ActorCritic Algorithm in Reinforcement Learning (original) (raw)
Actor-Critic Algorithm in Reinforcement Learning
Last Updated : 9 Oct, 2025
Actor-Critic Algorithm is a type of reinforcement learning algorithm that combines two parts i.e the Actor which selects actions and the Critic which evaluates them. This helps the agent learn more effectively by balancing decision-making and feedback. In the actor-critic method the actor learns how to make decisions and the critic checks how good those decisions are. This dual role helps the agent explore new actions while also using what it has learned and make the learning process better and more balanced.
Key Terms
There are two key terms:
**1. Policy (Actor) :
- The policy denoted as \pi(a|s), represents the probability of taking action a in state s.
- The actor seeks to maximize the expected return by optimizing this policy.
- The policy is modeled by the actor network and its parameters are denoted by \theta
**2. Value Function (Critic) :
- The value function, denoted as V(s), estimates the expected cumulative reward starting from state s.
- The value function is modeled by the critic network and its parameters are denoted by w.
How Actor-Critic algorithm works?
**Actor Critic Algorithm Objective Function
- The objective function for the Actor-Critic algorithm is a combination of the policy gradient (for the actor) and the value function (for the critic).
- The overall objective function is typically expressed as the sum of two components:
1. Policy Gradient (Actor)
\nabla_\theta J(\theta)\approx \frac{1}{N} \sum_{i=0}^{N} \nabla_\theta \log\pi_\theta (a_i|s_i)\cdot A(s_i,a_i)
Here,
- J(θ) represents the expected return under the policy parameterized by θ
- π_\theta (a∣s) is the policy function
- N is the number of sampled experiences.
- A(s,a) is the advantage function representing the advantage of taking action a in state s.
- _i represents the index of the sample
2. Value Function Update (Critic)
\nabla_w J(w) \approx \frac{1}{N}\sum_{i=1}^{N} \nabla_w (V_{w}(s_i)- Q_{w}(s_i , a_i))^2
Here,
- \nabla_w J(w) is the gradient of the loss function with respect to the critic's parameters w.
- N is number of samples
- V_w(s_i) is the critic's estimate of value of state s with parameter w
- Q_w (s_i , a_i) is the critic's estimate of the action-value of taking action a
- _i represents the index of the sample
Update Rules
The update rules for the actor and critic involve adjusting their respective parameters using gradient ascent (for the actor) and gradient descent (for the critic).
Actor Update
\theta_{t+1}= \theta_t + \alpha \nabla_\theta J(\theta_t)
Here,
- \alpha: learning rate for the actor
- t is the time step within an episode
Critic Update
w_{t} = w_t -\beta \nabla_w J(w_t)
Here
- w represents the parameters of the critic network
- \beta is the learning rate for the critic
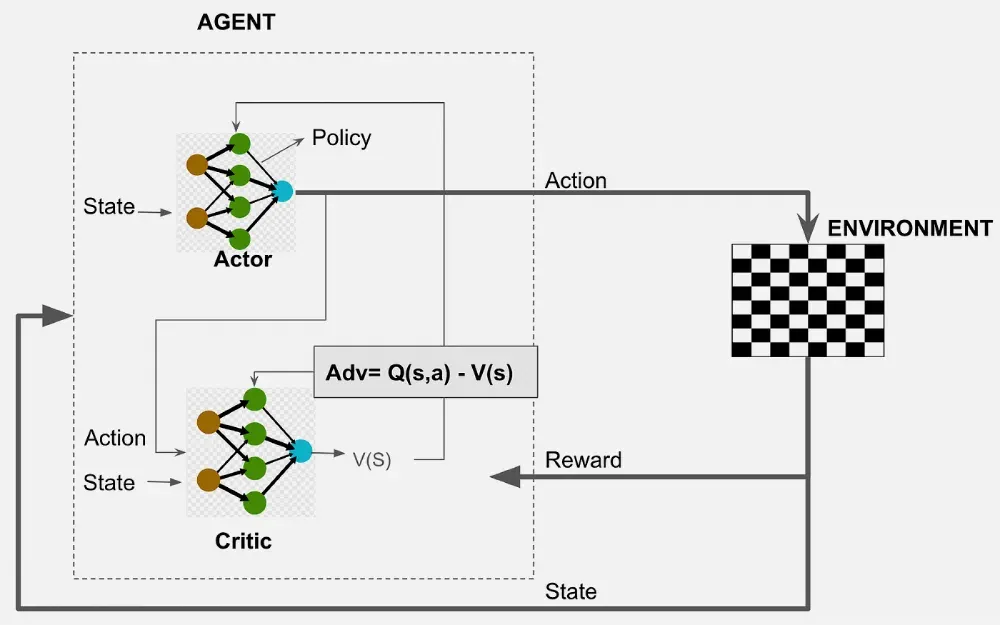
Advantage Function
The advantage function, A(s,a) measures the advantage of taking action **a in state **s over the expected value of the state under the current policy.
A(s,a)=Q(s,a)−V(s)
The advantage function, then, provides a measure of how much better or worse an action is compared to the average action. These mathematical expressions highlight the essential computations involved in the Actor-Critic method. The actor is updated based on the policy gradient, encouraging actions with higher advantages while the critic is updated to minimize the difference between the estimated value and the action-value.
Training Agent: Actor-Critic Algorithm
Let's understand how the Actor-Critic algorithm works in practice. Below is an implementation of a simple Actor-Critic algorithm using TensorFlow and OpenAI Gym to train an agent in the CartPole environment.
Step 1: Import Libraries
Python `
import numpy as np import tensorflow as tf import gym
`
Step 2: Creating CartPole Environment
Create the CartPole environment using the gym.make() function from the Gym library because it provides a standardized and convenient way to interact with various reinforcement learning tasks.
Python `
Create the CartPole Environment
env = gym.make('CartPole-v1')
`
Step 3: Defining Actor and Critic Networks
- Actor and the Critic are implemented as neural networks using TensorFlow's Keras API.
- Actor network maps the state to a probability distribution over actions.
- Critic network estimates the state's value. Python `
Define the actor and critic networks
actor = tf.keras.Sequential([ tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(env.action_space.n, activation='softmax') ])
critic = tf.keras.Sequential([ tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(1) ])
`
Step 4: Defining Optimizers and Loss Functions
We use Adam optimizer for both networks.
Python `
Define optimizer and loss functions
actor_optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) critic_optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
`
Step 5: Training Loop
The training loop runs for 1000 episodes with the agent interacting with the environment, calculating advantages and updating both the actor and critic.
Python `
Main training loop
num_episodes = 1000 gamma = 0.99
for episode in range(num_episodes): state = env.reset() episode_reward = 0
with tf.GradientTape(persistent=True) as tape:
for t in range(1, 10000): # Limit the number of time steps
# Choose an action using the actor
action_probs = actor(np.array([state]))
action = np.random.choice(env.action_space.n, p=action_probs.numpy()[0])
# Take the chosen action and observe the next state and reward
next_state, reward, done, _ = env.step(action)
# Compute the advantage
state_value = critic(np.array([state]))[0, 0]
next_state_value = critic(np.array([next_state]))[0, 0]
advantage = reward + gamma * next_state_value - state_value
# Compute actor and critic losses
actor_loss = -tf.math.log(action_probs[0, action]) * advantage
critic_loss = tf.square(advantage)
episode_reward += reward
# Update actor and critic
actor_gradients = tape.gradient(actor_loss, actor.trainable_variables)
critic_gradients = tape.gradient(critic_loss, critic.trainable_variables)
actor_optimizer.apply_gradients(zip(actor_gradients, actor.trainable_variables))
critic_optimizer.apply_gradients(zip(critic_gradients, critic.trainable_variables))
if done:
break
if episode % 10 == 0:
print(f'Episode {episode}, Reward: {episode_reward}')env.close()
`
**Output:

Advantages
The Actor-Critic method offer several advantages:
- **Improved Sample Efficiency: The hybrid nature of Actor-Critic algorithms often leads to improved sample efficiency, requiring fewer interactions with the environment to achieve optimal performance.
- **Faster Convergence: The method's ability to update both the policy and value function concurrently contributes to faster convergence during training, enabling quicker adaptation to the learning task.
- **Versatility Across Action Spaces: Actor-Critic architectures can seamlessly handle both discrete and continuous action spaces, offering flexibility in addressing a wide range of RL problems.
- **Off-Policy Learning (in some variants): Learns from past experiences, even when not directly following the current policy.
Variants of Actor-Critic Algorithms
Several variants of the Actor-Critic algorithm have been developed to address specific challenges or improve performance in certain types of environments:
- **Advantage Actor-Critic (A2C): A2C modifies the critic’s value function to estimate the advantage function which measures how much better or worse an action is compared to the average action. The advantage function is defined as:
A(s_t, a_t) = Q(s_t, a_t) - V(s_t)
A2C helps reduce the variance of the policy gradient, leading to better learning performance.
- **Asynchronous Advantage Actor-Critic (A3C): A3C is an extension of A2C that uses multiple agents (threads) running in parallel to update the policy asynchronously. This allows for more stable and faster learning by reducing correlations between updates.