.9), meaning it can store a lot of data without a significant drop in efficiency.
Collision Resolution in Robin Hood Hashing
In Robin Hood Hashing, when a collision occurs, the algorithm ensures that keys are placed as close as possible to their ideal position. If a key is inserted farther from its home slot than an existing key, it displaces the current key. This process "robs" the keys that are closer to their ideal positions (the "rich") to give space to the keys that are farther away (the "poor"), minimizing the overall distance and improving the hash table's efficiency.
**Probe Sequence Length (PSL)
In hashing, Probe Sequence Length (PSL****)** refers to the number of steps or "probes" required to find a key in the hash table, especially when collisions occur. While the average time to search a hash table using linear probing is **O(1), the actual number of probes needed can vary significantly depending on how the data is distributed in the table.
Suppose values a.....f hash : **a, e, f hash to 0; b, c to 1; d to 2. Then, inserting values in alphabetical order, a, b, c, d, e, f, produces the hash table:
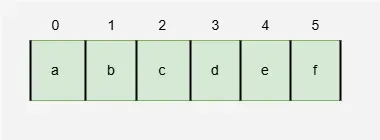
Hash Table
**Finding PSL:
- **a and b → Found directly in their respective buckets, so PSL = 0.
- **c and d → Need one extra step:
- To find c, check bucket 1, then bucket 2 → PSL = 1.
- To find d, check bucket 2 → PSL = 1.
- **f → Takes 5 steps to find → PSL = 5 (likely due to collisions and probing further).
**Time Complexity: The expected time to search may be constant, but the worst-case time is in O(size of the set).
Minimizing PSL in Hash Table
When inserting values into a hash table, we want to keep the farthest distance (PSL) as small as possible. To do this, we first place all values that hash to bucket 0, then all values that hash to bucket 1, then those that hash to bucket 2, and so on. This helps keep the table balanced and prevents any value from being too far from its original bucket. Now, c and d have the largest psl: only 3.
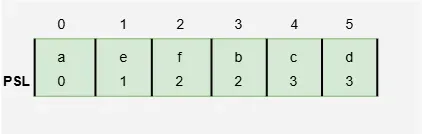
PSL
The table shows that f was hashed to bucket 0 and was found after checking buckets 0, 1, and 2, meaning its probe sequence length is 2. Similarly, d was hashed to bucket 2 and was found after checking buckets 2, 3, 4, and 5, giving it a probe sequence length of 3.
**Note: You might think the probe sequence (0, 1, 2) has length 3, but we say it is 2. Think of this sequence as we do a path (p0, p1, p2) in a graph; the path consists of the two edges from p0 to p1 and from p1 to p2, so the length is 2.
Steps for inserting a problem into the hash table
When inserting a value v into a hash table using linear probing, we follow these steps:
- **Step 1: Start at the bucket where v hashes to.
- **Step 2: If the bucket is already occupied, move to the next bucket.
- **Step 3: Keep checking the next buckets until an empty one (null bucket) is found.
- **Step 4: Once an empty bucket is found, insert v along with its PSL (Probe Sequence Length).
**Loop Invariant (Rule Maintained During the Process):
- Values that hash to bucket i always come before values that hash to bucket i+1.
- We start from the hashed bucket and ensure that vpsl (probe sequence length) successive buckets are occupied.
- The loop continues until we find an empty (null) bucket.
- The first empty bucket (b[p]) found is where we insert v.
To refer to a specific bucket:
- **b[p].v → Value stored in bucket **p.
- **b[p].psl → PSL of the value in bucket **p.
Code Implementation:
Java `
void insert(int v) { int p = hash(v) % b.length; int vpsl = 0; while (b[p] != null) { // TODO: Handle collision (e.g., Robin Hood hashing) p = (p + 1) % b.length; vpsl++; }
b[p].v = v;
b[p].psl = vpsl;}
`
Example illustration for Robin Hood Hashing
Explanation for the above illustration:
- In Robin Hood Hashing, when inserting keys into the hash table, the first key
A, is hashed and placed in its ideal position, with a probe sequence length (PSL) of 0. - As more keys are inserted, like
BandC, collisions occur when they hash to the same position. Instead of simply inserting the key into the next available slot, Robin Hood Hashing compares the PSL of the existing key with that of the new key. - If the new key has a higher PSL, it replaces the existing key to maintain fairness.
- This ensures that no key is too far from its ideal position, as keys with larger PSLs are placed closer to their intended slots.
- As more keys are inserted, the algorithm continues to swap keys based on their PSL values, preventing clustering and ensuring that no key has an unreasonably long probe sequence.
- By the end, Robin Hood Hashing keeps the table balanced, ensuring efficient lookups and minimizing the maximum distance a key needs to travel from its ideal position.