Z algorithm (Linear time pattern searching Algorithm) (original) (raw)
Given two strings **text (the text) and **pattern (the pattern), consisting of lowercase English alphabets, find all 0-based starting indices where the pattern occurs as a substring in the text.
Example:
**Input: text = "aabxaabxaa", pattern = "aab"
**Output: [0, 4]
**Explanation:
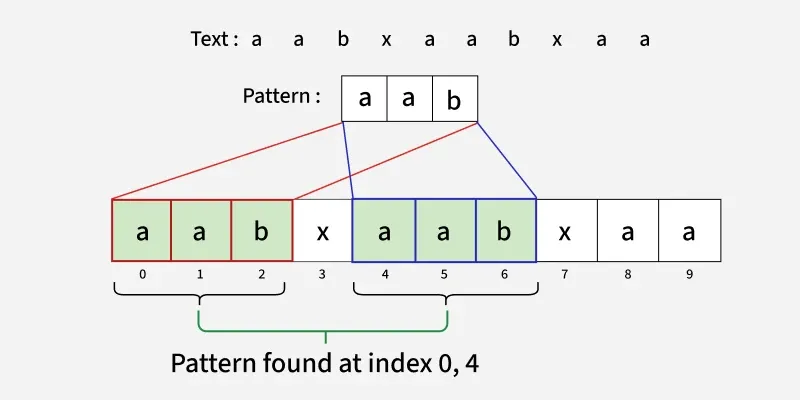
In the Naive String Matching algorithm, we compare the pattern with every substring of the text of the same size one by one, which takes O(n × m) time, where n is the length of the text and m is the length of the pattern. This becomes inefficient for large inputs. The Z Algorithm improves this by preprocessing the string and efficiently matching prefixes, allowing pattern searching in O(n + m) time.
Core Idea
- Create a string that is concatenation of 3 things, pattern, a separator (that should be present in pattern) and text
- Now we consider the above created string and at any point (starting from second index), if we find a substring that is also a prefix and is of same length as pattern, then the pattern is present at that point.
Z-Array to Track Prefix Matches
For a string s of length n, the Z-array stores:
z[i] = length of the longest substring starting from i which is also a prefix of s
**Example:
s = "aabxaab".
The Z-array is: z = [0, 1, 0, 0, 3, 1, 0]
- Z[0] is always defined as 0 because it would represent comparing the entire string with itself, which is trivial and not useful. Hence, by convention, we set: z[0]=0
- Z[1] = 1, Only the first character 'a' matches with the prefix.
- Z[2] = 0, 'b' does not match the first character of the prefix 'a'.
- Z[3] = 0, 'x' does not match the first character of the prefix 'a'.
- Z[4] = 3, The substring "aab" matches the prefix "aab".
- Z[5] = 1, Only 'a' matches with the first character of the prefix.
- Z[6] = 0, 'b' does not match the first character of the prefix 'a'.
Calculation of Z Array
The naive way checks, for each index i, how many characters from s[i...] match the prefix s[0...], which can take O(n²) time. The Z-algorithm improves this and computes all values in O(n) time.
While computing, we maintain a window [l, r] called the Z-box, which stores the rightmost substring that matches the prefix.
- l = start of the match
- r = end of the match
- s[l...r] matches s[0...(r-l)]
This helps reuse previous results instead of comparing again. When processing index i, there are two possibilities:
**If i > r (outside the Z-box): Compare characters from scratch and update [l, r].
**If i ≤ r:
- Let k be the position corresponding to i within the prefix (k = i - l).
- Use the value Z[k] as a reference.
- If Z[k] is **strictly less than the remaining length in [l, r], assign Z[i] = Z[k].
- Otherwise, begin comparing characters beyond the current window to extend the match.
- After extending, update the window [l, r] if a longer match was found.
The key idea is to preprocess a new string formed by combining the pattern and the text, separated by a special delimiter (e.g., $) that doesn’t appear in either string. This avoids accidental overlaps.
We construct a new string as: s = pattern + '$' + text
We then compute the Z-array for this combined string. The Z-array at any position i tells us the length of the longest prefix of the pattern that matches the substring of the text starting at that position (adjusted for offset due to the pattern and separator).
So, whenever we find a position i such that: Z[i] == length of pattern
It means the entire pattern matches the text at a position: match position = i - (pattern length + 1)
C++ `
#include #include using namespace std;
// Z-function to compute Z-array vector zFunction(string &s) { int n = s.length(); vector z(n); int l = 0, r = 0;
for (int i = 1; i < n; i++) {
if (i <= r) {
int k = i - l;
// Case 2: reuse the previously computed value
z[i] = min(r - i + 1, z[k]);
}
// Try to extend the Z-box beyond r
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) {
z[i]++;
}
// Update the [l, r] window if extended
if (i + z[i] - 1 > r) {
l = i;
r = i + z[i] - 1;
}
}
return z;}
// Function to find all occurrences of pattern in text vector search(string &text, string &pattern) { string s = pattern + '$' + text; vector z = zFunction(s); vector pos; int m = pattern.size();
for (int i = m + 1; i < z.size(); i++) {
if (z[i] == m){
// pattern match starts here in text
pos.push_back(i - m - 1);
}
}
return pos;}
int main() { string text = "aabxaabxaa"; string pattern = "aab";
vector<int> matches = search(text, pattern);
for (int pos : matches)
cout << pos << " ";
return 0;}
Java
import java.util.ArrayList; import java.util.Arrays;
public class GfG {
// Z-function to compute Z-array
static ArrayList<Integer> zFunction(String s) {
int n = s.length();
ArrayList<Integer> z = new ArrayList<>();
for (int i = 0; i < n; i++) {
z.add(0);
}
int l = 0, r = 0;
for (int i = 1; i < n; i++) {
if (i <= r) {
int k = i - l;
// Case 2: reuse the previously computed value
z.set(i, Math.min(r - i + 1, z.get(k)));
}
// Try to extend the Z-box beyond r
while (i + z.get(i) < n &&
s.charAt(z.get(i)) == s.charAt(i + z.get(i))) {
z.set(i, z.get(i) + 1);
}
// Update the [l, r] window if extended
if (i + z.get(i) - 1 > r) {
l = i;
r = i + z.get(i) - 1;
}
}
return z;
}
// Function to find all occurrences of pattern in text
static ArrayList<Integer> search(String text, String pattern) {
String s = pattern + '$' + text;
ArrayList<Integer> z = zFunction(s);
ArrayList<Integer> pos = new ArrayList<>();
int m = pattern.length();
for (int i = m + 1; i < z.size(); i++) {
if (z.get(i) == m){
// pattern match starts here in text
pos.add(i - m - 1);
}
}
return pos;
}
public static void main(String[] args) {
String text = "aabxaabxaa";
String pattern = "aab";
ArrayList<Integer> matches = search(text, pattern);
for (int pos : matches)
System.out.print(pos + " ");
}}
Python
def zFunction(s): n = len(s) z = [0] * n l, r = 0, 0
for i in range(1, n):
if i <= r:
k = i - l
# Case 2: reuse the previously computed value
z[i] = min(r - i + 1, z[k])
# Try to extend the Z-box beyond r
while i + z[i] < n and s[z[i]] == s[i + z[i]]:
z[i] += 1
# Update the [l, r] window if extended
if i + z[i] - 1 > r:
l = i
r = i + z[i] - 1
return zdef search(text, pattern): s = pattern + '$' + text z = zFunction(s) pos = [] m = len(pattern)
for i in range(m + 1, len(z)):
if z[i] == m:
# pattern match starts here in text
pos.append(i - m - 1)
return posif name == 'main': text = 'aabxaabxaa' pattern = 'aab'
matches = search(text, pattern)
for pos in matches:
print(pos, end=' ')C#
using System; using System.Collections.Generic;
public class GfG {
// Z-function to compute Z-array
static List<int> zFunction(string s)
{
int n = s.Length;
List<int> z = new List<int>(new int[n]);
int l = 0, r = 0;
for (int i = 1; i < n; i++) {
if (i <= r) {
int k = i - l;
// Case 2: reuse the previously computed
// value
z[i] = Math.Min(r - i + 1, z[k]);
}
// Try to extend the Z-box beyond r
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) {
z[i]++;
}
// Update the [l, r] window if extended
if (i + z[i] - 1 > r) {
l = i;
r = i + z[i] - 1;
}
}
return z;
}
// Function to find all occurrences of pattern in text
static List<int> search(string text, string pattern)
{
string s = pattern + '$' + text;
List<int> z = zFunction(s);
List<int> pos = new List<int>();
int m = pattern.Length;
for (int i = m + 1; i < z.Count; i++) {
if (z[i] == m) {
// pattern match starts here in text
pos.Add(i - m - 1);
}
}
return pos;
}
public static void Main()
{
string text = "aabxaabxaa";
string pattern = "aab";
List<int> matches = search(text, pattern);
foreach(int pos in matches)
Console.Write(pos + " ");
}}
JavaScript
function zFunction(s) { let n = s.length; let z = new Array(n).fill(0); let l = 0, r = 0;
for (let i = 1; i < n; i++) {
if (i <= r) {
let k = i - l;
// Case 2: reuse the previously computed value
z[i] = Math.min(r - i + 1, z[k]);
}
// Try to extend the Z-box beyond r
while (i + z[i] < n && s[z[i]] === s[i + z[i]]) {
z[i]++;
}
// Update the [l, r] window if extended
if (i + z[i] - 1 > r) {
l = i;
r = i + z[i] - 1;
}
}
return z;}
function search(text, pattern) { let s = pattern + '$' + text; let z = zFunction(s); let pos = []; let m = pattern.length;
for (let i = m + 1; i < z.length; i++) {
if (z[i] === m){
// pattern match starts here in text
pos.push(i - m - 1);
}
}
return pos;}
// Driver Code let text = 'aabxaabxaa'; let pattern = 'aab'; let matches = search(text, pattern); console.log(matches.join(" "));
`
**Time Complexity: O(n + m), where n is the length of the text and m is the length of the pattern, since the combined string and Z-array are processed linearly.
**Auxiliary Space: O(n + m), used to store the combined string and the Z-array for efficient pattern matching.
Advantages of Z-Algorithm
- Linear Time Complexity for pattern matching.
- Uses prefix comparison, avoiding re-evaluation of matched characters.
- Easier to code than KMP; works directly with prefix matches.
- Useful for preprocessing in multiple string problems beyond pattern matching.
Real-Life Applications
- Search Tools in Text Editors (e.g., VsCode, Sublime)
- Plagiarism Detection Systems (detect repeated blocks)
- Bioinformatics (finding exact DNA/RNA pattern matches)
- Intrusion Detection Systems (match known threat signatures)
- Compilers (identifying repetitive sequences or keywords)
- Information Retrieval (document or keyword scanning)
- Search Pattern
- Find All Occurrences of Subarray in Array
- Find the Longest Prefix which is also a Suffix
- Minimum Characters to Add at Front for Palindrome
- Strings Rotations of Each Other