Get all rows in a Pandas DataFrame containing given substring (original) (raw)
Last Updated : 24 Dec, 2018
Let’s see how to get all rows in a Pandas DataFrame containing given substring with the help of different examples.
Code #1: Check the values PG in column Position
import pandas as pd
df = pd.DataFrame({ 'Name' : [ 'Geeks' , 'Peter' , 'James' , 'Jack' , 'Lisa' ],
`` 'Team' : [ 'Boston' , 'Boston' , 'Boston' , 'Chele' , 'Barse' ],
`` 'Position' : [ 'PG' , 'PG' , 'UG' , 'PG' , 'UG' ],
`` 'Number' : [ 3 , 4 , 7 , 11 , 5 ],
`` 'Age' : [ 33 , 25 , 34 , 35 , 28 ],
`` 'Height' : [ '6-2' , '6-4' , '5-9' , '6-1' , '5-8' ],
`` 'Weight' : [ 89 , 79 , 113 , 78 , 84 ],
`` 'College' : [ 'MIT' , 'MIT' , 'MIT' , 'Stanford' , 'Stanford' ],
`` 'Salary' : [ 99999 , 99994 , 89999 , 78889 , 87779 ]},
`` index = [ 'ind1' , 'ind2' , 'ind3' , 'ind4' , 'ind5' ])
print (df, "\n" )
print ( "Check PG values in Position column:\n" )
df1 = df[ 'Position' ]. str .contains( "PG" )
print (df1)
Output: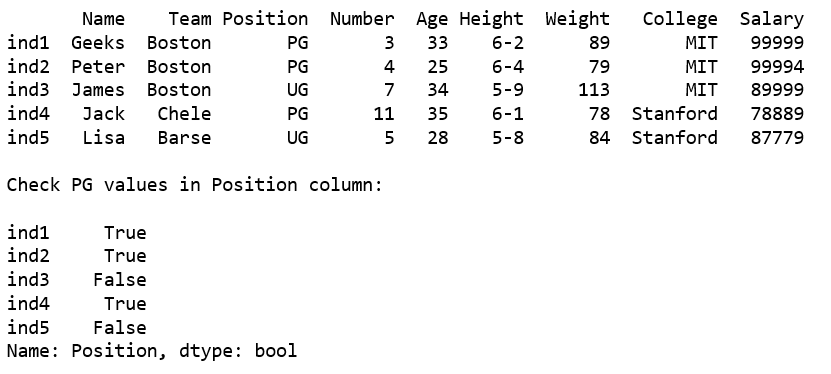
But this result doesn’t seem very helpful, as it returns the bool values with the index. Let’s see if we can do something better.
Code #2: Getting the rows satisfying condition
import pandas as pd
df = pd.DataFrame({ 'Name' : [ 'Geeks' , 'Peter' , 'James' , 'Jack' , 'Lisa' ],
`` 'Team' : [ 'Boston' , 'Boston' , 'Boston' , 'Chele' , 'Barse' ],
`` 'Position' : [ 'PG' , 'PG' , 'UG' , 'PG' , 'UG' ],
`` 'Number' : [ 3 , 4 , 7 , 11 , 5 ],
`` 'Age' : [ 33 , 25 , 34 , 35 , 28 ],
`` 'Height' : [ '6-2' , '6-4' , '5-9' , '6-1' , '5-8' ],
`` 'Weight' : [ 89 , 79 , 113 , 78 , 84 ],
`` 'College' : [ 'MIT' , 'MIT' , 'MIT' , 'Stanford' , 'Stanford' ],
`` 'Salary' : [ 99999 , 99994 , 89999 , 78889 , 87779 ]},
`` index = [ 'ind1' , 'ind2' , 'ind3' , 'ind4' , 'ind5' ])
df1 = df[df[ 'Position' ]. str .contains( "PG" )]
print (df1)
Output: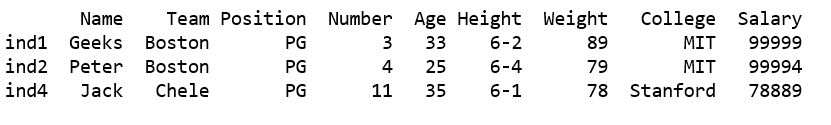
Code #3: Filter all rows where either Team contains ‘Boston’ or College contains ‘MIT’.
import pandas as pd
df = pd.DataFrame({ 'Name' : [ 'Geeks' , 'Peter' , 'James' , 'Jack' , 'Lisa' ],
`` 'Team' : [ 'Boston' , 'Boston' , 'Boston' , 'Chele' , 'Barse' ],
`` 'Position' : [ 'PG' , 'PG' , 'UG' , 'PG' , 'UG' ],
`` 'Number' : [ 3 , 4 , 7 , 11 , 5 ],
`` 'Age' : [ 33 , 25 , 34 , 35 , 28 ],
`` 'Height' : [ '6-2' , '6-4' , '5-9' , '6-1' , '5-8' ],
`` 'Weight' : [ 89 , 79 , 113 , 78 , 84 ],
`` 'College' : [ 'MIT' , 'MIT' , 'MIT' , 'Stanford' , 'Stanford' ],
`` 'Salary' : [ 99999 , 99994 , 89999 , 78889 , 87779 ]},
`` index = [ 'ind1' , 'ind2' , 'ind3' , 'ind4' , 'ind5' ])
df1 = df[df[ 'Team' ]. str .contains( "Boston" ) | df[ 'College' ]. str .contains( 'MIT' )]
print (df1)
Output: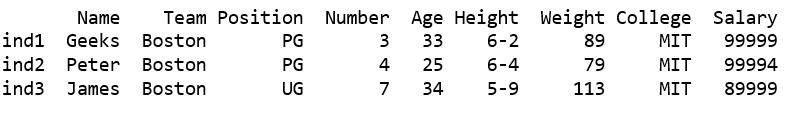
Code #4: Filter rows checking Team name contains ‘Boston and Position must be PG.
Output: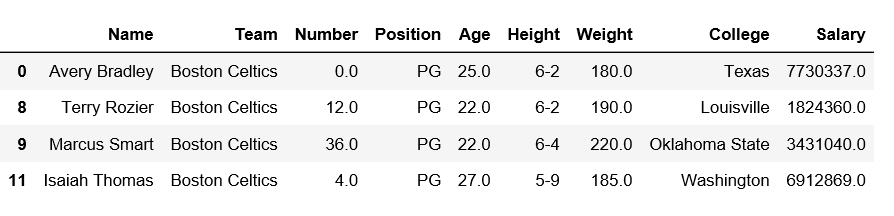
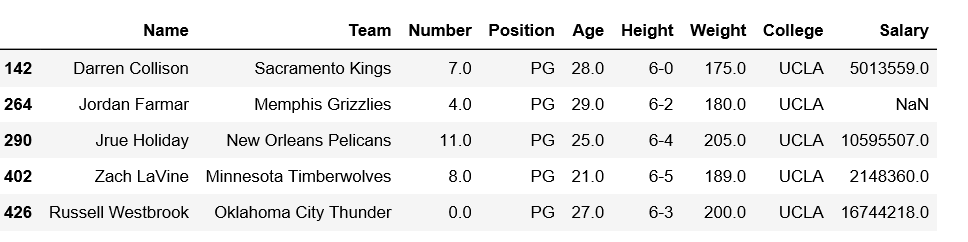
Code #5: Filter rows checking Position contains PG and College must contains like UC.
Output: