Introduction to CUDA Programming (original) (raw)
Last Updated : 2 Mar, 2026
CUDA (Compute Unified Device Architecture) is a parallel computing and programming model developed by NVIDIA, which extends C++ to enable general-purpose computing on GPUs. It allows multiple threads to execute simultaneously, significantly accelerating data-parallel computations compared to sequential CPU execution.
CUDA programs are compiled using the NVIDIA compiler (NVCC), which is designed specifically for NVIDIA GPUs.
Architecture of a CUDA GPU
The power of CUDA lies in its physical hardware organization. While a CPU is composed of a few sophisticated cores, a CUDA-capable GPU is built from an array of Streaming Multiprocessors (SMs).
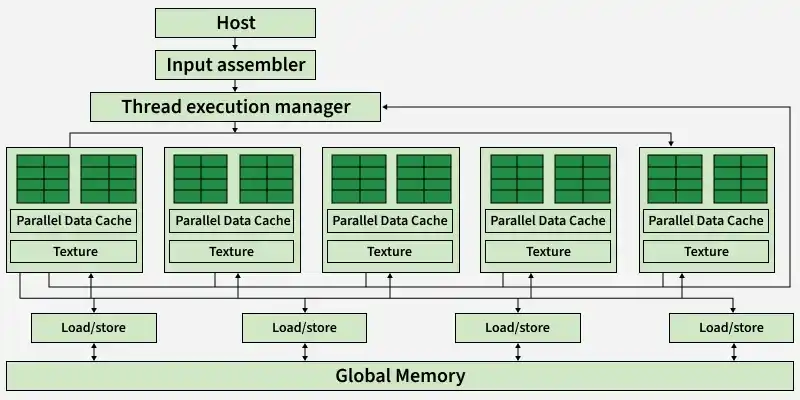
CUDA GPU Hardware Architecture
Above diagram shows how the host (CPU) sends tasks to the GPU, where Thread Execution Manager distributes them across multiple Streaming Multiprocessors (SMs) for parallel execution, with each SM accessing Global Memory as needed.
Key Components of the Hardware Architecture
- **Streaming Multiprocessor (SM): The "brain" of GPU. Each GPU contains multiple SMs (e.g., modern architectures feature 80+ SMs). SM is responsible for managing, scheduling and executing threads in groups.
- **CUDA Cores (Streaming Processors - SP): Each SM contains a set of CUDA Cores. These are the fundamental units that perform the actual integer and floating-point arithmetic (MAD units for Multiplication and Addition).
- **Thread Capacity: Each SM is designed to manage a massive number of threads (often 768 to 2048 depending on the generation). Because each core can handle multiple threads through rapid context switching, hardware is described as massively parallel.
- **Memory Bandwidth: CUDA GPUs feature high-speed onboard memory (VRAM). For example, even older architectures like G80 offered 86.4 GB/s, while modern cards exceed 1000 GB/s, ensuring that thousands of cores are constantly fed with data.
CUDA Work Distribution
CUDA organizes threads into a logical hierarchy that maps directly onto the hardware components mentioned above.
- **Thread: The smallest unit of execution. Every thread executes the same code (Kernel).
- **Block: A group of threads. All threads within a single block are guaranteed to reside on the same Streaming Multiprocessor (SM), allowing them to share data through high-speed shared memory.
- **Grid: The entire collection of blocks launched for a specific task. Blocks within a grid are independent, allowing them to be scheduled across any available SM in any order.
**Note: CUDA programs can be written and executed in Google Colab, which provide built-in NVIDIA GPUs and CUDA support.
Basic Program
This basic "Hello World" example demonstrates the interaction between the CPU and the GPU by launching a single thread to print a message.
C++ `
%%cuda #include <stdio.h>
global void simpleKernel() { printf("Hello world\n"); }
int main() { simpleKernel<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;}
`
**Output
Hello world
**Explanation:
- %%cuda command automatically handles nvcc compilation and execution in one step.
- __global__ keyword indicates a function that runs on the GPU (the "device") but is called from the CPU (the "host").
- <<<1, 1>>> defines the execution configuration (1 block, 1 thread).
- cudaDeviceSynchronize() forces the CPU to wait until the GPU has finished executing the kernel and flushed its printf buffer before exiting the program.
Limitations
- **Vendor Dependency: CUDA works only on NVIDIA GPUs and is not supported on other hardware vendors.
- **Data Transfer Overhead: Data transfer between CPU and GPU can be slower than computation if the task is not sufficiently large.
- **Memory Management Complexity: Requires careful handling when interacting with other GPU-based APIs like OpenGL or DirectX.