Few Shot Learning (original) (raw)
Last Updated : 11 May, 2026
Few-Shot Learning is a machine learning approach where models learn to perform new tasks or recognize new classes using only a few labeled samples. Supervised learning needs large datasets, FSL aims to mimic human learning, allowing models to generalize from limited examples. It is highly useful in fields where data collection is costly or scarce such as healthcare and rare species detection.
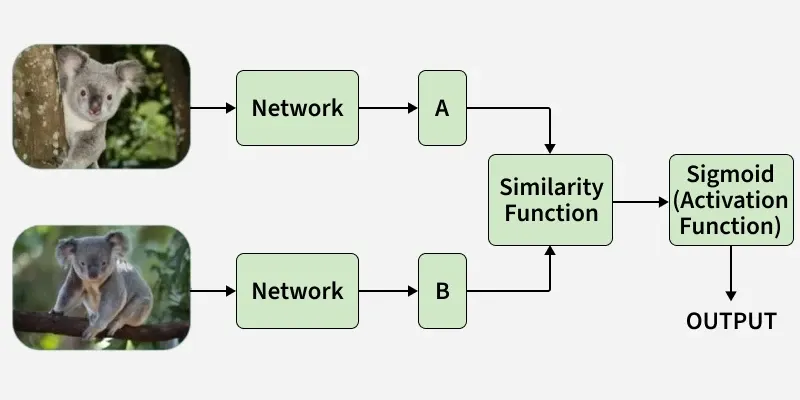
Few Shot Learning
This approach offers several practical benefits that make AI more efficient, adaptable and closer to human-like intelligence
- **Less Dependence on Big Data: Performs effectively with minimal samples, ideal for domains like healthcare or astronomy.
- **Quick Adaptation: Enables AI to recognize new objects or faces from just a few examples.
- **Time and Cost Efficient: Reduces the need for large labeled datasets saving effort and resources.
- **Adaptability to Rare Domains: Efficient in evolving fields like cybersecurity or medical diagnosis.
How Few Shot Learning Works
In Few Shot Learning each task is generally divided into two key parts the Support Set and the Query Set. These two sets play a vital role in helping the model learn from a few labeled examples and then generalize to new unseen samples.
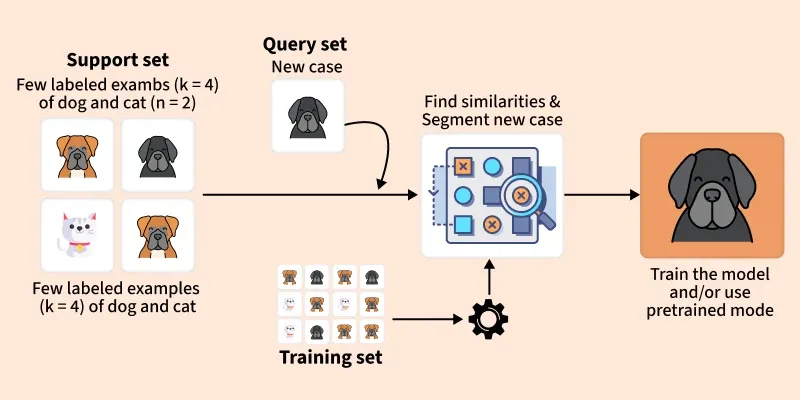
Core idea
Support Set (S)
The Support Set is a small collection of labeled examples used for learning represented as:
S = \{(x_1, y_1), (x_2, y_2), \dots, (x_k, y_k)\}
**where :
- x_i represents the data point
- y_i is the corresponding label for that data point
Query Set (Q)
The Query Set contains unlabeled examples used to test the model’s ability to generalize.
Q = \{x'_1, x'_2, \dots, x'_m\}
The model’s task is to predict the labels for these query samples based on what it has learned from the Support Set.
How the Model Learns from Support and Query Sets
Few Shot Learning models work by comparing samples from the Query Set with those in the Support Set to determine similarity. This comparison is typically performed using a distance or similarity function Common similarity functions:
The model uses these measures to identify which support examples a query example is most similar to and assigns the corresponding label. Then model uses the most similar examples from the Support Set to predict the correct label for the Query sample or fine tune its parameters for better task adaptation.
Step-By-Step Implementation
Here we uses a pretrained ResNet50 as a feature extractor and performs a metric based few shot classification pick a small support set, embed support and query images compute cosine similarity then assign each query the label of its nearest support example.
Step 1: Install and Import Libraries
- Install essential packages such as timm, torch and torchvision
- Import all required modules for model creation, dataset loading and image transformations
- Set random seeds for reproducibility and configure device
- Ensure consistent output across multiple runs Python `
!pip install -q timm torch torchvision
import random import torch import torch.nn.functional as F from torchvision import transforms from torchvision.datasets import CIFAR10 import timm
random.seed(42) torch.manual_seed(42) if torch.cuda.is_available(): torch.cuda.manual_seed_all(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print("Using device:", device)
`
Step 2: Load the Pretrained ResNet50 Model
- Load a ResNet50 model from the timm library with its final classification layer removed
- Use the model as a feature extractor instead of a classifier
- Move the model to GPU if available for faster computation
- Set the model to evaluation mode to disable training operations Python `
model = timm.create_model("resnet50", pretrained=True, num_classes=0) model.eval().to(device)
`
**Output:
Load resnet
Step 3: Define Image Transformations
- Apply resizing and cropping to make CIFAR-10 images compatible with ResNet input size
- Convert images to tensors and normalize them using ImageNet statistics
- Ensure that all input images follow the same preprocessing pipeline Python `
transform = transforms.Compose([ transforms.Resize(224), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ])
`
Step 4: Load the CIFAR-10 Dataset
- Download the CIFAR-10 dataset if not already present locally
- Use the training set for support examples and test set for query examples
- Each class contains small labeled images Python `
train_dataset = CIFAR10(root="./data", train=True, transform=transform, download=True) test_dataset = CIFAR10(root="./data", train=False, transform=transform, download=True)
class_names = train_dataset.classes print("Classes:", class_names)
`
Step 5: Configure Few-Shot Task
- Select a subset of classes for few shot classification
- Define the number of samples per class for both support and query sets Python `
selected_classes = [0, 1, 2] num_support_per_class = 5 num_query_per_class = 5
`
Step 6: Sample Support and Query Sets
- Randomly sample few examples from each class for training (support set)
- Randomly select query examples from the test dataset
- Store indices separately for both sets to maintain class balance Python `
support_indices, query_indices = [], []
for cls in selected_classes: train_idxs = [i for i, y in enumerate(train_dataset.targets) if y == cls] test_idxs = [i for i, y in enumerate(test_dataset.targets) if y == cls]
support_indices.extend(random.sample(train_idxs, num_support_per_class))
query_indices.extend(random.sample(test_idxs, num_query_per_class))`
Step 7: Prepare Image Tensors and Labels
- Extract selected samples and convert them into tensors
- Move data to GPU for faster embedding extraction
- Keep track of labels for evaluation
- Prepare both support and query datasets in memory Python `
support_images, support_labels = zip([train_dataset[i] for i in support_indices]) query_images, query_labels = zip([test_dataset[i] for i in query_indices])
support_images = torch.stack(support_images).to(device) query_images = torch.stack(query_images).to(device)
support_labels = list(support_labels) query_labels = list(query_labels)
`
Step 8: Extract and Normalize Embeddings
- Pass images through the pretrained ResNet50 to obtain feature embeddings
- Avoid gradient calculations using torch.no_grad() for efficiency
- Normalize embeddings using L2 normalization to make cosine similarity effective
- Convert high dimensional images into compact, comparable feature vectors Python `
with torch.no_grad(): support_embeddings = model(support_images) query_embeddings = model(query_images)
support_embeddings = F.normalize(support_embeddings, p=2, dim=1) query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
`
Step 9: Compute Similarity and Predict Labels
- Compute cosine similarity between query and support embeddings
- Assign the corresponding support label as the predicted label
- Perform few-shot classification based on embedding similarity Python `
similarity = torch.mm(query_embeddings, support_embeddings.T) _, nearest = similarity.max(dim=1) predicted_labels = [support_labels[i] for i in nearest.cpu().tolist()]
`
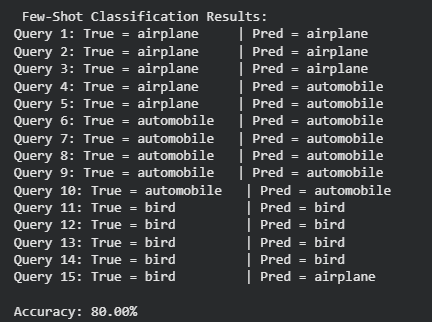
Step 10: Results and Accuracy
- Print true and predicted class labels for each query image.
- Count correct predictions to calculate accuracy.
- Display overall few shot accuracy for the selected classes. Python `
print("\nFew-Shot Classification Results:") for i, (t, p) in enumerate(zip(query_labels, predicted_labels), 1): print(f"Query {i}: True = {class_names[t]:12s} | Pred = {class_names[p]}")
correct = sum(int(t == p) for t, p in zip(query_labels, predicted_labels)) acc = 100.0 * correct / len(query_labels) print(f"\nAccuracy: {acc:.2f}%")
`
**Output:
Few Shot Learning
You can download full code from here.
Approaches for Few Shot Learning
**1. Model Agnostic Meta Learning (MAML)
Model Agnostic Meta Learning (MAML) focuses on training a model so it can quickly adapt to new tasks using only a few examples. It learns an optimal parameter initialization that can be fine tuned easily for unseen tasks with minimal updates.
2. Metric Learning
Metric Learning focuses on learning a distance function that measures how similar two data points are. The model learns a similarity metric that captures relationships between data points.
Common Metric Learning Models:
- **Siamese Networks: Use twin neural networks that learn to differentiate between similar and dissimilar pairs.
- **Matching Networks: Use attention mechanisms to compare a query example with a support set.
- **Prototypical Networks: Create a prototype for each class and classify query samples based on their distance to these prototypes.
3. Transfer Learning
Transfer Learning leverages knowledge gained from large-scale datasets to improve learning in data scarce domains. It involves reusing a pre trained model and fine tuning it on a small domain specific dataset.
- **Pretrained Models: Use models trained on large datasets and adapt them to the new few shot task.
- **Fine Tuning: Adjust only the final layers or a subset of parameters to suit the target task.
- **Feature Extraction: Freeze earlier layers and use them to extract useful features for new data.
Variations In Few-shot learning
- **Zero-Shot Learning (ZSL)****:** In this approach, there are no training examples from the target classes. The system relies on prior knowledge or textual descriptions to make predictions.
- **One Shot Learning: Only a single example per class is provided and the system must generalize to new, unseen samples from that minimal data.
- **Two Shot Learning: Each class comes with two labeled examples allowing slightly better learning while still keeping data requirements low.
- **N Shot Learning : It is a framework where a model learns new tasks using only n examples per class enabling it to generalize from limited data similar to human learning.
Applications
- **Healthcare: Detects rare diseases or segments medical images using only a few annotated scans.
- **Computer Vision: Classifies new objects or species from limited training examples.
- **Cybersecurity: Identifies emerging threats or malware patterns from scarce labeled data.
- **Robotics: Helps robots learn new tasks or adapt to changing environments with minimal retraining.
- **Speech Recognition: Personalizes voice assistants and adapts to new speakers or accents quickly.
Limitations
- **Data Sensitivity: Performance drops sharply with noisy or mislabeled samples.
- **Poor Generalization: Struggles with tasks very different from training data.
- **Complex Training: Requires intricate meta-learning setups.
- **Pretrained Dependence: Relies heavily on large pretrained models.
- **Class Bias: Tends to favor classes seen during training.