Bellman Equation (original) (raw)
Last Updated : 7 Apr, 2026
The Bellman Equation is a formula used in reinforcement learning to calculate the value of a state. It says that the value of a state is equal to the reward received now plus the expected value of the next state. This helps an agent make better decisions by considering both immediate and future rewards. It is based on the principle of optimality which means the best value of a state depends on the immediate reward and the value of the next state.
**1. Bellman Equation for State Value Function
State value function denoted as V(s) under a given policy represents the expected cumulative reward when starting from state s and following that policy:
V^{\pi}(s) = \mathbb{E}[R(s,a) + \gamma V^{\pi }(s')]
Expanding this equation with transition probabilities we get:
V^{\pi}(s) = \sum_{a \in A} \pi(a | s) \sum_{s' \in S} P(s' | s, a) \left[ R(s, a) + \gamma V^{\pi}(s') \right]
where:
- V^{\pi}(s): Value function of state **s under policy.
- P(s' | s, a): Transition probability from state s to state s' when taking action a.
- R(s, a): Reward obtained after taking action a in state s.
- γ: Discount factor controlling the importance of future rewards.
- \pi(a | s): Probability of taking action a in state s under policy .
**2. Bellman Equation for Action Value Function (Q-function)
Q-function **(Q(s, a)****) represents the expected return for taking action a in state s and following the policy afterward:
Q^{\pi}(s, a) = \mathbb{E} \left[ R(s, a) + \gamma V^{\pi}(s') \right]
Expanding it using transition probabilities:
Q^{\pi}(s, a) = \sum_{s' \in S} P(s' | s, a) \left[ R(s, a) + \gamma \sum_{a'} \pi(a' | s') Q^{\pi}(s', a') \right]
This equation helps compute the expected future rewards based on both current action a and subsequent policy actions.
**Bellman Optimality Equations
For an optimal policy \pi^*, the Bellman equation becomes:
**1. Optimal State Value Function
V^*(s) = \max_{a} \sum_{s'} P(s' | s, a) \left[ R(s, a) + \gamma V^*(s') \right]
**2. Optimal Action Value Function (Q-Learning)
Q^*(s, a) = \sum_{s'} P(s' | s, a) \left[ R(s, a) + \gamma \max_{a'} Q^*(s', a') \right]
These equations form the foundation for Dynamic Programming, Temporal Difference (TD) Learning and Q-Learning.
**Solving MDPs with Bellman Equations
Markov Decision Process can be solved using Dynamic Programming (DP) methods that rely on Bellman Equations:
- **Value Iteration: Uses Bellman Optimality Equation to iteratively update value functions until convergence.
- **Policy Iteration: Alternates between policy evaluation (solving Bellman Expectation Equation) and policy improvement (updating policy based on new value function).
- **Q-Learning: Uses the Bellman Optimality Equation for Q-values to learn optimal policies.
Example: Navigating a Maze
Consider a maze as our environment, where an agent's goal is to reach the trophy state (reward R = 1) while avoiding the fire state (reward R = -1). The agent receives positive reinforcement for reaching the goal and negative reinforcement for failing. The agent must navigate the maze efficiently while considering possible future rewards.
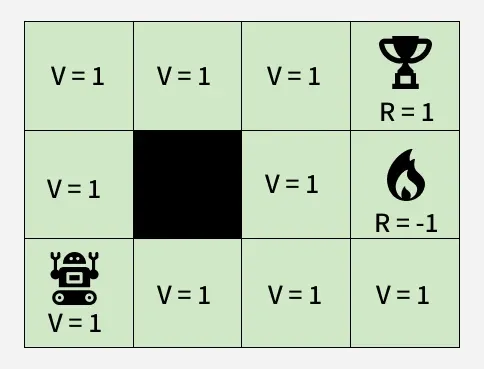
Without Bellman Equation
**What Happens Without the Bellman Equation?
- Initially we allow the agent to explore the environment and find a path to the goal. Once it reaches the trophy state it backtracks to its starting position and assigns a value of V = 1 to all states that lead to the goal.
- However if we change the agent’s starting position it will struggle to find a new path since all previously learned state values remain the same. This is where the Bellman Equation helps by dynamically updating state values based on future rewards.
**Applying the Concept
Consider a state adjacent to the fire state, where V = 0.9. The agent can move UP, DOWN or RIGHT but cannot move LEFT due to a wall. Among the available actions the agent selects the action leading to the maximum value, ensuring the highest possible reward over time.
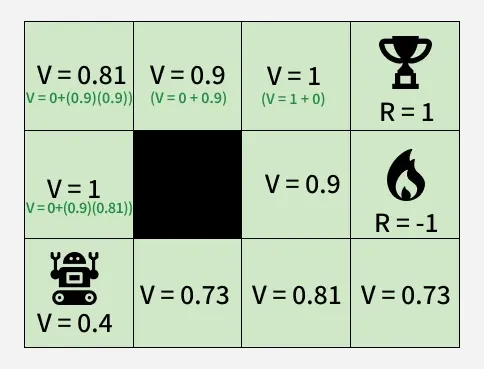
Using Bellman Equation
By continuously updating state values the agent systematically calculates the best path while avoiding the fire state. The goal (trophy) and failure (fire) states do not require value updates as they represent terminal states (their value depends on the reward and formulation). Bellman Equation allows agents to think ahead, balance immediate and future rewards and choose actions wisely.