Introduction to Recurrent Neural Networks (original) (raw)
**Recurrent Neural Networks (RNNs) differ from regular neural networks in how they process information. While standard neural networks pass information in one direction i.e from input to output, RNNs feed information back into the network at each step.
Imagine reading a sentence and you try to predict the next word, you don’t rely only on the current word but also remember the words that came before. RNNs work similarly by “remembering” past information and passing the output from one step as input to the next i.e it considers all the earlier words to choose the most likely next word. This memory of previous steps helps the network understand context and make better predictions.
Key Components of RNNs
There are mainly two components of RNNs that we will discuss.
1. Recurrent Neurons
The fundamental processing unit in RNN is a **Recurrent Unit. They hold a hidden state that maintains information about previous inputs in a sequence. Recurrent units can "remember" information from prior steps by feeding back their hidden state, allowing them to capture dependencies across time.
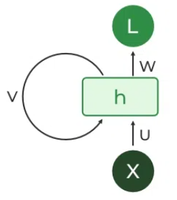
Recurrent Neuron
2. RNN Unfolding
RNN unfolding or unrolling is the process of expanding the recurrent structure over time steps. During unfolding each step of the sequence is represented as a separate layer in a series illustrating how information flows across each time step.
This unrolling enables **backpropagation through time (BPTT) a learning process where errors are propagated across time steps to adjust the network’s weights enhancing the RNN’s ability to learn dependencies within sequential data.

RNN Unfolding
Recurrent Neural Network Architecture
RNNs share similarities in input and output structures with other deep learning architectures but differ significantly in how information flows from input to output. Unlike traditional deep neural networks where each dense layer has distinct weight matrices. RNNs use shared weights across time steps, allowing them to remember information over sequences.
In RNNs the hidden state H_i is calculated for every input X_i to retain sequential dependencies. The computations follow these core formulas:
**1. Hidden State Calculation:
h = \sigma(U \cdot X + W \cdot h_{t-1} + B)
Here:
- h represents the current hidden state.
- U and W are weight matrices.
- B is the bias.
**2. Output Calculation:
Y = O(V \cdot h + C)
The output Y is calculated by applying O an activation function to the weighted hidden state where V and C represent weights and bias.
**3. Overall Function:
Y = f(X, h, W, U, V, B, C)
This function defines the entire RNN operation where the state matrix S holds each element s_i representing the network's state at each time step i.

Recurrent Neural Architecture
How does RNN work?
At each time step RNNs process units with a fixed activation function. These units have an internal hidden state that acts as memory that retains information from previous time steps. This memory allows the network to store past knowledge and adapt based on new inputs.
Updating the Hidden State in RNNs
The current hidden state h_t depends on the previous state h_{t-1} and the current input x_t and is calculated using the following relations:
**1. State Update:
h_t = f(h_{t-1}, x_t)
where:
- h_t is the current state
- h_{t-1} is the previous state
- x_t is the input at the current time step
**2. Activation Function Application:
h_t = \tanh(W_{hh} \cdot h_{t-1} + W_{xh} \cdot x_t)
Here, W_{hh} is the weight matrix for the recurrent neuron and W_{xh} is the weight matrix for the input neuron.
**3. Output Calculation:
y_t = W_{hy} \cdot h_t
where y_t is the output and W_{hy} is the weight at the output layer.
_These parameters are updated using backpropagation. However, since RNN works on sequential data here we use an updated backpropagation which is known as **backpropagation through time .
**Backpropagation Through Time (BPTT) in RNNs
Since RNNs process sequential data **Backpropagation Through Time (BPTT)is used to update the network's parameters. The loss function L(θ) depends on the final hidden state h_3 and each hidden state relies on preceding ones forming a sequential dependency chain:
h_3 depends on \text{ depends on } h_2, \, h_2 \text{ depends on } h_1, \, \dots, \, h_1 \text{ depends on } h_0.
.webp)
Backpropagation Through Time (BPTT) In RNN
In BPTT, gradients are backpropagated through each time step. This is essential for updating network parameters based on temporal dependencies.
- **Simplified Gradient Calculation:
\frac{\partial L(\theta)}{\partial W} = \frac{\partial L (\theta)}{\partial h_3} \cdot \frac{\partial h_3}{\partial W} - **Handling Dependencies in Layers: Each hidden state is updated based on its dependencies:
h_3 = \sigma(W \cdot h_2 + b)
The gradient is then calculated for each state, considering dependencies from previous hidden states. - **Gradient Calculation with Explicit and Implicit Parts: The gradient is broken down into explicit and implicit parts summing up the indirect paths from each hidden state to the weights.
\frac{\partial h_3}{\partial W} = \frac{\partial h_3^{+}}{\partial W} + \frac{\partial h_3}{\partial h_2} \cdot \frac{\partial h_2^{+}}{\partial W} - **Final Gradient Expression: The final derivative of the loss function with respect to the weight matrix W is computed:
\frac{\partial L(\theta)}{\partial W} = \frac{\partial L(\theta)}{\partial h_3} \cdot \sum_{k=1}^{3} \frac{\partial h_3}{\partial h_k} \cdot \frac{\partial h_k}{\partial W}
This iterative process is the essence of backpropagation through time.
Types Of Recurrent Neural Networks
There are four types of RNNs based on the number of inputs and outputs in the network:
**1. One-to-One RNN
This is the simplest type of neural network architecture where there is a single input and a single output. It is used for straightforward classification tasks such as binary classification where no sequential data is involved.

One to One RNN
2. One-to-Many RNN
In a One-to-Many RNN the network processes a single input to produce multiple outputs over time. This is useful in tasks where one input triggers a sequence of predictions (outputs). For example in image captioning a single image can be used as input to generate a sequence of words as a caption.
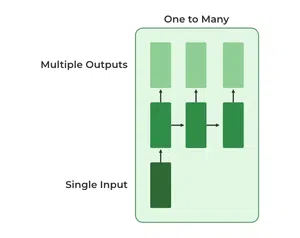
One to Many RNN
3. Many-to-One RNN
The **Many-to-One RNN receives a sequence of inputs and generates a single output. This type is useful when the overall context of the input sequence is needed to make one prediction. In sentiment analysis the model receives a sequence of words (like a sentence) and produces a single output like positive, negative or neutral.

Many to One RNN
4. Many-to-Many RNN
The **Many-to-Many RNN type processes a sequence of inputs and generates a sequence of outputs. In language translation task a sequence of words in one language is given as input and a corresponding sequence in another language is generated as output.
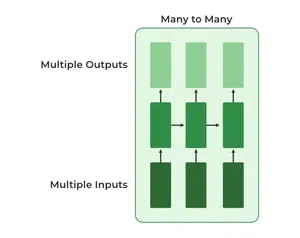
Many to Many RNN
Variants of Recurrent Neural Networks (RNNs)
There are several variations of RNNs, each designed to address specific challenges or optimize for certain tasks:
**1. Vanilla RNN
This simplest form of RNN consists of a single hidden layer where weights are shared across time steps. Vanilla RNNs are suitable for learning short-term dependencies but are limited by the vanishing gradient problem, which hampers long-sequence learning.
**2. Bidirectional RNNs
Bidirectional RNNs process inputs in both forward and backward directions, capturing both past and future context for each time step. This architecture is ideal for tasks where the entire sequence is available, such as named entity recognition and question answering.
**3. Long Short-Term Memory Networks (LSTMs)
Long Short-Term Memory Networks (LSTMs) introduce a memory mechanism to overcome the vanishing gradient problem. Each LSTM cell has three gates:
- **Input Gate: Controls how much new information should be added to the cell state.
- **Forget Gate: Decides what past information should be discarded.
- **Output Gate: Regulates what information should be output at the current step. This selective memory enables LSTMs to handle long-term dependencies, making them ideal for tasks where earlier context is critical.
**4. Gated Recurrent Units (GRUs)
Gated Recurrent Units (GRUs) simplify LSTMs by combining the input and forget gates into a single update gate and streamlining the output mechanism. This design is computationally efficient, often performing similarly to LSTMs and is useful in tasks where simplicity and faster training are beneficial.
How RNN Differs from Feedforward Neural Networks?
Feedforward Neural Networks (FNNs) process data in one direction from input to output without retaining information from previous inputs. This makes them suitable for tasks with independent inputs like image classification. However FNNs struggle with sequential data since they lack memory.
Recurrent Neural Networks (RNNs) solve this **by incorporating loops that allow information from previous steps to be fed back into the network. This feedback enables RNNs to remember prior inputs making them ideal for tasks where context is important.
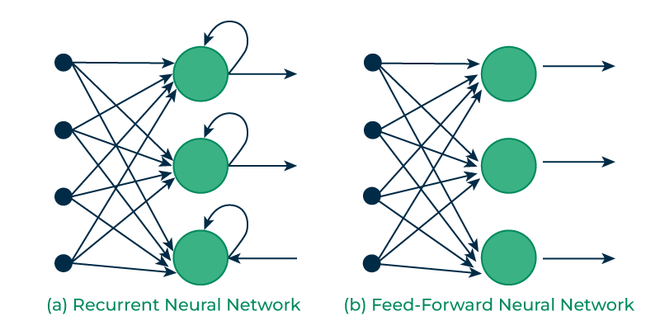
Recurrent Vs Feedforward networks
Implementing a Text Generator Using Recurrent Neural Networks (RNNs)
In this section, we create a character-based text generator using Recurrent Neural Network (RNN) in TensorFlow and Keras. We'll implement an RNN that learns patterns from a text sequence to generate new text character-by-character.
1. Importing Necessary Libraries
We start by importing essential libraries for data handling and building the neural network.
Python `
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import SimpleRNN, Dense
`
2. Defining the Input Text and Prepare Character Set
We define the input text and identify unique characters in the text which we’ll encode for our model.
Python `
text = "This is GeeksforGeeks a software training institute" chars = sorted(list(set(text))) char_to_index = {char: i for i, char in enumerate(chars)} index_to_char = {i: char for i, char in enumerate(chars)}
`
3. Creating Sequences and Labels
To train the RNN, we need sequences of fixed length (seq_length) and the character following each sequence as the label.
Python `
seq_length = 3 sequences = [] labels = []
for i in range(len(text) - seq_length): seq = text[i:i + seq_length] label = text[i + seq_length] sequences.append([char_to_index[char] for char in seq]) labels.append(char_to_index[label])
X = np.array(sequences) y = np.array(labels)
`
4. Converting Sequences and Labels to One-Hot Encoding
For training we convert X and y into one-hot encoded tensors.
Python `
X_one_hot = tf.one_hot(X, len(chars)) y_one_hot = tf.one_hot(y, len(chars))
`
5. Building the RNN Model
We create a simple RNN model with a hidden layer of 50 units and a Dense output layer with softmax activation.
Python `
model = Sequential() model.add(SimpleRNN(50, input_shape=(seq_length, len(chars)), activation='relu')) model.add(Dense(len(chars), activation='softmax'))
`
6. Compiling and Training the Model
We compile the model using the categorical_crossentropy loss and train it for 100 epochs.
Python `
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_one_hot, y_one_hot, epochs=100)
`
**Output:
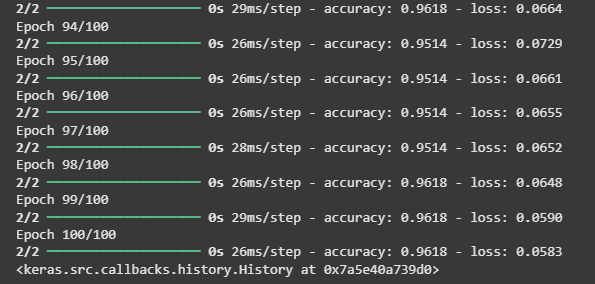
Training the RNN model
7. Generating New Text Using the Trained Model
After training we use a starting sequence to generate new text character by character.
Python `
start_seq = "This is G" generated_text = start_seq
for i in range(50): x = np.array([[char_to_index[char] for char in generated_text[-seq_length:]]]) x_one_hot = tf.one_hot(x, len(chars)) prediction = model.predict(x_one_hot) next_index = np.argmax(prediction) next_char = index_to_char[next_index] generated_text += next_char
print("Generated Text:") print(generated_text)
`
**Output:
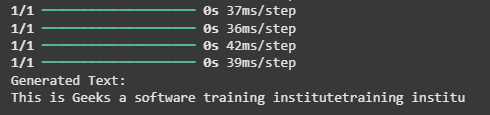
Predicting the next word
Advantages of Recurrent Neural Networks
- **Sequential Memory: RNNs retain information from previous inputs making them ideal for time-series predictions where past data is crucial.
- **Enhanced Pixel Neighborhoods: RNNs can be combined with convolutional layers to capture extended pixel neighborhoods improving performance in image and video data processing.
Limitations of Recurrent Neural Networks (RNNs)
While RNNs excel at handling sequential data they face two main training challenges i.e vanishing gradient and exploding gradient problem:
- **Vanishing Gradient: During backpropagation gradients diminish as they pass through each time step leading to minimal weight updates. This limits the RNN’s ability to learn long-term dependencies which is crucial for tasks like language translation.
- **Exploding Gradient: Sometimes gradients grow uncontrollably causing excessively large weight updates that de-stabilize training.
These challenges can hinder the performance of standard RNNs on complex, long-sequence tasks.
Applications of Recurrent Neural Networks
RNNs are used in various applications where data is sequential or time-based:
- **Time-Series Prediction: RNNs excel in forecasting tasks, such as stock market predictions and weather forecasting.
- **Natural Language Processing (NLP): RNNs are fundamental in NLP tasks like language modeling, sentiment analysis and machine translation.
- **Speech Recognition: RNNs capture temporal patterns in speech data, aiding in speech-to-text and other audio-related applications.
- **Image and Video Processing: When combined with convolutional layers, RNNs help analyze video sequences, facial expressions and gesture recognition.